|
|
|

如何评价 AMD 推出的 FidelityFX Super Resolution(FSR)技术?

登录后你可以
不限量看优质回答
私信答主深度交流
精彩内容一键收藏


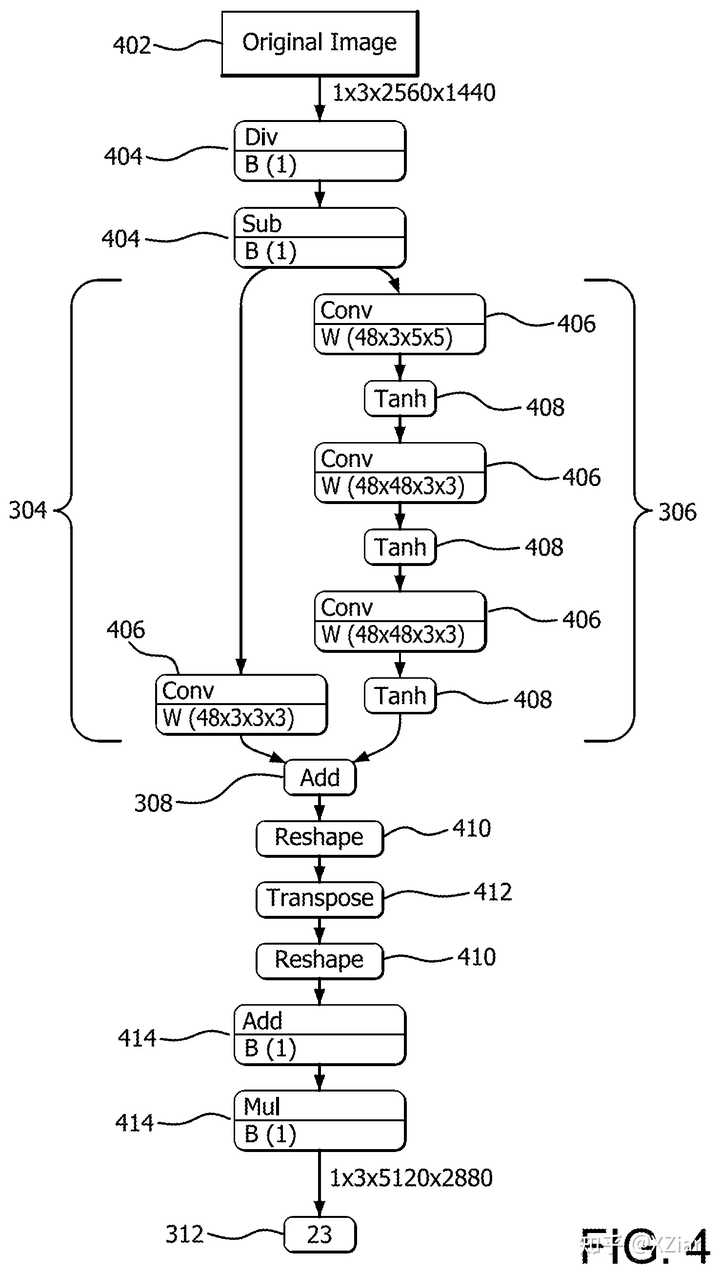
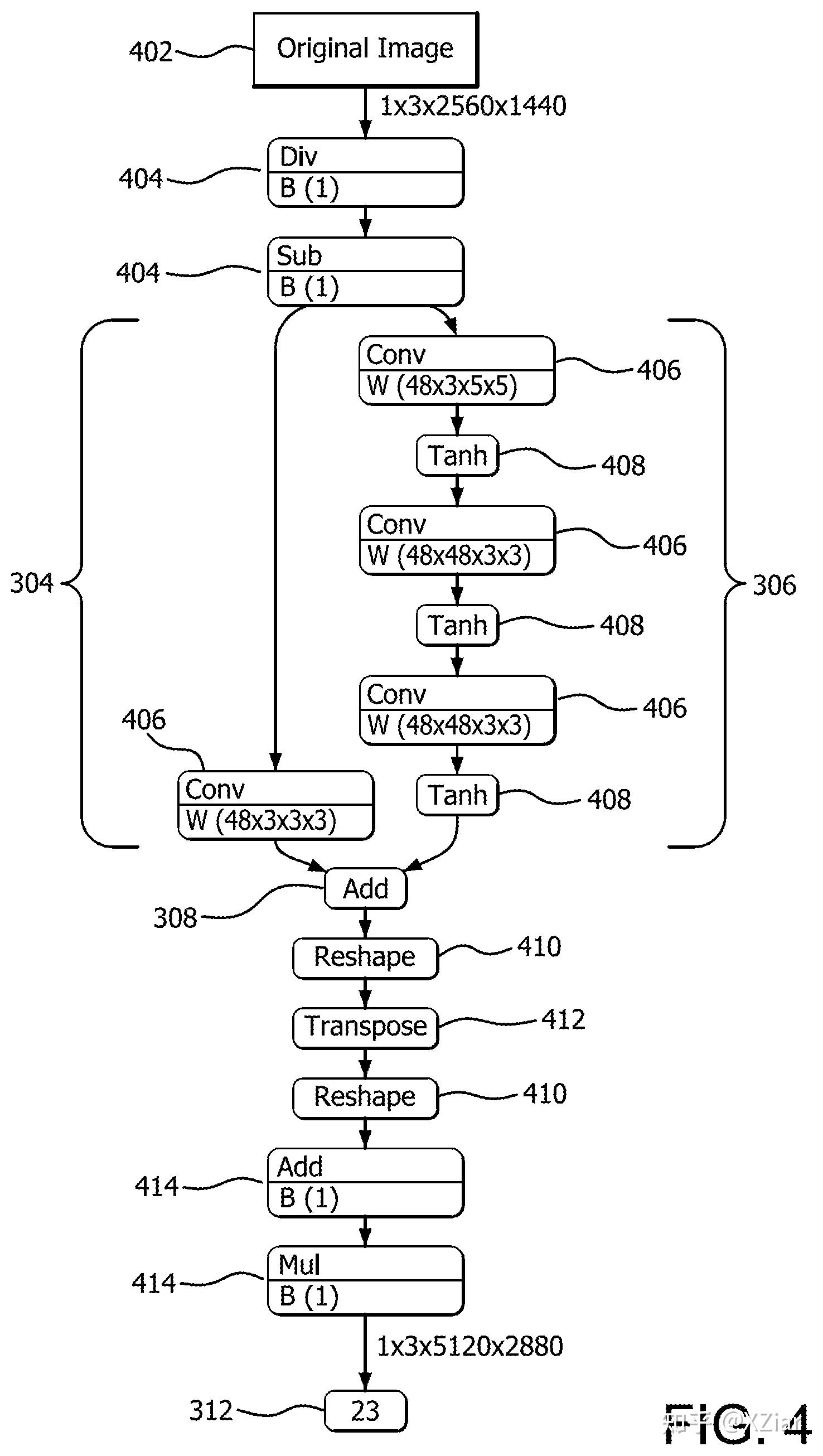
FSR现已开源,现在没有秘密了,没用ML。
之所以有2个shader dispatch,是因为分两步,第一步EASU做1-4x上采样,第二步RCAS做一个加强版锐化(大概是之前Fidelity锐化改进而来)。
EASU需要在AA和toenmapping后的线性空间,本质上是size2的lanczos。不过在这之前根据梯度估算了方向和强度(数学不好没看懂怎么推导出来的),把插值的坐标系做了小旋转,从而做到各向异性,还做了局部最值的clip。
RCAS更加粗暴,3x3的十字filter,通过周围像素最值相对0-1的距离来确定强度,这个强度计算可以近似看作 -\frac{(1-min)\cdot(1-max)}{4} ,取RGB通道最小值(负值表示锐化),不过有限制。锐化这步就没有各向异性了。
所以,就这么简单?
根据现有情报:
fsr就跑了俩computeshader,每个threadgroup内2个wavefront(应该是按RDNA算的总计32线程)去处理12x16像素大的一个block。
所以应该不是下面说到的论文里的CNN做法了。
详细的等开源了我再去分析一下shader,实在不想对着几百行asm或者DXIL去逆向算法……
广泛流传的说法是,FSR是按照AMD发布的论文来实现的,所以 以下分析建立在FSR就是专利里描述的这个模型的基础上:
按照论文里给的模型:
参考SR方向的一些发展历程:
与其FSR说是SRCNN [1] (算是CNN超分辨率鼻祖), 不如说是residual block化的ESPCN [2] ,除了标志性的sup-pixel,5-3-3的conv、tanh激活都对得上号 。
根据论文的数据,ESPCN的效果比SRCNN9-5-5的效果稍好,边缘对比度更高。更重要的是ESPCN的速度够快,毕竟就3个更小的conv。
复现代码可以直接参考高赞:
论文里用的K2,对1080P视频做4倍放大是29ms。FSR调整了层数加了residual,对应过来对单帧1080p画面放大2倍应该要8ms左右。考虑到1060的浮点吞吐差不多是K2的1.7倍,外加架构、shader等优化,理论上单帧4ms内是能做到的(这已经不是小数目了)。
但是参考AMD给的截图数据,2560x1440的目标分辨率下(720P源分辨率,压力比前面还要小),1060仅从27fps提升到38fps,不如6800XT提升大。 只能说NV卡也别抱太大希望,就算能用优化也比不上自家亲儿子 。
anandtech上传了ppt里的高清对比图,分辨率似乎是被放大了:


就算恢复到1440p,画面差异也挺明显的,而这已经是质量模式了:
- 地面细节丢失
- 远处怪物细节丢失严重
- 叶子等细节边缘也没有想象中的锐
根据SRGAN [3] 的论文,之前这些用MSE作loss function(即PSNR做评判指标)的模型有一个缺点——倾向于保留低频信息但忽视了高频信息。
改用VGG做GAN后,差异显著:虽然PSNR降了,但细节增加导致观感大幅提升(不过“过分脑补”导致的瑕疵也多了)。
当然论文里是拿自己的SRResNet做对比的,我感觉用PSNR做目标时已经过拟合,所以涂抹感比SRCNN它们严重多了。而且FSR这个小模型,怕是学不到这么复杂的生成规律……
但就算用上GAN做训练, 游戏本身的特性也会造成很多问题 ……
首先,大多数超分辨率论文都对数据集有一些隐形假设,比如ESPCN这篇里:
The task of SISR is to estimate a HR image I SR given a LR image I LR downscaled from the corresponding original HR image I HR. The downsampling operation is deterministic and known: to produce I LR from I HR, we first convolve I HR using a Gaussian filter - thus simulating the camera’s point spread function - then downsample the image by a factor of r.
作者训练时是用高斯分布来模拟点扩散函数,把大图模糊处理完再下采样得到小图的。先不说现实中小图的生成是否遵循这一原则,游戏渲染本身肯定不是这么简单……
而 数据集不满足假设的话,模型的好坏/效果也就不见得能直接套用过来了 。
当然具体到FSR的训练,正常人都会拿低分辨率和高分辨率渲染的结果做数据,至少训练集和测试集不会存在bias……
AI方面不怎么熟,就不多瞎分析了。但是 低分辨率渲染时丢失的东西是很多的 ……
比如光栅化阶段,不开MSAA的话相当于对边缘做了类似最邻近的下采样,由此带来常见的锯齿现象。
而PS阶段由于ddx/ddy就变大,mipmap倾向于采用更高级别即更低分辨率的纹理,这不但会丢失一些细节,而且mipmap的下采样通常是双线性或其他。涉及到各向异性过滤的话还更复杂一些。
这些丢失的信息可以说是找不回来的,只有脑补……
当然这个问题大家早就意识到了。于是有了TAA来做时域抗锯齿(理论上能带来超采效果,参考相机的摇摇乐),从子像素层面提升到像素层面,就是棋盘格渲染……
但这相当于把一部份空间信息平摊到时域上,单帧超分辨率丝毫利用不上这信息不说,还容易受其干扰……
可以参见DLSS2.0的技术讲解内容:
当然也可能是把FSR应用在TAA之后,那FSR就还要考虑前面引入的干扰,比如错误的鬼影、抗闪烁带来的模糊等……
事实上就算不考虑TAA,运动物体或者变化的光照本身(考虑计算精度),也会造成欠采样。
单帧超分辨率会不会不放大这些瑕疵/走样,换句话说这些模型对于动态内容的稳定性如何,就不好说了 ……
当然也有可能,拿连续画面训练时,闪烁的低分辨率图像与稳定的高分辨率图像使得模型降低了锐化的程度……
单帧超分辨率和多帧超分辨率的优劣是很重要的话题,AMD选择单帧超分辨率自然也是有自己的原因的:
- 没有足够高效的计算单元,不适合用大型模型
- 考虑覆盖更多设备,也不适合用大型模型
- 模型大了,训练、测试、优化周期也会更久
但从目前的趋势来看,AMD已经在RDNA2上添加了DP4A支持(这或许是RDNA2上效率高的因素之一,虽然Pascal也支持但这需要针对性开启的),未来加入类似tensor core的专用计算单元也不是不可能(毕竟CDNA已经加了),届时推出更大更复杂更优化的FSR2.0也完全可能。
FSR到底效果如何,只有实测才知道。
至于FSR是不是就是论文中那样的实现,等代码公布呗,毕竟是开源的。