|
|
|
相关文章推荐

|
才高八斗的柳树 · Teams团队消息无声音· 5 月前 · |
|
|
才高八斗的柳树 · 云消息队列Kafka ...· 5 月前 · |
|
|
才高八斗的柳树 · 意总理提名人被曝涉嫌美化学历校方:查无此人-新华网· 5 月前 · |
|
|
才高八斗的柳树 · 注意!谨防骗子潜入班级群疯狂行骗!-广州市增 ...· 5 月前 · |

请 登录 后了解优惠价格
点击立即购买,获取最新价格
请 登录 后了解优惠价格
点击立即购买,获取最新价格
请 登录 后了解优惠价格
点击立即购买,获取最新价格
丰富的实例类型
针对不同业务规模以及不同读写流量比例场景提供场景匹配的实例规格
构建日志分析平台
网站活动跟踪
流计算处理
数据中转枢纽


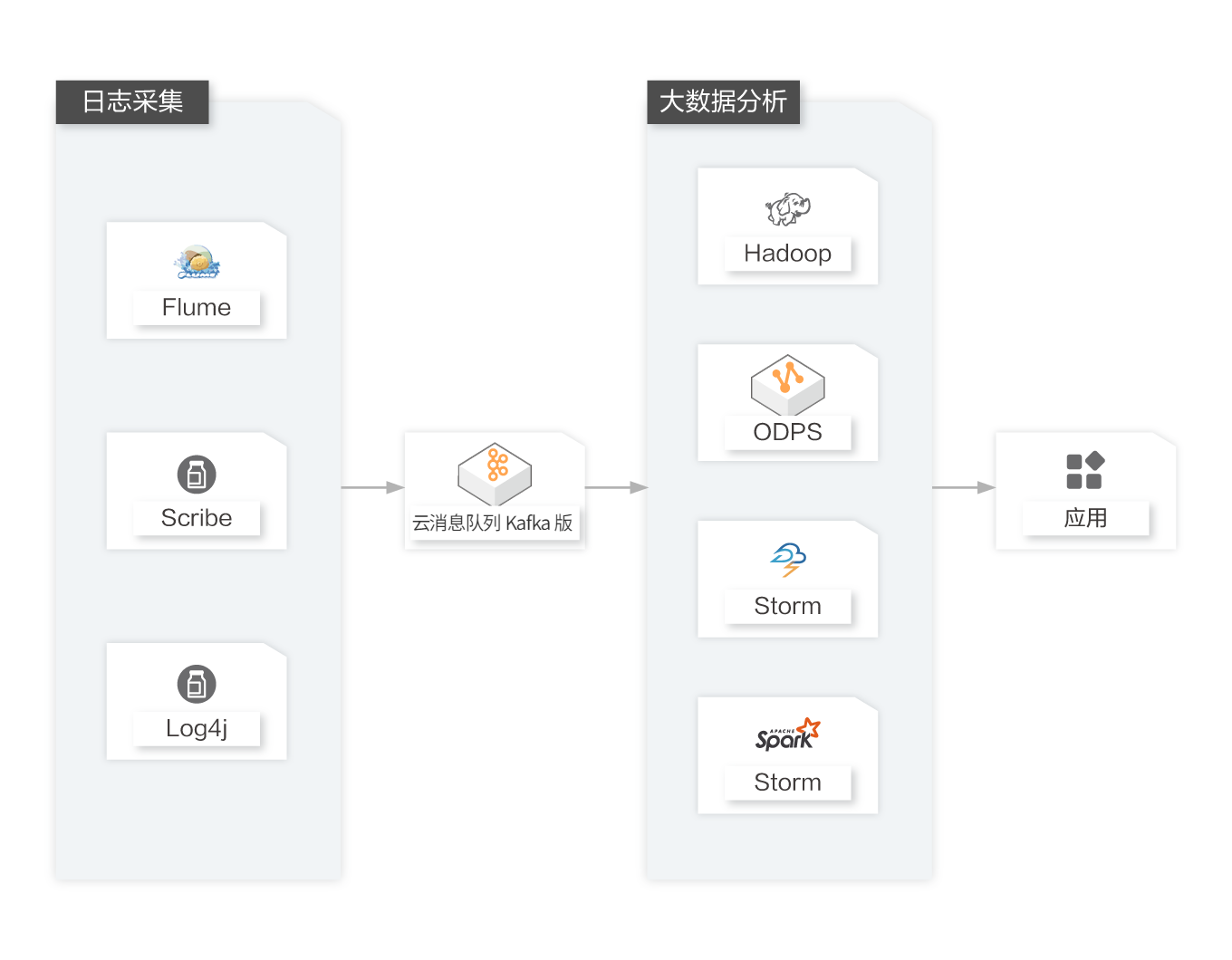
网站活动跟踪
通过云消息队列 Kafka 版可以实时收集网站活动数据(包括用户浏览页面、搜索及其他行为等)。发布-订阅的模式可以根据不同的业务数据类型,将消息发布到不同的 Topic;还可通过订阅消息的实时投递,将消息流用于实时监控与业务分析或加载到 Hadoop、ODPS 等离线数据仓库系统进行离线处理。
能够解决
高吞吐
网站所有用户产生的行为信息极为庞大,需要非常高的吞吐量来支持;
大数据分析
可对接 Storm/Spark 实时流计算引擎,亦可对接 Hadoop/ODPS 等离线数据仓库系统;
推荐搭配使用
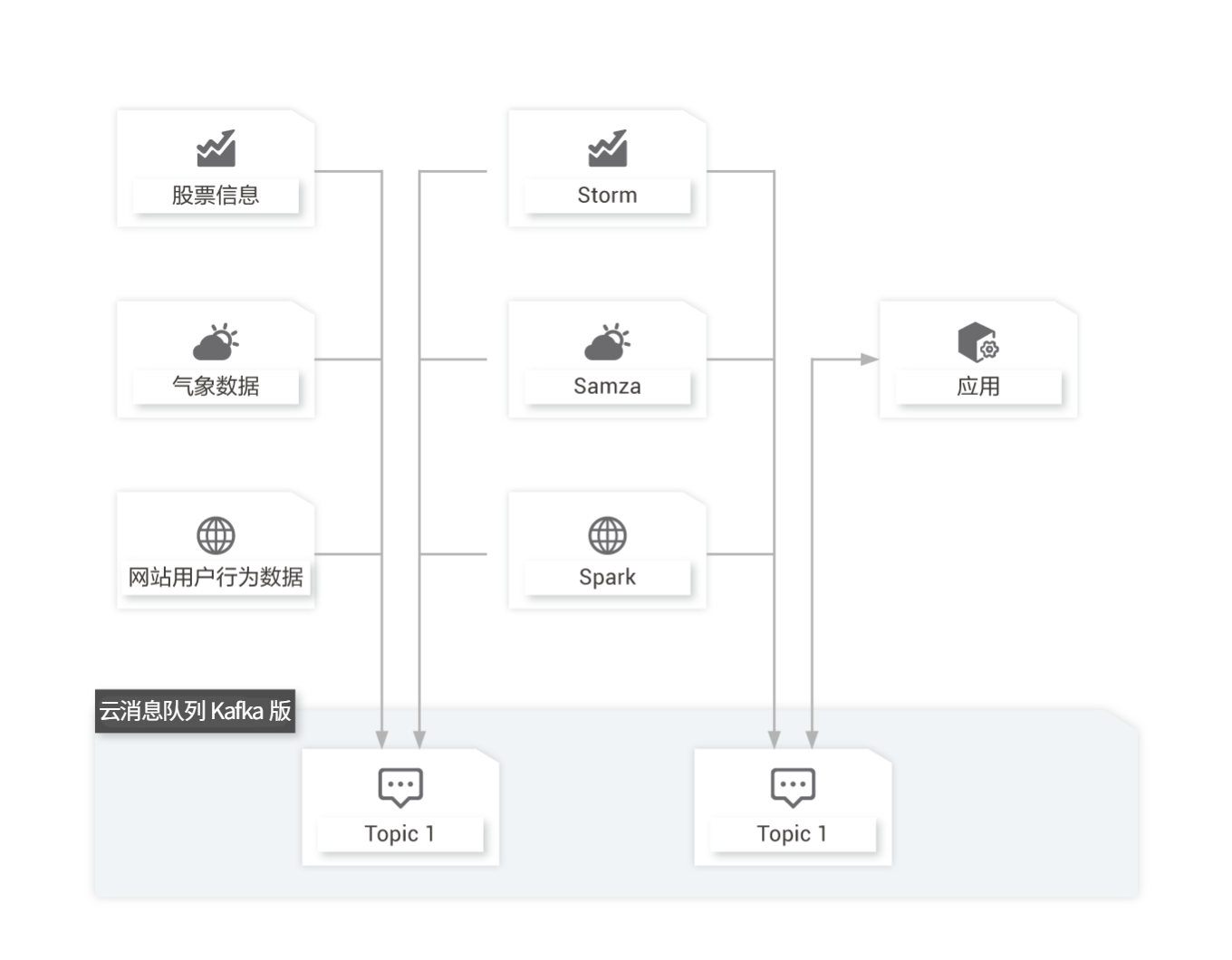
流计算处理
股市走向分析、气象数据测控、网站用户行为分析等领域,由于数据产生快、实时性强、数据量大,所以很难统一采集并入库存储后再做处理,这便导致传统的数据处理架构不能满足需求。而云消息队列 Kafka 版以及 Storm/Samza/Spark 等流计算引擎的出现,可以根据业务需求对数据进行计算分析,最终把结果保存或者分发给需要的组件。
能够解决
高可扩展性
由于数据产生非常快且数据量大,需要非常高的可扩展性;
流计算引擎
可对接开源 Storm/Samza/Spark 以及 EMR、Blink、StreamCompute 等阿里云产品;
推荐搭配使用

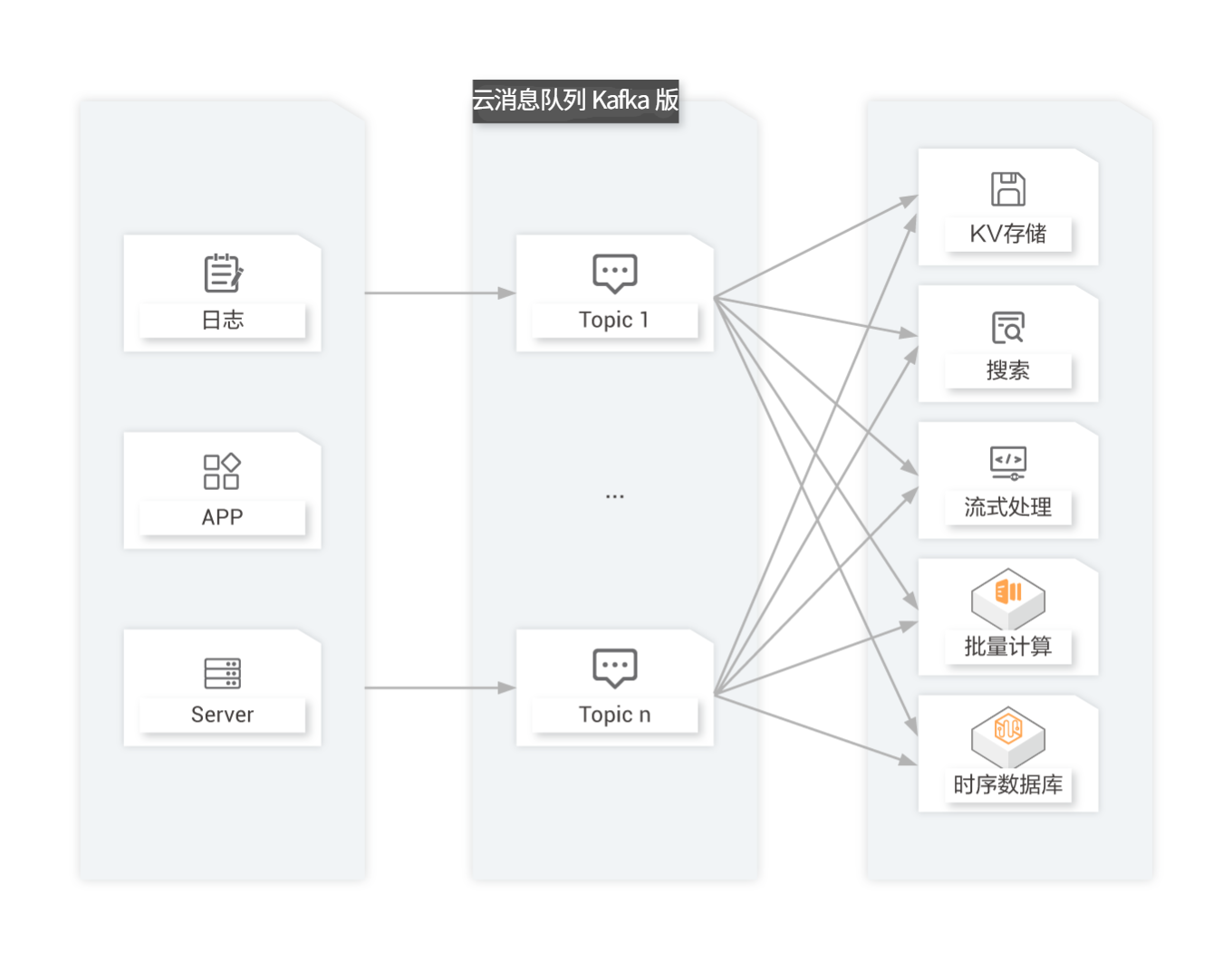
数据中转枢纽
近年来KV存储(HBase)、搜索(ElasticSearch)、流式处理(Storm/Spark Streaming/Samza)、时序数据库(OpenTSDB)等专用系统应运而生,产生了同一份数据集需要被注入到多个专用系统内的需求。利用云消息队列 Kafka 版作为数据中转枢纽,同份数据可以被导入到不同专用系统中。
能够解决
一对多消费模型
发布/订阅模型,支持同份数据集能同时被消费多次;
同时支持实时和批处理
本地数据持久以及PageCache,在无性能损耗的情况下能同时传送消息到实时和批处理消费者;
推荐搭配使用





查看详情
2018-03-29 新产品
阿里云消息队列 Kafka 公测发布
查看详情
2018-05-31 新功能/规格
消息队列 Kafka 支持 VPC 专享实例输出
查看详情
2018-07-12 新地域/新可用区
消息队列Kafka-华南 1发布
查看详情
2018-08-29 新功能/规格
消息队列Kafka 经典网络支持
查看详情
2019-04-25 新功能/规格
Kafka消息查询能力发布
查看详情
2020-09-27 新功能/规格
Kafka 专业版系列支持高读版实例规格
查看详情
2020-11-20 新功能/规格
Kafka 支持 MaxCompute Connector
查看详情
2020-12-14 新功能/规格
Kakfa 支持 FC Connector
查看详情
2021-03-03 新功能/规格
消息队列 Kafka 支持 OSS Connector,实现数据转出 OSS
查看详情
2021-03-15 新功能/规格
Kafka 支持 Mysql Connector
查看详情
2021-03-16 新功能/规格
Kafka 专业版支持大容量高效云盘存储规格
查看详情
2022-05-20 新功能/规格
迁移路由功能发布
查看详情
2022-06-10 新功能/规格
Serverless 版本公测
查看详情
2022-06-13 新功能/规格
Prometheus监控支持
查看详情
2022-07-14 新功能/规格
资源组支持
查看详情
查看全部日志

