


文章目录
文章来源团队:腾讯医疗资讯与服务部-技术研发中心
前言:随着产品矩阵和团队规模的扩张,跨业务、APP的数据处理、分析总是不可避免。一个显而易见的问题就是异构数据源的连通。我们基于 Presto DB构建了业务线内适应腾讯生态的联邦查询引擎,连通了部门内部20+数据源实例,涵盖了90%的查询场景。同时,我们参与公司级的 Presto Oteam进行协同共建,在引擎层面做了诸多改造。在实际使用 Presto 的过程中,也发现其SQL表达能力的过人之处。本文将从Presto使用者和开发者两种角度,给大家分享一些技术落地过程中的干货。
简介
Presto是facebook研发的基于SQL进行大数据分析的高性能分布式计算引擎,最开始是用来解决Hive速度慢以及异构数据源互通的问题。在大数据家族中属于MPP(Massive Parallel Processing)计算引擎范畴,其原理是火山(Volcano)模型:将SQL抽象成一个个算子(Operator),形成管线(Pipeline)。目前能够支持Hive、HBase、ES、Kudu、Kafka、MySQL、Redis等几十种数据源的读取。它有如下特点:
-
基于SQL语言,上手成本低,而且功能强大,支持reduce和lambda函数
-
纯计算引擎,解耦底层存储,可快速缩扩容
-
纯内存计算,速度快,提供交互式的查询体验
-
通过插件的方式实现拓展功能,二次开发友好
-
通过不同的连接器(Connector)插件读取异构数据源,进行联邦查询
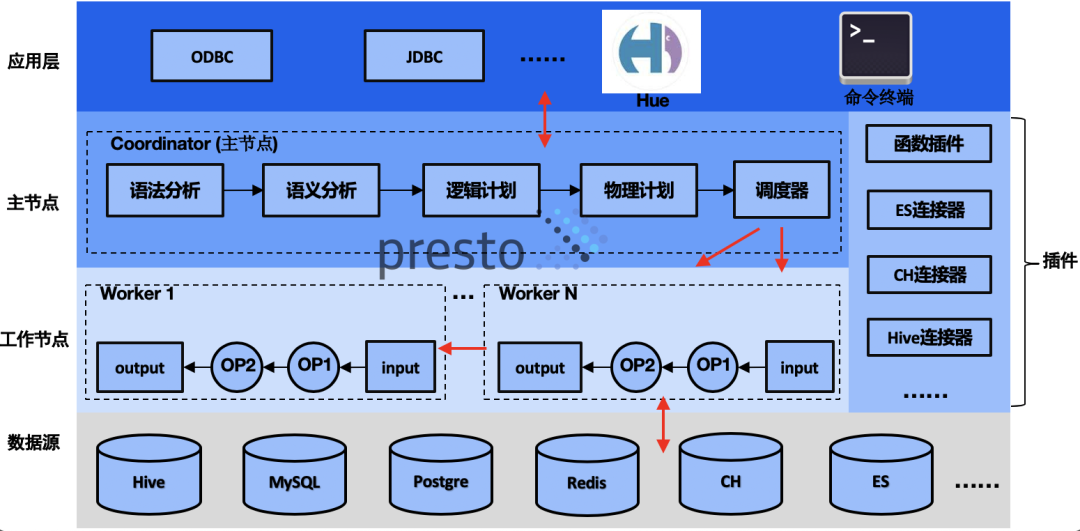
业务现状
无论是传统信息流业务,或是医疗业务,或多或少都会遇到 异构数据源整合 问题。比如医生、患者的状态数据,由后台维护,前端上报数据则在Hive中。另外,由于相同数据源不同版本间差异较大,往往没有完整的解决方案,导致 查询分析速度慢 ,业务叫苦不迭,e.g. Hive不同实例仅通过MR引擎进行互通。
业务构成
目前,个人接触过的业务包括资讯类的腾讯看点、腾讯医典,以及医生问诊相关的腾讯云医。
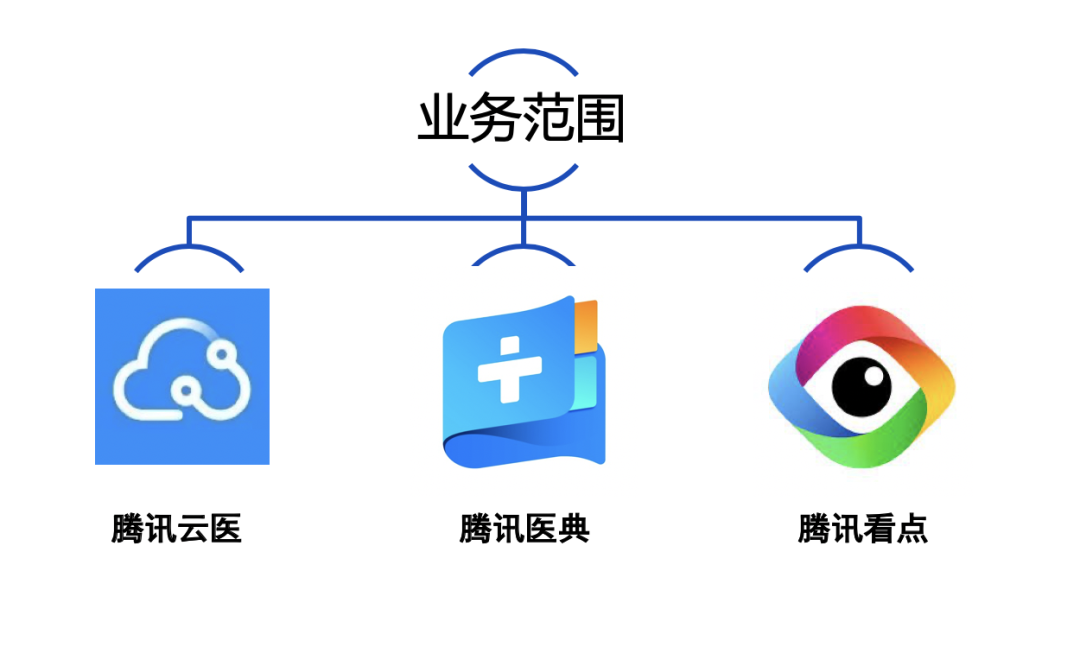
痛点问题
数据互通的时候,底层的数据源可能是同一数据源的多个实例,或是不同版本、魔改版本,e.g. 司内tHive与Venus都是Hive数据源。在跨业务/APP分析时,这种问题会更加明显。同时,由于应用场景的不同(离线计算、快速索引),天然也会存在多数据源问题。原因总结如下:
-
团队技术栈差异
-
同类产品较多
-
架构、历史遗留
-
应用场景不同
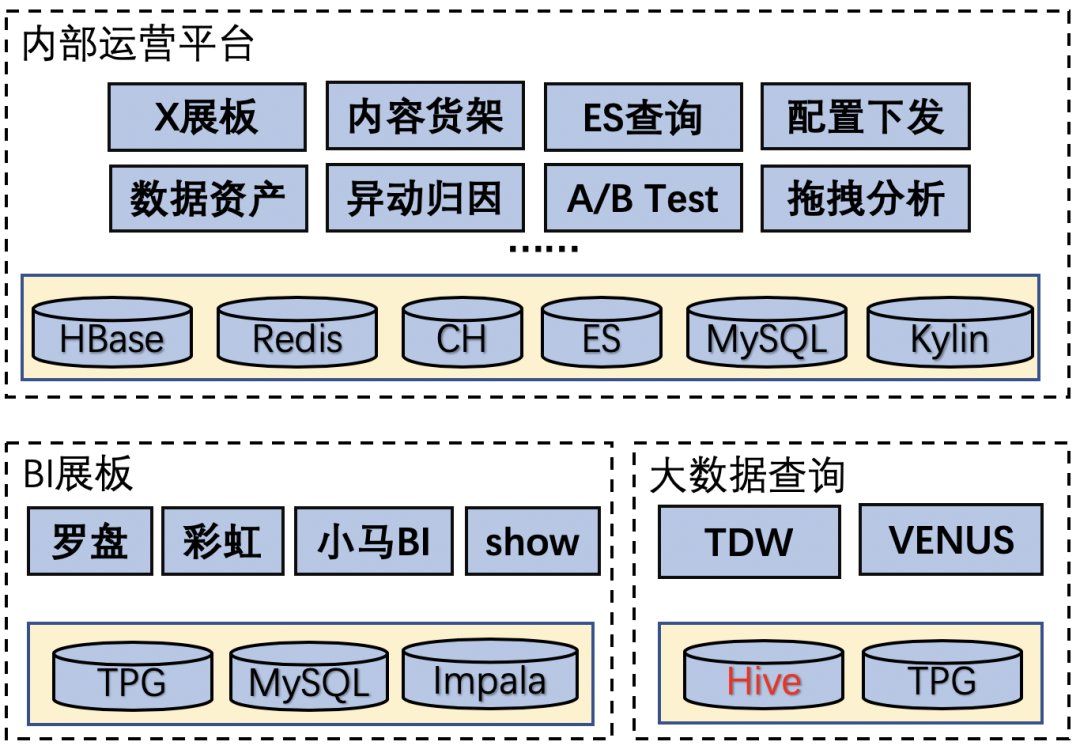
主要工作
针对Hive查询提速的问题,我们在联邦查询引擎中适配了内部的Hive数据源,并且参与中台Oteam项目进行Hive兼容、Presto引擎层优化、改造。同时,我们进行了技术运营工作来帮助大家更好地使用Presto。针对异构数据源打通的问题,我们进行了联邦查询引擎的调研与开发,在引擎层面对内部不同种类的数据源进行适配。最后是一些技术输出的规划工作。
-
Presto技术运营
-
联邦查询引擎改造适配
-
Presto Oteam引擎研发
-
技术输出
技术运营
由于身处业务的数据团队中,除了参与中台的技术研发,平时也会使用Presto,并且负责SQL相关问题的答疑,既是开发者,也是使用者。大多数人对Presto的印象,仅仅停留在“都是SQL引擎”上,其实不然。Presto的SQL语言能力非常出色。如slogan说宣传的那样,
SQL on Everything
:不仅能够连接各种数据源,还能满足复杂的处理逻辑。如果认为“Presto在SQL层面上做到兼容Hive就差不多了”,那就没有真正发挥出Presto的威力。
Reduce + Lambda
以下来自一个真实案例,数据分析同学根据APP上报的用户行为日志进行清理、建模。
-
v1版本:对用户路径按时间排序,然后输入模型进行建模。通过以下SQL片段可以满足需求。首先用array_agg将用户所有行为按照event_time排序,收集成数组,然后用'/'连接符进行拼接。
-
-
array_join(array_agg(data order by event_time asc), '/')
-
-
v2版本: 由于上报时机的原因,总是会有些相邻的重复上报,分析同学希望把这些相邻数据剔除掉,例如有些行为定时10s上报一次,期望达到如下的效果:
-
-
A/B/A/A/C -> A/B/A/C
-
如果不是别人问,自己是不会想到可以用SQL来完成这种操作的。
数组相邻元素去重
,乍看是非常特化的需求,SQL不太可能满足,但后来发现还真的可以实现。不得不说Presto的reduce函数,加上自由度极高的lambda表达式,以及可以承载多个变量的
Row
类型,使得我们几乎可以在SQL中“编程”(这里使用针对array类型的reduce函数,更通用的聚合函数为reduce_agg)。最终解法如下:
-- 逻辑:6/4/6/6/10/20 -> 6/4/6/10/20
-- distinct adjacent elements
SELECT reduce(
ARRAY ['6', '4', '6', '6', '10', '20'], -- 输入
CAST(
ROW(ARRAY[], '')
AS ROW(arr ARRAY(VARCHAR), prev_ele VARCHAR)
), -- 初始状态S
(S, T) -> CAST(
ROW(IF(S.prev_ele=T, S.arr, S.arr||T), T)
AS ROW(arr ARRAY(VARCHAR), prev_ele VARCHAR)
), -- lambda输入函数I
S -> array_join(S.arr, '/') -- lambda输出函数O
以作用对象为数组的reduce函数为例,包含以下4个参数:
-
长度为N的数组。每个元素将会依次送入lambda输入函数
-
初始状态。第一个元素和该状态作为lambda输入函数第一次调用的参数
-
一个lambda输入函数。调用N次。它接收一个状态和一个元素,产生一个新的状态
-
一个lambda输出函数。调用一次。对3中处理完的最终状态做一次变换
reduce(array(T), initialState S, inputFunction(S, T, S), outputFunction(S, R)) → R
可以看到,示例中的状态S是一个
Row
类型的变量,它可以存储多个元素。第一个是去重数组arr,第二个是上一个元素的值prev_ele。lambda输入函数每次接收到一个新的值,和prev_ele比较,相等则什么也也不做,不等则将新值放入去重数组中,同时更新prev_ele。reduce是一种通用的模型,lambda则最大程度地利用了SQL的现有能力,使得Presto的SQL表现力更加强大。
3.2 窗口函数
Presto中的聚合函数都可以被用在窗口函数中,使用array_agg可以把当前的窗口截取下来,结合Window Frame可以操纵窗口大小,衍生出很多窗口类型。主要由两个维度组成:
首先是相同行的处理方式,记为dim1:
-
RANGE: 当前窗口 会 包含值相同的相邻行
-
ROWS: 当前窗口 不会 包含值相同的相邻行
然后是窗口的边界指定,最后两种仅支持与ROWS连用,记为dim2:
-
UNBOUND PRECEDING: 排序后第一个元素
-
UNBOUND FOLLOWING: 排序后最后一个元素
-
N PRECEDING: 排序后,当前行的前N行
-
N FOLLOWING: 排序后,当前行的后N行
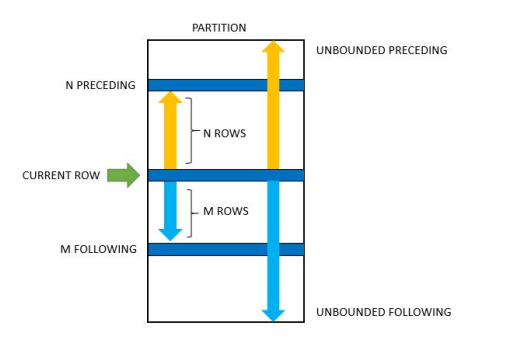
通过以下SQL的结果,应该能对窗口函数有更进一步的认识。为了简化我们假设只有一个partition,排序为asc。列名取值如下所示方便大家理解:
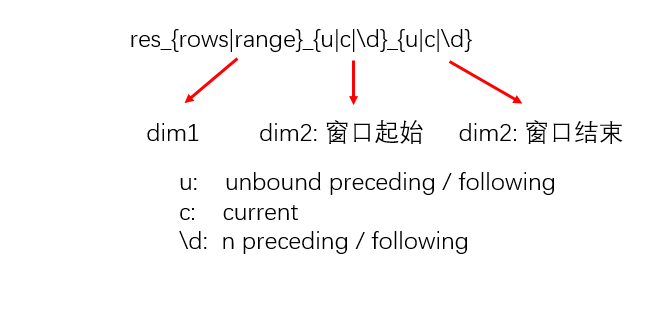
-- value为关心的值
-- 以index进行排序
t1 (value, index) AS
SELECT * FROM (VALUES ('a', 1),
('b', 2),
('c', 3),
('d', 4),
('e', 4),
('f', 5),
('g', 5),
('h', 6))
SELECT *,
-- 默认
array_agg(value) OVER
(ORDER BY index) res,
-- [开头, 当前值]
array_agg(value) OVER
(ORDER BY index RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) res_range_uc,
-- [开头, 当前行]
array_agg(value) OVER
(ORDER BY index ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) res_rows_uc,
-- [当前值, 末尾]
array_agg(value) OVER
(ORDER BY index RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) res_range_cu,
-- [当前行, 末尾]
array_agg(value) OVER
(ORDER BY index ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) res_rows_cu,
-- [前1个值,后1个值] 不支持
-- array_agg(value) OVER (ORDER BY index RANGE BETWEEN 1 PRECEDING AND 1 FOLLOWING) res_range_11, not support
-- [前1行,后1行]
array_agg(value) OVER
(ORDER BY index ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) res_rows_11
FROM t1;
presto>
value | index | res | res_range_uc | res_rows_uc | res_range_cu | res_rows_cu | res_rows_11
-------+-------+--------------------------+--------------------------+--------------------------+--------------------------+--------------------------+-------------
a | 1 | [a] | [a] | [a] | [a, b, c, d, e, f, g, h] | [a, b, c, d, e, f, g, h] | [a, b]
b | 2 | [a, b] | [a, b] | [a, b] | [b, c, d, e, f, g, h] | [b, c, d, e, f, g, h] | [a, b, c]
c | 3 | [a, b, c] | [a, b, c] | [a, b, c] | [c, d, e, f, g, h] | [c, d, e, f, g, h] | [b, c, d]
d | 4 | [a, b, c, d, e] | [a, b, c, d, e] | [a, b, c, d] | [d, e, f, g, h] | [d, e, f, g, h] | [c, d, e]
e | 4 | [a, b, c, d, e] | [a, b, c, d, e] | [a, b, c, d, e] | [d, e, f, g, h] | [e, f, g, h] | [d, e, f]
f | 5 | [a, b, c, d, e, f, g] | [a, b, c, d, e, f, g] | [a, b, c, d, e, f] | [f, g, h] | [f, g, h] | [e, f, g]
g | 5 | [a, b, c, d, e, f, g] | [a, b, c, d, e, f, g] | [a, b, c, d, e, f, g] | [f, g, h] | [g, h] | [f, g, h]
h | 6 | [a, b, c, d, e, f, g, h] | [a, b, c, d, e, f, g, h] | [a, b, c, d, e, f, g, h] | [h] | [h] | [g, h]
(8 rows)
高阶运营
一般来说,通过官方文档就可以解答大部分问题。但有时候文档也没说明的细节,只能看源码了。关于语法特点的问题,需要查看
SqlBase.g4
。比如以下SQL为什么可以运行?不是所有查询语句都需要select开头:
presto> (VALUES ('a', 1),('b', 2));
_col0 | _col1
-------+-------
a | 1
b | 2
(2 rows)
语义分析中的问题,需要查看
StatementAnalyzer
。比如窗口函数执行完成后,用标量函数做一些加工处理,必须写在整个窗口函数
func2(func1() over ())
的外面,而不是
func2(func1()) over ()
。
array_join(array_agg(concat(col1, col2)), '/')
over (partition by user_id order by event_time)
array_join(
array_agg(concat(col1, col2))
over (partition by user_id order by event_time),
语法、语义错误
还有个问题,到底怎么区分语法、语义错误?对于使用者而言,不建议了解。对于开发者来说,还是很有必要了解的。语法错误是指通过简单规则捕获的SQL错误,在Antlr层面就可以截获,跟上下文关系不大,e.g. select * from from table1; 语义错误需要上下文信息,比如库表、字段是否合法?对于Presto而言,lambda表达式出现的位置是否合法?了解语法、语义的区别,对问题的排查也是十分高效的。
联邦查询引擎
异构数据源导致的问题:
-
搭建各种ETL Pipeline,维护成本高
-
数据分析速度 严重拖慢
为此,我们引入Presto作为联邦查询引擎,一方面利用多数据源能力,减少ETL相关工作量。另一方面,利用Presto的速度为业务分析提速。本次介绍两个数据源适配的工作:
-
为了适配内部的tHive,我们在MetaStore的Thrift RPC协议中植入了内部鉴权机制。
-
针对云上ES的网络情况,禁用了自动嗅探逻辑。
Hive连接器适配
Presto的Hive连接器通过与HMS(Hive MetaStore)通信获取Hive库表的位置信息,然后拉取数据。腾讯tHive有自己的一套鉴权体系TAUTH,我们需要将这种鉴权机制引入到Hive连接器中。外部一般通过Thrift RPC协议与HMS通信。那么如何加入鉴权能力呢?

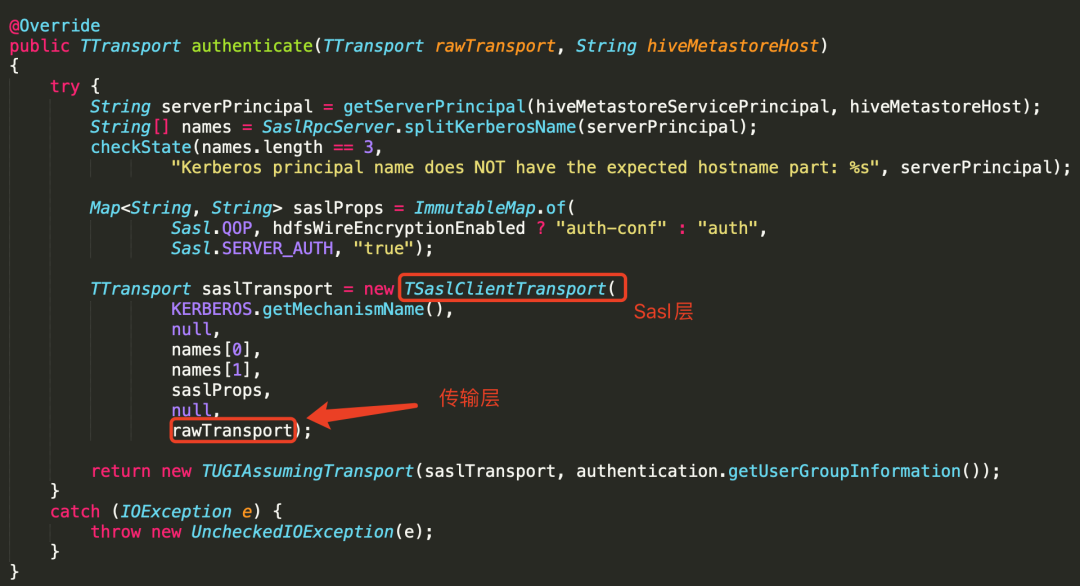
参考Hive连接器中
Kerberos
机制的实现(下图),可以看到rawTransport作为参数,用来构建一个新的SaslTransport。
结合
TSaslClientTransport
的源码可以发现,这里其实是计算机网络分层思想的典型应用。在可靠传输层rawTransport的基础上,再包装了一个Sasl层。利用底层rawTransport提供的可靠传输能力,进一步提供安全策略。e.g. 某些QoS条件下,调用Sasl层的
write()
,会对数据进行加密,Sasl进而调用下一层的
write()
函数,将加密后的数据发送到可靠的传输通道中。它们都实现了
TTtransport
接口,I/O函数如下所示:
-
open()
-
close()
-
flush()
-
readAll()
-
write()
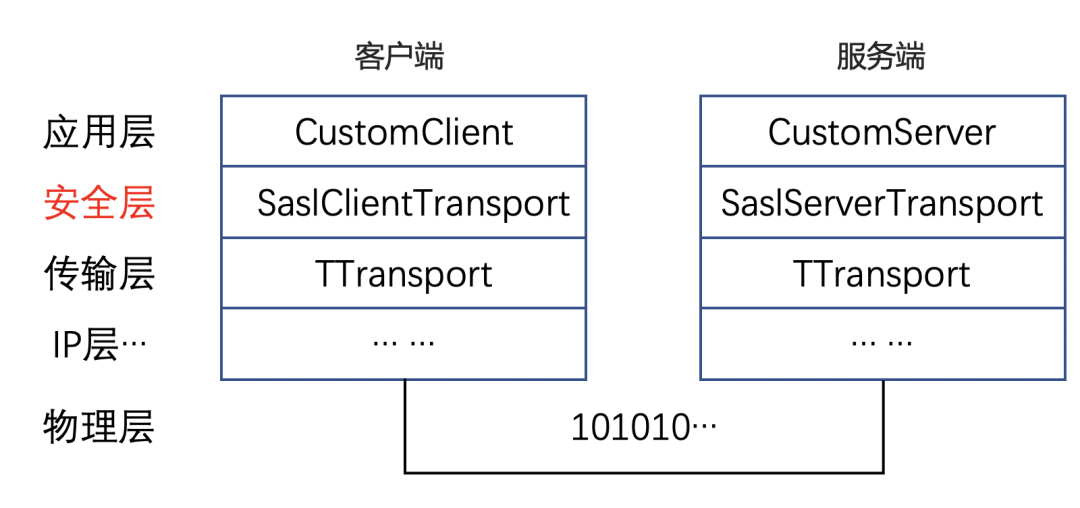
Sasl层本身并不绑定特定的鉴权机制,它是一个框架。通过JCA注册的鉴权机制都可以在运行时被指定。
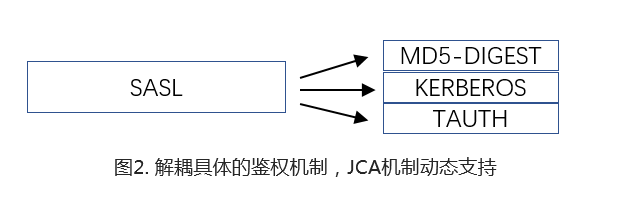
所以如果想整合自定义的鉴权机制,需要注册对应的
SecurityProvider
。
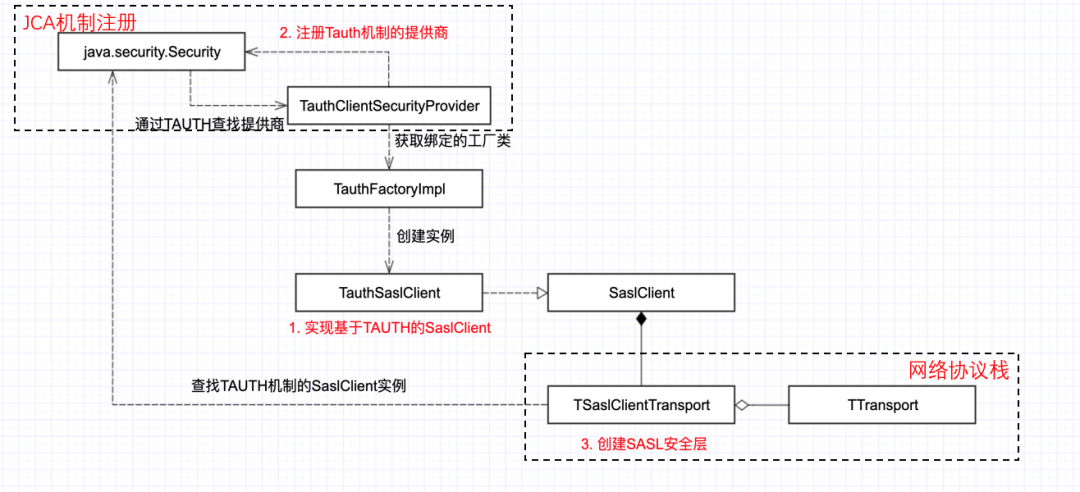
总结:对于小白来说,“为Hive连接器增加一种鉴权机制”是个很难理解的技术需求,通过前文的探索,我们发现其本质是:“如何在HMS的Thrift RPC中,为SASL鉴权层增加一种自定义的安全协议。”这里的上下文比较多,需要对HMS、THrift RPC、SASL、JCA、Kerberos等概念有个大概的了解,才知道需要做什么。对技术的提升还是很有帮助的。
ES连接器踩坑
第二个case:调研ES连接器的时候,发现Presto启动时第一次连接ES集群是成功的。但是后面哪怕没有执行ES相关查询也会无故报错,堆栈信息显示网络连接失败。
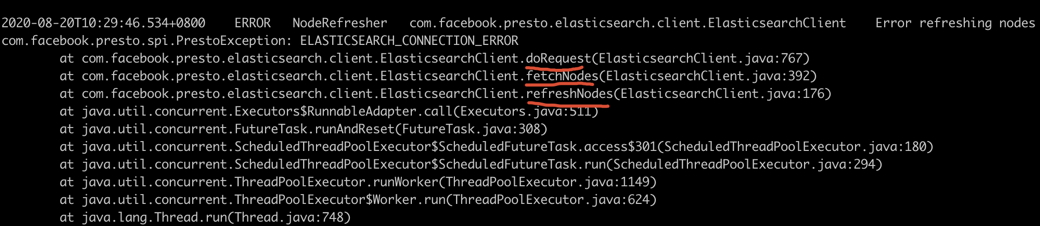
经过排查,发现与定时嗅探逻辑有关。Presto底层依赖了facebook内部的
Airlift
后台框架。在这个场景下,通过
Bootstrap
注册的类会被生命周期管理器识别,
@PostConstruct
注解(Annotation)标记的函数会在类实例化后被自动调用。可以看到,一个
refreshNodes()
函数被定期调用了,该函数会获取ES集群中所有的可用节点IP,并在下次将请求发送到其中一个节点。

由于云上ES集群只开放了一个主节点的访问端口,嗅探获得的IP其实是不能用的。这也解释了为什么第一次访问是成功的(第一次访问的主节点开放),后续访问大概率是失败的(其它节点端口不开放)。
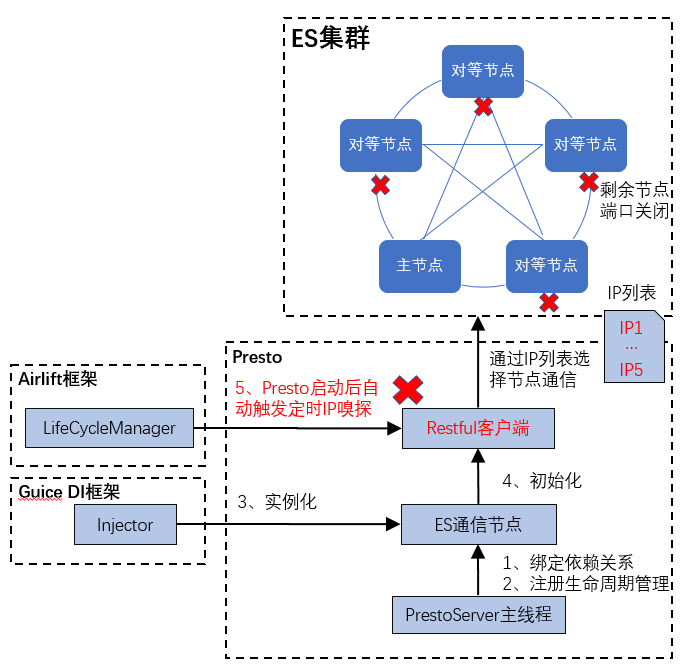
主要的改造就是禁用自动更新节点逻辑,位于
ElasticSearchClint
文件。在改造的过程中,发现已经有参数
elasticsearch.ignore-publish-address
可以满足需求,但是在去年8月的时候DB、SQL的文档里竟然没有记录这个参数,github上搜索一波发现已有issue了,目前社区已经补齐了文档。
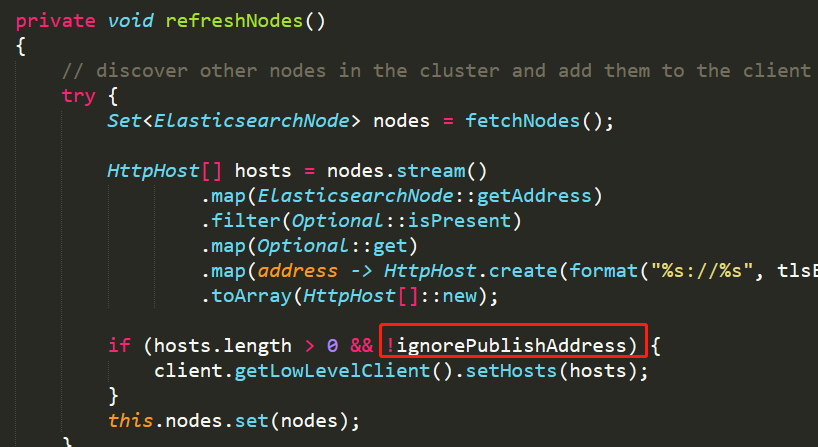
总结:
Airlift
后台框架虽然没有文档,但开发者还是要认真看。
Oteam共建
在去年,随着Presto在腾讯内部的应用场景越来越多,为了整合各部门的研发能力和技术成果,公司内部由PCG欧拉数据中台牵头发起了Presto Oteam项目,主要for Presto引擎的研发。作为资讯业务的数据工程同学,我们也有幸参与共建。Oteam部分工作内容如下:
-
Hive语义兼容,函数迁移
-
RBO/CBO执行解析器
-
Worker Tag能力
-
分析函数开发
-
语法/语义扩展
-
动态数据源支持
-
查询性能优化专项
-
Coordinator执行流程优化
-
bug fix ...
限于篇幅,简单介绍第一点:标量函数开发原理。
函数开发
不同于Hive UDF函数可以由用户直接上传,在Presto引擎中所有扩展部件都以插件形式被统一整合。除了最常见的连接器(Connector)插件以外,函数也是一种插件。如果业务需要自定义函数,就需要单独开发函数插件。Presto引擎自带了很多函数,可以作为开发者的参考。总共有两种函数开发方式:
-
使用注解框架的普通函数
-
使用字节码适配的变长参数函数
第一种方式需要使用Presto引擎的注解框架,官网给的例子比较简单,各种注解搭配使用的方式实际比较复杂。同时函数的数据类型需要涉及到Presto引擎的
Slice
,
Block
等类型,有一定学习成本。第二种方式比较少见,而且不支持通过插件进行开发,只能写到
presto-main
模块中,它基于Presto自带的字节码框架动态生成字节码(包
com.facebook.presto.sql.gen
),是比较hack的实现,可以参考
ArrayConcatFunction
。
函数注解框架
以标量函数为例。函数开发和普通的Java方法编写本质上是一样的,但是也有很多差异点:
-
需要使用注解(annotation)标记出该函数是一个可供调用的标量函数,包括函数名,返回类型、参数类型等。
-
java原生类型和Presto类型有一一对应的关系。Java的
Slice对应Presto中的Varchar类型,Java的Block对应Presto中的Array类型。(下文分别称为Java类型和SQL类型) -
这些特定的Java类型逻辑上等价于
String,Array数组,但是API差别很大,前期有一定的上手成本。 -
函数有两套签名。基于反射可以获取Java类型的形参、返回值类型,称为 方法签名 。基于
@SqlType注解可以获取Presto引擎使用的参数、返回值类型,称为 函数签名 。这里做个严格的区分。 -
可以使用
@TypeParameter函数注解引入 泛型变量 。在函数体声明相关的泛型参数,供SqlType引用。 -
可以使用
@LiteralParameter函数注解引入字面量变量。 -
可以使用形参注解
@TypeParameter、@LiteralParameter、@FunctionDependency、@OperatorDependency声明一些 依赖型参数 ,在调用函数之前,Presto会根据解析出来的元数据,自动注入参数依赖。
我们把写在函数体/类名上的注解称为 函数注解 ,写在函数形参前面的注解称为 形参注解 ,方便下文引用。一般来说,关注前四点就够了。后面是一些进阶的使用技巧。
按注解类型区分:
| 函数注解 | 形参注解 | |
|---|---|---|
| @SqlScalarFunction | 定义函数名,函数属性 | - |
| @Description | 定义函数描述信息 | - |
| @SqlNullale | 返回值是否可以是null | 形参是否接收null |
| @SqlType | 返回值的SQL类型 | 形参的SQL类型 |
| @TypeParameter | 定义泛型变量 | 引入依赖型参数 |
| @LiteralParameters | 定义字面量变量 | 引入依赖型参数 |
以下是官网[2]的一个例子:
public class ExampleNullFunction
@ScalarFunction("is_null", calledOnNullInput = true)
@Description("Returns TRUE if the argument is NULL")
@SqlType(StandardTypes.BOOLEAN)
public static boolean isNull(@SqlNullable @SqlType(StandardTypes.VARCHAR) Slice string)
return (string == null);
对应刚刚说到的几点:
-
isNull函数体有三个注解,
@ScalarFunction定义了函数名和calledOnNullInput属性。@Description定义了函数的描述字段,在Presto客户端用show functions命令可以看到函数的描述信息。@SqlType描述了函数的返回值类型。这些是 函数注解 。 -
形参的SQL类型是VARCHAR,Java类型是Slice。如果Slice换成其它类型,函数调用会失败。这个是 形参注解 。
-
返回值、形参都有
@SqlType注解,它们定义了SQL类型。在Presto引擎层面,基本都是使用SQL类型来进行解析。
再来看另外一个例子:
@ScalarFunction(name = "is_null", calledOnNullInput = true)
@Description("Returns TRUE if the argument is NULL")
public final class IsNullFunction
@TypeParameter("T")
@SqlType(StandardTypes.BOOLEAN)
public static boolean isNullSlice(@SqlNullable @SqlType("T") Slice value)
return (value == null);
@TypeParameter("T")
@SqlType(StandardTypes.BOOLEAN)
public static boolean isNullLong(@SqlNullable @SqlType("T") Long value)
return (value == null);
@TypeParameter("T")
@SqlType(StandardTypes.BOOLEAN)
public static boolean isNullDouble(@SqlNullable @SqlType("T") Double value)