

![[计量经济学-4]随机微分方程SDE](data:image/svg+xml;utf8,<svg xmlns='http://www.w3.org/2000/svg'></svg>)
[计量经济学-4]随机微分方程SDE


欢迎来到计量经济学第4部分,前三部分的内容在:
这次来点轻松的有意思的话题:随机微分方程,英文为SDE=stochastic differential equation;这个可不是software development engineer的缩写~~
微分方程大家并不陌生,例如dy=x+y+1这种的。那随机微分方程,就是加入了“随机过程”的成分。例如经典的布朗运动。下面分别举几个例子,给出数学公式,大概的含义,以及示例代码来理解这些随机微分方程。
第一节:扩散过程(diffusion process)
主要示例两种扩散过程,一种是布朗运动(Brown Motion),另外一种是均值回归过程(Mean-reversion process)。
布朗运动,这是1826年英国植物学家 布朗 (1773~1858)用显微镜观察悬浮在水中的花粉时发现的。后来把悬浮微粒的这种运动叫做布朗运动。不只是花粉和小炭粒,对于液体中各种不同的悬浮微粒,都可以观察到布朗运动。布朗运动可在气体和液体中进行。
金融学中引入布朗运动,其应用的一个方面在于描述股价的随时间的走向。严谨的定义并描述布朗运动由诺伯特 • 维纳(Norbert Wiener)在 1918 年提出,因此 布朗运动(Brownian motion,一般表示为dB(t))又称为维纳过程(Wiener process,一般表示为dW(t)) 。关于布朗运动的一个科普性的视频,讲足球轨迹和布朗运动的,可以参考李永乐老师在youtube上的一个视频:
题目:世界杯球场上的诡异足球轨迹,如何用爱因斯坦的理论来解释?李永乐老师讲布朗运动
(如果下面URL失效,请直接进入Youtube并搜索上面的题目就有了)
另外,关于布朗运动的一个比较不错的知乎文章,这里也推荐一下:
为了区别于这些文章,这里主要是给出基于matlab的代码示例,并通过simulation来进一步理解好玩儿的布朗运动。
代码在:
入口文件是:ex_BM.m
下面的代码,模拟的是SDE:
dX(t)=\alpha dt + \sigma dB(t)
即两个距离足够近的时间点上,X(t)和X(t- \Delta t )的(例如股价变化量)差距 X(t)-X(t-\Delta t) ,可以使用等式右边的两项表示:第一项有个时间的极小量dt,以及它的系数 \alpha ,用来表明X(t)随时间变化的强度: \alpha 越大表明X(t)在短时间内的变化越大;第二项则是布朗运动dB(t)的微分,其中B(t)满足的是N(0, t)这样的均值为0,方差为t的正态分布。这里也有一个系数 \sigma ,其表明的是这种“不确定性跳跃”的强度。
简单修改上面的公式如下:
dX(t)=\alpha dt + \sigma dB(t); \\ X(t)-X(t-\Delta t) = \alpha \Delta t + \sigma \sqrt{\Delta t}z_t, z_t\sim N(0,1); \\ X(t)=X(t-\Delta t) + \alpha \Delta t + \sigma \sqrt{\Delta t}z_t, z_t\sim N(0,1); \\
% SDE=stochastic differential equation随机微分方程
% Simulation of diffusion process; BM = Brown Motion
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
close all;
clear all;
nt=21*12; % 21 days per month, 12 months per year
Xt=zeros(nt,1); % vector
Xt2=zeros(nt,1)
Xt3=zeros(nt,1)
Xt4=zeros(nt,1)
Xt5=zeros(nt,1)
dt=1/nt;
%%%%%%%%%%%%%%
% (1) dX(t)=alp*dt+sig*dB(t)
% alpha (alike mu),
% dt (time-difference),
% sig (sigma), dB(t): Brown motion,
% dX(t) = difference of the value function, X(t).
%%%%%%%%%%%%%%%
Xt(1)=0;
Xt2(1)=0;
Xt3(1)=
0;
alp=0.2;
sig=0.3;
rng(123456789,'twister');
for t=2:nt
dB=dt^0.5*randn(1);
Xt(t)=Xt(t-1)+alp*dt+sig*dB; % alp=0.2, sig=0.3
Xt2(t)=Xt2(t-1) + alp*2*dt+sig*dB; % alp=0.4, sig=0.3
Xt3(t)=Xt3(t-1) + alp*4*dt+sig*dB; % alp=0.8, sig=0.3
Xt4(t)=Xt4(t-1) + alp*dt+sig*2*dB; % alp=0.2, sig=0.6
Xt5(t)=Xt5(t-1) + alp*4*dt+sig*2*dB; % alp=0.8, sig=0.6
figure(1);
plot(Xt);grid on;
title('Diffusion process, alpha=0.2/0.4/0.8, sigma=0.3/0.6');
hold on;
plot(Xt2);
plot(Xt3);
plot(Xt4);
plot(Xt5);
legend('alpha=0.2, sigma=0.3', 'alpha=0.4, sigma=0.3', ...
'alpha=0.8, sigma=0.3', 'alpha=0.2, sigma=0.6', ...
'alpha=0.8, sigma=0.6')执行的结果如下:
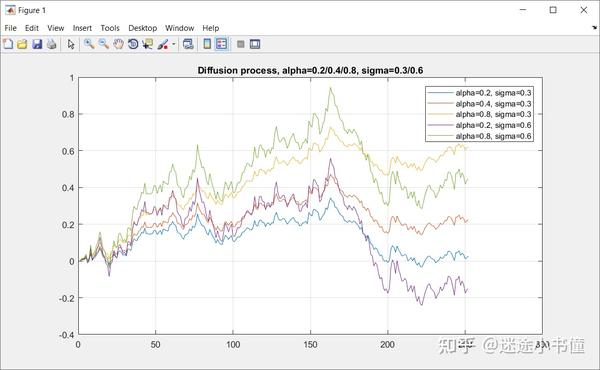

可以看到,alpha=0.8, sigma=0.6的时候的绿色的曲线,在中间达到了最大值,但后来则急速下降。与此对应的,alpha=0.8, sigma=0.3的时候的橙色曲线,虽然中间阶段没有绿色线那么高,但后来逐步达到了最大值。
另外,alpha=0.2, sigma=0.6的紫色曲线,随着模拟的进行,最后居然达到了负值。主要是因为 z_t\sim N(0,1) ,会产生,“正的”和“负的”满足标准正态分布的随机数。
下面再看一个“均值回归过程”。这个过程,在现实世界中比较扎心。例如,人类的智商的均值的回归:上一代是农民,下一代智商爆棚,再下一代则集体哑火的例子,还少吗?也看过不少帖子,里面的家长说他们这一代多么牛多么学霸,但孩子是学渣,之类的;也有那种说因为自己牛,所以孩子肯定牛而且不接受反驳。还有所谓,富不过三代之类的思葱思蒜的例子。这背后都有“均值回归过程”在作祟。
“有人研究了1980年到1994年出生的考上985、211的人数,和他们的父母考上大学、大专的人数之比(因为当时考上大专,和大学扩招后考上211学校的比例差不多,都是3%),发现当父母教育水平处于前3%时,子女教育仍然处于前3%的概率只有 10% 。”-不知道数据是否有假,不过也具有一定的意义来进行思考。
还有一个例子,说随机问大学教授,其科研能力是否高于学校教授的均值,结果90%以上的教授都认为自己高于均值 - 剩下的10%难道都是傻子吗?!
其实理解了均值回归理论,就会更加看淡这个世界的一些光怪陆离的现象,而去发掘其背后的本质。
达尔文的表弟高尔顿提出一个理论,叫做“均值回归”,他认为父母的极端特征不会完全遗传给下一代,后代的这一特征,会朝着均值靠近。
也就是说,不是孩子不争气, 要怪只能怪父母太优秀 。

当然,不可否认的是,人类的整体智商和整体智慧的均值是在“进化”中的,即整体均值本身也不是固定的,是(可能震荡,例如两次世界大战把精英打掉不少)上升的。
当然,学霸父母,拥有了更好的社会和教育资源之后,肯定会投入更多到下一代的教育中。我们再来看一项调查。范围扩展到小学、初中、职校技校、大专、本科、研究生等各个学历,看一下父母受教育水平和子女受教育水平的关系。这次的结果就和大家想的一样了,父母教育程度在大专以上的,子女考上大学的比例高达80%,远高于同期大学评价录取比例17%的平均值。所以说,孩子考上大学的比例和父母受教育程度在 一定情况下是成正比 的。
好了,八卦了半天,看看数学公式吧:
dX(t)=\alpha*(\bar{X}-X(t))*dt + \sigma dB(t).
这里的事先给定的均值是: \bar{X} 。按照和布朗运动类似的方法,我们可以使用如下公式来模拟这个均值回归过程:
dX(t)=\alpha*(\bar{X}-X(t))*dt + \sigma dB(t); \\ X(t)-X(t-\Delta t) = \alpha*(\bar{X}-X(t))*\Delta t + \sigma \sqrt{\Delta t}z_t; here\ z_t\sim N(0,1). \\ X(t)=X(t-\Delta t) + \alpha*(\bar{X}-X(t))*\Delta t + \sigma \sqrt{\Delta t}z_t; here\ z_t\sim N(0,1). \\
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% (2) Mean-reversion process;
% dX(t)=alp*(Xbar-X(t))dt+sig*dB(t)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% In finance, mean reversion is the assumption that:
% a stock's price will tend to move to the average price over time.
Xt(1)= 0.15;
Xt2(1) = 0.15;
Xt3(1) = 0.15;
Xt4(1) = 0.15;
alp = [20.0 2.0]; % strength of mean-reversion, 2.0
Xbar = [0.1 0.5];% long-run mean, pre-given
sig = 0.3;
%rng(123456789,'twister');
for t=2:nt
dB=dt^0.5*randn(1);
Xt(t)=Xt(t-1)+alp(1)*(Xbar(1)-Xt(t-1))*dt + sig*dB; % 20.0, 0.1
Xt2(t)=Xt2(t-1)+alp(2)*(Xbar(1)-Xt2(t-1))*dt + sig*dB; % 2.0, 0.1
Xt3(t)=Xt3(t-1)+alp(1)*(Xbar(2)-Xt3(t-1))*dt + sig*dB; % 20.0, 0.5
Xt4(t)=Xt4(t-1)+alp(2)*(Xbar(2)-Xt4(t-1))*dt + sig*dB; % 2.0, 0.5
%Xt(t)=Xt(t-1);
figure(2);
plot(Xt);hold on;
plot(Xt2);plot(Xt3);plot(Xt4);
grid on;title('Mean Reversion process');
legend('alp=20.0, Xbar=0.1', 'alp=2.0, Xbar=0.1', ...
'alp=20.0, Xbar=0.5', 'alp=2.0, Xbar=0.5', 'Location','Best')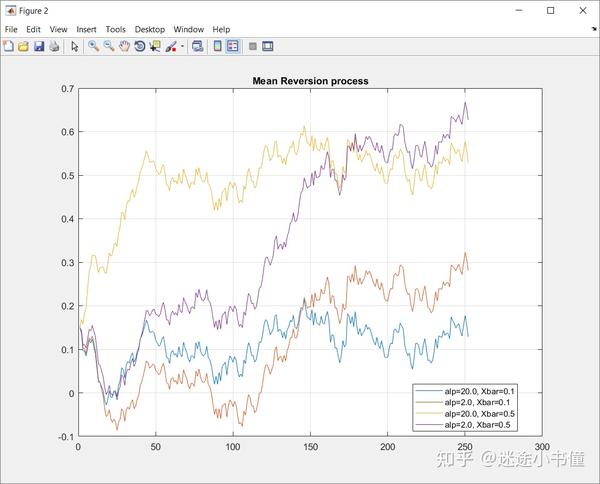

上图中,紫色和黄色的两条线的均值都是0.5,并且黄色的线的强度为20.0,紫色的为2.0;所以可以看到黄色的线的向均值0.5回归的速度更快一些。
另外两条青色和橙色的线的均值都是0.1,并且青色的线的强度为20.0,也可以看到青色的线向0.1回归的更快一些:经过250次之后,青色的线更接近于y=0.1这个线。
这些曲线多么像股票走势图?!证券投资理论的研究能够在一定程度上或一定范围内对 股票价格 进行预测才是该理论研究的直接目的。 均值回归理论 就是 股票收益 可预测理论的一个突破性进展,尤其对于 长线 投资者具有重要指导意义。
第二节:跳跃过程(Jump Process)和Hawkes过程(Hawkes process)
不禁想起之前看到的一篇NeurIPS 2017的论文,讲的是Neural Hawkes Process的:
当时看了很多遍这个paper,收益颇深。而且这个文章的第二作者Jason Eisner,其实是NLP的大神,ACL Fellow。之前开会的时候,总能看到他问问题,感觉是沉迷在NLP的研究中的真正的大神。
直接上示例代码,看如何simulate这些过程:
主要入口文件是:ex_jump.m
下面的代码,对应的公式为:
N_t(t)=N_t(t-1)+dN; \\where \ dN=\delta(z_t<N*dt); \\ i.e., dN=1\ if \ z_t<N*dt;\\ dN=0\ otherwise. \\ N=times\ of\ jump.
%
% Simulation of jump process
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
close all;
clear all;
%%%%%%%%%%%%%%
% (1) N(t): Plain jump(Poisson) process
% lam: constant intensity
%%%%%%%%%%%%%%%
lam=10;
% one year, 10 times, jump times, alike write 10 reports per year
nt=21*12;
% 21 days per month; 12 months
Nt=zeros(nt,1);
% jump's times vector
dt=1/nt;
% one day
rng(123456789,'twister');
for t=2:nt % nt - 2 + 1 = nt - 1 times
if rand(1)<lam*dt
% Passion Process, unique distribution-based
% randomly generate a double in [0, 1], 10*1/(21*12)
dN=1;
% do jump, with a probability of lam*dt
dN=0;
% do not jump, with a probability of (1-lam*dt), specially important
Nt(t)=Nt(t-1)+dN; % Nt add (1, or 0)
figure(1);
disp(Nt);
% draw Nt into figure 1:
stairs(Nt);grid on;title('N(t)');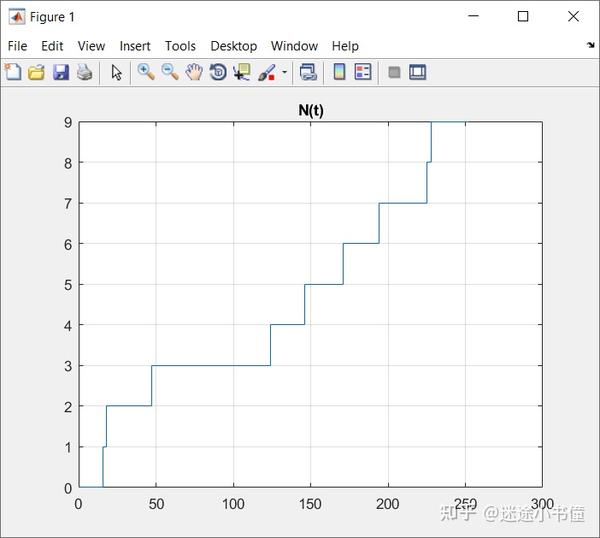

Hawkes过程:
公式为:
d\lambda(t)=\alpha*(\bar\lambda - \lambda(t))*dt + \beta * dN(t).
而用来进行simulation的公式就是:
\lambda(t) = \lambda(t-1) + \alpha * (\bar\lambda - \lambda(t-1))*dt + \beta*dN;
这里的dN也是一个跳跃过程,根据均匀分布得到的一个随机变量 z_t\sim U(0,1) ,且当 z_t < \lambda(t-1)*dt 的时候,有dN=1(跳跃);否则dN=0(不跳跃)。
Neural Hawkes过程会对跳跃过程对应的函数,用深度神经网络描述,并且改进离散的RNN为可以适用于连续时间的RNN,进行跳跃点的长距离依赖的描述。
%%%%%%%%%%%%%%
% (2) Simulation of Hawkes(HW) process
% d lam(t) = alpha*(lambar-lam(t))*dt + beta*dN(t)
%%%%%%%%%%%%%%%
lam=zeros(nt,1);
lam(1)=20;
lambar=20; % 10
alp=1.5; % 1.5
bt=0.5; % 0.5
rng(123456789,'twister');
for t=2:nt
if rand(1)<lam(t-1)*dt
dN=1;
dN=0;
Nt(t)=Nt(t-1)+dN;
% first update the jumping of Nt(t) based on a jumping probability of lam(t-1)*dt
lam(t) = lam(t-1) + alp * (lambar - lam(t-1))*dt + bt*dN;
% then update lam(t) based on updated dN
% this is a joint jumping process, interesting
figure(2);
subplot(2,1,1);plot(lam);grid on;
title('Hawkes intensity: $\lambda(t)$','interpreter','latex');
subplot(2,1,2);stairs(Nt);grid on;title('N(t)');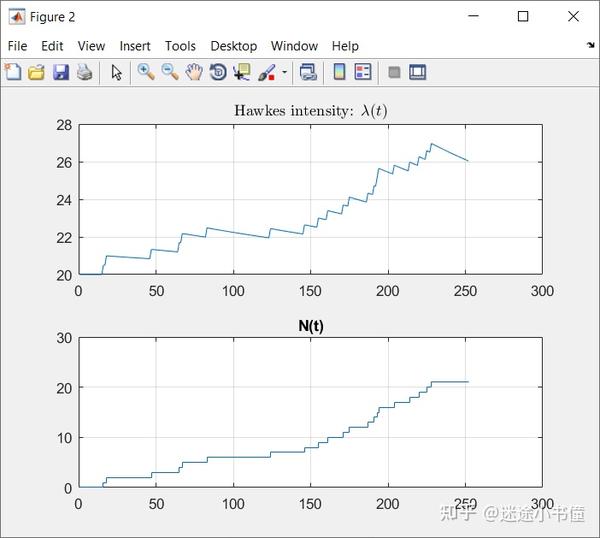

上图对比了Hawkes过程的密度函数和跳跃函数,因为Hawkes过程是基于N(t)跳跃的,所以他们的跳跃点相同。大的不同在于,N(t)是一直向上的,而Hawkes有“低头”的动作,即每次跳跃之后,都有下滑的趋势,然后再经历下一次跳跃。
随机Hawkes过程:
下面对Hawkes过程加入随机过程因子,这里是加入了一个布朗运动的因子,从而让其具有了随机的属性。称为Stochastic Hawkes过程。
下面的代码,对应的公式是:
d\lambda(t) = \alpha*(\bar\lambda-\lambda(t))*dt + \underline{\sigma*dB(t)} + \beta*dN(t) 。
而为了simulate这个过程,下面的代码,实际使用的公式是:
\underline{dB}=\sqrt{dt}*z_t; \\ where, \ z_t\sim N(0,1); \rightarrow add\ a\ Brown\ Motion \\ Nt(t)=Nt(t-1)+dN; \\ where,\ dN=\delta(u_t<\lambda(t-1)*dt), u_t\sim U(0,1);\\ \lambda(t) = \lambda(t-1) + \alpha * (\bar\lambda - \lambda(t-1))*dt + \sigma * \underline{dB} + \beta * \underline{dN}.
%%%%%%%%%%%%%%
% (3) Simulation of stochastic HW process
% d lam(t) = alpha*(lambar-lam(t))*dt + sigma*dB(t) + beta*dN(t)
% d lam(t) = lam(t) - lam(t-1)
%%%%%%%%%%%%%%%
lam=zeros(nt,1);
lam(1)=20;
lambar=10;
alp=1.5;
bt=0.5;
sig=0.8;
rng(123456789,'twister');
for t=2:nt
if rand(1)<lam(t-1)*dt
dN=1;
dN=0;
dB=dt^0.5*randn(1); % add a Brown motion
Nt(t)=Nt(t-1)+dN;
lam(t) = lam(t-1) + alp * (lambar - lam(t-1))*dt + sig * dB + bt * dN;
% consider to add Brown motion in the chatting process? for topic
% selection?