


【医学图像分割】最新综述--聚焦全监督与弱监督学习

Title : Medical Image Segmentation Using Deep Learning: A Survey
作者 :Tao Lei, Senior Member, IEEE, Risheng Wang, Yong Wan, Xiaogang Du, Hongying Meng, Senior Member, IEEE,and Asoke K. Nandi, Fellow, IEEE
发表单位 :未知
发表于 :arxiv
关键词 :医学图像分割,综述
一句话总结 :医学图像分割综述,讲了有监督和弱监督的方法,比较全面 ;
0. Abstract
- 本文做综述的两个创新之处:1)文献分类是多层级由粗到细的;2)不涉及无监督方法,只介绍有监督和弱监督学习方法。
- 对于有监督学习方法 supervised learning,从三个角度分析:
- 网络backbone的选择;
- 网络block的设计;
- loss function的设计;
- 对于弱监督方法 weakly supervised,从三个角度分析:
- 数据增强
- 迁移学习
- 交互式分割 interactive segmentation
1. Introduction
医学图像分割具体有哪些任务?
- liver and liver-tumor segmentation [1, 2], 肝脏
- brain and brain-tumor segmentation [3, 4], 大脑
- optic disc segmentation [5, 6], 视盘,视神经盘
- cell segmentation [7, 8], 细胞
- lung segmentation and pulmonary nodules [9, 118], 肺,肺结节
医学图像有哪些类型?
- X-ray, X射线照片
- Computed Tomography (CT), 计算机断层扫描
- Magnetic Resonance Imaging (MRI) ,核磁共振
- ultrasound超声
somethings else:
- 分割一般指semantic segmentation或者instance segmentation,医学图像上,几乎没有instance segmentation,一般默认就是semantic segmentation。
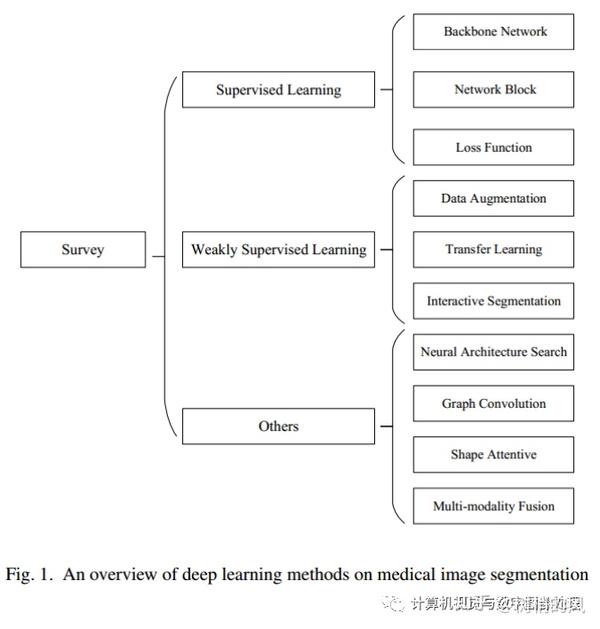

2. 有监督学习
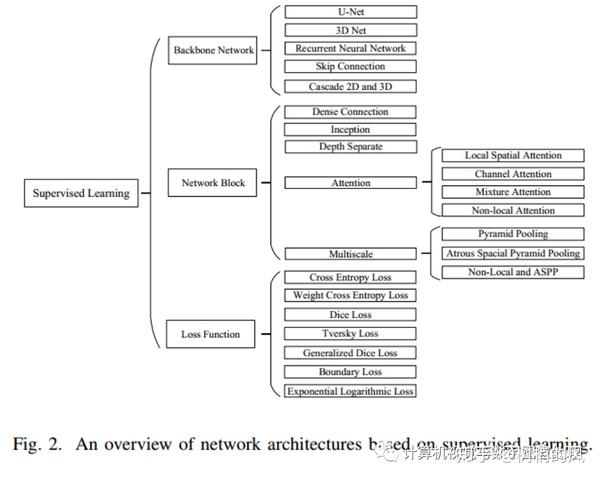

2.1 Backbone Networks
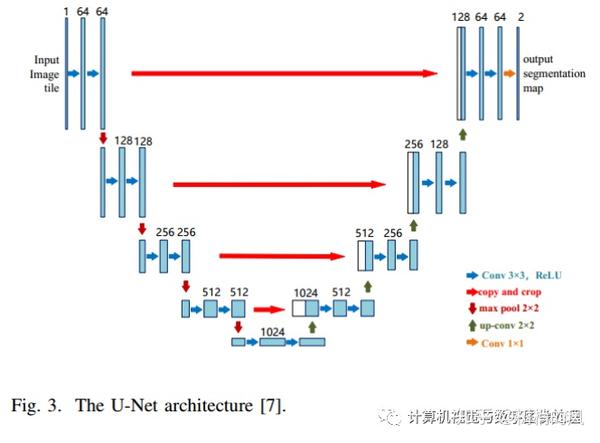
最基础的U-Net:

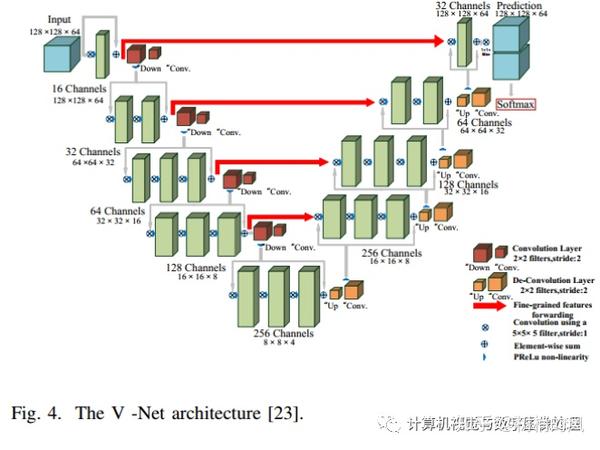
3D版本U-Net+residual connection=V-Net:

RNN在图像分割中的应用:
- Alom et al. [32] 将ResUNet与RNN结合;
- Gao et al. [33] 将LSTM与CNN结合;
- Bai et al. [34] 将FCN与RNN结合;
对Skip Connection的改进:
- skip connection的缺点是:low-level feature与high-level feature之间的semantic gap;large semantic gap between low- and high-resolution features, leading to blurred feature maps.
- Ibtehaz et al. [43] 提出了MultiResUNet,Seo et al. [44] 提出了mUNet,Chen et al. [60] 提出了FED-Net,三者都是在skip connection中加入了卷积层;
Cascade of 2D and 3D: 指训练两个或更多模型,一般是串联使用;
- coarse-fine segmentation:串联两个FCN,第一个做coarse segmentation,第二个以第一个FCN的输出做输入,做fine segmentation;
- Christ et al. [61] proposed a cascaded network for liver and liver-tumor segmentation. 第一个FCN分割liver,第二个分割tumor;
- Yuan et al. [62] 也提出了这种方法。Besides, other networks using the coarse-fine segmentation framework can be found in [64-66].
- detection segmentation:先用R-CNN [128] or You-On-Look-Once (YOLO) [129] 做detection,相当于coarse segmentation,然后再用一个FCN做fine segmentation。
- Al-Antari et al. [130],Tang et al [63] ,Salehi et al [131] and Yan et al [132];
- 优点:This kind of cascade network can effectively extract richer multi-scale context information by using a posteriori probabilities generated by the first network than normal cascade networks.
- mixed segmentation:
- 问题:大多数医学图像是3D volume data,2D卷积不能学到第三维的temporal 信息,3D卷积计算量大耗费memory;
- 解决:使用伪-3D方法;
- 使用了局部时序信息:Oda et al [126],Vu et al. [127],缺点:Although these pseudo-3D approaches can segment object from 3D volume data, they only obtain limited accuracy improvement due to the utilization of local temporal information.
- hybrid cascading 2D and 3D networks:Li et al. [67] 提出了H-DenseUNet,做法是平行使用一个2D网络和一个3D网络,最后做特征融合;Zhang et al. [37] proposed a lightweight hybrid convolutional network (LW-HCN) ,因为使用了depthwise and spatiotemporal separate(DSTS) block and the use of 3D depth separable convolution;Dey et al. [68] also designed a cascade of 2D and 3D network for liver and liver-tumor segmentation.
- Valanarasu et al. [133] 提出了 KiUNet to perform brain dissection segmentation. 为了保存小物体的边缘信息,设计的FCN中间层的resolution大于图片原始尺寸,相当于做了放大,与普通的U-Net串联使用,道理是有的。
- GAN一般适合做数据增强,也有用于分割的:
- 动机:Since medical images usually show low contrast, blurred boundaries between different tissues or between tissues and lesions, and sparse medical image data with labels, U-Net-based segmentation methods using pixel loss to learn local and global relationships between pixels are not sufficient for medical image segmentation, and the use of generative adversarial networks is becoming a popular idea for improving image segmentation.
- Luc et al. [121],Singh et al. [122],Conze et al. [123];
结合prior knowledge进CNN中:
- 动机:the incorporation of the prior knowledge about organ shape and position may be crucial for improving medical image segmentation effect, where images are corrupted and thus contain artefacts due to limitations of imaging techniques.
- Oktay et al. [124],Boutillon et al. [125],
2.2 网络中Block 的设计
Dense Connection:
- Guan et al. [27] proposed an improved U-Net by replacing each subblock of U-Net with a form of dense connections;
- Zhou et al. [41]提出了UNet++;为了防止参数过多,还提出了一种剪枝方法。
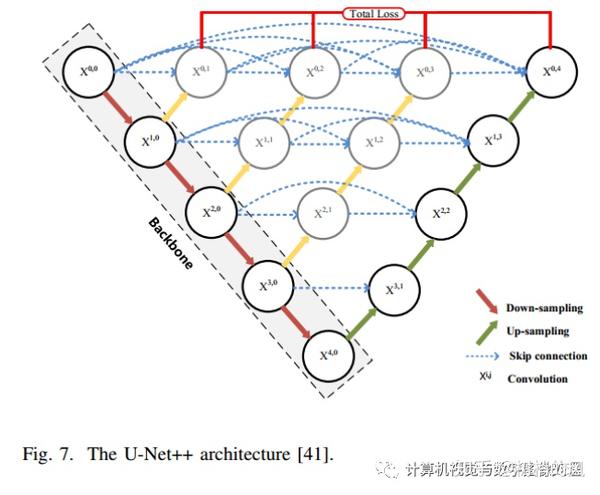

- deep supervision也是很常用的!the deep supervision [42] is also employed to balance the decline of segmentation accuracy caused by the pruning.
Inception:其实属于多尺度模块了
- 问题:深的网络存在问题vanishing gradient, the difficulty of network convergence, the requirement of large memory usage;
- GoogleNet [29-30];Gu et al. [28] proposed CE-Net;
- Depth Separability:减少参数,提高泛化性,减少memory
- Lei et al. [35] proposed a lightweight V-Net (LV-Net),使用depth separable convolution;
- Zhang et al. [37] and Huang et al. [38];[39] [40];
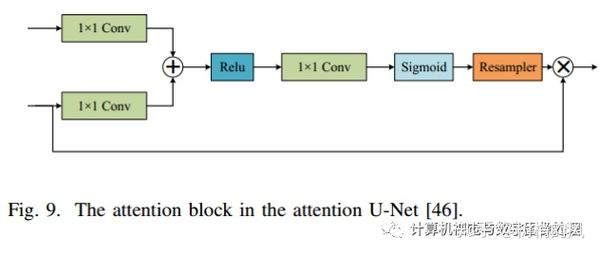
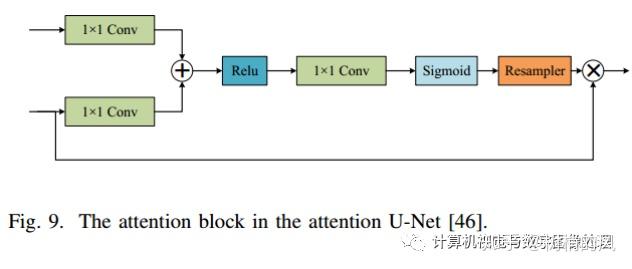
Attention Mechanism:
- Local Spatial Attention
- Jaderberget al. [45] early proposed a spatial transformer network (STNet);
- Oktay et al. [46] proposed attention U-Net. 相当于是利用attention方式融合low-level和high-level信息;
- Channel Attention
- 用处:The channel attention block can achieve feature recalibration, which utilizes learned global information to emphasize selectively useful features and suppress useless features.
- Hu et al. [47] proposed SE-Net;
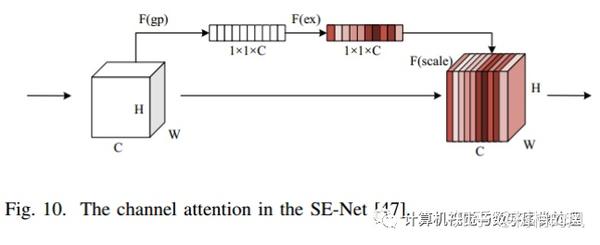

- Chen et al. [60] proposed FED-Net that uses the SE block to achieve the feature channel attention.
- Mixture Attention:同时使用spatial attention和channel attention;
- Kaul et al. [48] proposed the focusNet,[39],[40];
- Wang et al. [53]提出了ScleraSegNet. 在skip connection中加入attention layer,做了详细对比实验,发现加channel attention最好;
- Non-local Attention
- Wang et al. [54] proposed a Non-local U-Net;
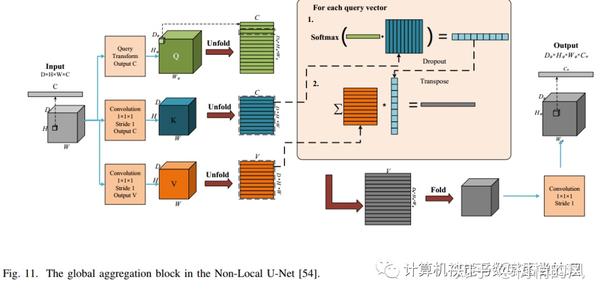

Multi-scale Information Fusion:
- 意义:For example, a tumor in the middle or late stage could be much larger than that in the early stage. The size of perceptive field roughly determines how much context information we can use.
- Pyramid Pooling: 平行使用pooling
- He et al. [55] first proposed spatial pyramid pooling (SPP)
- residual multi-kernel pooling (RMP) [28]
- ASPP:
- deeplabV3
- Wang et al. [58] designed an hybrid expansion convolution (HDC) networks.
- Non-local and ASPP:
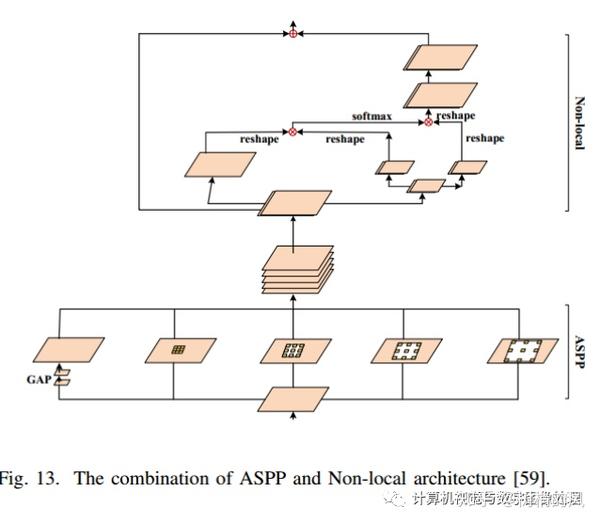

2.3 Loss Function的设计
Cross Entropy Loss:
Weighted Cross Entropy Loss: 为了解决类别不平衡问题
- Long et al. [20] proposed weighted cross entropy loss (WCE) to counteract the class imbalance.
- In [7], Ronneberger et al. proposed U-Net in which the cross entropy loss function is improved by adding a distance function. The improved loss function is able to improve the learning capability of models for inter-class distance.
Dice Loss:
- Milletari et al. [23] proposed V-Net that employs the Dice loss
- Dice loss难训练,适合类别不平衡的样本,难训练的原因分析:


Tversky Loss:
- Salehi et al. [69] proposed the Tversky Loss (TL) that is a regularized version of Dice loss to control the contribution of both false positive and false negative to the loss function.
Generalized Dice Loss:
- 更好地解决类别不平衡,更易训练;
Boundary Loss:
- To solve the problem of class imbalance, Kervadec et al. [71] proposed a new boundary loss used for brain lesion segmentation.
Exponential Logarithmic Loss:
- Therefore, by combining focal loss [73] and dice loss, Wong et al. [72] proposed the exponential logarithmic loss (EXP loss) used for brain segmentation to solve problem of serious class imbalance.
Loss Improvements:
- Chen et al. [74] proposed a new loss function by applying traditional active contour energyminimization to convolutional neural networks,
- Li et al. [75] proposed a new regularization term to improve the crossentropy loss function, and
- Karimi et al. [76] proposed a loss function based on Hausdorff distance (HD).
- Besides, there are still a lot of works [77-78] trying to deal with this problem by adding penalties to loss functions or changing the optimization strategy according to specific tasks.
- 医学图像中,经常有小物体,物体相比背景是很小的,需要额外关注和设计loss;
Deep supervision:
- 动机:解决vanishing gradient and gradient explosion.
- Lee et al. [42] proposed Deeplysupervised nets (DSNs) by adding some auxiliary branching classifiers to some layers of the neural network. [134] [135]
3. 弱监督学习
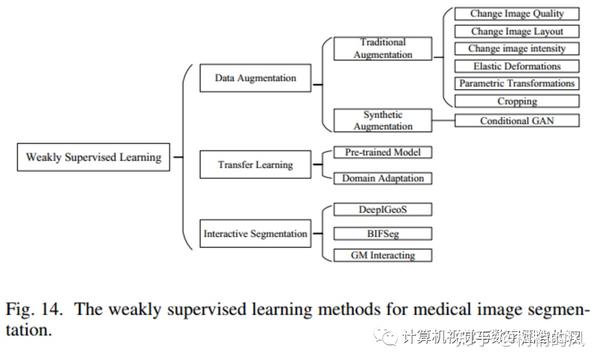

3.1 数据增强
传统的数据增强有什么缺点?
一般是翻转、旋转之类的,与原始图像太相似了。
解决方法 :
Goodfellow [79] 提出的用GAN来做数据增强,解决了与原始图像相似的问题。
传统方法 :
- the improvement of image quality such as noise suppression, the change of image intensity such as brightness, saturation, and contrast, and
- the change of image layout such as rotation, distortion, and scaling
- Sirinukunwattana et al. [80] utilized the Gaussian blur to achieve data enhancement
- Dong et al. [81] randomly used the brightness enhancement function in 3D MR images
- Ronneberger et al. [7] used random elastic deformation to perform data expansion
Conditional Generative Adversarial Nets (cGAN):
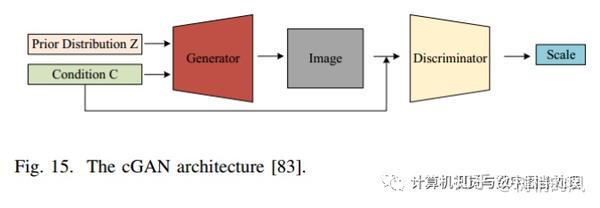

- Guibas et al. [82] proposed a network architecture composed of a GAN [79] and a cGAN [83].
- Mahapatra et al. [84] used a cGAN to synthesize X-ray images with required abnormalities,
- there are also some other works [85-86] using GAN or cGAN to generate images to achieve data enhancement.
- Although the image generated by cGAN has many defects, such as blurred boundary and low resolution, the cGAN provides a basic ideas for the later CycleGAN [88] and StarGAN [109] used for the conversion of image styles.
3.2 迁移学习
Pre-trained Model:
- Kalinin [151] et al. considered the VGG-11, VGG-16, and ResNet-34 networks pre-trained on ImageNet as encoders of the U-shaped network to perform semantic segmentation;
- Similarly, Conze et al. [152] used VGG-11 pretrained on ImageNet as the encoder of a segmentation network to perform shoulder muscle MRI segmentation.
- 预训练模型的问题:popular transfer learning methods are hardly applicable to 3D medical image analysis because pretrained models often rely on 2D image datasets.
Domain Adaptation:
- CycleGAN
- Huo et al. [87] proposed a jointly optimized image synthesis and segmentation framework for the task of spleen segmentation in CT images using CycleGAN [88].
- Chen et al. [89] also adopted a similar method using segmentation labels of MR images to achieve the task of cardiac CT segmentation.
- Chartsias et al. [90] used the CycleGAN to generate corresponding MR images and labels from CT slices and myocardial segmentation labels, and then used synthetic MR and real MR images to train the myocardial segmentation model. This model obtains 15% improvement over the myocardial segmentation model trained on real MR images.
- [91] [92]
3.3 交互式分割
交互式分割的两个优点:
- 医生可以在模型给出的初始分割图上修改,省时间;
- 模型可以根据医生修改后的更准确的分割图,继续训练,调整参数;
传统的交互式分割:
- GraphCuts, RandomWalks and ITK-Snap
CNN系列的交互式分割:
- Wang et al. [93] proposed the DeepIGeoS using the cascade of two CNNs for interactive segmentation of 2D and 3D medical images.
- Wang et al. [94] proposed the BIFSeg that is similar to the principle of GrabCut [143, 144].
- Rupprecht et al. [95] proposed a new interactive segmentation method named GM interacting that updates image segmentation results according to the input text from users.
3.4 其他工作
半监督学习 :
- Semi-supervised learning can use a small part of labeled data and any number of unlabeled data to train a model, and its loss function often consists of the sum of two loss functions. The first is a supervised loss function that is only related with labeled data. The second is an unsupervised loss function or regularization term that is related to both labeled and unlabeled data;
- Zhang et al. [96] proposed a semi-supervised learning framework based on the adversarial way between segmentation network and evaluation network.
- Similarly, some other semi-supervised frameworks [97-100] are also proposed to optimize medical image segmentation.
4. 未来研究计划
4.1 Network Architecture Search
- So far, NAS [101] has made significant progress in improving the accuracy of image classification. The NAS can be deemed to a subdomain of automatic machine learning [102] (AutoML) and has a strong overlap with hyperparametric optimization [103] and meta learning [104].
- 目前的NAS聚焦于三个点:search space, search strategy and performance estimation.
- Some improved CNN model based on NAS [105,106] have been proposed and applied to image segmentation.
- Isensee et al. [136] argued that too much manual adjustment on network structure could lead to over-fitting for a given dataset, and therefore proposed a medical image segmentation frameworkno newUNet (nnU-Net)that adapts itself to any new dataset.
- Weng et al [107] first proposed a NAS-UNet for medical image segmentation.
4.2 Graph Convolutional Neural Network
- The GCN [110] is one of the powerful tools for the study of non-Euclidean domains.
- Gao et al. [112] designed a new graph pooling (gPool) and graph unpooling (gUnpool) operation based on GCN and proposed an encoder-decoder model namely graph U-Net.
- Yang et al. [113] proposed the end-to-end conditional partial residual plot convolutional network CPR GCN for automatic anatomical marking of coronary arteries.
4.3 Interpretable Shape Attentive Neural Network
- NN的可解释性是一个重要课题;
- Sun et al. [108] proposed the SAU-Net that focuses on the interpretability and the robustness of models. The proposed architecture attempts to address the problem of poor edge segmentation accuracy in medical images by using a secondary shape stream.
- Wickstrm et al. [137] explored the uncertainty and interpretability of semantic segmentation of colorectal polyps in convolutional neural networks, and the authors developed the central idea of guided back propagation [138] for the interpretation of network gradients.
- Medical image analysis is an aid to the clinical diagnosis,the clinicians wonder not only where the lesion is located at, but also the interpretability of results given by networks. (医学的可解释性重要)
- Currently, the interpretation of medical image analysis is dominated by visualization methods such as attention and the class-activation-map (CAM). Therefore, the research on the interpretability of deep learning for medical image segmentation [114-117] will be a popular direction in future.
4.4 多模态数据融合
- Dou et al. [139] proposed a novel multi-modal learning scheme for accurate segmentation of anatomical structures from unpaired CT and MRI images, and designed a new loss function using knowledge distillation to improve model training efficiency [140].
- Moeskops et al. [141] investigated a question whether it is possible to train a single convolutional neural network (CNN) to perform same segmentation tasks on differentmodality data.
- More relevant literatures can be found in the review on multi-modal fusion for medical image segmentation using deep learning [142].
5. 讨论和展望
5.1 医学图像分割数据集
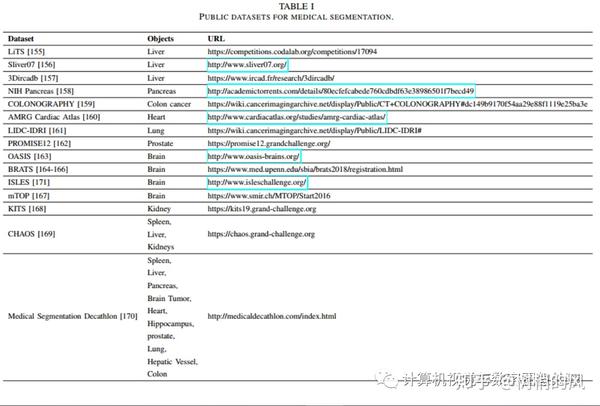

5.2 挑战和未来
存在的挑战 :
class imbalance, noise interference problems and serious consequences of missed tests;
- 网络结构的设计:
- skip connection的优化和提升设计;
- NAS搜索大的网络耗费GPU memory,难以实现,所以未来应该是NAS和手工设计相结合;First, a backbone network is designed manually, and then small network modules are searched by NAS before training.
- 卷积结构的设计,graph convolution的应用。
- loss function的设计:
- 对特定任务而言,cross-entropy loss+a specific regularization term逐渐流行;
- 基于NAS,搜索loss function;
- 迁移学习
- 模型可解释性
- 预处理和后处理
原文:
