|
|
|

Apache Airflow是一个强大的工作流程自动化和调度工具,它允许开发者编排、计划和监控数据管道的执行。EMR Serverless Spark为处理大规模数据处理任务提供了一个无服务器计算环境。本文为您介绍如何通过Apache Airflow实现自动化地向EMR Serverless Spark提交任务,以实现作业调度和执行的自动化,帮助您更有效地管理数据处理任务。
前提条件
-
已安装并启动Airflow服务,详情请参见 Installation of Airflow 。
-
已创建工作空间,详情请参见 创建工作空间 。
注意事项
当前EmrServerlessSparkStartJobRunOperator未输出实际作业的日志。如果您需要查看详细的作业日志,请登录EMR Serverless Spark控制台,通过任务运行ID找到对应的任务实例,然后,您可以在 日志探查 页签或者 Spark UI 中进一步检查和分析任务日志。
操作步骤
步骤一: 配置Apache Airflow
-
在Airflow的每个节点上安装airflow-alibaba-provider插件。
airflow-alibaba-provider插件是由EMR Serverless Spark团队提供,包含了一个专门用于提交EMR Serverless Spark任务的EmrServerlessSparkStartJobRunOperator组件。
pip install airflow_alibaba_provider-0.0.1-py3-none-any.whl -
添加Connection。
CLI方式
通过Airflow CLI执行相应命令来建立Connection,详情请参见 创建Connection 。
airflow connections add 'emr-serverless-spark-id' \ --conn-json '{ "conn_type": "emr_serverless_spark", "extra": { "auth_type": "AK", #指定使用阿里云的AccessKey(AK)方式认证。 "access_key_id": "<yourAccesskeyId>", # 阿里云账号的AccessKey ID。 "access_key_secret": "<yourAccesskeyKey>", # 阿里云账号的AccessKey Secret。 "region": "<yourRegion>" }'UI方式
通过在Airflow Web页面手动添加Connection,详情请参见 创建Connection 。
在 Add Connection 页面,配置以下信息。
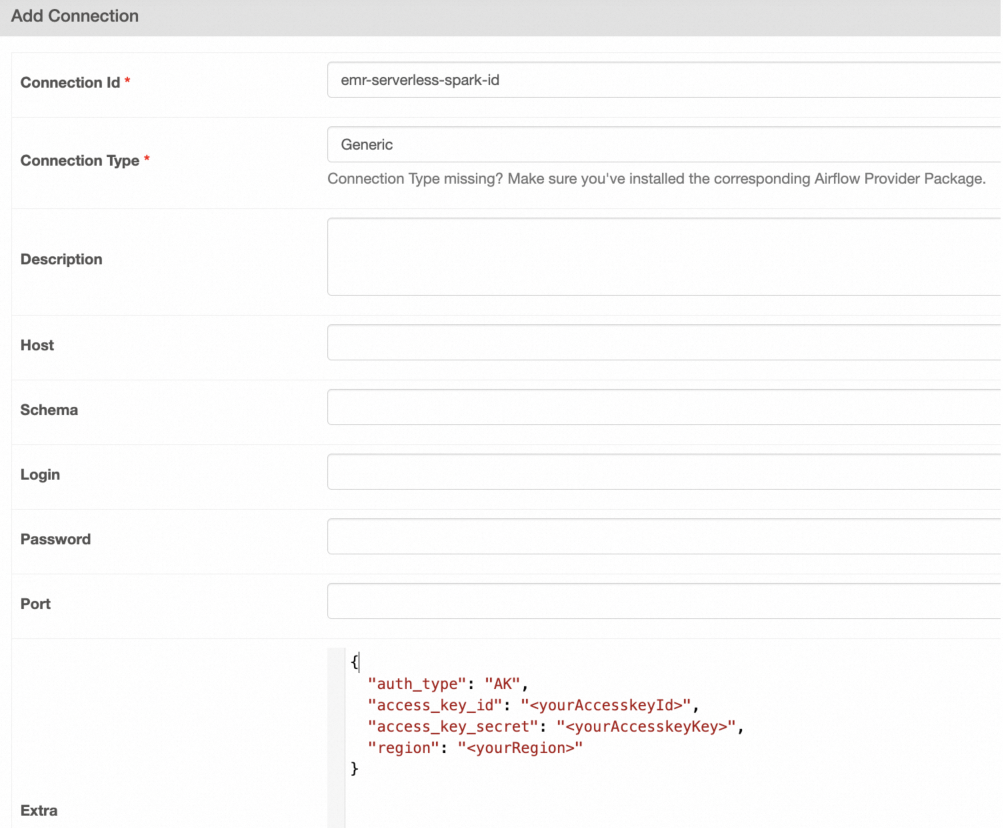
涉及参数如下表所示。
参数
说明
Connection Id
本文示例为emr-serverless-spark-id。
Connection Type
选择 Generic 。如果没有该类型,您也可以选择 Email 。
Extra
填写内容如下。
{ "auth_type": "AK", #指定使用阿里云的AccessKey(AK)方式认证。 "access_key_id": "<yourAccesskeyId>", # 阿里云账号的AccessKey ID。 "access_key_secret": "<yourAccesskeyKey>", # 阿里云账号的AccessKey Secret。 "region": "<yourRegion>" }
步骤二: DAG 示例
Airflow的DAG(Directed Acyclic Graph)定义允许您声明任务执行的方式,以下是通过Airflow使用EmrServerlessSparkStartJobRunOperator执行不同类型的Spark作业的示例。
提交JAR包
此场景涉及使用Airflow任务提交一个预编译的Spark JAR作业到阿里云EMR Serverless Spark。
from __future__ import annotations
from datetime import datetime
from airflow.models.dag import DAG
from airflow_alibaba_provider.alibaba.cloud.operators.emr import EmrServerlessSparkStartJobRunOperator
# Ignore missing args provided by default_args
# mypy: disable-error-code="call-arg"
DAG_ID = "emr_spark_jar"
with DAG(
dag_id=DAG_ID,
start_date=datetime(2024, 5, 1),
default_args={},
max_active_runs=1,
catchup=False,
) as dag:
emr_spark_jar = EmrServerlessSparkStartJobRunOperator(
task_id="emr_spark_jar",
emr_serverless_spark_conn_id="emr-serverless-spark-id",
region="cn-hangzhou",
polling_interval=5,
workspace_id="w-7e2f1750c6b3****",
resource_queue_id="root_queue",
code_type="JAR",
name="airflow-emr-spark-jar",
entry_point="oss://<YourBucket>/spark-resource/examples/jars/spark-examples_2.12-3.3.1.jar",
entry_point_args=["1"],
spark_submit_parameters="--class org.apache.spark.examples.SparkPi --conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.driver.cores=4 --conf spark.driver.memory=8g --conf spark.executor.instances=1",
is_prod=True,
engine_release_version=None
emr_spark_jar
提交SQL文件
在Airflow DAG中直接执行SQL命令。
from __future__ import annotations
from datetime import datetime
from airflow.models.dag import DAG
from airflow_alibaba_provider.alibaba.cloud.operators.emr import EmrServerlessSparkStartJobRunOperator
# Ignore missing args provided by default_args
# mypy: disable-error-code="call-arg"
ENV_ID = os.environ.get("SYSTEM_TESTS_ENV_ID")
DAG_ID = "emr_spark_sql"
with DAG(
dag_id=DAG_ID,
start_date=datetime(2024, 5, 1),
default_args={},
max_active_runs=1,
catchup=False,
) as dag:
emr_spark_sql = EmrServerlessSparkStartJobRunOperator(
task_id="emr_spark_sql",
emr_serverless_spark_conn_id="emr-serverless-spark-id",
region="cn-hangzhou",
polling_interval=5,
workspace_id="w-7e2f1750c6b3****",
resource_queue_id="root_queue",
code_type="SQL",
name="airflow-emr-spark-sql",
entry_point=None,
entry_point_args=["-e","show tables;show tables;"],
spark_submit_parameters="--class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver --conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.driver.cores=4 --conf spark.driver.memory=8g --conf spark.executor.instances=1",
is_prod=True,
engine_release_version=None,
emr_spark_sql
从OSS提交SQL文件
从阿里云OSS获取并执行SQL脚本文件。
from __future__ import annotations
from datetime import datetime
from airflow.models.dag import DAG
from airflow_alibaba_provider.alibaba.cloud.operators.emr import EmrServerlessSparkStartJobRunOperator
# Ignore missing args provided by default_args
# mypy: disable-error-code="call-arg"
DAG_ID = "emr_spark_sql_2"
with DAG(
dag_id=DAG_ID,
start_date=datetime(2024, 5, 1),
default_args={},
max_active_runs=1,
catchup=False,
) as dag:
emr_spark_sql_2 = EmrServerlessSparkStartJobRunOperator(
task_id="emr_spark_sql_2",
emr_serverless_spark_conn_id="emr-serverless-spark-id",
region="cn-hangzhou",
polling_interval=5,
workspace_id="w-ae42e9c92927****",
resource_queue_id="root_queue",
code_type="SQL",
name="airflow-emr-spark-sql-2",
entry_point="",
entry_point_args=["-f", "oss://<YourBucket>/spark-resource/examples/sql/show_db.sql"],
spark_submit_parameters="--class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver --conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.driver.cores=4 --conf spark.driver.memory=8g --conf spark.executor.instances=1",
is_prod=True,
engine_release_version=None
emr_spark_sql_2
从OSS提交Python脚本
从阿里云OSS获取并执行Python脚本文件。
from __future__ import annotations
from datetime import datetime
from airflow.models.dag import DAG
from airflow_alibaba_provider.alibaba.cloud.operators.emr import EmrServerlessSparkStartJobRunOperator
# Ignore missing args provided by default_args
# mypy: disable-error-code="call-arg"
DAG_ID = "emr_spark_python"
with DAG(
dag_id=DAG_ID,
start_date=datetime(2024, 5, 1),
default_args={},
max_active_runs=1,
catchup=False,
) as dag:
emr_spark_python = EmrServerlessSparkStartJobRunOperator(
task_id="emr_spark_python",
emr_serverless_spark_conn_id="emr-serverless-spark-id",
region="cn-hangzhou",
polling_interval=5,
workspace_id="w-ae42e9c92927****",
resource_queue_id="root_queue",
code_type="PYTHON",
name="airflow-emr-spark-python",
entry_point="oss://<YourBucket>/spark-resource/examples/src/main/python/pi.py",
entry_point_args=["1"],
spark_submit_parameters="--conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.driver.cores=4 --conf spark.driver.memory=8g --conf spark.executor.instances=1",
is_prod=True,
engine_release_version=None
emr_spark_python
涉及参数如下表所示。
|
参数 |
参数类型 |
描述 |
|
|
|
指定Airflow任务的唯一标识符。 |
|
|
|
指定Airflow用于连接EMR Serverless Spark的Connection ID。 |
|
|
|
指定EMR Spark所处的区域。 |
|
|
|
设置Airflow轮询任务状态的时间间隔,单位为秒。 |
|
|
|
EMR Spark工作区的唯一标识符。 |
|
|
|
用于指定EMR Spark任务所使用资源队列的ID。 |
|
|
|
任务类型,可以是SQL、Python或JAR,根据任务类型,entry_point参数将有不同的含义。 |
|
|
|
EMR Spark任务的名称。 |
|
|
|
指定启动任务的文件位置,例如JAR、SQL或Python文件。根据
|
|
|
|
传递给Spark程序的参数列表。 |
|
|
|
包含用于
|
|
|
|
指定任务运行的环境。当设置为True时,则表明任务将在生产环境中执行,
|
|
|
|
设定EMR Spark引擎的版本。默认值是"esr-2.1-native",对应Spark版本为3.3.1和Scala版本为2.12,使用原生运行时。 |