我们先了解一下这个项目最终能达到的一个目标,然后以这个来进行项目的分析:
1、实现最基本的HTTP/1.0版本的web服务器,客户端能够使用GET、POST方法请求资源
2、服务器将客户请求的资源以html页面的形似呈现,并能够进行差错处理(如:客户请求的资源不存在时,服务器能够返回一个404的页面)
3、服务器能进行简单的cgi运行。比如当客户在表单中输入数据后,服务器能够将运行结果返回个客户
4、能够通过页面对数据库进行操作,如增删查改等操作
一、http服务器实现的基本框架
-
关于HTTP协议
即超文本传输协议,是互联网上应用最广泛的网络协议。它是应用层的协议,底层是基于TCP通信的。HTTP协议的工作过程:客户通过浏览器向服务器发送文档请求,浏览器将请求的资源回应给浏览器,然后关闭连接。即:连接->请求->响应->关闭连接。
-
关于URL
即统一资源定位符,每个网页都对应一个URL地址(俗称网址),具有全球唯一性。它包含的信息指出文件的位置以及浏览器应该怎么处理它。 一个完整的URL包括协议类型、主机类型、路径和文件名。
http协议的URL格式: http: //host[:port][abs_path] ,http表示使用http协议来进行资源定位;host是主机域名;port是端口号,一般有默认的;abs_path代表资源的路径。
这里我主要介绍项目中涉及的URL的两种格式—URL带参数和不带参数的。

GET方法使用的是带参数的URL,即传递的参数会使用?连接在资源路径后边;POST方法使用的是不带参数的URL,它的参数是通过http请求报头中的请求消息体传递给服务器的。
-
关于HTTP的请求与响应格式
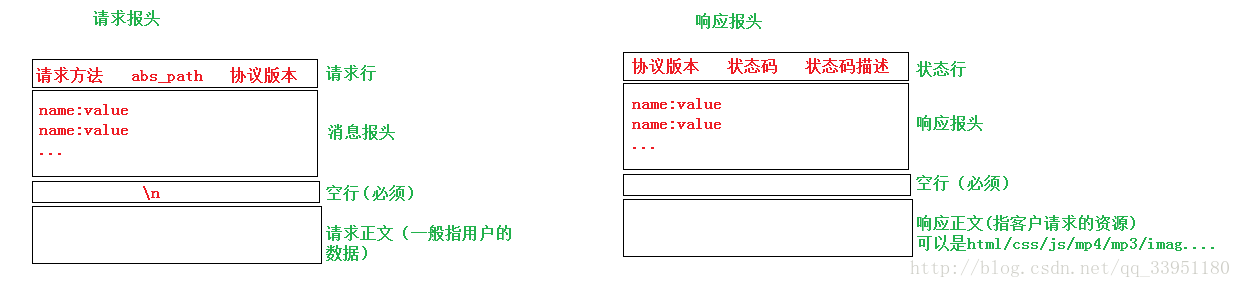
响应报头中的状态码和状态码描述,例如:当请求的资源不存在时,会收到“404 NotFound”的页面,404就是状态码,“NotFound”就是状态码描述,即请求的文件不存在。
二、服务器实现的基本思路
1、http协议是基于TCP通信的协议,因此,实现web服务器的第一步至少要能实现两个主机不同进程之间的TCP通信。
2、接下来的部分就是比较主要的处理逻辑了,当服务器收到请求后,首先应该分析请求方法(因为web服务器是要支持cgi的,但请求方法不同处理cgi也不同,这里我们只处理GET和POST方法)。
3、当方法确定后,应该拿到请求的URL,这一步是为了我们后边能处理GET和POST方法的cgi(GET和POST的参数位置不同,GET的参数在URL中,POST的参数在请求正文中)
4、判断资源是否存在,如果存在,判断这个资源是一个目录、普通文件还是一个可执行程序。之前几步我们已经提取到URL以及参数。GET方法:如果没有参数,就直接将请求的资源返回(即进入非cgi模式运行);否则,进入cgi模式内部运行;只要是POST方法就需要支持cgi:直接进入cgi函数内部运行。
非cgi模式:
进入非cgi模式时一定是GET方法且没有参数,此时进入echo_www()函数内部即可,该函数会将所请求的资源以html的格式返回给浏览器。
cgi模式:
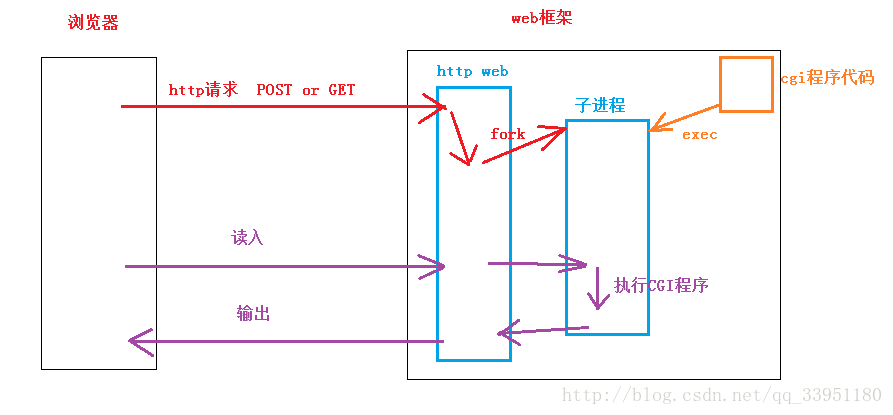
上述这张图描述了运行cgi时的过程,首先服务器要从浏览器上读取参数,然后需要fork出一个子进程进行cgi部分的处理,父进程通过环境变量的方式将参数转交给子进程,子进程运行完成后,将结果交给父进程,父进程再将数据输出给浏览器。在这个过程中可以将父进程看作一个所谓的中间量,只进行了参数的转交,因此可以将子进程的输入输出文件描述符进行重定向,即子进程直接与浏览器“联系”。
下面总结出父子进程内部各自需要干的事情:

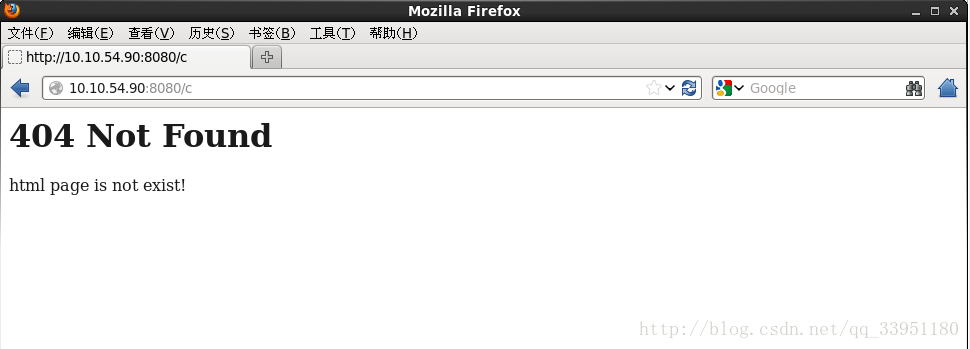
三、错误处理
错误处理这部分的实现可以参考echo_www()函数,但需要改变响应的消息报头的格式,即改变状态码,状态码描述,以及返回的页面。例如当请求的资源不存在时,服务器需要返回给浏览器一个默认的404页面,告诉客户请求的资源不存在。效果如图:
四、项目文件
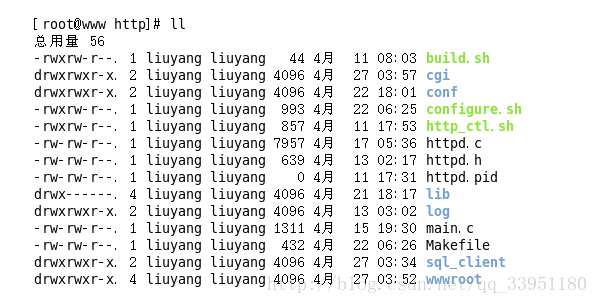
目录:
cgi:运行cgi部分的实现代码
conf:配置文件,存放需要绑定的服务器的ip和port
log:shell的日志文件以及http错误处理的日志文件
lib:mysql需要的lib库
sql_client:mysql部分的API及CGI实现
wwwroot:web服务器工作的根目录,包含各种资源页面(例如默认的index.html页面,差错处理的404页面),以及执行cgi的可执行程序
文件:
configure.sh:sheel脚本,运行该shell脚本后需要自动生成Makefile文件
http_ctl.sh:服务器控制脚本,需要实现服务器的启动、暂停以及重新启动
httpd.pid:与http_ctl.sh配合使用。如果把服务器变成守护进程在后台运行,重新启动时就需要检测服务器是否启动,该文件存放服务器启动以后的进程id
httpd.h:服务器的方法声明
httpd.c:方法实现
main.c:服务器的主逻辑
五、实现结果
请求资源存在:
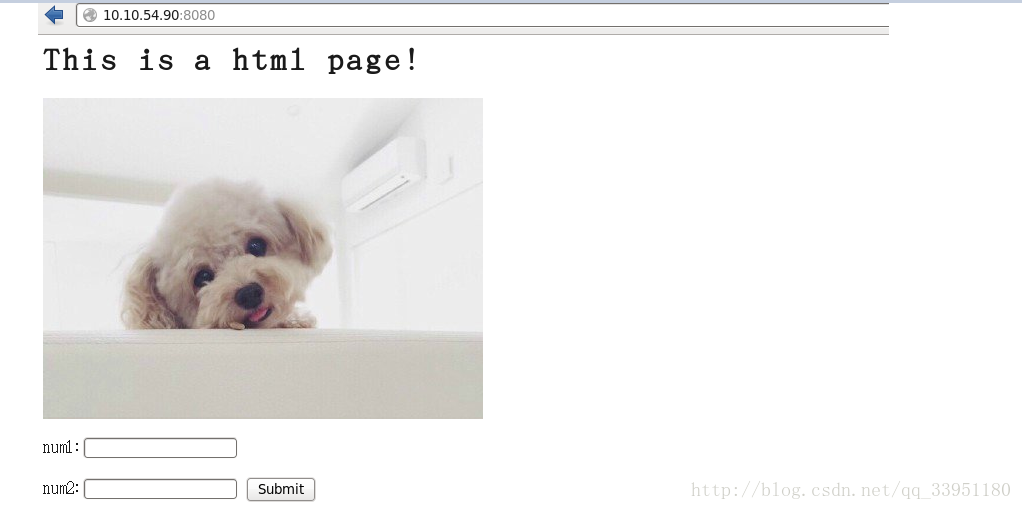
运行cgi后:

六、源码:
https://github.com/lybb/Linux/tree/master/httpd
附:
这里是我遇到的一些问题,粘出来,也可能是你遇到的问题:
1、本地环回测试ok,Linux下的浏览器测试也可以,但不能接外部的浏览器访问(没有设置桥接模式)嗯~要是在外部浏览器测试的话千万别忘记关闭防火墙
2、服务器应答时,没有将html格式的页面发送,而是将底层的实现代码展示在浏览器,并且在调试时将本来要打印的调试信息会打印到网页上(在回应空行时将send期望发送的数值写的太大,本来只需要发送两个字节的内容)
解决:先检查代码,思路正确,在容易出现问题的地方加入调试信息,最后将问题定位在echo_www()函数内
3、不能显示图片(这个问题是没有将所有发送的情况考虑完全,只考虑到目录、可执行程序,但没有考虑到如果请求的是一个路径明确的普通文件)
解决:测试请求一个路径明确的test.html文件,加入调试信息 ,将问题定位在:如果请求的资源存在,应该如何处理。对于普通文件,找到后并回显给浏览器;如果是目录,应答的是默认页面;如果是可执行程序,执行后返回结果
4、能显示图片后,但显示的不完整(原因:echo_www中,期望读取一行信息的line值太小,不能存下一张图片)
5、运行cgi模式时,每次提交数据并进行submit后都会自动出现提醒下载的页面
原因:在响应报头中,将Content-Type中的”text”写成”test”。而浏览器对于不能识别或解析的实体,都会提醒用户下载。
我们先了解一下这个项目最终能达到的一个目标,然后以这个来进行项目的分析: 1、实现最基本的HTTP/1.0版本的web服务器,客户端能够使用GET、POST方法请求资源 2、服务器将客户请求的资源以html页面的形似呈现,并能够进行差错处理(如:客户请求的资源不存在时,服务器能够返回一个404的页面) 3、服务器能进行简单的cgi运行。比如当客户在表单中输入数据后,服务器能够将运行结果返回个
一、实验目的及任务
1、熟悉并掌握WireShark的基本操作,了解网络协议实体间的交互以及报文交换。
2、通过对WireShark抓包实例进行分析,进一步加深对
HTTP
网络协议的理解。
3、编写一个简单的
Web
服务器
,
实现
作业(2)(3)项所要求的功能。
4、培养理论联系实践的科学研究精神。
二、实验环境
1、系统环境:Windows 10 家庭中文版 1607
2、浏览器:Chrome
3、WireShark:Versio
不管是什么
Web
服务器
,它们都能够接收请求资源的
HTTP
请求,将其内容回送给客户端
Web
服务器
实现
了
HTTP
和相关的
TCP
连接处理。负责管理
Web
服务器
提供的资源,以及对
Web
服务器
的配置、控制以及扩展方面的管理。
Web
服务器
逻辑
实现
了
HTTP协议
、管理着
Web
资源,并负责提供
Web
服务器
的管理功能。
Web
服务器
逻辑和操作系统共同负责管理
TCP
连接。底层操作系统负责计算机系统的硬件细节,并提供了
TCP
/IP网络支持、负责装载
Web
资源的文件系统以及控制当前计算活动的进程管理功能
第一步:接收客户端
什么是
web
server?
百度百科是这么解释的:
Web
Server中文名称叫网页
服务器
或
web
服务器
。
WEB
服务器
也称为WWW(WORLD WIDE
WEB
)
服务器
,主要功能是提供网上信息浏览
服务
。
Web
服务器
可以解析(handles)
HTTP协议
。当
Web
服务器
接收到一个
HTTP
请求(request),会返回一个
HTTP
响应(response),例如送回一个HTML页面。为了...
完整的
HTTP
过渡到
TCP
实现
客户端与
服务器
的交互过程
1.当客户端执行网络请求的时候,从url中解析出url的主机名,并将主机地址转换成ip
2.从url解析出
服务器
的所用端口号
3.客户端用
TCP
连接
服务器
4.连接成功后 获取输出流,将数据以报文的形式传递给
服务器
5.当
服务器
接收到数据之后,进行判断和解析码,并回应...
网站中浏览器端获取网页的过程
3、
http
请求作用:将要获取的内容以
http协议
的格式发送给
服务
端,
服务
端根据格式进行解析获取到其真实内容,将结果以
http协议
的格式回复给客户端
4、特点:
1、应用层协议,传输层使用
tcp
协议
2、简单、灵活,和多种语言对接方便
3、无状态的协议,即不记...
什么是
http
服务器
??
答:通过浏览器(客户端)对
服务器
的访问,连接远程的
http
服务器
,
服务器
通过分析
http
请求,构建
http
响应,将解析出来的数据返回给客户端,从外在表现就是得到一个相对应的
web
页面。
做这个项目我们最终达成的目标:
实现
一个基于
HTTP
/1.0版本的
web
服务器
,客户端能使用GET、POST方法请求资源
服务器
通..
Flask应用程序将在本地主机上的默认端口(5000)上启动。在
Web
浏览器中访问
http
://localhost:5000/ ,应该会看到“Hello, World!”的消息。
这就是一个基本的Flask
Web
服务器
的
实现
。可以通过添加其他路由和功能来扩展它。
Mika_Gu:

