
解决GNU Radio+USRP实现OFDM收发在接收端存在误码问题

前言
在使用 GNU Radio 时使用官方例程搭建 GNU Radio + USRP 实现 OFDM 收发测试时,发现误码情况很严重,明明都是理想信道的情况下,即时在仿真情况下不接 USRP 硬件设备进行收发也会出现误码,如下图所示,这就不得不怀疑是官方的底层 C++ 源码存在的问题了。
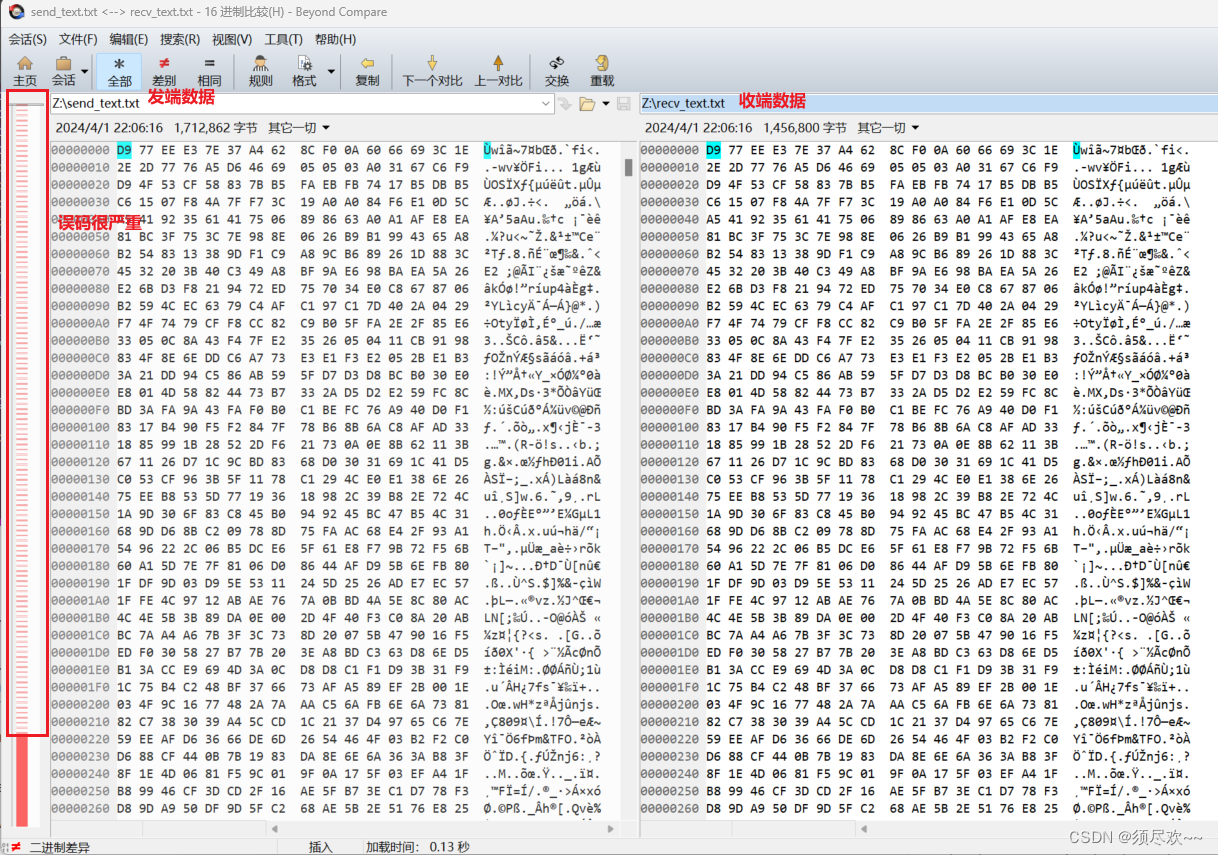
当然,之前我也用了一些方法在不修改底层 C++ 源码时解决了这个问题: GNURadio+USRP+OFDM实现文件传输 ,但是还是想从根本上解决这个误码问题。
首先声明一下我的环境:(Ubuntu20.04LTS + GNURadio 3.8 + UHD 3.15),一台电脑 + 一台 USRP 自收自发。
一、OFDM 收发流程
当使用官方的例程(一次发送 10 帧即 960 个字节的数据)进行测试时即使是在仿真中将信道条件改为理想信道时在接收端也会出现丢帧的现象。
1、OFDM 收端流程
有关 OFDM 发送端流程图如下图所示:
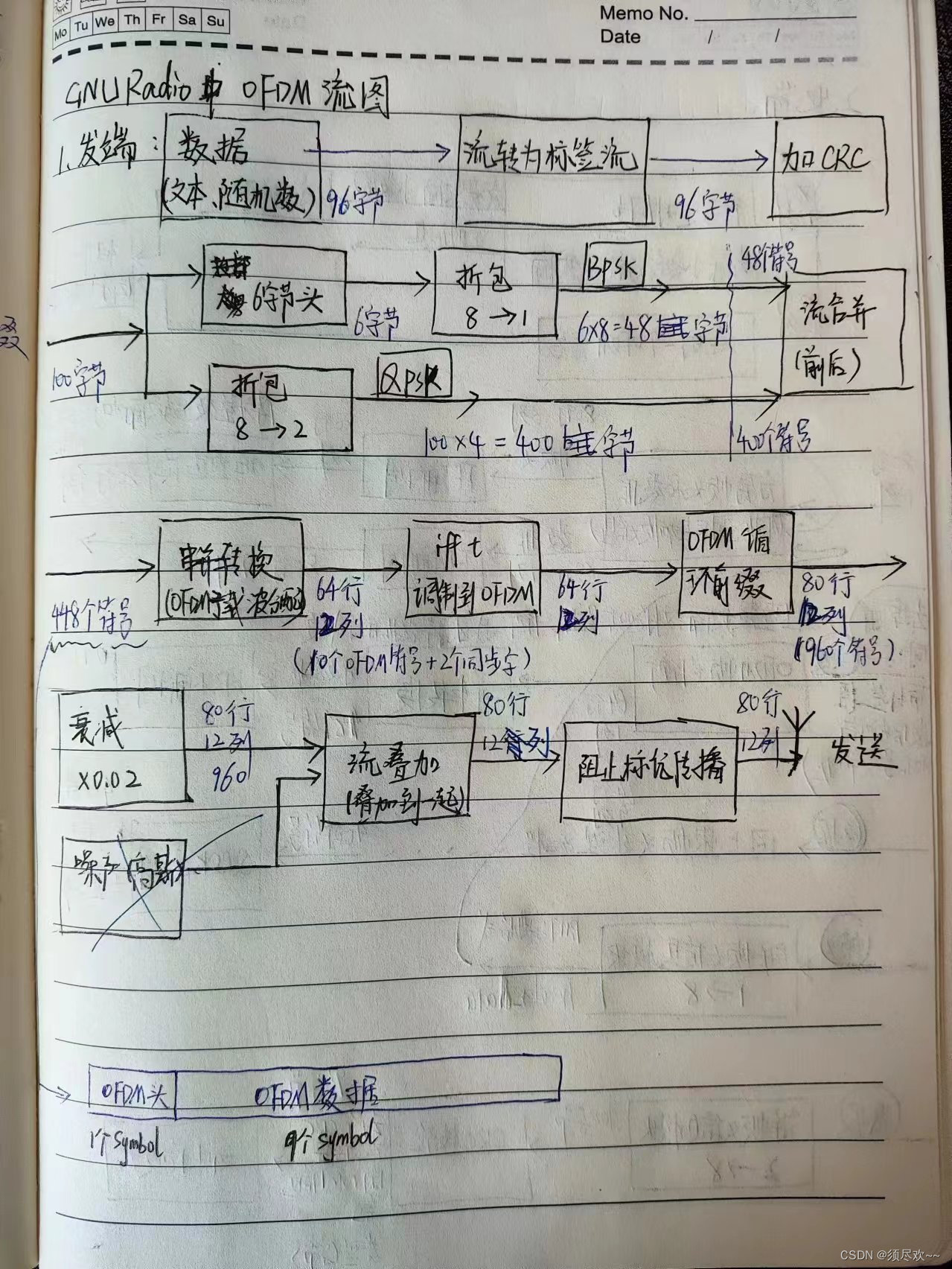
发端没有什么问题,问题存在于收端的处理
2、OFDM 收端流程
有关 OFDM 接收端流程图如下图所示:
其中问题所在是
Header/Payload Demux
模块的底层处理,下面一起看看其内部实现
二、问题所在
下图红框内的模块即
Header/Payload Demux
模块。
Header/Payload Demux:该模块的作用是根据定时信息和帧头信息,将复合在一起的帧头和数据进行分离。该模块的工作原理是:首先,将三个输入端口从上到下编号为 0,1,2,输出端编号类似。0 号端口连续输入去除载波频偏的数据流,当 1 号端口(定时信息)输入 1 时,也就是功能被触发,则输出端口 0 输出帧头,而数据(Payload)则保持不动。直到输入端口 2 接收到解码后的帧头信息,输出端口才有数据输出,输出数据为帧头和数据 payload 的分离数据。
我们首先看一下官方源码的原理,以下为官方有关核心程序讲解:
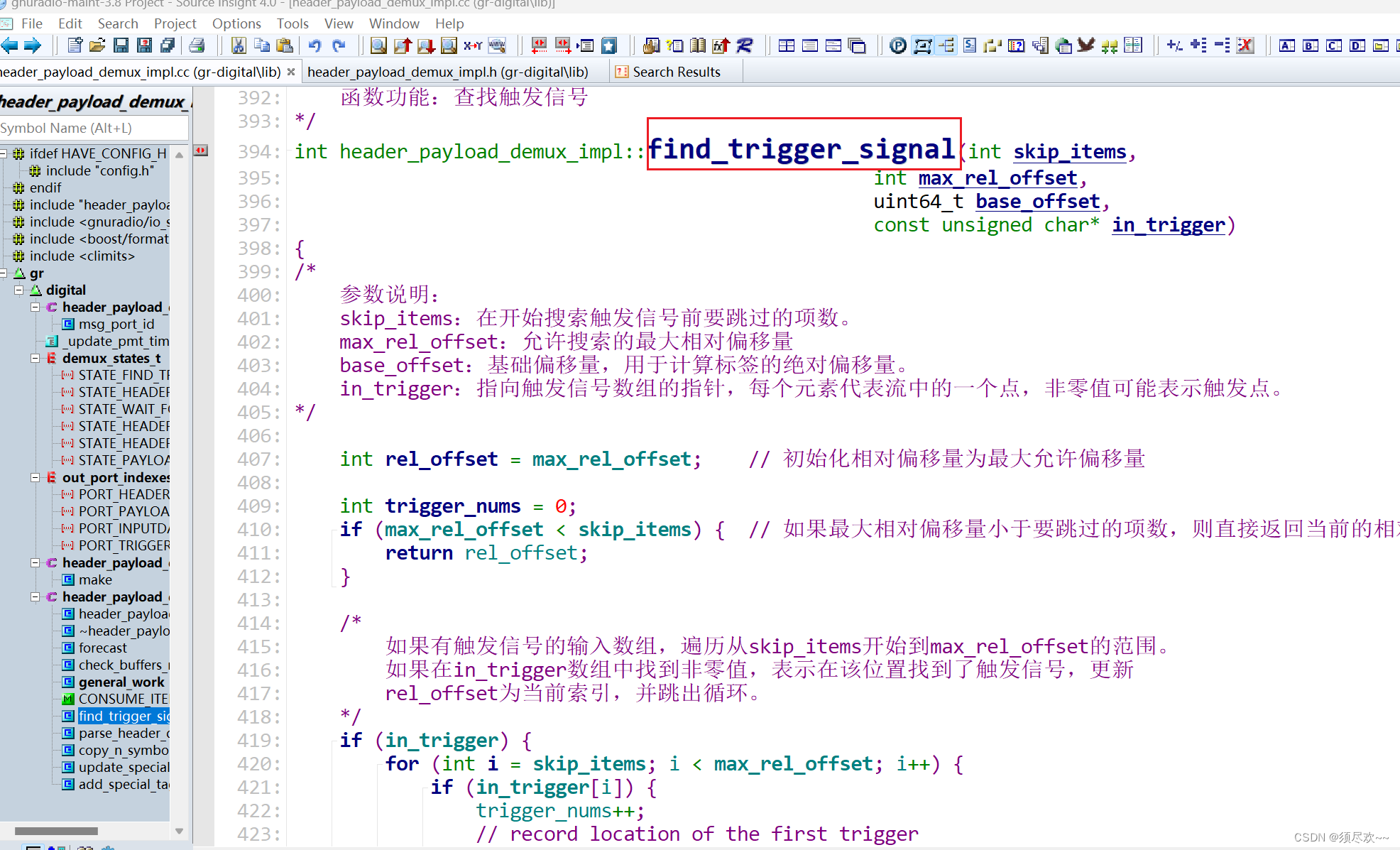
1、find_trigger_signal 函数解读
/*
函数功能:在信号处理或数据流处理程序中寻找触发信号的函数
int header_payload_demux_impl::find_trigger_signal(int skip_items,
int max_rel_offset,
uint64_t base_offset,
const unsigned char* in_trigger)
参数说明:
skip_items:开始搜索之前要跳过的项目数量
max_rel_offset:最大的相对偏移量,即在这个范围内寻找触发信号
base_offset:基准偏移量,是搜索的起始点
in_trigger:指向触发信号数据的指针
int rel_offset = max_rel_offset; // 初始化为最大相对偏移量,用来存储找到的触发信号的相对位置
/*如果最大相对偏移量小于要跳过的项目数,直接返回rel_offset。
这意味着没有足够的数据来进行搜索,所以函数提前结束。*/
if (max_rel_offset < skip_items) {
return rel_offset;
if (in_trigger) { // 如果 in_trigger 不是空指针,即有触发信号数据提供进行搜索。
这里使用了一个for循环从skip_items开始,一直到max_rel_offset,遍历触发信号数据。
for (int i = skip_items; i < max_rel_offset; i++) {
如果在某个位置i找到触发信号(if (in_trigger[i])),则更新rel_offset为这个位置,
并跳出循环。这表示找到了触发信号的第一个实例。
if (in_trigger[i]) {
rel_offset = i;
break;
if (d_uses_trigger_tag) { // 如果类的成员变量d_uses_trigger_tag为真,表示使用了触发标签进行搜索
std::vector<tag_t> tags; // 用来存储找到的标签
get_tags_in_range(tags, // 从输入数据端口(PORT_INPUTDATA)中获取一个范围内的标签,并把这些标签存储到tags中
PORT_INPUTDATA,
base_offset + skip_items,
base_offset + max_rel_offset,
d_trigger_tag_key);
如果找到了标签,则按照偏移量对它们进行排序。
取排序后的第一个标签的相对偏移量(相对于base_offset),并与当前的rel_offset比较。如果找到的标签偏移量更小,则更新rel_offset为该标签偏移量。
if (!tags.empty()) {
std::sort(tags.begin(), tags.end(), tag_t::offset_compare);
const int tag_rel_offset = tags[0].offset - base_offset;
if (tag_rel_offset < rel_offset) {
rel_offset = tag_rel_offset;
return rel_offset; // 即找到的触发信号的相对位置(如果找到的话),或者是最大相对偏移量(如果没有找到触发信号)
} /* find_trigger_signal() */2、general_work 函数
我们重点看
general_work
函数中的有效载荷(payload)数据的处理实现:
int header_payload_demux_impl::general_work(int noutput_items,
gr_vector_int& ninput_items,
gr_vector_const_void_star& input_items,
gr_vector_void_star& output_items)
const unsigned char* in = (const unsigned char*)input_items[PORT_INPUTDATA];
unsigned char* out_header = (unsigned char*)output_items[PORT_HEADER];
unsigned char* out_payload = (unsigned char*)output_items[PORT_PAYLOAD];
const int n_input_items = (ninput_items.size() == 2)
? std::min(ninput_items[0], ninput_items[1])
: ninput_items[0];
// Items read going into general_work()
const uint64_t n_items_read_base = nitems_read(PORT_INPUTDATA);
// Items read during this call to general_work()
int n_items_read = 0;
#define CONSUME_ITEMS(items_to_consume) \
update_special_tags(n_items_read_base + n_items_read, \
n_items_read_base + n_items_read + (items_to_consume)); \
consume_each(items_to_consume); \
n_items_read += (items_to_consume); \
in += (items_to_consume)*d_itemsize;
switch (d_state) {
当解复用器的状态变为 STATE_PAYLOAD 时,意味着它已经成功接收到了头部(header)信息,
并准备处理接下来的有效载荷数据。这个状态下的主要任务是从输入数据流中读取有效载荷数据,
然后将这些数据发送到输出端口。
case STATE_PAYLOAD: // 有效载荷(payload)数据
// Assumptions:
// - Input buffer is in the right spot to just start copying
检查缓冲区是否准备好
首先,通过调用 check_buffers_ready 函数来检查是否有足够的输入和输出缓冲区空间来
处理当前的有效载荷长度。这个检查确保了在开始复制数据之前,输入和输出都已经准备妥当。
这些参数用来判断是否满足处理当前有效载荷的条件:
d_curr_payload_len是当前有效载荷的长度。
noutput_items, ninput_items, 和 n_items_read分别表示输出项数、输入项数和已读项数,
if (check_buffers_ready(d_curr_payload_len, // 当前有效载荷的长度
noutput_items, // 输出项数
d_curr_payload_len * (d_items_per_symbol + d_gi),
ninput_items, // 输入项数
n_items_read)) { // 已读项数
// Write payload
写入有效载荷:
如果缓冲区检查通过,copy_n_symbols 函数会被调用来从输入缓冲区(in)复制有效载荷数据
到输出缓冲区(out_payload)。复制的数据量基于当前的有效载荷长度(d_curr_payload_len)
和每个符号的项目数(d_items_per_symbol加上d_gi,d_gi是一个保护间隔)。
copy_n_symbols(in,
out_payload,
PORT_PAYLOAD,
n_items_read_base + n_items_read,
d_curr_payload_len);
// Consume payload
// We can't consume the full payload, because we need to hold off
// at least the padding value. We'll use a minimum padding of 1
// item here.
消耗输入项:
完成数据复制后,需要更新已处理的输入项计数。不过,这里有一个微妙之处:
我们不能简单地消耗掉所有的有效载荷数据,因为需要保留一定的“填充”数据以
确保数据的完整性。因此,计算items_to_consume时会减去一个最小的填充项数,
通常至少为1。这确保了在当前处理周期结束时,输入缓冲区中还留有一些数据,
以便后续的处理。
const int items_padding = std::max(d_header_padding_total_items, 1);
const int items_to_consume =
d_curr_payload_len * (d_items_per_symbol + d_gi) - items_padding;
CONSUME_ITEMS(items_to_consume);
set_min_noutput_items(d_output_symbols ? 1 : (d_items_per_symbol + d_gi));
更新状态:
最后,解复用器的状态被设置回STATE_FIND_TRIGGER,这意味着在处理完当前有效载荷后,
解复用器将重新开始寻找下一个触发信号,以准备接收下一个数据包的头部。
d_state = STATE_FIND_TRIGGER;
break;
}3、问题所在
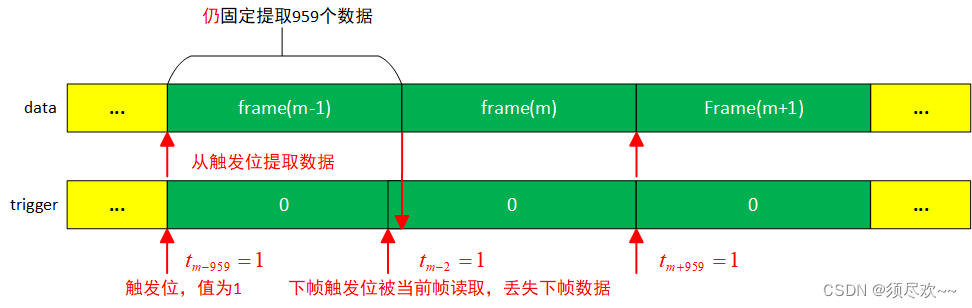
总的来说,丢帧的原因就是相邻两个定时信号的间隔过短时,导致当前帧提取数据时将后一个帧数据的定时信号作为当前帧的数据一并读入,这样就丢失了下一帧数据的定时信号,因此就造成了丢帧的现象。这种现象是源码中固有的问题。具体分析如下:
下图中 数据与触发信号是严格执行对应位置的并行传输关系,Header/Payload Demux 模块先读取 trigger 信号,当读到值为 1 时就被认为是一帧数据的开始,这时就从数据信号的相应位置开始往后提取 959 个数据作为当前帧的数据进行输出。 根据源码的数据处理过程,源码中每次接收到定时信号后,都会提取紧跟着该定时信号后面的 959 个数据作为当前帧进行输出,因此这对定时信号的精确型提出了很高的要求,如果相邻两个定时信号的间隔出现了小于正常数据帧长度的偏差,比如正常间隔为 960,如果此时出现了间隔为 958 的间隔, 如下图 ,则在提取后续 959 个数据的时候就会正好把下一帧的定时信号当作当前帧的数据一起读入,这样就丢失了下一帧数据的定时信号,因此就造成了丢帧的现象。
三、修改源码
解决这个问题的方法就是在源码中进行修改,在保证相邻定时信号不想相互干扰的基础上再重新进行源码的编译安装。需要修改的源码部分为
gr-digital/lib/header_payload_demux_impl.cc
以及
gr-digital/lib/header_payload_demux_impl.h
。
相关修改以及详解以放到文末,有需要的通信爱好者可自取。
find_trigger_signal()
部分代码
general_work()
部分代码

四、运行结果
1、频谱
使用 USRP 自收自发 OFDM 收发端频谱如下图:
2、传输数据测试
使用 USRP 自收自发 OFDM 随机数传输测试: