近期发现阿里云的数据库备份一直在收钱,咨询发现是数据库大小超出免费限额,超出部分收取费用,不超出的免费。
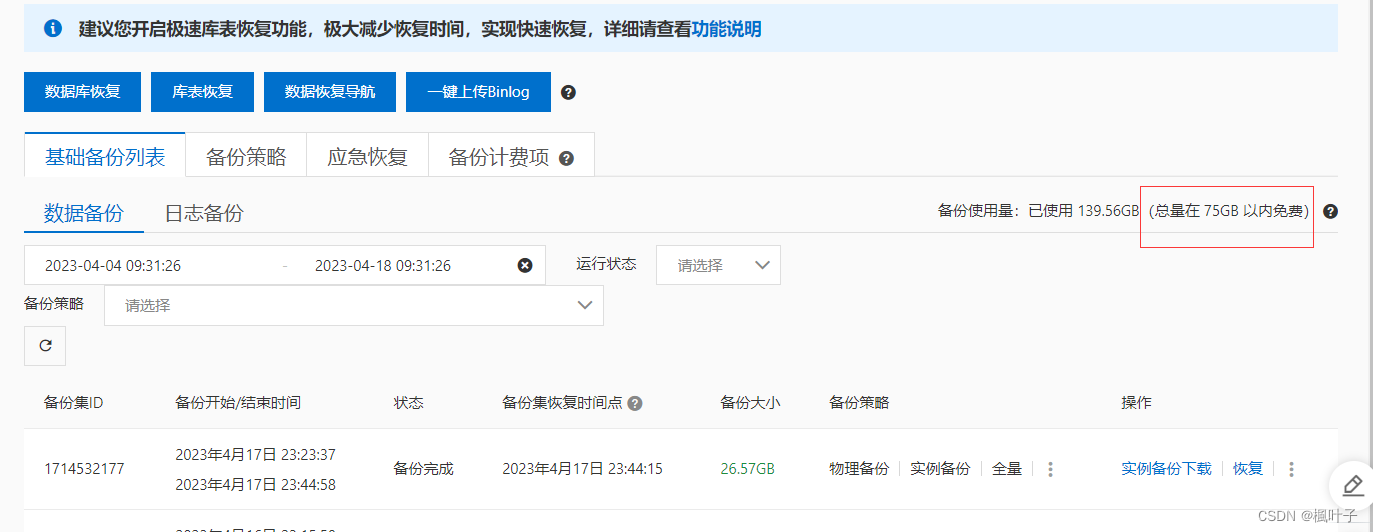
然后我就查看了下数据库的大小以及每张表存储数据的大小
USE information_schema;
SELECT CONCAT(ROUND(SUM((data_length+index_length)/1024/1024),2),'MB') AS DATA FROM TABLES
WHERE table_schema = 'xxx_prod'
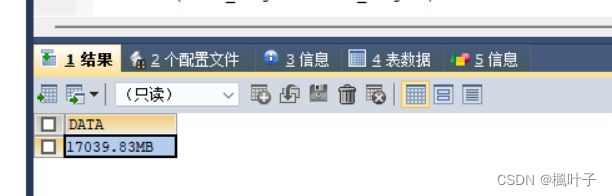
看到数据库总大小约17G
SELECT table_schema,table_name,data_free,
TRUNCATE ( data_length / 1024 / 1024, 2 ) AS '数据容量(MB)',
TRUNCATE ( index_length / 1024 / 1024, 2 ) AS '索引容量(MB)',
TRUNCATE ( ( data_length + index_length ) / 1024 / 1024, 2 ) AS '总大小(MB)'
FROM information_schema.TABLES
ORDER BY ( data_length + index_length ) DESC
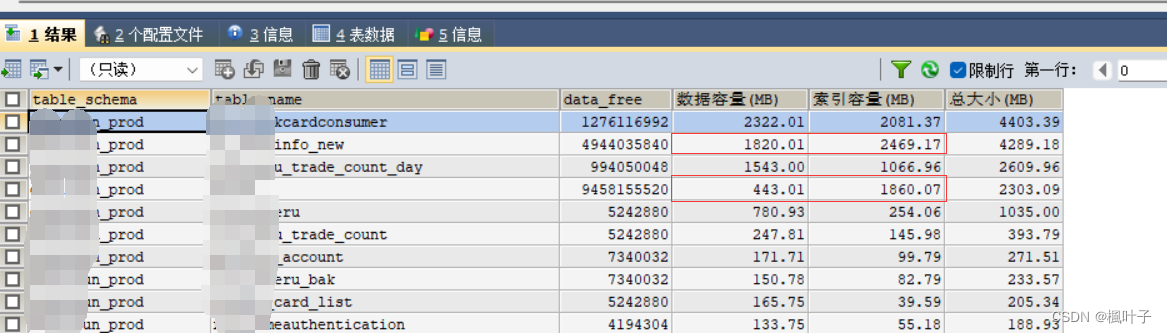
其中前几张表数据比较大的约4G,而且出现了索引的数据比数据本身占用了更多的存储。
1、首先解决方法是对没用的数据做了备份,数据容量少了一部分,单索引容量不明显。
2、再对表的索引进行了优化,过多重复数据的索引列取消了,再查看下发下还是没有变化。
3、检查到自增的主键已经达到千万级别
之前不用的数据已经清理或者备份了,若自增主键从1开始会节省很多的占用空间,所以先进行了更改下现有的主键
UPDATE table_name SET id = id - 最小id+1
让主键从1开始重新排列
再重置下自增主键
ALTER TABLE table_name AUTO_INCREMENT=最大ID-最小ID;
之后再查看下索引容量有明显下降,配置好备份策略就可以继续免费使用了
近期发现阿里云的数据库备份一直在收钱,咨询发现是数据库大小超出免费限额,超出部分收取费用,不超出的免费。之前不用的数据已经清理或者备份了,若自增主键从1开始会节省很多的占用空间,所以先进行了更改下现有的主键。2、再对表的索引进行了优化,过多重复数据的索引列取消了,再查看下发下还是没有变化。其中前几张表数据比较大的约4G,而且出现了索引的数据比数据本身占用了更多的存储。1、首先解决方法是对没用的数据做了备份,数据容量少了一部分,单索引容量不明显。然后我就查看了下数据库的大小以及每张表存储数据的大小。
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。我们知道,数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linearsearch),这种复杂度为O(n)的算法在数据量很大时显然是糟糕的,好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binarysearch)、二叉树查找(binarytreesearch)等。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二
1.所用到的数据结构?
B+树或hash表
这里data放到叶子节点上,非叶子节点可以存放更多索引,一个节点的最大存储容量约是16kb;同时,正因为叶子节点用指针相连,所以B+树支持范围查找,而hash索引不支持范围查找,故在正常开发中99.9%都是使用B+树结构.
2.MySQL中形容表常见的存储引擎?
(1)myisam存储引擎
在文件中存储的形式,有.frm文件(存储sql结构),.MYD文件(D指data,表
1:查询频繁 2:区分度高 3:长度小 4: 尽量能覆盖常用查询字段.
1: 索引长度直接影响索引文件的大小,影响增删改的速度,并间接影响查询速度(占用内存多).
针对列中的值,从左往右截取部分,来建索引
1: 截的越短, 重复度越高,区分度越小, 索引效果越不好
2: 截的越长, 重复度越低,区分度越高, 索引效果越好,但带来的影响也越大--增删改变慢,并间影响查询速度.
所以, 要在 区...
我认为应该把查询加上,尤其是看到美团技术团队写的一篇关于MySQL 索引原理及慢查询优化后,其中的查询主要是指查询优化以及编写高效率的 SQL 语句。
本文主要关注的是有关索引方面的,若未特别说明,以下内容默认是基于 MySQL Innodb存储引擎的 。
什么是索引
MySQL 官方对于索引的定义是:索...
* @return
public static PrivateKey getPrivateKeyByStream(byte[] pfxBytes, String priKeyPass) {
try {
String KEY_PKCS12 = "PKCS12";
KeyStore ks = KeyStore.getInstance(RsaConst.KEY_PKCS12);
char[] charPriKeyPass = priKeyPass.toCharArray();
ks.load(new ByteArrayInputStream(pfxBytes), charPriKeyPass);
Enumeration<String> aliasEnum = ks.aliases();
String keyAlias = null;
if (aliasEnum.hasMoreElements()) {
keyAlias = (String) aliasEnum.nextElement();
return (PrivateKey) ks.getKey(keyAlias, charPriKeyPass);
} catch (IOException e) {
// 加密失败
// log.error("解析文件,读取私钥失败:", e);
} catch (KeyStoreException e) {
// log.error("私钥存储异常:", e);
} catch (NoSuchAlgorithmException e) {
// log.error("不存在的解密算法:", e);
} catch (CertificateException e) {
// log.error("证书异常:", e);
} catch (UnrecoverableKeyException e) {
// log.error("不可恢复的秘钥异常", e);
[/code]

