不长的编码生涯,看到无数概念和词汇:面向对象编程、过程式编程、指令式编程、函数式编程、防御式编程、流式编程、响应式编程、契约式编程、进攻式编程、声明式编程……有种生无可恋的感觉。
本文试图加以汇总和整理,搞清除某个概念所指,并大致加以区分。虽然,严格区分不同概念/名词之间的区别,对于指导我们编程的实战意义不是特别大。
注:资源源自于互联网,仅有部分加上参考来源。
比如,PHP可以面向过程编程,也可以面向对象编程。任何语言在设计时都会倾向某些范式,同时回避某些范式,由此形成不同的语法特征和语言风格。抽象的编程范式须要通过具体的编程语言来体现。范式的世界观体现在语言的核心概念之中,范式的方法论体现在语言的表达机制中。一种语言的语法和风格与其所支持的编程范式密切相关。
一种编程范式,与面向对象编程(OOP)和过程式编程(Procedural programming)并列。函数式编程也遵从 数据结构+算法 的约束。
函数式编程关心类型(代数结构)之间的关系,关心的是结构、数据的映射或者变换;
函数式编程中的lambda可以看成是两个类型之间的关系,一个输入类型和一个输出类型。lambda演算就是给lambda表达式一个输入类型的值,则可以得到一个输出类型的值,这是一个计算,计算过程满足 -等价和 -规约。
函数式编程的思维就是如何将这个关系组合起来,用数学的构造主义将其构造出你设计的程序。
函数式编程即为:构造类型的映射关系。
函数式编程,设计函数的复合与代数数据结构,提供对并发计算的支持,这是其他编程范式难以实现的。
用Haskell来说,这个关系就是运算符(->),其表示一个lambda演算的类型,在值的层面和符号’'一起构造一个lambda表达式。空类型()、积类型(a, b)与和类型Either a b是最基本的数据类型的构造,其和curry和uncurry一起,还有米田定理、伴随函子,使得可以构造任意复杂的数据类型和程序。比如Functor、Applicative、Monad/Comonad、Limit/Colimit、End/Coend、Left Kan Extenstion/Right Kan extension等。
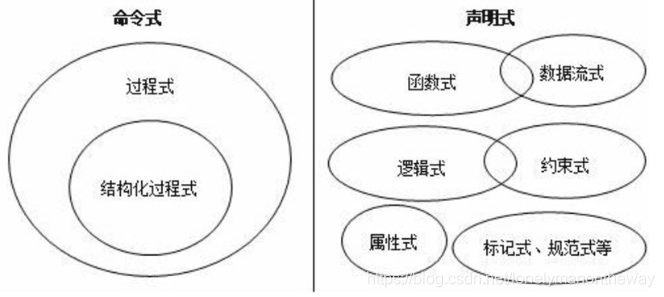
命令式编程关心解决问题的步骤;
在函数式中,函数是一等公民,函数能作为变量的值,函数可以是另一个函数的参数,函数可以返回另一个函数等。
函数式编程关注的是:describe what to do, rather than how to do it。故而,过程式编程范式又叫 Imperative Programming –
指令式编程
,函数式编程范式叫做 Declarative Programming –
声明式编程
。
纯函数三个重要的特点:
-
函数的结果只受函数参数影响
-
函数内部不使用能被外部函数影响的变量
-
函数的结果不影响外部变量
stateless:函数不维护任何状态。函数式编程的核心精神是 stateless,简而言之就是它不能存在状态,你给我数据我处理完扔出来,里面的数据是不变的。
immutable:输入数据是不能动的,动了输入数据就有危险,所以要返回新的数据集。
-
没有状态就没有伤害
-
并行执行无伤害
-
Copy-Paste 重构代码无伤害
-
函数的执行没有顺序上的问题
-
惰性求值。这需要编译器的支持。表达式不在它被绑定到变量之后就立即求值,而是在该值被取用的时候求值。也就是说,语句如 x:=expression; (把一个表达式的结果赋值给一个变量) 显式地调用这个表达式被计算并把结果放置到 x 中,但是先不管实际在 x 中的是什么,直到通过后面的表达式中到 x 的引用而有了对它的值的需求的时候,而后面表达式自身的求值也可以被延迟,最终为了生成让外界看到的某个符号而计算这个快速增长的依赖树。
-
确定性。所谓确定性,就是像在数学中那样,f(x) = y 这个函数无论在什么场景下,都会得到同样的结果,这个我们称之为函数的确定性。而不是像程序中的很多函数那样,同一个参数,却会在不同的场景下计算出不同的结果。所谓不同的场景,就是我们的函数会根据运行中的状态信息的不同而发生变化。
函数式编程常用技术:
-
first class function(头等函数) :这个技术可以让你的函数就像变量一样来使用。也就是说,你的函数可以像变量一样被创建、修改,并当成变量一样传递、返回,或是在函数中嵌套函数。
-
tail recursion optimization(尾递归优化) : 递归的问题:递归很深时,会出现StackOverflow异常;即使没有达到抛出异常的条件,Stack过深时,也会导致性能大幅度下降。因此,使用尾递归优化技术——每次递归时都会重用 stack,这样能够提升性能。当然,这需要语言或编译器的支持。Python不支持。
-
map & reduce :函数式编程最常见的技术就是对一个集合做 Map 和 Reduce 操作。这比起过程式的语言来说,在代码上要更容易阅读。(传统过程式的语言需要使用 for/while 循环,然后在各种变量中把数据倒过来倒过去的)这个很像 C++ STL 中 foreach、find_if、count_if 等函数的玩法。
-
pipeline(管道):这个技术的意思是,将函数实例成一个一个的 action,然后将一组 action 放到一个数组或是列表中,再把数据传给这个 action list,数据就像一个 pipeline 一样顺序地被各个函数所操作,最终得到我们想要的结果。
-
recursing(递归) :递归最大的好处就简化代码,它可以把一个复杂的问题用很简单的代码描述出来。注意:递归的精髓是描述问题,而这正是函数式编程的精髓。
-
currying(柯里化) :将一个函数的多个参数分解成多个函数, 然后将函数多层封装起来,每层函数都返回一个函数去接收下一个参数,这可以简化函数的多个参数。在 C++ 中,这很像 STL 中的 bind1st 或是 bind2nd。
-
higher order function(高阶函数):所谓高阶函数就是函数当参数,把传入的函数做一个封装,然后返回这个封装函数。现象上就是函数传进传出,就像面向对象对象满天飞一样。这个技术用来做 Decorator 很不错。
注:菜逼我水平有限,还不能理解函数式编程和范畴论有什么关系;但是总是在讲述函数式编程的文章中看到
范畴论
。
参考《代码大全》第二版—第八章,防御式编程。
防御式编程:对代码的健壮性极其重视,以测试驱动编程,思考可能发生的问题提前进行预防。以异常处理为例,简单粗暴的try…catch加Exception把所有异常都包起来,简单省事。这种方式最主要的问题在于:
Exception会吃掉所有可以处理的异常,使得对于某些特定异常无法捕获,因为对于不同的异常可能需要做不同的处理,有些可以在本函数内处理掉,有些需要提示用户(例如文件不存在,网络无法访问),有些需要告诉上一层代码该如何处理,所有这些在直接用Exception处理异常时都无法做到,简而言之就是无法做到异常的精细化处理;
怎么做才好呢?具体如何处理这些没有完全标准的答案,软件设计本来就没有一劳永逸的解决方案,最关键的在于掌握好基础知识,因地制宜地采取措施。基本的实现软件健壮性的技术有以下几种:
-
断言
-
错误处理
-
异常
-
从设计上简化异常处理的技术;隔离程序
-
辅助调试的代码(print打印之类的小段函数)
断言,是一种在开发阶段使用的,让程序在运行时进行自检的代码,断言为真,那么程序运行正常,断言为假,那么程序运行异常退出。实际上,先断言、后处理错误,而断言是在开发环境中的,正式上线后是不会有断言的。断言是给程序员看的,是用来查找bug。
所以应该在内部逻辑的问题上使用断言去检查一些理论上不可能发生的情况,因为如果发生就说明内部逻辑有问题,也就是有bug。
断言:判断一个布尔表达式的语句,如果这个布尔表达式为真,不会有任何效果,但是如果为假,根据不同实现技术会出现不同的效果。以Java语言为例,Assert就是断言最好的例子。
举个简单的例子,例如某个函数有一个参数,这个参数是某数据流,这个数据流是软件下层通过读取文件传进来的,调用这个函数的时候,内部逻辑已经确定是正确读取到了文件,否则是不会调用这个函数的,那么,一般会在函数开头,对这个参数用断言加以检查,如果不幸,出现问题,就说明内部逻辑错了(读取失败仍然调用?内存被意外析构?),这就是典型的通过断言查找程序bug的例子。
断言是用来检测程序内部逻辑的,如果是和外部有数据交流,就不是断言的范畴,因为外部的情况,程序是不能假定的,既然不能假定,就无法设断言,那应该是错误处理或者异常的范畴。因此,理解断言的关键点在于,作用于内部逻辑,用来查找bug。通常,现代编译工具都会在编译release版本软件的时候去掉异常,因为异常是给程序员看的。
错误处理可以说是软件健壮性的核心,程序员在编写软件的时候,应该尽可能的预测到可能发生的错误,并对这些错误进行处理,正常情况下要对这些错误进行分类,重大错误,这类错误一般不可恢复,通常的做法都是报告后直接退出,类似windows中的蓝屏,普通程序在遇到堆栈溢出,内存不足等错误时也是会这样做;