广义线性混合模型GLMM
(
Generalized Linear Mixed Model
),是
广义线性模型GLM
和
线性混淆模型LMM
的扩展形式,于二十世纪九十年代被提出。GLMM因其借鉴了混合模型的思想,其在处理
纵向数据
(
重复测量资料
)时,被认为具有独特的优势。GLMM不仅擅长处理重复测量资料,还可以用于
任何层次结构的数据
(因为本质上又是
多水平模型
)。
提到GLMM,有必要先介绍几个容易混淆的概念:GLM、LMM、MLM、GMM 和GEE。
相关模型简介
广义线性模型 GLM
广义线性模型GLM,是大家经常接触的概念了,比如经典的Logistic模型。GLM是普通线性模型的扩展形式,由于普通线性回归的因变量必须服从正态分布,而实际问题中经常会遇到分类问题或计数问题的建模,GLM采用连接函数(Link Function),将因变量的分布进行了扩展,使得因变量只要服从指数分布族即可(如正态分布,二项分布,泊松分布,多项分布等)。
GLM 可以分解为 Random Component、System Component 和 Link Function 三个部分。
Random Component
为残差部分,取决于因变量的分布;
System Component
为预测部分,又称 linear predictor,是拟合的关键;
Link Function
为连接变化函数,用于将指数分布族转化成正态分布,或者说,对预测结果进行非线性映射(建立 linear predictor与 label 之间的变换关系),是LM成长为GLM的关键环节。
需要强调的是,link function 是从 label 映射到 linear predictor的过程,link function的反函数称为响应函数 response function。响应函数 把 linear predictor 直接映射到了预测目标 label。较常见的link function如 logit函数(又称log-odds);较常用的响应函数如 logistic(又称sigmoid,是二分类中的相应函数)和 softmax(是sigmoid的扩展形式,用于多分类问题),这两个都是 logit 的反函数。
以
Logistic
为例,如下(本部分摘自:
GLM(广义线性模型) 与 LR(逻辑回归) 详解
):
最后啰嗦一句,因变量为Bernoulli Distribution也就是对二分类问题建模,因变量为Binomial Distribution也就是对多分类问题建模,因变量为Poisson Distribution也就是对计数问题建模(注意区分计数问题和多分类问题)。
本文讲得比较简略,有两篇博客对GLM总结得比较棒,给出链接如下,值得一读:
GLM(广义线性模型) 与 LR(逻辑回归) 详解
广义线性模型GLM
线性混合模型 LMM
本部分参考自:《高级医学统计学》和
Wiki: Mixed_model
线性混合模型LMM,又称混合线性模型MLM、混合模型MM、多水平模型MLM、随机系数模型RCM、等级线性模型HLM 等。首先看一下 Wiki上对混合模型MM的介绍:A
mixed model
(or more precisely
mixed error-component model
) is a statistical model containing both
fixed effects
and
random effects
. (注意:fixed在这里译为固定,不同于mixed混合)
混合模型擅长于处理纵向数据(重复测量数据)和有缺失的数据,并且往往优于ANOVA等方法。
在混合模型中,需要区分两个概念:
random effects
与
random errors
。
以矩阵定义混合模型,可以写成:
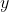 是观测值的向量,服从多元正态分布,且平均值可以表示为
是观测值的向量,服从多元正态分布,且平均值可以表示为

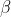 是固定因子的效应值(与X对应的固定效应参数向量)
是固定因子的效应值(与X对应的固定效应参数向量)
 是随机因子的效应值,服从多元正态分布,且平均值为
是随机因子的效应值,服从多元正态分布,且平均值为
 ,它的方差为
,它的方差为

 是残差的向量矩阵,它的平均值为
是残差的向量矩阵,它的平均值为
 ,它的方差为
,它的方差为

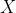 为
固定效应
自变量的设计矩阵(可包括连续性变量和分类变量,甚至可包含交互项或二次项等),
为
固定效应
自变量的设计矩阵(可包括连续性变量和分类变量,甚至可包含交互项或二次项等),
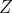 为
随机效应
变量构造的设计矩阵。
为
随机效应
变量构造的设计矩阵。
[ 注意:切勿将固定效应狭义理解为主要变量,而应该是所有可能的解释变量(如分组变量和时间变量),包括这些变量之间的交互项。而随机效应则是假定的随机效应部分(这部分的意义应当从
多水平模型
的角度来理解了) ]
该模型为固定效应
 和随机效应
和随机效应
 的混合,且固定效应和随机效应均与响应变量为线性关系,因此称为线性混合模型。
的混合,且固定效应和随机效应均与响应变量为线性关系,因此称为线性混合模型。
注意:当满足球形检验时,重复测量资料的线性混合效应模型可退化为一般线性模型。
混合模型的假定为
 ,
,
 ,其中
,其中
 ,即两者的协方差为0(二者互相独立)。可以给出Henderson's "mixed model equations" (
MME
):
,即两者的协方差为0(二者互相独立)。可以给出Henderson's "mixed model equations" (
MME
):
The solutions to the MME,
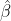 and
and
 are best linear unbiased estimates (BLUE) and predictors (BLUP) for
and
are best linear unbiased estimates (BLUE) and predictors (BLUP) for
and
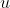 (此处的
指的就是
,有的版本习惯使用
来替代
字符), respectively. 拟合混合模型还可以使用 EM 算法。
(此处的
指的就是
,有的版本习惯使用
来替代
字符), respectively. 拟合混合模型还可以使用 EM 算法。
工具包:R (nlme包中的lme方法,或 lme4 包中的lmer方法), Python (statsmodels包)。
多水平模型 MLM
本部分参考自:《高级医学统计学》
多水平模型其实和线性混合模型LMM是等价的,只是理解的角度不同而已。MLM是从模型组建的多个水平来理解,关注构建过程;LMM则仅关注模型构建的结果(固定效应部分+随机效应部分)。多水平模型可以分层表述,然后整合成一个公式(即等价于LMM的公式)。下面以两水平模型为例,进行解读。
一个包含“2个水平1的解释变量(x和z)和1个水平2的解释变量(w)”的两水平模型可以表述为:
其中,
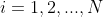 (N是总样本量),
(N是总样本量),
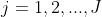 (J是水平2的解释变量的w的取值个数,假定w为分类变量)。则
(J是水平2的解释变量的w的取值个数,假定w为分类变量)。则
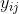 表示在变量w的第 j 种取值的情况中的第 i 个个体的结局测量值。第1水平方程(第1个等式)中,截距
表示在变量w的第 j 种取值的情况中的第 i 个个体的结局测量值。第1水平方程(第1个等式)中,截距
 带有下标 j,表示其值随 w 的取值变化而变化;系数
带有下标 j,表示其值随 w 的取值变化而变化;系数
 带有下标 j,表示变量
带有下标 j,表示变量
 对
的效应随 w 的取值变化而变化;而系数
对
的效应随 w 的取值变化而变化;而系数
 不带有下标 j,表示变量
不带有下标 j,表示变量
 对
的效应不随 w 的取值变化而变化。在两个第2水平方程(第2、3个等式)中,第1水平的回归系数变成了因变量。关于其他参数如e和u的规则,此处跳过(感兴趣的可查阅统计书《高级医学统计学》)。
对
的效应不随 w 的取值变化而变化。在两个第2水平方程(第2、3个等式)中,第1水平的回归系数变成了因变量。关于其他参数如e和u的规则,此处跳过(感兴趣的可查阅统计书《高级医学统计学》)。
从概念上来讲,该模型的建立是从顶向下的,先进行第1水平的参数计算(通过枚举 j 来获得 j 组回归系数
和
);然后使用估计的回归系数进行第2水平的参数计算,生成多个第2水平的方程。这种计算步骤是传统的计算方法,现在的计算其实是同步进行的。
如果将两个第2水平的方程代入到第1水平的方程中,可以得到:
这是一个组合模型,该式右边分为两部分,第一个括号部分是各个解释变量及其交互项产生的效应,第二个括号部分是复合残差结构。第一部分便可对应为LMM中提到的
固定效应
部分,第二部分可对应为LMM中提到的
随机效应
部分(包括纯粹残差项)。
更一般地,两水平模型可表述为:
将Q个第2水平的方程代入到第1水平的方程中,可以得到:
该组合模型由两部分组成:
固定效应
部分(第一个括号中)和
随机效应
部分(第二个括号中)。
MLM的参数估计十分复杂,模型构建的步骤也比较繁琐,此处都不进行讲解。
高斯混合模型 GMM
高斯混合模型GMM(Gaussian Mixed Model)指的是多个高斯分布函数的线性组合,理论上GMM可以拟合出任意类型的分布,通常用于解决同一集合下的数据包含多个不同的分布的情况(或者是同一类分布但参数不一样,或者是不同类型的分布,比如正态分布和伯努利分布)。
设有随机变量X,则混合高斯模型可以用下式表示:
称
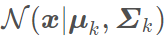 为混合模型中的第k 个分量(component)。比如有两个聚类,可以用两个二维高斯分布来表示,那么分量数K=2
为混合模型中的第k 个分量(component)。比如有两个聚类,可以用两个二维高斯分布来表示,那么分量数K=2
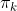 是混合系数(mixture coefficient),且满足:
是混合系数(mixture coefficient),且满足:
实际上,可以认为
就是每个分量
的权重。
GMM常用于聚类。如果要从 GMM 的分布中随机地取一个点的话,实际上可以分为两步:首先随机地在这 K 个 Component 之中选一个,每个 Component 被选中的概率实际上就是它的系数
,选中 Component 之后,再单独地考虑从这个 Component 的分布中选取一个点就可以了──这里已经回到了普通的 Gaussian 分布,转化为已知的问题。
可以用EM算法估计GMM参数。
此处介绍较为简略,有一篇博客讲得比较好,值得参考:
高斯混合模型(GMM)及其EM算法的理解
另外,还有个概念叫广义矩方法,也简称GMM,其与GEE密切相关,可参考:
广义矩方法(GMM)和广义估计方程(GEE)到底有什么区别
广义估计方程
GEE
广义估计方程(
generalized estimating equation,
GEE)
用于估计广义线性模型的参数(其中线性模型的结果之间可能存在未知的相关性)。于1986年由Liang和Zeger首次提出,是在广义线性模型和
重复测量数据
中,运用
准似然估计方法
估计参数的一种用于分析
相关性数据
的回归模型。
详细介绍请参考这篇博客:
广义估计方程GEE
广义线性混合模型 GLMM
广义线性混合模型GLMM,可以看做是线性混合模型LMM的扩展形式,使得因变量不再要求满足正态分布;也可以看作是GLM的扩展形式,使得可以同时包含
固定效应
和
随机效应
。
回顾一下,LMM模型的一般形式为:
是N*1的向量,表示观测值;X是N*p的矩阵,表示
固定效应
自变量;
是p*1的向量,表示固定效应参数向量;Z是N*q的矩阵,表示
随机效应
变量;
是q*1的向量(
在某些版本中也写成
),表示随机因子的效应值;
是N*1的向量,表示残差(随机误差)。
GLMM在此基础上做了一些改动。令 linear predictor,
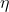 , 表示固定效应和随机效应的组合(随机误差不包含在内),即:
, 表示固定效应和随机效应的组合(随机误差不包含在内),即:
令g(⋅)表示link function,用来连接 linear predictor 和 label,h(⋅)为g(⋅)的反函数,即response function。则有:
 , 因此:
, 因此:

此处的 link function 和 response function 的示例,请直接参考GLM中的介绍(但此处会额外接触到几个概念:带随机效应的Logistic回归中的 probability density function 或简称PDF,和带随机效应的Poisson回归中的probability mass function 或简称PMF)。结果的解读,和GLM中的解读类似,细微的差别仅在于随机效应部分的解读。
借鉴知乎上的一个理解:
举个例子,我们认为疗效可能与服药时间相关,但是这个相关并不是简简单单的疗效随着服药时间的变化而改变。更可能的是疗效的随机波动的程度与服药时间有关。比如说,在早上10:00的时候,所有人基本上都处于半饱状态,此时吃药,相同剂量药物效果都差不多。但在中午的时候,有的人还没吃饭, 有的人吃过饭了,有的人喝了酒,结果酒精和药物起了反应,有的人喝了醋,醋又和药物起了另一种反应。显然,中午吃药会导致药物疗效的随机误差非常大。这种疗效的随机误差(而非疗效本身)随着时间的变化而变化,并呈一定分布的情况,必须用广义线性混合模型了。对于固定效应来说,参数的含义是,自变量每变化一个单位,应变量平均变化多少。而对于随机效应而言,参数是服从正态分布的一个随机变量,也就是说对于两个不同的自变量的值,对应变量的影响不一定是相同的。
一篇文献以一个案例对以上几种模型进行了比较,值得一读:GEE、GLMM和MLM分析卫生重复测量资料的效果比较
万崇华等. 高级医学统计学. 科学出版社.
Wiki: Generalized_linear_model
Wiki: Mixed_model
Wiki: Generalized_linear_mixed_model
Introduction to generalized linear mixed models
GLM(广义线性模型) 与 LR(逻辑回归) 详解
广义线性模型GLM
广义估计方程GEE
高斯混合模型(GMM)及其EM算法的理解
混合模型初探
周婷,兰蓝,邱建青,杜春霖,李晓松,张韬.GEE、GLMM和MLM分析卫生重复测量资料的效果比较[J].现代预防医学,2017,44(16):2881-2885+2899
R中的
广义
线性
混合
模型
教程
该存储库包含(相对)简短的教程,介绍使用R拟合和比较
模型
的
广义
线性
混合
模型
(
GLM
M)。 本教程的一般内容是由Richard McElreath出色的统计学课程“ Statistical Rethinking”启发而来的。 有关该材料的最新信息,可以在理查德的找到。 特别是,我编写此脚本时借鉴了课程期末考试中出现的一系列问题。 这些练习对我来说尤其具有启发性,因为它们说明包含随机效应(又称变化效应)不仅可以改变相对
模型
排名,而且还强调,添加随机效应可以极大地改变我们对固定效应的估计(即,通常情况下,关心我们的
模型
中的大多数)。 本教程使用R软件包lme4 , AICcmodavg和rethinking 。 赤池的信息准则(AIC)用于比较拟合
模型
。
储存库内容
glm
m_tutorial_script.R文件包含我的代码和教程注释
glm
m_tutorial_d
同时,在机器学习中,我们称 w 和 b 为
线性
模型
的超参数,满足等式条件的(w,b)组合可能不只一种,所有的超参数构成了一个最优参数集合。注意,这里用”尽可能地准确“这个词,是因为在大多数时候,我们是无法得到一个完美拟合所有样本数据的
线性
方程的,即直接基于输入数据构建的多元
线性
方程组在大多数时候是无解的。损失函数用来评价
模型
的预测值和真实值不一样的程度,损失函数越好,通常
模型
的性能越好。,选择一个特定的超参数(w,b),使得
模型
具备最好的泛化能力,机器学习算法的目的不是解方程,而是获得最好的泛化能力。
重复测量数据有几个明显的特征,一是个体内数据是反复收集的,同一对象的多次观测结果往往不独立(存在相关性),二是变异来源上看有个体内变异和个体间变异,三是数据可能存在缺失值。有多个统计
模型
可以实现重复测量数据的分析:【1】一般
线性
模型
中的重复测量方差分析,可以采用一元方差分析和多元方差分析。重复测量方差分析要求还是比较苛刻的,要求多元正态性、组间方差-协方差矩阵相等(Box’M检验),数据...
《统计学习方法》虽然分别对两者作了介绍,但没有深入讨论它们之间的联系。本文准备从最大熵
模型
出发,推导出逻辑斯谛回归
模型
,并解释两者的联系与区别。
本文主要从以下几个方面进行描述:
最大熵原理的数学解释
如何理解条件分布的极大似然函数
将最大熵
模型
转化为逻辑斯谛
模型
一、从最大熵
模型
到逻辑斯谛回归
(一)最大熵
模型
最大熵原理
我们知道(参考第5章)信息熵用于衡量一个随机变量的“不确定性”,熵越大,表示随机变量的不确定性越高。也证明了,当随机变量为均匀分布的时候,它的熵最大。
“最大熵原理”的意思
之前我们已经探讨了,在构建
GLM
模型
之前,如何进行数据预处理,接下来就介绍一下正式的建模过程。
首先我们要做的是进一步具体地分析我们应该选择
模型
的变量。第一步是对一个个变量单独建模,观察他们的p值:
这个p值就是假设检验的p值,意思就是我们对
模型
的参数进行假设检验:
H0:βj=0 H_0 : \beta _j = 0 H0:βj=0
检验的就是变量的参数在等于0和不等于0的情况下(bet...
GLM
M(generalized linear mixed model)
广义
线性
混合
模型
中的关键是“mixed”,“mixed”是区别于一般的
GLM
(generalized linear model)的显著体现。
一般的
GLM
指的就是要求因变量符合“指数分布族”即可。关于
GLM
的详细解释可以在stata的help文档中看到,
GLM
的两个核心是 Family 和 Link。其中Family指的就是因变量的分布函数,常见的几种因变量的分布如下:
连续变量——Gaussian分布/正态分布
binary变量(0,
GLM
一般是指 generalized linear model ,也就是
广义
线性
模型
;而非 general linear model,也就是一般
线性
模型
;而
GLM
M (generalized linear mixed model)是
广义
线性
混合
模型
。
广义
线性
模型
GLM
很简单,举个例子,药物的疗效和服用药物的剂量有关。这个相关性可能是多种多样的,可能是简单
线性
关系(发烧时吃一片...
三部分:固定项age,随机项(1|subject)和误差项ε。
为什么要加上一个随机项这部分呢?
在
线性
模型
中我们将所有的不感兴趣的因素,非系统性的因素,不可预测的因素造成的误差统统由一个ε来代替。这样我们求出的...
为什么要用
混合
线性
模型
:比如测量了不同收入水平的人群的收入和幸福感,但每个群体内收入水平是不同的,幸福感也不同,两者之间的关系也是不同的, 如果直接用一般
线性
模型
,会造成错误的结论,这个时候要考察的是可以推广到不同收入群体的收入和幸福感之间的关系 (即考察的关系不仅可以应用于当前的收入群体,还可以应用到其他的群体)。这时候需要用到
混合
线性
模型
(或者层次
线性
模型
)。
R中
混合
线性
模型
...
笔者做过国赛也做过美赛,其中一类典型问题就是分析相关性,从而进行预测或者其他操作。这类问题通常情况下属于比较常规的问题,一般通过matlab或SPSS分析相关性,得到一个较好的数值即可。 然而有的时候不论取哪两个或者哪几个变量,相关性都弱得令人发指,以至于无法昧着良心继续煞有介事地絮叨他们之间的相关性,这个时候,如果变量较多,可以考虑
广义
相加
模型
,实质是分析因变量与多个自变量之间的相关性。目...
0. 飞哥感言
这篇文章,主要是介绍了抗性数据,如何利用
GLM
M
模型
进行的分析,文中,他将9级分类性状变为了二分类性状,进行分析。
分析中用到了加性效应(A矩阵),空间分析(行列信息)。
对比了SAS和ASReml,结果基本一致。
其实,9分级性状,可以直接使用ASReml进行有序多分类性状分析,用累计Logistic
模型
分析,也可以考虑系谱数据和空间位置信息。这样效果应该更好。
回头找下数据,测试一下。
1. 文献
Genetic analysis of resistance to Pseudomona
进行数据分析时,会发现有时候一个
模型
中的变量之间可能具有相关性(correlation),比如面积和长度就具有高度的相关性,如果同时对这些参数建模,就存在共
线性
问题,所以一般是只针对其中一个参数建模。而这种相关性,其实还存在于数据之中,比如时间序列数据,在不同的时间,同一个对象的数据之间就是相互有联系的,那么我们应该怎么对这些具有相关性的数据进行建模分析呢。
在进一步分析之前,再次强调一下,这里...
