


带你认识图像检索系统

1 图像检索系统能做什么?
从90年代开始,出现了对图像的内容语义,如图像的颜色、纹理、布局等进行分析和检索的图像检索技术,即基于内容的图像检索(Content-based Image Retrieval,简称CBIR)技术。CBIR属于基于内容检索(Content-based Retrieval,简称CBR)的一种,CBR中还包括对动态视频、音频等其它形式多媒体信息的检索技这里我们主要说 基于内容的图像检索系统 ,在现在以视频,图像为主流传播媒介的互联网,大数据时代,图像检索是有非常多的应用的,比如我们熟知的:
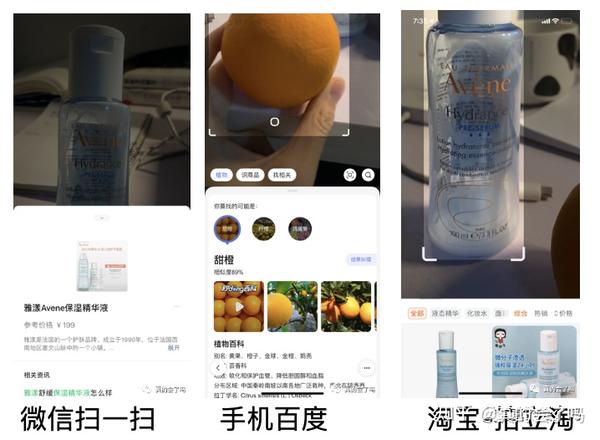
能够满足我们认知的需求,微信扫一扫,百度识图(这张图片中的内容是什么,是什么花,是什么树),阿里拍立淘/京东拍照购,我们见到的服饰等一些商品,用详细文字描述去搜索,相对困难,拿着商品的图片去搜索就容易很多~(是不是带你解锁了一项移动app的新技能?)
除了这些我们可以看得见的产品,还有很多是我们看不到的,在企业内部使用的功能,具体有那些用途这里总结了一张图,如下图所示:
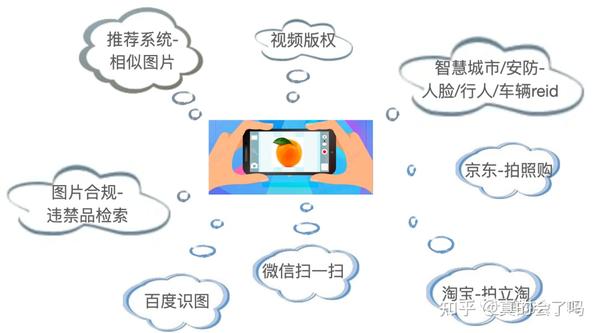
比如,前段时间上了热搜的大厂们互相pk的视频版权保护(版权识别),推荐系统中的相同图像/视频。相似图像/视频推荐(推荐池优化),安防领域的人脸/行人重识别,还有一些小众的安全场景的违禁品的检索等等等。。。。
2 如何搭建图像检索系统 ?
2.1检索架构
下面我们拿商品检索来举例:
检索系统主要完成的功能是 ,输入一张图片,从商品库中找出图片中的商品 ,并返回主图以及商品链接,检索服务主要分为两部分工作,如下图所示:
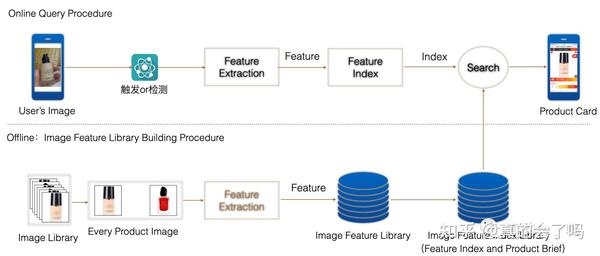
主要分为在线和离线两部分:
1 在线部分:
在线部分主要是拿到图片之后,进行目标检测和类目预测(如果识别的物品比较多,例如万物识别,类目检测和预测会比较复杂,这里暂时不说这种情况),根据检测框将图片中的商品抠出来,使用不同类别的检索模型进行特征提取,将提取好的特征,和对应检索库里的特征进行比对,找到与当前特征最近的商品图片,并将商图片与链接返回
2 离线部分:
离线部分主要是检索库构建部分,主要是收集商品图片,并进行特征提取后入库,以及索引构建这几部分(索引构建是为了加速特征比对的速度,以及优化特征存储空间)
2.2 模型训练
在线检索部分主要有 检测模型 + 检索模型 组成。
2.2.1 检测模型
数据上还是已公开数据为主,业务场景相关数据集合为辅。当系统初期,任务相对简单,检测模型往往需要承担目标检测+类目预测功能,这时在一些Yolo系列的开源模型上微调,是能解决大部分问题,但是随着系统类目的增加,可能会出现两种挑战:
A:如何使检测模型很好的支持类别的增加还是很值得研究的
B:类目预测如果做到精准
2.2.2 检索模型
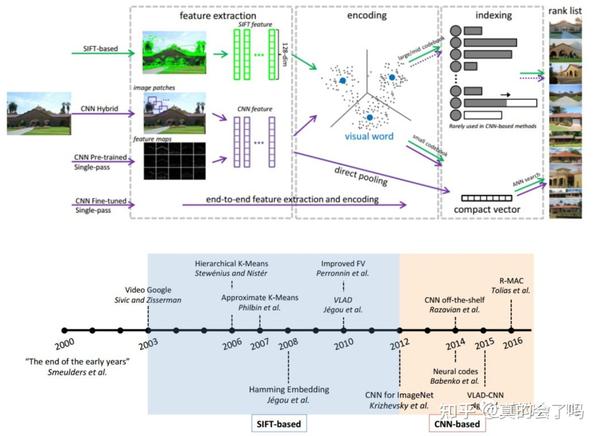
(1) 检索模型的发展历程
2012年以前,检索模型的特征还是以基于sift等局部特征点+特征描述符+编码本为主,这种方式虽然流程相对繁琐,但至今也有很多场景还延用了这种方法,2012年之后,随着深度学习的兴起,基于CNN的全局特征快速的在图像检索领域被应用,后面我们主要介绍基于CNN的图像检索特征。
(2) 兵马未动,粮草先行-检索模型之数据准备

公开数据: 公开数据集合往往是按照不同垂类划分的,我们照相关的论文或者比赛,来收集公开数据集合,这里拿一个垂类来举例,假设我们需要收集服饰场景相关的数据集合,公开数据集合我们可以找到(如果商用,这里要注意一些商用的条款,自己学习是没啥问题的):
A:DeepFashion:包含一些实拍图和商品图的图片对,应该是几万对左右
B:Kaggle/天池的某些比赛数据,应该有那么2-3个比赛可以搜一搜
自有数据: 自有数据集主要是跟所处业务相关的数据,这里主要分为两个部分:
A: 业务场景相关测试集 ,业务场景相关测试集主要用来评估模型在实际使用场景中的效果
B: 模型训练需要的训练集 ,训练集合是我们模型训练使用的数据,一般做商品检索商品图就是很好的训练数据,在业务上线后,如何获取高质量的业务场景的优化模型也是很重要的哦~
(3)检索模型之建模
检索模型的目标是一个同款/相似款商品提取的特征尽量相近,不同款商品提取的特征之间距离尽量远,主要的建模方式包含两种:
A: 分类模型
图像分类模型主要是将一个商品或者一种服饰类型来当作一个类别,然后将分类层的前一层当作该图片的特征(embedding的特征)用来做检索。主要的流程可以参考下面的图片:
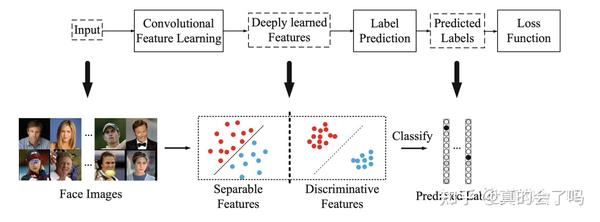
B: 度量学习
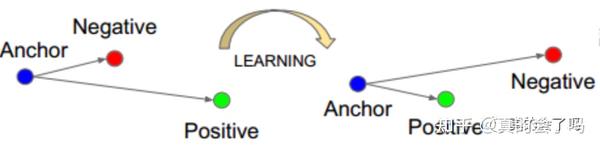
图像检索是一个特征比对的问题,度量学习的loss的训练目标往往是使得同类别的图片的特征更相近,不同类别的更远,优化方式更加直接,主要的流程见下图:

举一个典型的例子是TripletLoss,输入为图像的三元组,Anchor,Positive,Negative,优化的目标是使得Anchor与Positive的特征尽量相似(两个的相似度后面称为Dap),Anchor与Negative(后面也称为Dan)的特征距离尽量不同,这种方式也有缺点,由于数据不可能是完全干净的,所以当遇到脏数据是,很容易使得训练不稳定,所以要注意一些hardcase的挖掘以及冗余策略
(4)检索模型优化
数据方面:
A:是如何获得更多的数据,无论是通过爬虫,公开数据集合的收集都是可以的
B:数据清洗,可以借助一些外力的方法来进行数据清洗
例子1:通过聚类+人工过滤离群点的方式去除类内噪声
例子2: 通过服饰检测模型去掉训练集合中的非服饰/服饰局部特写图。
例子3: 通过图片哈希以及商品标题信息将不同的skuid下的同一个商品进行合并
Loss方面:
A:分类
提高特征的判别能力:
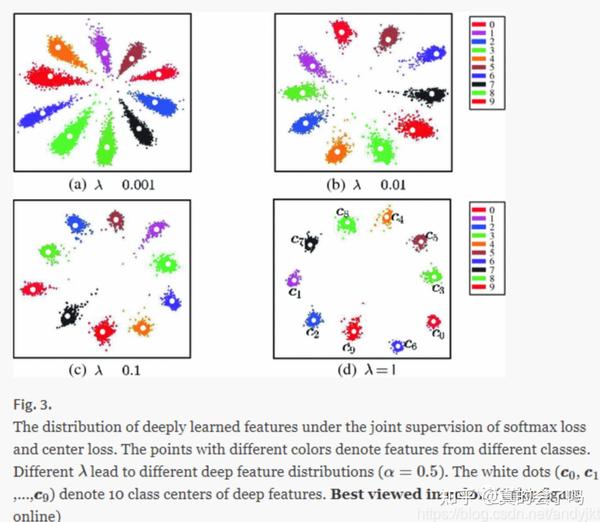
分类的建模方式我们可以考虑,加入人脸相关的Loss,centra loss、arcFace、sub-Arcface等,提高类内的聚合程度的约束,下图是是一个简单的事例:
B: 度量学习
提高训练的稳定性:
主要是一些case挖掘相关的策略,比如FaceNet中的semi-hard策略,以及circleloss中的提出的针对Dan与Dap惩罚不灵活的问题进行了优化。
C: Multi-loss
提高特征的判别能力:
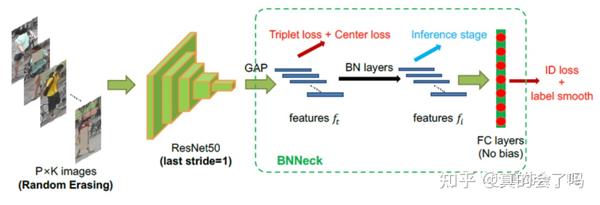
可以参考行人reID方面比较成熟的pipline:
D: Multi-task
提高特征的判别能力-对某些固定细节的关注:
某些特殊的垂类/当数据量不是很充裕的时候,我们可以通过增加特定任务的方式是的模型关注到固定的区域,比如,品牌logo这个方面,我们可以在已有学习任务增加品牌的分类任务
E: Backbone方面
Resnet、resnext,se-resnext,resnest系列
Efficient系列
Vit,Deit,Swin-transformer系列:依赖大量数据(可能百万以上更能体现优势)
2.3 检索框架
这里也是比较大的一块内容,后面可以按照索引类型单独写一篇文章。
从实用的角度来看,在大部分情况下(百万级检索库+512维特征)开源检索框架Faiss是能够满足我们日常需求的。当数据非常大,增删改需求多并且对实时性要求高的情况下,这部分需要配合研发环境自研。
2.4 检索系统发展方向
2.4.1 自监督
随着transformer+自监督在cv领域越来越火,自监督pretrain模型在图像检索领域会有一个不错的应用,虽然目前大部分transformer+自监督在小数据上finetune上效果不是很好,但是随着技术的发展,自监督应该还是大有可为的
2.4.2 多模态
随着电商的发展,商品数据越来越多,图文信息也更加丰富,商品标题等文本信息能不能帮助检索模型学到更加鲁棒且判别性更好的特征呢?这个最近已经有一篇论文了,也可以看看
2.4.3 系统自反馈以及进化
如何实现一个业务-数据-模型的闭环系统,业务场景的数据能够帮助模型朝着我们预期的方向前进(当前阶段可能加入人工的定期check才是一个可行+合适的方案),并且对较小的业务变化有一定的适应能力,可能也是未来检索系统发展的一个方向
3 参考资料
论文:
A Discriminative Feature Learning Approach for Deep Face Recognition
FaceNet: A Unified Embedding for Face Recognition and Clustering
Bag of tricks and a strong baseline for deep person re-identification
SIFT Meets CNN:A Decade Survey of Instance Retrieval
https://www. zhihu.com/topic/1960159 3/hot
