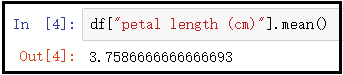
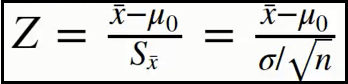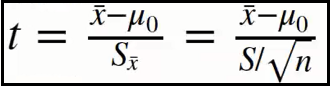iris = load_iris()
dt = np.concatenate([iris.data,iris.target.reshape(-1,1)],axis=1)
df = pd.DataFrame(dt,columns=iris.feature_names + ["types"])
display(df.sample(5))
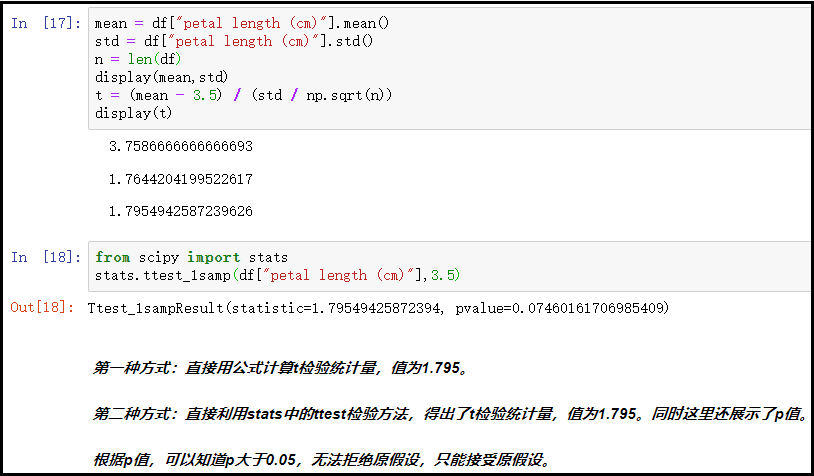
mean = df["petal length (cm)"].mean()
std = df["petal length (cm)"].std()
n = len(df)
display(mean,std)
t = (mean - 3.5) / (std / np.sqrt(n))
display(t)
from scipy import stats
stats.ttest_1samp(df["petal length (cm)"],3.5)
结果如下:
统计推断-经典统计推断基本问题统计学与概率论贝叶斯统计与经典统计推断模型与推断变量术语解释经典参数估计术语最大似然估计均值和方差的估计置信区间求近似的置信区间基于方差近似估计量的置信区间线性回归最小二乘法合理性贝叶斯线性回归多元线性回归非线性回归线性规划注意事项简单假设检验内曼-皮尔逊引理显著性检验广义似然比和拟合优度检验
统计推断是什么?
统计推断是从观测数据推断未知变量或未知模型的...
u分布:指标准正态分布,是以0为平均值,以1为标准差的正态分布
z分布:泛指正态分布,是以u为平均值,以西格玛为标准差的正态分布。对于z分布中的所有变量X,转换为(X-U)/西格玛时,其服从u分布。即标准正态分布。
t分布:t分布的均值为0
(参考链接):https://www.applysquare.com/topic-cn/TZVQpbknE/
1》t分布是正态分布的小样...
统计学被广泛的应用于各个领域之上,从物理和社会科学,再到人文科学,甚至被用在工商业及ZF的情报决策当中。统计学又可分为描述统计学和推断统计学,那么要怎样来区分她们呢?
我们先来了解描述统计学和推断统计学的概念:
描述统计学(descriptive statistics)是研究如何取得反映客观现象的数据,并通过图表形式对所搜集的数据进行加工处理和显示,进而通过综合概括与分析得出反
在统计推断中有两类问题,一类为估计问题,一类为假设检验。估计问题中主要包括**点估计**和**区间估计**,点估计是估计出一个分布中**未知参数的值**,**区间估计则是估计出一个分布中未知参数所在的范围**。
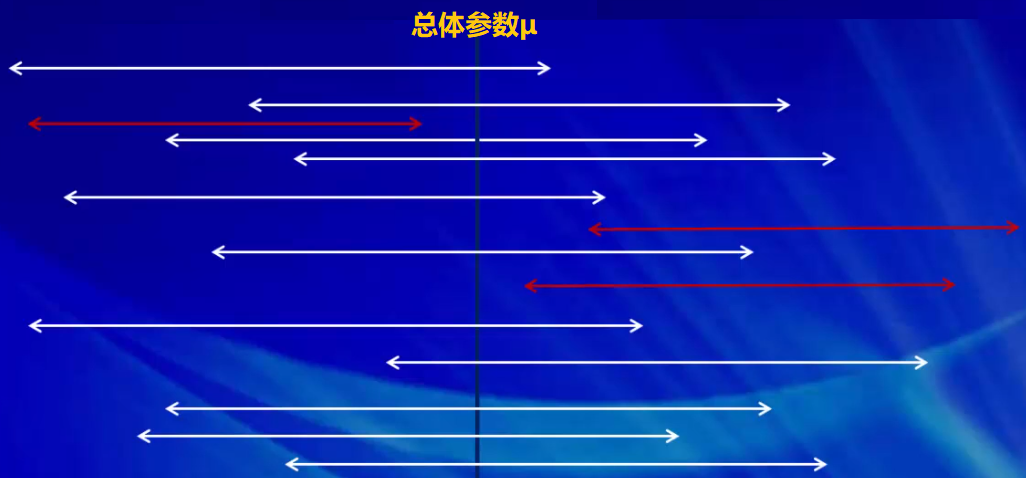
区间估计最终要估计出未知参数所在的区间,这个区间就是经常听到的**置信区间;
T检验,U检验
假设检验和参数估计都是推断统计的重要内容,但是两者的角度不同:
参数估计是利用样本信息推断未知的总体参数;
假设检验是先对总体参数提出一个假设,然后利用信息进行验证。
4.2枢轴量法(续)※两个正态样本有时我们也会比较两个正态总体之间均值或方差有无差异.假设总体 和 是两个相互独立的正态总体,从中分别抽取样本 和 ,相应的统计量如下: 这些分别是两个总体的样本均值、样本方差和偏差平方和.均值之差 的区间估计以下分为几种情形: 两总体方差已知.与单个正态总体完全类似,可以构造枢轴量为 把找常数以及改写不等式的步骤省略,这里直接给出置信水平为 的置信区间...
方差分析的零假设是:各组均值相等。这个“各组均值相等”如何理解?正确理解是:各组和所有组总均值相等,并不是真的“各组均值相等”。方差分析认为:各组和总均值无差异,那么各组均值等于总均值,意味着各组均值相等。单因素方差分析大家应该都理解的比较好,我们可以看看单因素方差分析F检验统计量的分子核心部分:(各组均值-总均值)的平方。看到没,减的是“总均值”。一般来说,如果各组和总均值无差异,那么各组之间也...
-点击上方“中国统计网”订阅我吧!-背 景假如你们现在针对用户提出了三种提高客单价的策略A、B、C,现在想看一下这三种策略最后对提高客单价的效果有什么不同,那我们怎么才能知道这三种策略效果有什么不同?最简单的方法就是做一个实验,我们可以随机挑选一部分用户,然后把这些用户分成三组A、B、C组,A组用户使用A策略、B组用户使用B策略、C组用户使用C策略,等策略实施一段时间以后,我们来看一下...
推论统计是统计学乃至于心理统计学中较为年轻的一部分内容。它以统计结果为依据,来证明或推翻某个命题。具体来说,就是通过分析样本与样本分布的差异,来估算样本与总体、同一样本的前后测成绩差异,样本与样本的成绩差距、总体与总体的成绩差距是否具有显著性差异。例如,我们想研究教育背景是否会影响人的智力测验成绩。可以找100名24岁大学毕业生和100名24岁初中毕业生。采集他们的一些智力测验成绩。用推论统计方法进行数据处理,最
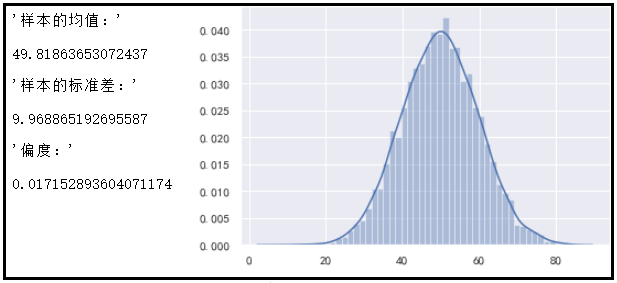
来自正态分布的样本平均数的分布符合N(μ,σ^2/n),即使总体分布不符合正态分布,抽样次数足够大时,样本平均数的分布也符合正态分布。假设检验又称为显著性检验,根据总体的理论分布和小概率原理,对未知或者不完全知道的总体提出两种对立的假设,然后根据样本统计数进行计算,统计推断是 依据总体理论分布(u分布、t分布、二项分布、泊松分布、卡方分布、F分布等),从样本的统计数对总体的参数做出推断。统计可以分为两块,一是统计描述,就是你的数据长什么样子,二是统计推断,就是根据你的数据讨论下理论总体长什么样子。
推断统计是研究如何利用样本数据来推断总体特征的统计方法。包含参数估计和假设检验。参数估计即利用样本信息推断总体特征,也就是根据样本数据来估计变量的概率分布,或者是总体分布所包含的未知参数的过程。举个例子:要研究人们的市场消费行为,首先需要了解人们的收入状况,若某城市人均年收入数据服从正态分布,但参数的均值和方差的具体取值未知,此时就可以根据样本的来估计这两个参数。方法有点估计和区间估计。通俗理解,...
假设检验是统计推断的另一个重要的应用,在分布未知或部分已知的情况下提出对总体的某种假设,比如总体的数学期望,方差以及分布。与参数估计类似,需要基于假设找到适合的检验统计量,通过计算检验统计量的值来确定是否接受假设。通常在方差已知的情况下我们用Z检验来检验关于均值的估计,在方差未知的情况下用T检验检验关于均值的估计,用卡方检验单个总体方差假设,用F检验来检验多个总体的方差假设。在参数估计中我们提到了...
方差分析(Analysis of Variance,ANOVA)就是用于检验两组或两组以上的均值是否具有显著性差异的数理统计方法。有单因素方差分析和多因素方差分析。1 基本原理在方差分析中,把要分析的变量称为响应变量,对响应变量取值有影响的其它变量称为因素,因素的不同取值称为水平。1.1 方差分析的模型以一个单因素的例子进行分析。四种用于缓解手术后疼痛的药品,研究它们的治疗效果是否存在显著性差异。...