|
|
|

请问UVM中,RAL的mirror值是干什么用的?
关注者
2
被浏览
106
登录后你可以
不限量看优质回答
私信答主深度交流
精彩内容一键收藏


要弄清mirror值是干什么用的,首先必须对寄存器模型中的相关基本概念有个清楚的认识。
讨论寄存器模型中涉及到各种值以及对应的方法,我们还是要从其中的最小存储单元uvm_reg_field开始讲起
uvm_reg_field
我们先看看uvm_reg_field的定义
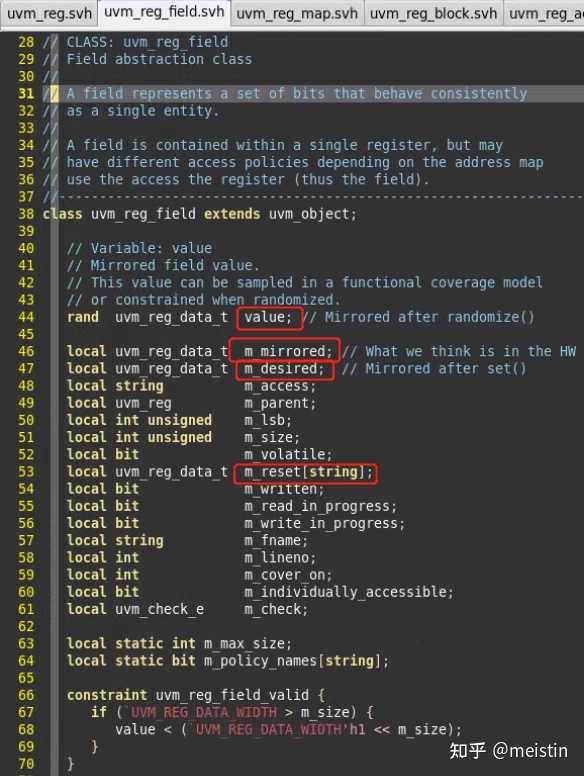
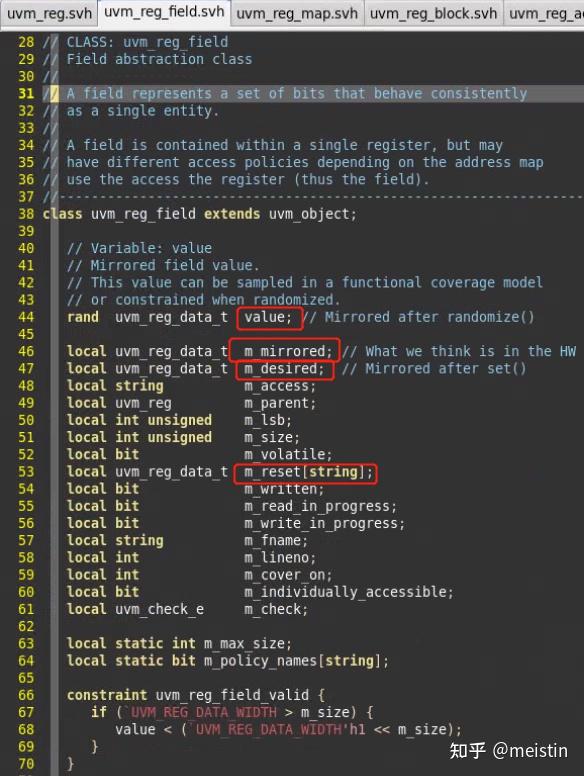
我们可以看到这里涉及到了4个值类型:
1、value:唯一一个没有被local修饰的值类型,即寄存器模型可以直接访问,也是唯一一个用rand修饰的字段,即对寄存器模型里的寄存器进行随机时value用来存储随机后的随机值(关于这个随机值的值内容有什么特点我们后面会具体讲),并且这个值也是我们对寄存器模型收集覆盖率所sample的值。
2、m_mirrored(镜像值):存放我们认为此时DUT里寄存器的实际值。
3、m_desired(期望值):存放我们期望DUT寄存器被赋予的值。
4、m_reset["HARD"](复位值):存放硬复位值。m_reset其实是一个以字符串为索引(key)以uvm_reg_data_t为值(value)的联合数组类型,除了默认的key="HARD"类型的硬复位值,我们还可以添加我们自定义的复位类型对。
上面这4种值类型,除了value都是用local修饰的,即除了uvm_reg_field本身和它的子类,其他外部类都无法直接访问,所以自然就需要提供一些访问(写和读)它们的函数。
首先我们看下我们创建uvm_reg_fiedl都会调用的configure()函数具体都执行了什么
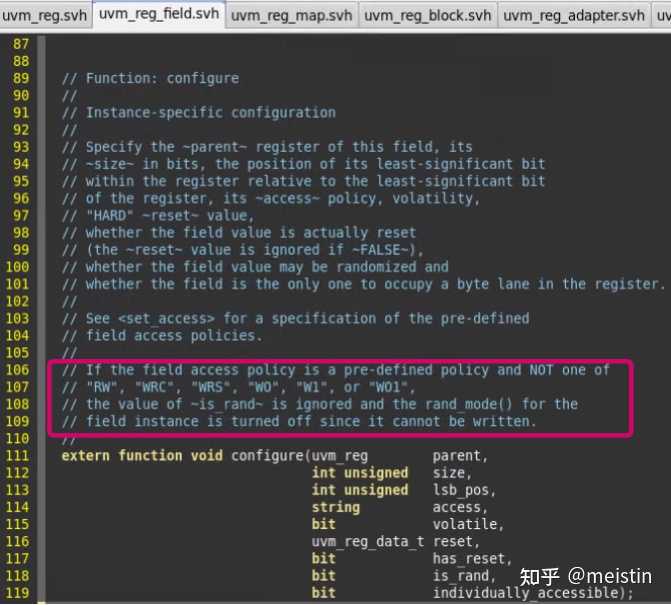
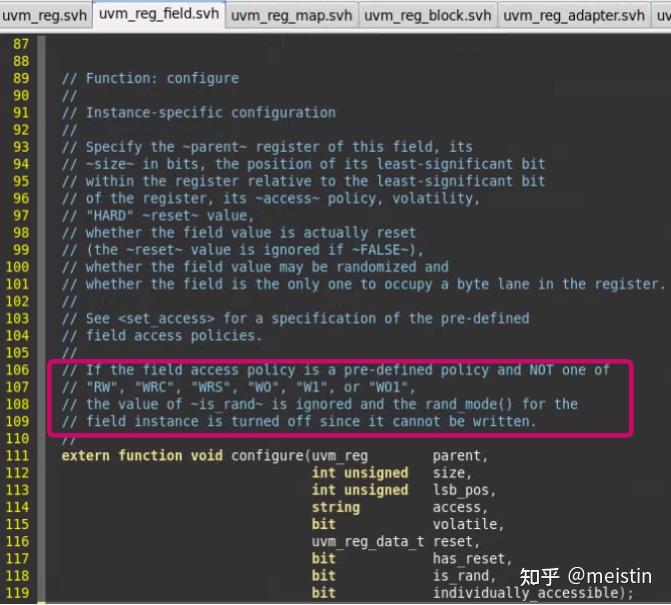
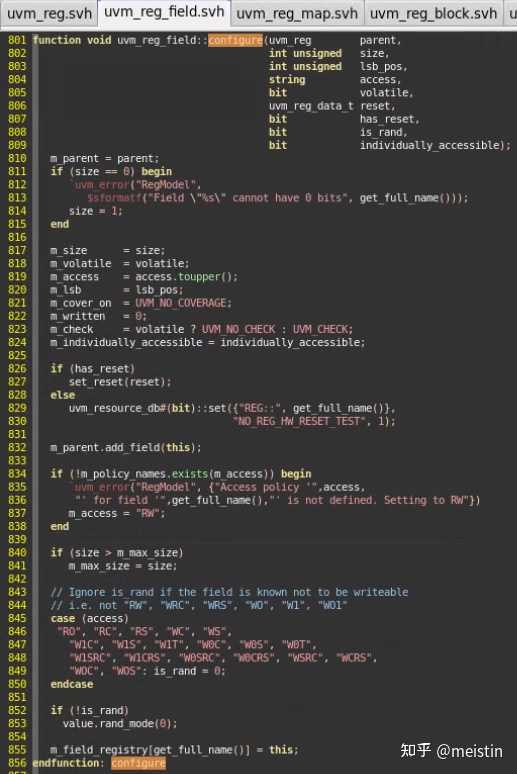
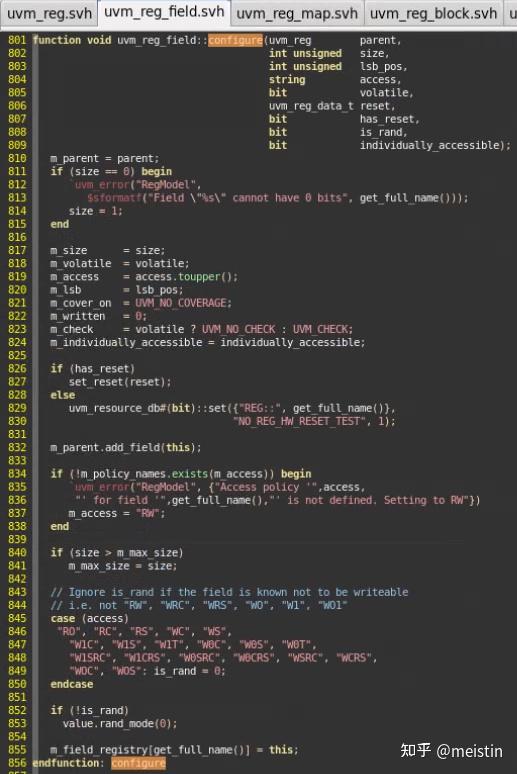
这里需要注意的几点就是,当在uvm_reg中调用某个uvm_reg_field的configure()函数时:
1、has_reset参数决定了m_reset["HARD"]是否被赋值,赋值内容为reset参数所给的值
2、access和is_rand共同决定了在执行randomize的时候value值是否会被随机。
set_reset()


这里我们涉及到了第一个修改uvm_reg_field里复位值的函数set_reset(),我们可以通过调用 set_reset() 函数实现对m_reset[string]关联数组的赋值,这样便可以覆盖我们在调用寄存器模型初始化configure的硬复位值,全局修改m_reset["HARD"]值,当然也可以自定义添加其他复位值类型。
reset()
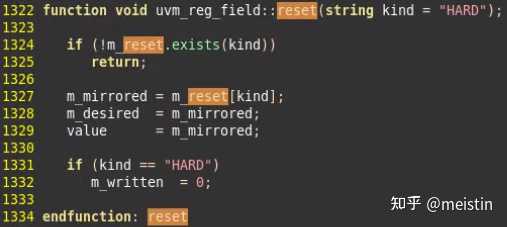
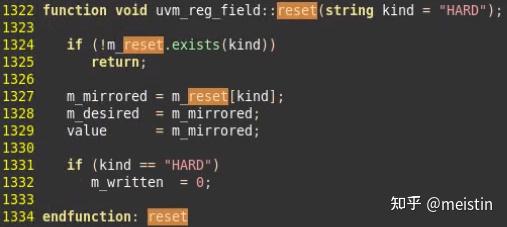
这是与复位相关的另一个函数,它实现了将uvm_reg_field中m_mirred、m_desired、value都赋值成我们预先设置的reset值(reset值即可以是默认的key="HARD",也可以是我们预先定义的key对应的reset值),同时将m_written变量赋值为0表示该uvm_reg_field没有被写过,纵观整个uvm_reg_field类的定义,只有在do_predict()函数里才有涉及到将m_written赋值为1的情况,后面我们再具体介绍do_predict()函数,这里先埋个伏笔。
set_reset()和reset()是用来修改reset值,而获取reset值包含如下两个函数
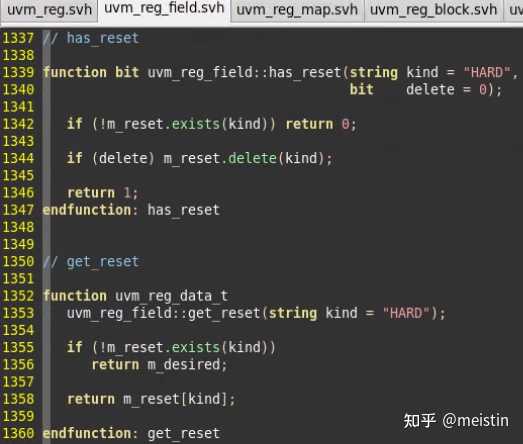
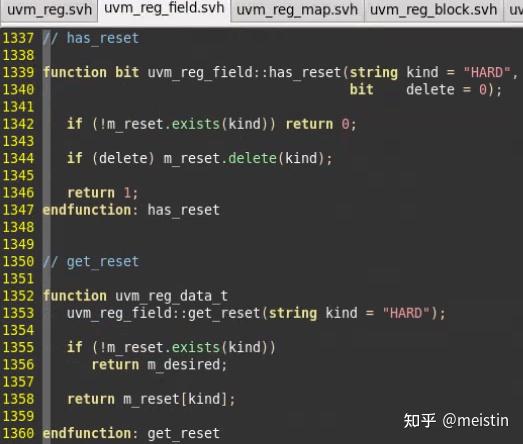
has_reset()
判断对应reset类型(kind参数)是否有reset值
get_reset()
获取某种reset类型(kind参数)的reset值,如果不存在该reset类型,则返回m_desired(期望值)
关于reset值相关的函数就介绍到这里,下面介绍剩余三种值的读写相关的函数。
set()
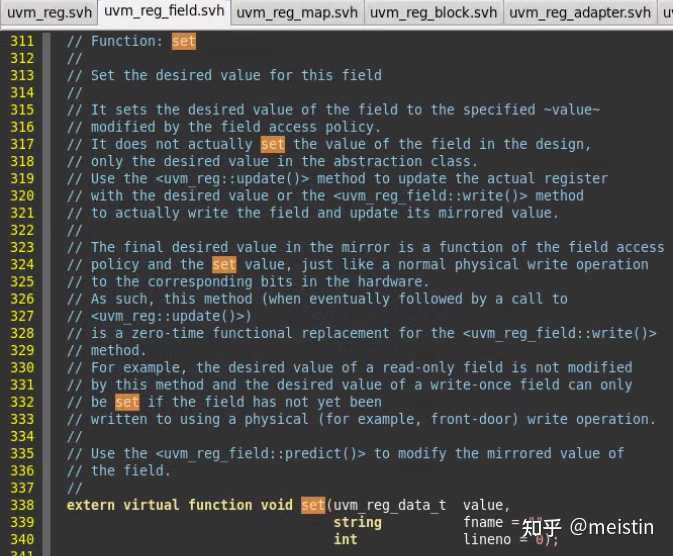
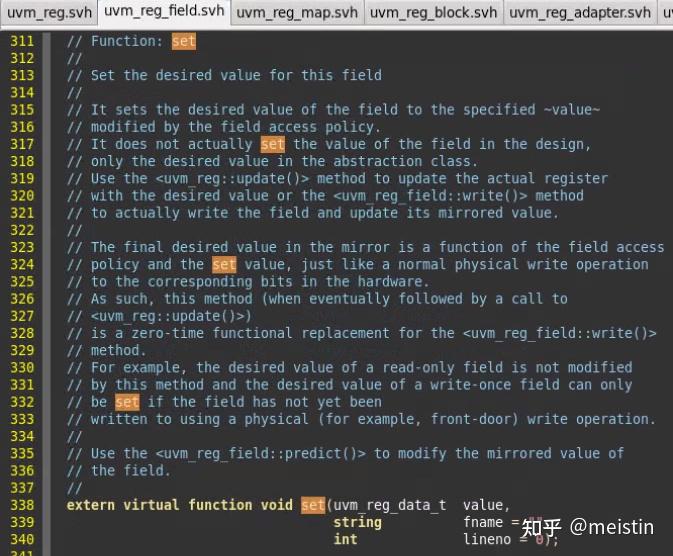
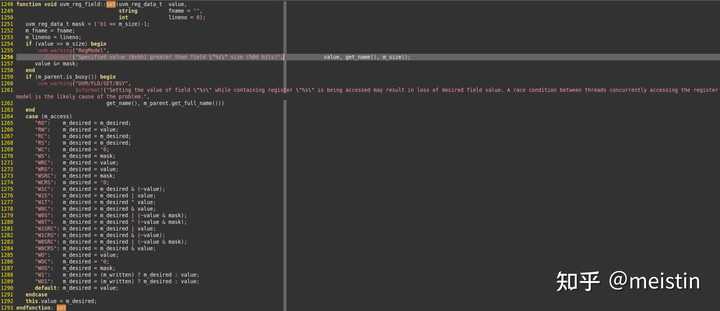
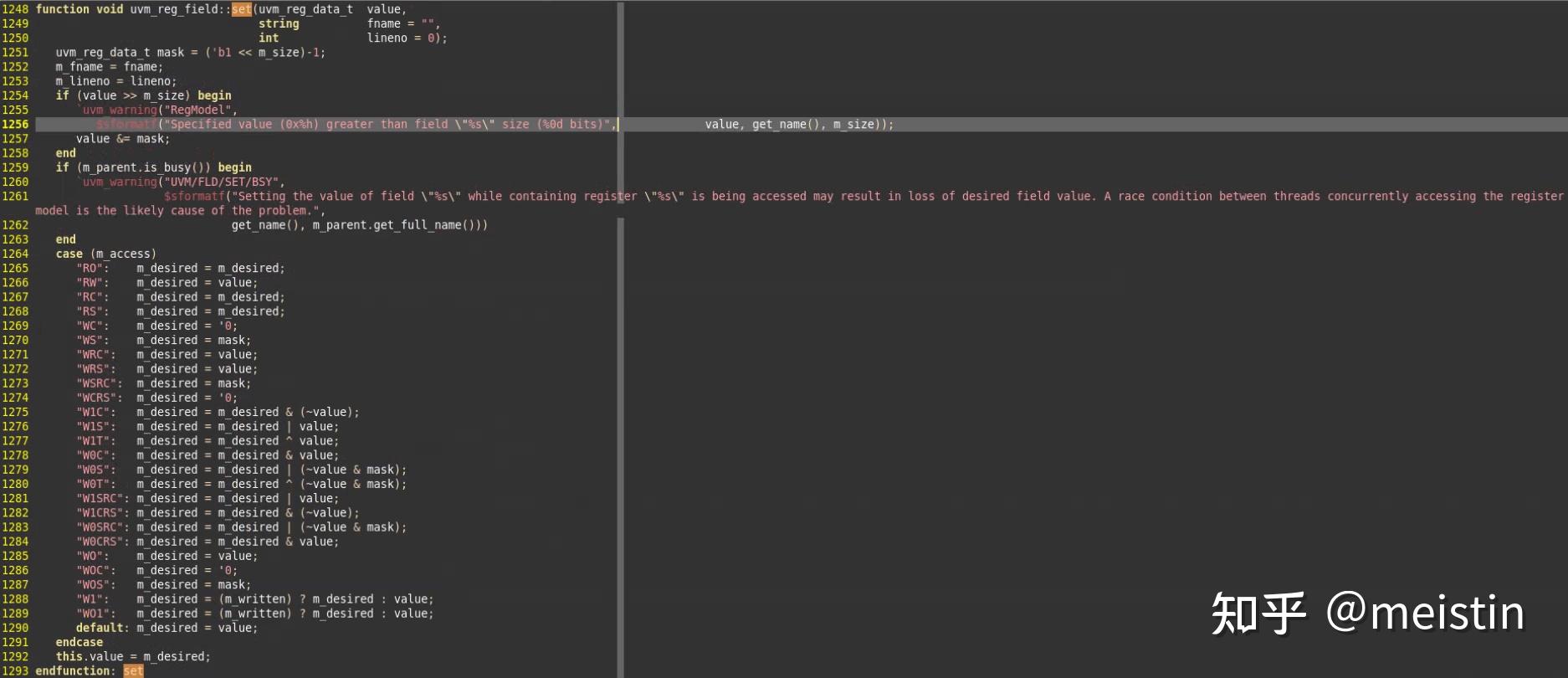
set()函数修改的是寄存器模型中调用该函数的uvm_reg_field的m_desired(期望值),并且根据configure()时配置的m_access(访问类型)来限制期望值设置的值的范围(函数中case...endcase中间的内容),同时将value值更新为最新的m_desired值。
注意这里修改的仅仅是寄存器模型中的m_desired和value值,并不涉及任何与dut相关的寄存器值的修改。
这里的参数fname和lineno我们先不深入分析,一般情况下也都是使用的缺省值。
get()
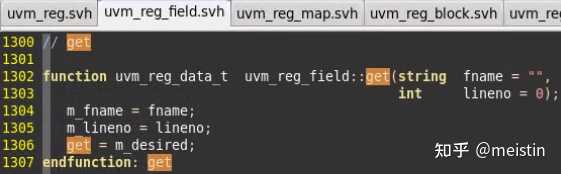
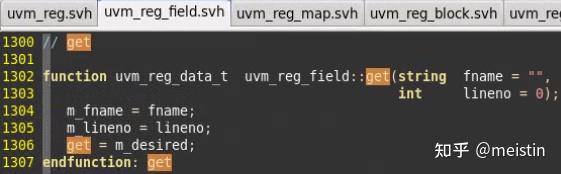
get()是与set()的关系类似于reset()与get_reset(),用来获取调用uvm_reg_field的m_desired(期望值)。
randomize()
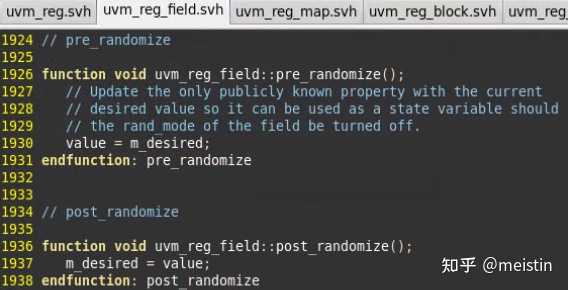
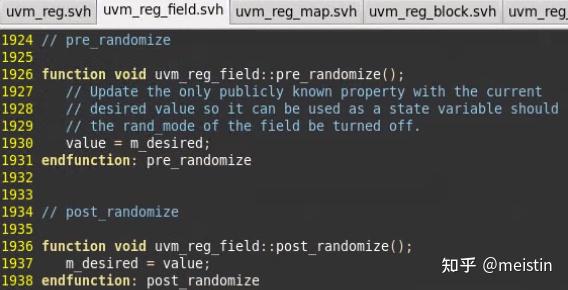
这里并没有定义randomize()函数,而是定义了相应的callback函数来对randomize()前后的行为进行一定的约束,我们知道randomize()实际是对value值做的随机,在randomize()前会自动调用pre_randomize()将m_desired的值赋给了value,这样如果rand_mode被设置为0,那么value值就使用了m_desired。而post_randomize()则是将随机后的value值更到m_desired中。由此我们得出这么个结论,randomize()功能类似于set()了一个随机的值。
mirror()
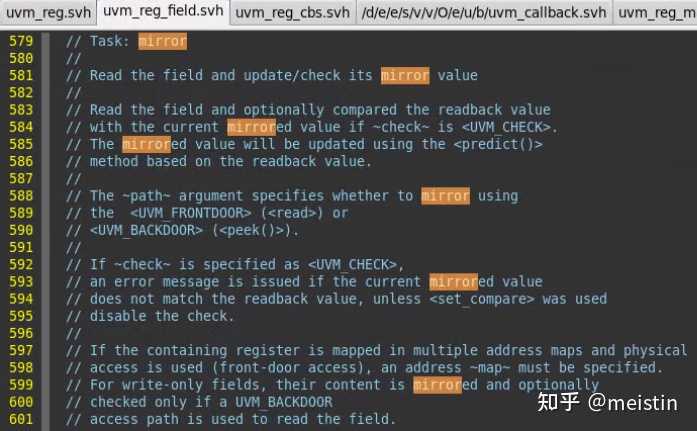
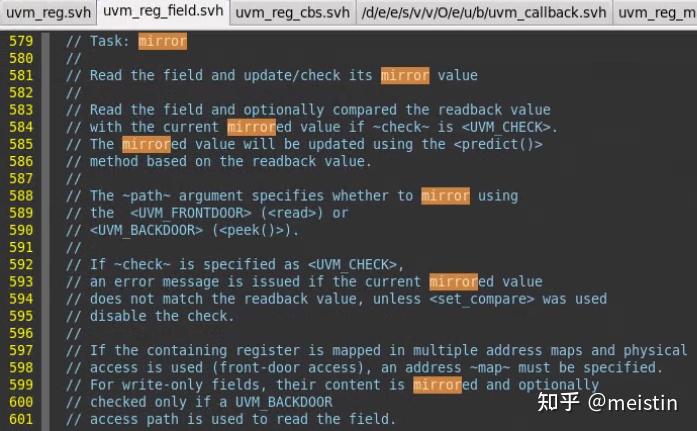
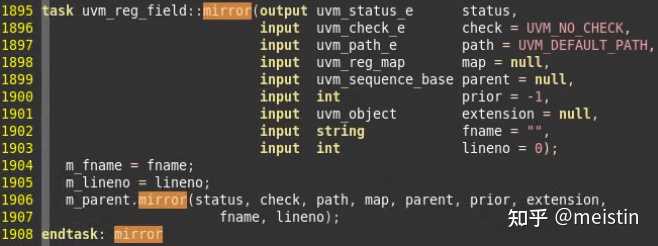
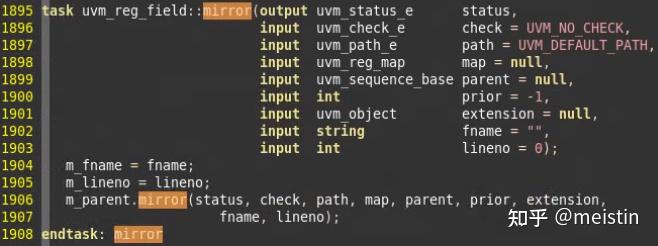
uvm_reg_field的mirror函数会调用它所在uvm_reg中mirror函数,如下图所示
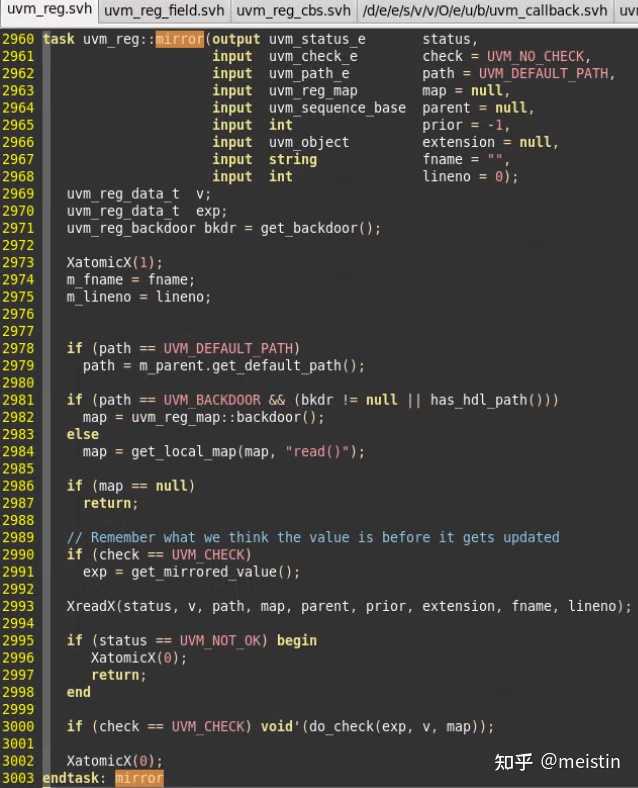
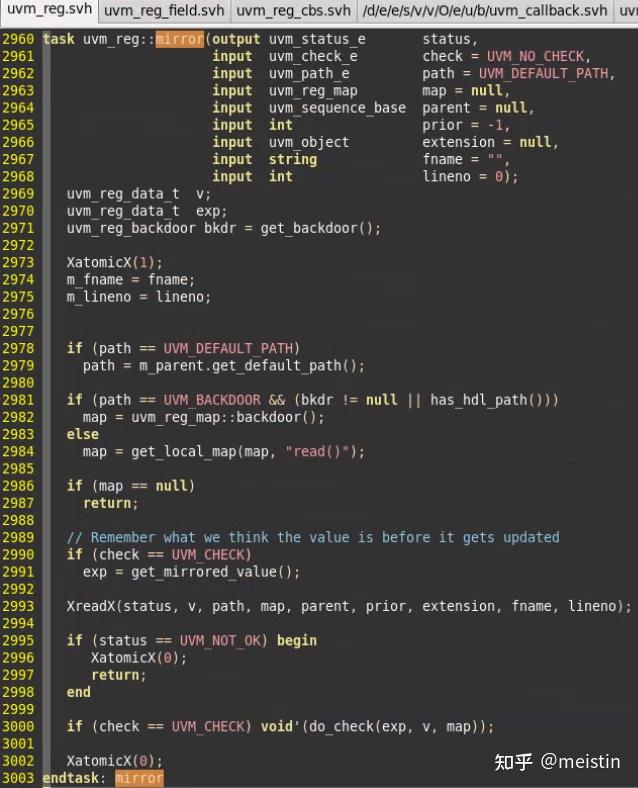
具体的方法实现细节我们就不赘述了,简而言之mirror()任务相关知识点总结如下:
1、mirror()任务主要功能是通过所在uvm_reg发起的read()行为获取dut中寄存器对应reg_field的值(UVM_FRONTDOOR是消耗时间的,因而这里用的task,而不同于上面提到的都是function),并将值更新到m_mirrord(镜像值)和m_desired(期望值)。
2、check参数用于检查当DUT中的值与寄存器模型中的值不一致时是否报错,当参数check配置为UVM_CHECK时一般用来检查寄存器模型和DUT有没有发生与预期不一致的行为,例如DUT内部错误更改了某个寄存器等等。而如果仅仅是为了将寄存器模型跟DUT的寄存器保持同步而调用mirror,则需要将check参数配为UVM_NO_CHECK或使用default值。关于这个check参数还有一点需要注意的是,当我们把该uvm_reg_field的volatile(易失性)字段configure为1时,即使我们调用mirror的时候把check配置为UVM_CHECK,实际也不会执行check功能,这是因为易失性这个属性使得我们无法精确预测DUT中该寄存器域的值,因而check的意义就不大了。
3、使用mirror任务更新寄存器模型中镜像值和期望值可以是uvm_reg(寄存器)级别的更新,也可以是uvm_reg_field(寄存器域)
get_mirrored_value()
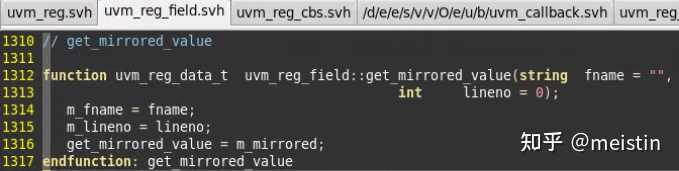
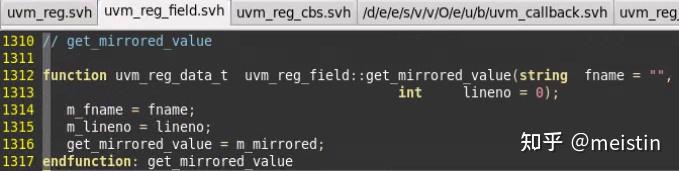
返回m_mirrored(镜像值)
needs_update()
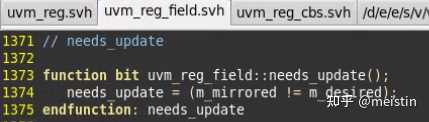
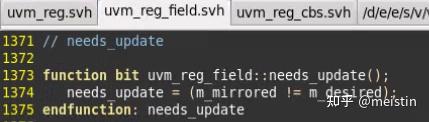
update()这个函数定义在了uvm_reg中,后面我们将uvm_reg中的方法的时候会具体介绍,简而言之就是说当m_mirrored与m_desired不相等时就讲m_mirrored值更新为m_desired值,并执行总线write行为将DUT上对应的寄存器也更新为m_desired值。
有了以上背景知识,我们不难清楚needs_update()函数的作用就是比较m_mirrored与m_desired是否相等,判断是否需要执行寄存器级别的update操作。
write()
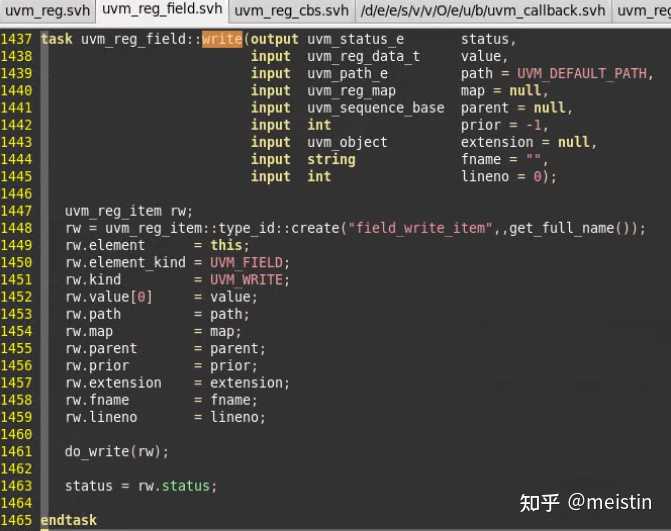
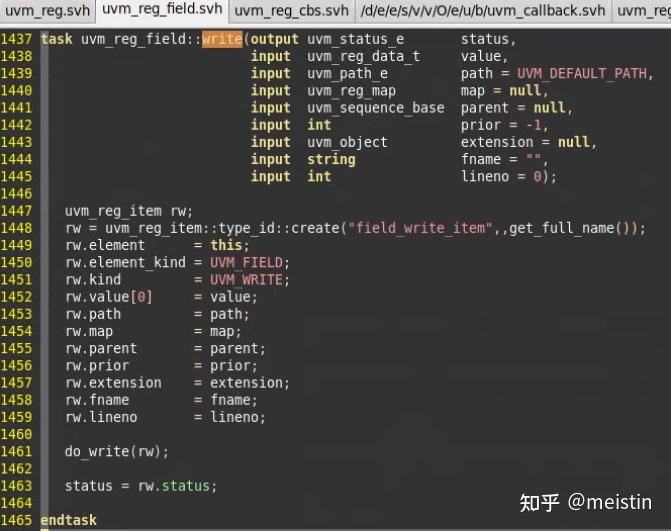
具体的执行内容在do_write()任务中,具体我们就不详细分析了,uvm_reg_field中write()与uvm_reg()中的write()功能类似,都是将value值以path(UVM_FRONTDOOR或UVM_BACKDOOR)的方式写入到DUT中,同时将寄存器模型中的m_mirrored和m_desired值更新为value。
read()
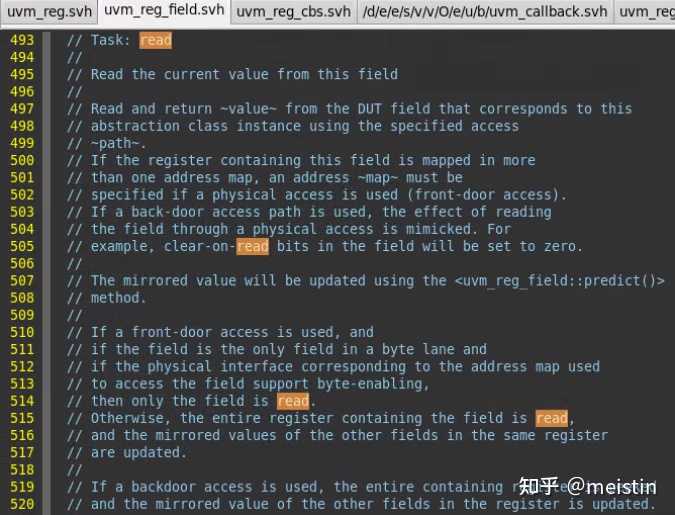
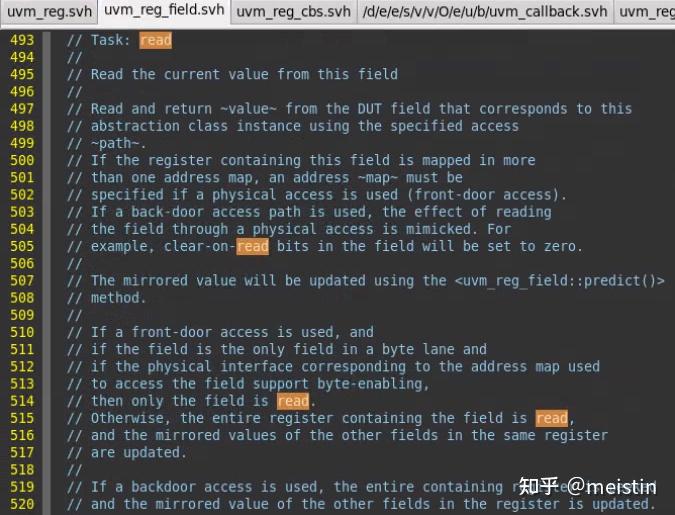
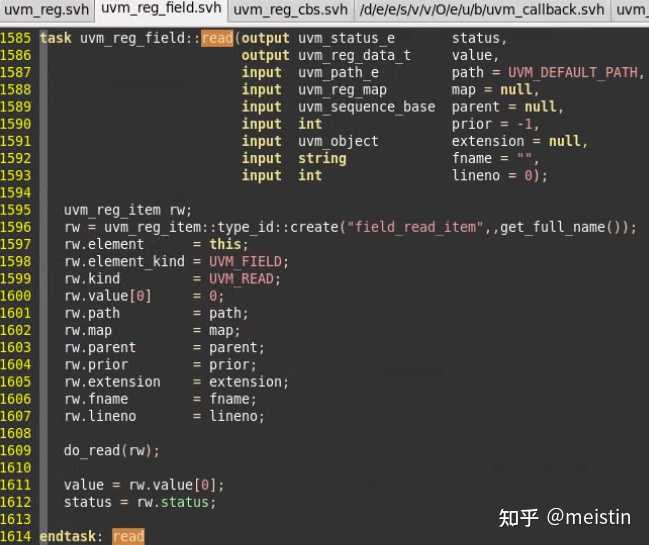
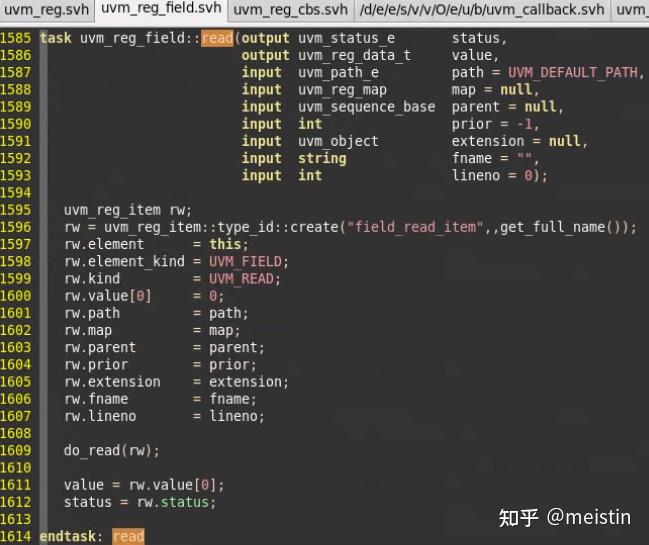
以path(UVM_FRONTDOOR或UVM_BACKDOOR)的方式从DUT中获取寄存器某个reg_field的值,同时将值更新到寄存器模型中的m_mirrored和m_desired中。
这里需要注意的就是当我们read的reg_field包含在多个byte中时,那么会将相关byte都读出来,这会导致除我们想读的reg_field之外的其他包含在同一个byte中的reg_field对应的m_mirrored和m_desired的值也会被更新。
peek()
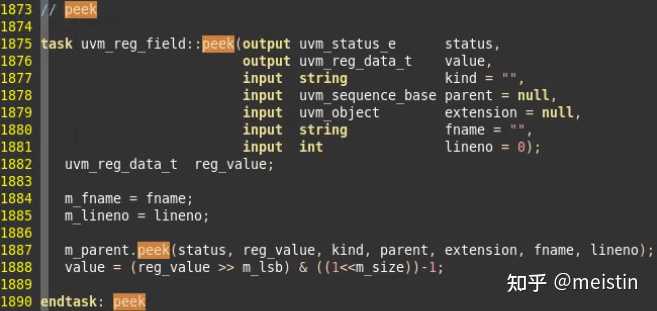
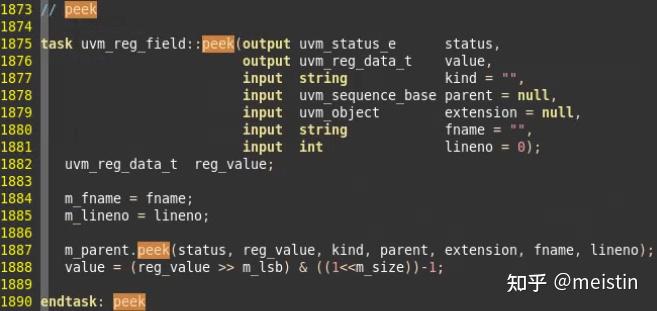
又是一个调用了uvm_reg_field所在uvm_reg中方法的方法,这里我们就不详细介绍这个peek方法的执行过程了,简而言之总结如下:
1、通过backdoor的方式获取DUT中相应reg_field的值作为任务参数返回,同时将寄存器模型中对应的m_mirrored和m_desired值更新。
2、peek()与read()的UVM_BACKDOOR模式的区别在于read()会受m_access的影响,如果寄存器是WO类型是无法被读出的,但是peek()不受m_access影响,会将DUT中寄存器的值通过backdoor的方式读出。
3、peek()之前必须设置好对应寄存器的BACKDOOR的hdl_path路径,否则无法读取(关于backdoor的访问方式,我们会开专门的专题进行介绍)
poke()
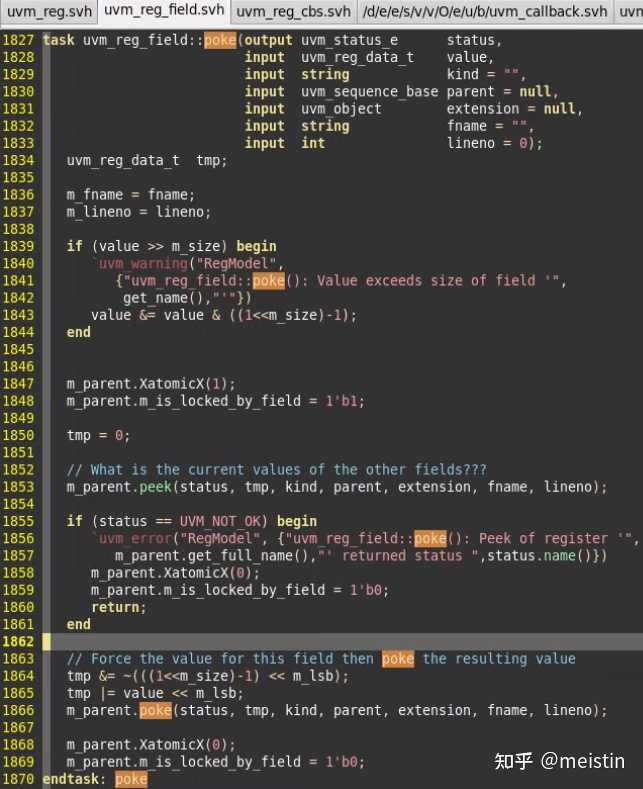
与peek()相对应的任务,通过backdoor的方式将uvm_reg_field值写入到DUT中,同时将寄存器模型中对应的m_mirrored和m_desired值更新,类似于peek()的特点,poke()与write()的区别也在于poke不受m_access值的限制,即使是RO的寄存器也是可以通过peek()改写DUT和寄存器模型中的值,poke调用之前也需要设置好对应寄存器的BACKDOOR的hdl_path路径。
predict()
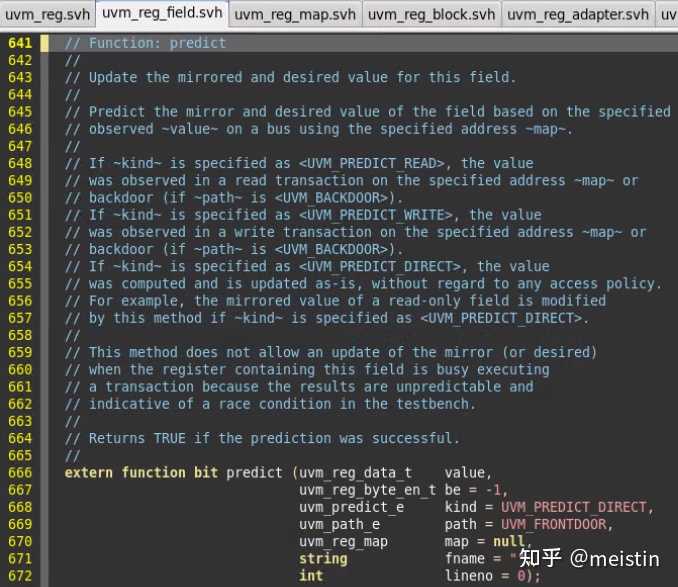
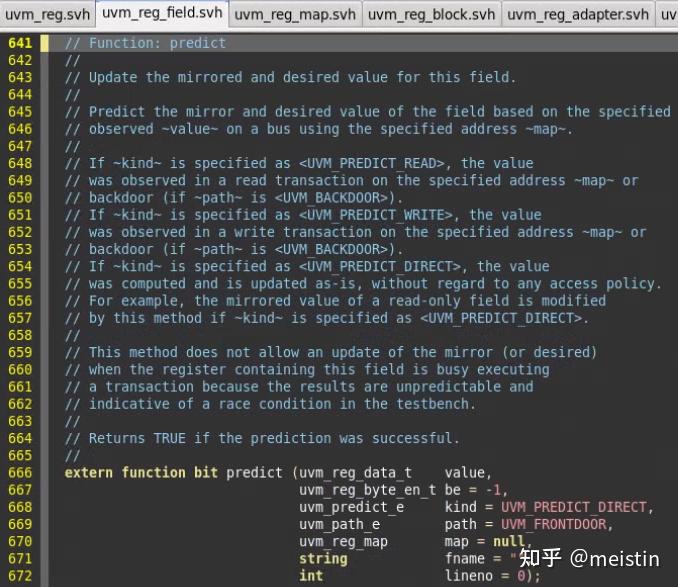
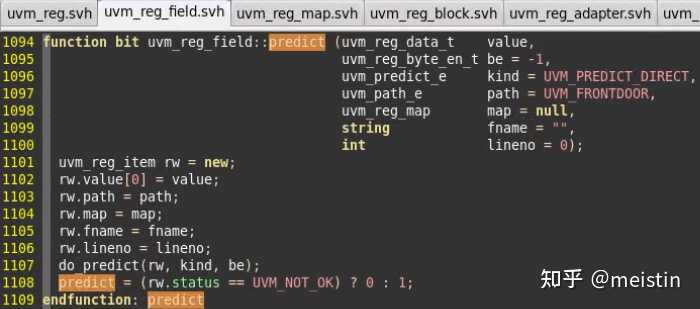
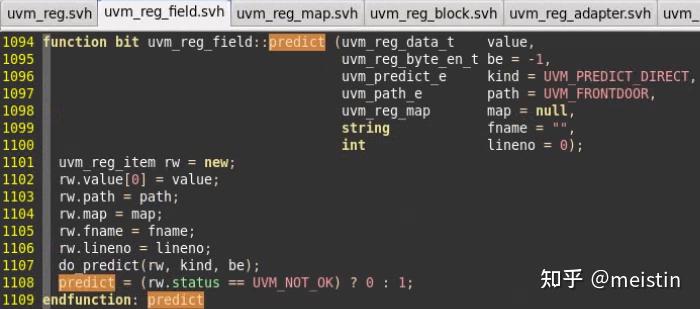
do_predict()代码line 1114-1203这里就不截图了,通过对predict()函数的描述,简而言之可以提取以下要点:
1、函数作用是更新m_mirrored(镜像值)和m_desired(期望值)
2、predict是有返回值的,predictc()成功后返回1,否则返回0
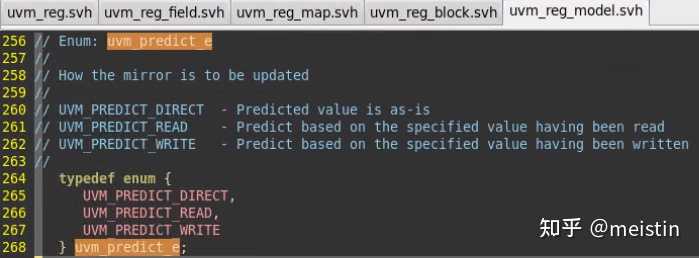
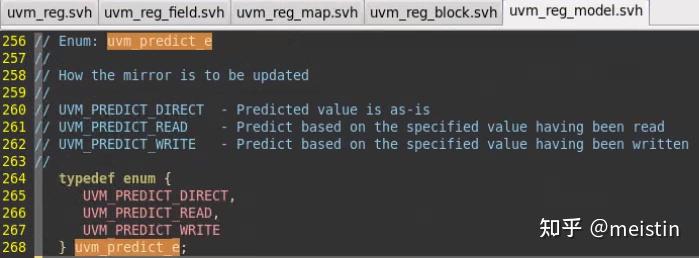
3、更新的m_mirrored值内容受多个参数的影响,kind对应枚举类型定义如下图所示。
UVM_PREDICT_DIRECT表示不需要经过read/write行为直接将value值更新到对应的m_mirrored和m_desired值上,并不会考虑该uvm_reg_field的m_access(访问属性)值是否可写(例如RO也会被更新),这种调用存在一定的风险,需要建立在对该uvm_reg_field足够了解,并且如果此时该uvm_reg_field所在的uvm_reg不处于空闲状态,那么predict()结果会返回0(错误标志)。UVM_PREDICT_DIRECT的一大特点就是不会涉及到任何DUT中寄存器值的操作,仅仅操作的是寄存器模型中的值。
UVM_PREDICT_READ(UVM_PREDICT_WRITE)则会在指定map的address上发起相应的读(写)行为来获取对应的值以更新m_mirrored和m_desired,当然这里也可以指定访问方式是UVM_BACKDOOR,这两种方式都涉及到访问DUT。
4、predict()我们一般不会直接调用,predict功能涉及到一个auto_predict和手动predict概念,通常我们在使用寄存器模型时,相关组件的connect_phase()都会带上下面这句话,即打开了自动预测的功能,这样我们就不需要写专门的predictor来执行do_predict()的行为。

auto_predict存在的问题就是只有当我们通过寄存器模型来访问DUT时,才会更新寄存器模型中的m_mirror等值,如果我们发起了一个读写sequence来访问DUT,那这个行为并不会反映到我们寄存器模型中,因而也不会更新寄存器模型中的任何值。为了解决上述问题,我们需要自己写predictor来手动调用do_predict(),当然调用do_predict()这个行为UVM源代码已经帮我们在uvm_reg_predictor中实现了,我们只需要写一个从uvm_reg_predictor继承而来的my_predictor,然后将bus_in这个imp连接到monitor上的analysis_port上,同时将上面截图里的代码替换为ral.default_map.set_auto_predict(0)即可实时监测interface上的行为达到实时更新m_mirrored等值的目的,关于这部分代码的具体实现后续我们会专门开章节介绍,这里先简单说明下。
至此,我们关于uvm_reg_field中相关值变量的读写方法就介绍的差不多了,下面我们介绍一下uvm_reg中相关值变量的读写方法。
uvm_reg
首先我们还是看下uvm_reg中变量的声明
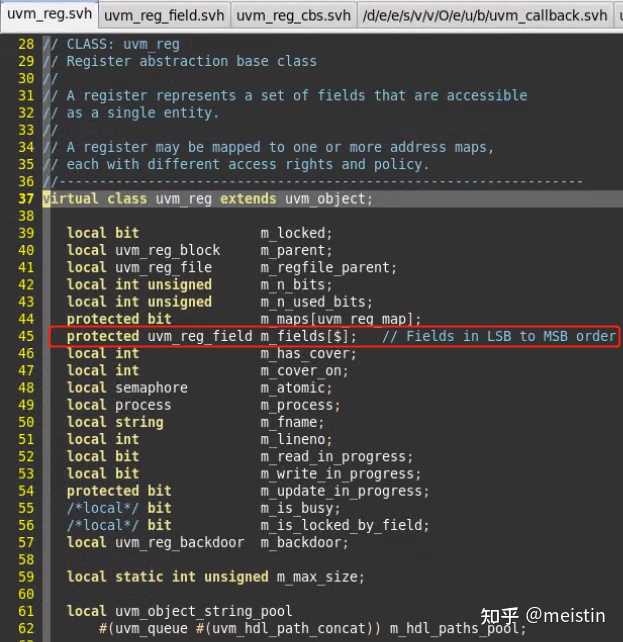
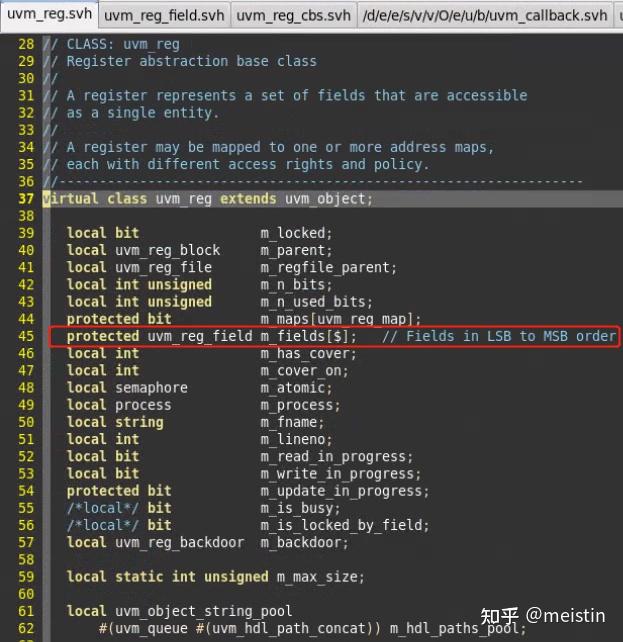
我们发现并没有出现想uvm_reg_field中具体的值变量的声明,取而代之的是一个uvm_reg_field的队列,每一个uvm_reg都是通过调用add_field将相应的uvm_reg_field包含到其中的,通过lsb或者msb加上size来安排具体的offset位置。显而易见,在uvm_reg中就没有了镜像值、期望值这种说法了,uvm_reg操作的是完整一个寄存器,那涉及到寄存器值的读写有哪些方法呢?
set()
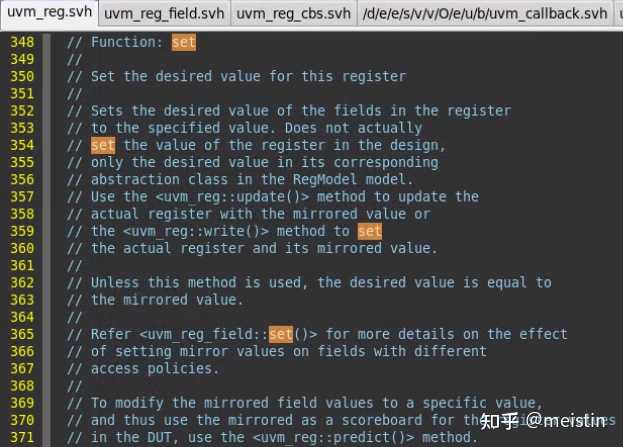
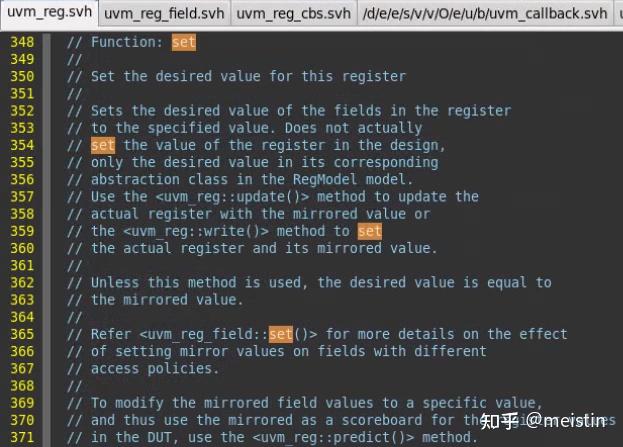
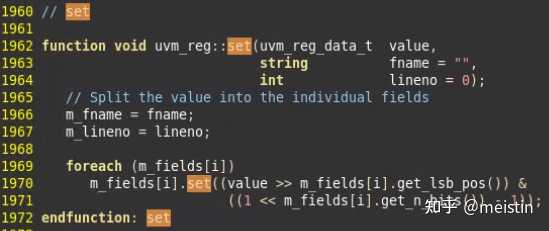
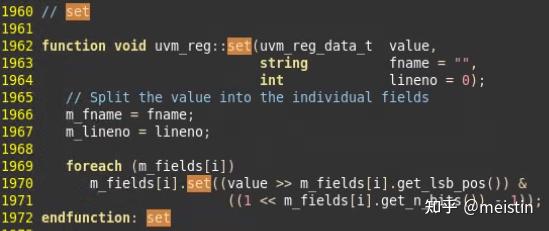
uvm_reg中调用set()相当于遍历的调用其中所有uvm_reg_field的set()函数,这种原理类似递归调用所有uvm_reg_field中的同名方法的包括get()、reset()、get_reset()、has_reset()、needs_update()、get_mirrored_value(),我们就不具体截图展开描述了。
有些方法执行的功能与uvm_reg_field类似,仅仅是执行的内容由寄存器域替换为了寄存器,这里我们也不具体展开了,例如write()、read()、predict()、poke()、peek()、mirror()我们也不截图展开描述了。
下面我们讨论一些uvm_reg_field中没有的或者不同的方法
update()
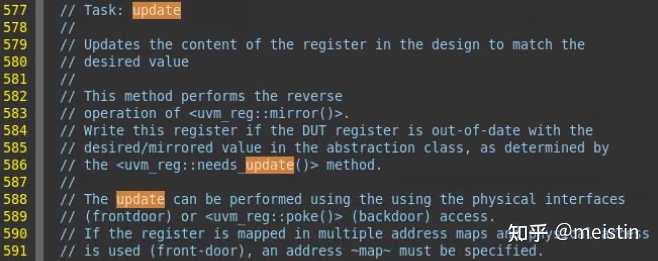
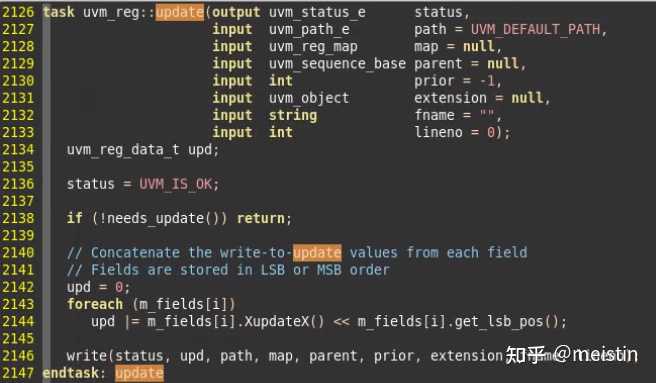
update()由于涉及到可能执行的UVM_BACKDOOR写DUT的行为,所以潜在消耗时间的行为,因而是一个task。update()功能是遍历所有uvm_reg包含的uvm_reg_field看是否有其中m_mirrored值与m_desired值不相等的,只要有一个不相等就会执行对DUT的write()行为,write的值为所有uvm_reg_field的m_desired中拼起来的uvm_reg值,path可以选择UVM_FRONTDOOR或者UVM_BACKDOOR。
backdoor_read()
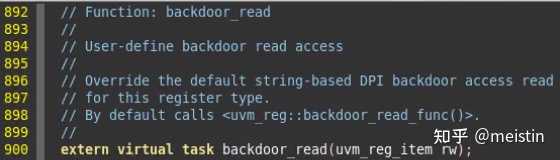
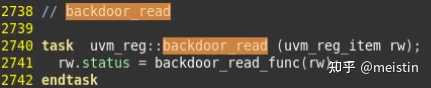


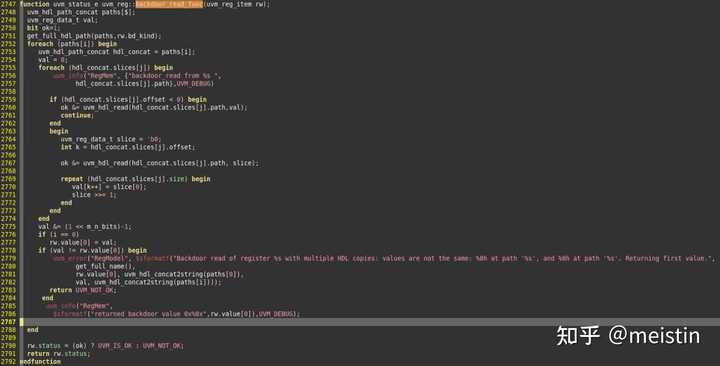
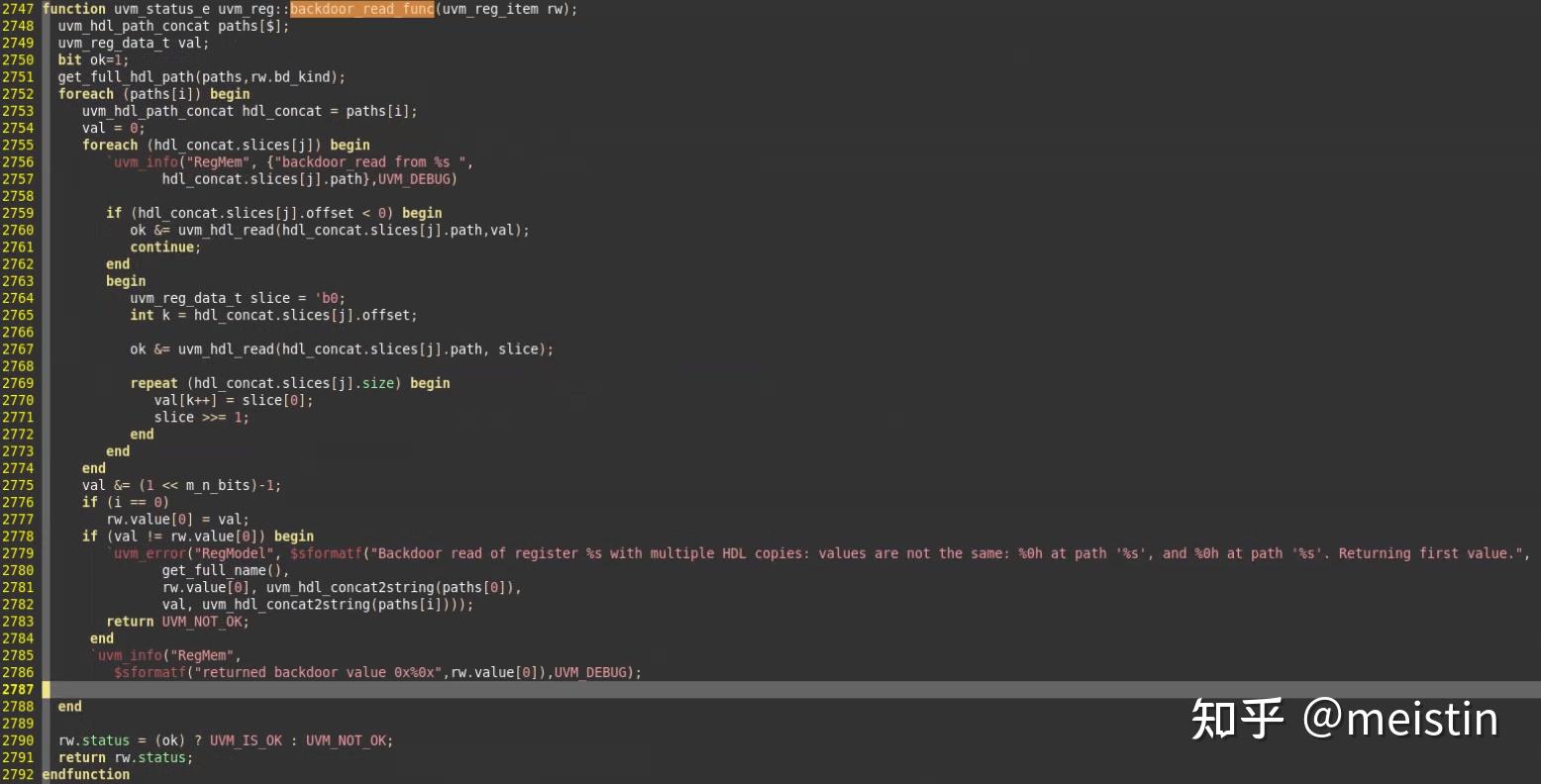
在uvm_reg中搜索backdoor_read()可以看到在do_read()中也有调用该方法,由此可见backdoor_read()功能与read()指定path为UVM_BACKDOOR功能类似,区别在于read()除了包含backdoor_read()的所有功能外,还额外增加了一些进程控制、值检查、do_predict()以及post_read()之类的callback功能。
backdoor_write()的实现与backdoor_read()类似,也属于write(.path(UVM_BACKDOOR))的简化版,这里就不做赘述了,保险起见我们还是师兄write()/read(),不要使用这两个backdoor任务。
至此,我们关于uvm_reg/uvm_reg_field中的四种值类型的解释以及相关读写访问的方法的介绍就讲到这里了,希望大家对寄存器模型中值的存储与访问能有个更加立体的认知。
发布于 2023-04-07 14:27
・IP 属地上海