从概率分布的角度考虑,对于一堆样本数据,每个均有特征
X
i
对应分类标记y
i。
生成模型:学习得到联合概率分布P(x,y),即特征x和标记y共同出现的概率,然后求条件概率分布。能够学习到数据生成的机制。
判别模型:学习得到条件概率分布P(y|x),即在特征x出现的情况下标记y出现的概率。
数据要求:
生成模型需要的数据量比较大,能够较好地估计概率密度;而判别模型对数据样本量的要求没有那么多。
两者的优缺点如下图,摘自
知乎
生成模型:
以统计学和Bayes作为理论基础
1、朴素贝叶斯:
通过学习先验概率分布
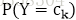 和条件概率分布
和条件概率分布
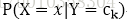 ,得到联合概率分布,然后对应分类时的后验概率为:
,得到联合概率分布,然后对应分类时的后验概率为:
使用极大似然估计(使用样本中的数据分布来拟合数据的实际分布概率)得到先验概率。
2、混合高斯模型:
3、隐马尔可夫模型 (HMM)
由隐藏的马尔可夫链随机生成观测序列,是生成模型。HMM是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。包含三要素:初始状态概率向量pie,状态转移概率矩阵A,观测概率矩阵B。
1、感知机 (线性分类模型)
输入空间为
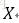 ,输出空间为
,输出空间为
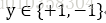 ,使用的映射函数为
,使用的映射函数为
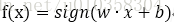 ,其中sign为符号函数 (输入大于等于1时输出为1;否则为0)。使用的损失函数为误分类点到超平面的总距离,即:
,其中sign为符号函数 (输入大于等于1时输出为1;否则为0)。使用的损失函数为误分类点到超平面的总距离,即:
其中M为所有误分类点的集合,||w||可以不考虑。可以使用随机梯度下降得到最后的分类超平面。
2、k近邻法
基于已知样本,对未知样本进行预测时,找到对应的K个最近邻,通过多数表决进行预测。没有显式的学习过程。
3、决策树
决策树在每个单元定义一个类的概率分布,形成一个条件概率分布。决策树中递归地选择最优特征,所谓最优特征即分类效果最好的特征,算法中使用信息增益 (information gain)来衡量,对应公式为:
其中D为训练集,A为待测试的特征,H(D)为熵 (经验熵),H(D|A)为条件熵,两者的计算为
但是以信息增益为划分,存在偏向于选择取值较多的特征,因此使用信息增益比来校正,
其中n为特征A的取值个数。
4、逻辑斯蒂回归模型
使用条件概率分布表示,
可以使用极大似然估计法估计模型参数,对优化目标使用梯度下降法或者拟牛顿法。
5、最大熵模型
原理:概率模型中,熵最大的模型是最好的模型,可以使用拉格朗日函数求解对偶问题解决。
6、支持向量机 (SVM)
SVM分为线性可分支持向量机 (硬间隔最大化)、线性支持向量机 (软间隔最大化)、非线性支持向量机 (核函数)三种。
目的是最大化间隔,这是和感知机最大的区别。
7、boosting方法 (AdaBoost等)
通过改变训练样本的权重,训练多个分类器,将分类器进行线性组合,提升分类性能。AdaBoost采用加权多数表决的方法。
8、条件随机场 (conditional random field, CRF)
给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机变量构成马尔可夫随机场。可应用于标注问题。
9、CNN
训练过程中,每一个中间层都有其功能,但其具体的功能无法知道。
1. 写在前面
今天补了一下
机器学习
的数学知识,突然又遇到了
判别
模型
和
生成
模型
这两个词语,之前学习统计学习方法的时候也遇到过,当时就模模糊糊的,如今再遇到,发现我还是没明白, 但这次哪有轻易再放过去之理?所以查了很多资料,试图结合自己理解的,把这个知识点整理整理,毕竟这个知识点也是面试官非常喜欢问的一个问题。
所以,下面我尽量把语言说的白话一些。
2. 判定
模型
VS
生成
模型
从本质上讲,
生成
模型
和
判别
模型
是解决分类问题的两类基本思路。 首先,你得了解,分类问题,就是我给定一个数据x,去判断它
对应
的标签y。
我的目标就是P(Y|X)。 下面我直接开门见山,先说一下这两种
模型
针对这个目标是怎么
这篇博客是自己在学习
生成
模型
与
判别
模型
过程中的一些记录,整理了相关的文章后写成,感谢前辈们的辛苦总结转载自:https://blog.csdn.net/zouxy09/article/details/8195017https://blog.csdn.net/lk7688535/article/details/52353350https://blog.csdn.net/Solomon1558/art...
您可以使用它从单个代码库为 Android、Windows、Linux、macOS、iOS、Web 等设备开发跨平台应用程序。它是由曾在谷歌工作过的 Evan You 创建的,目的是利用 Angular 的最佳部分并围绕它构建一个自定义工具。Bootstrap是一个框架,它使开发人员可以使用一组可重用的 HTML、CSS 和 JavaScript 代码轻松构建完全响应的网站或 Web 应用程序。您可以在软件工程的所有领域找到这些框架,包括 Web 开发(前端和后端)、移动应用程序、数据科学等等。
·
生成
模型
和
生成
对抗网络(GANs)是计算机视觉应用最新进展的核心。本文将介绍GANs及其不同的组件。有一些激动人心的GANs用例,快来探索!
你能辨别出下列图片中的奇怪之处吗?
这幅图片呢?
图中所有的实物和动物都由GANs这种计算机视觉
模型
生成
!它是目前深度学习中最流行的一类,可以激发人类潜藏的创造力。
GANs无疑是笔者在深度学习中最喜欢的话题之一,这些
模型
创造出的各种程序我都喜欢,比如
生成
新的人脸图像或创造图画,还有修复旧画中遗失的部分!
这篇文章将介绍
生成
网络和GANs,了解其各种程序,并进一步探索工作机
判别
方法(Discriminative approach)
由数据直接学习决策函数Y=f(X)或者条件概率分布P(Y|X)作为预测的
模型
,即
判别
模型
。
判别
方法关心的是对于给定的输入X,应该预测什么样的输出Y。基本思想是有限样本条件下建立
判别
函数,不考虑样本的产生
模型
,直接研究预测
模型
。典型的
判别
模型
包括k近邻,感知级,决策树,支持向量机等。
生成
方法(Generative approach)
由数据学习联合概率密度分布P(X,Y),然后由
机器学习
可以分为两大类:
生成
式
模型
(Generative Model)、
判别
式
模型
(Discriminative Model)。 现在有一堆球,颜色信息已知为绿色和黄色两种,有且仅有这两种颜色,这里,球的颜色为y(目标变量),坐标轴上位置为特征X。我们想要知道,如果在坐标轴的某一位置x新放入一个球,这个球会是什么颜色的? 1.
生成
式
模型
的思想:
生成
式
模型
使用的是联合概率P(X,Y),若已知x(球的坐标位置信息),通过计算出P(X,Y)我们就可以知道球的颜色。 P(X,Y) = P(Y)*P(X|Y),其中
生成
模型
与
判别
模型
1.定义2.通俗解释例1:猫狗分类例2:如何确定一只羊是山羊还是绵羊例3.识别一种语言是哪种语言例4.跟踪问题3.如何选择哪种
模型
主要来源:[白话解析] 深入浅出最大熵
模型
生成
模型
(Generative Model, GM):先对联合概率P(x,ω)P(x, ω)P(x,ω)建模,然后再求取后验概率
模型
。
判别
模型
(Discriminative Model, DM):从数据集D中直接估计后验概率
模型
:
P(ω1∣x),P(ω2∣x),...,P(ωN∣x)P(ω_1 | x)
判别
式
模型
(Discriminative Model):直接对条件概率p(y|x)进行建模,常见
判别
模型
有:线性回归、决策树、支持向量机SVM、k近邻、神经网络等;
生成
式
模型
(Generative Model):对联合分布概率p(x,y)进行建模,常见
生成
式
模型
有:隐马尔可夫
模型
HMM、朴素贝叶斯
模型
、高斯混合
模型
GMM、LDA等;
生成
式
模型
更普适;
判别
式
模型
更直接,目标性更强
生成
式
模型
关注数据是...
从概率分布的角度考虑,对于一堆样本数据,每个均有特征XiX_iXi
对应
分类标记yiy_iyi。
生成
模型
:学习得到联合概率分布P(x,y),即特征x和标记y共同出现的概率,然后求条件概率分布。能够学习到数据
生成
的机制。(
生成
模型
就是要学习x和y的联合概率分布P(x,y)P(x,y)P(x,y),然后根据贝叶斯公式来求得条件概率P(y∣x)P(y|x)P(y∣x),预测条件概率最大的y)
判别
模型
:学习得到条件概率分布P(y|x),即在特征x出现的情况下标记y出现的概率。(
判别
模型
就是直接学习条
一、名词解释
生成
方法由数据学习联合概率风波P(X,Y),然后求出条件概率分布P(Y|X)为预测的
模型
,即
生成
模型
:
P(Y∣X)=P(X,Y)P(X)P(Y|X)=\frac{P(X,Y)}{P(X)}P(Y∣X)=P(X)P(X,Y)
这样的方法之所以称为
生成
方法,是因为
模型
表示了给定输入X产生输出Y的
生成
关系。典型的
生成
模型
由朴素贝叶斯法和隐马尔可夫
模型
。
判别
方法由数据直接学习决策函数f(X)或者条件概率分布P(Y|X)作为预测
模型
,即
判别
模型
。
判别
方法关心的是对给定的输入X,应该预测什么样的输出

