


(干货!)「自然语言生成NLG」资料大整理(持续更新...)


来源: AINLPer 微信公众号
编辑: ShuYini
校稿: ShuYini
时间: 2019-12-30
GitHub: https:// github.com/yinizhilian/ NLP_Share
什么是自然语言生成(NLG)?
自然语言生成(NLG)是一种语言技术,其主要目的是构建能够“写”的软件系统的技术,即能够用汉语、英语等其他人类语言生成解释、摘要、叙述等。具体来说就是计算机的“编写语言”,它将结构化数据转换为文本,以人类语言表达。即能够根据一些关键信息及其在机器内部的表达形式,经过一个规划过程,来自动生成一段高质量的自然语言文本。NLG用于Email、手机短信,它可以为您自动创建答复;NLG用于图标说明时,可以根据公司数据自动生成图标说明。前段时间在一个有趣的用例中,美联社利用自然语言生成成功的从公司收益报表中生成了报告。这意味着他们不再需要人类消耗他们的时间和精力去解决这些问题。更重要的是,NLG一旦被完美设置就会自动生成数以千计的报告。
学术研究介绍
NLG学术界每年都会召开会议,公布NLG的最新发现。这些会议是由 ACL SIGGEN 组织的,你可以查看其web页面以获取关于即将举行的活动的信息。在这些活动中提交的论文可以通过 ACL Anthology 在线获得。NLG的商业兴趣日益增长,其中大部分集中在数据到文本,即结合NLG和数据分析的系统,以产生摘要,解释等结构化数据.
「自然语言处理(NLP)」你必须要知道的八个国际顶级会议! 国际学术会议是一种学术影响度较高的会议,它具有国际性、权威性、高知识性、高互动性等特点,其参会者一般为科学家、学者、教师等。具有高学历的研究人员把它作为一种科研学术的交流方式,够为科研成果的发表和对科研学术论文的研讨提供一种途径 ;同时也能促进科研学术理论水平的提高。针对自然语言处理方向比较重要的几个会议有:ACL、EMNLP、NACAL、CoNLL、COLING、ICLR、AAAI、NLPCC等。ACL、EMNLP、NAACL 和 COLING 可以说是 NLP 领域的四大顶会。其中 ACL、EMNLP、NAACL都是一家(均由 ACL)举办。ACL 、AAAI是 CCF 推荐A类国际学术会议,EMNLP 和 COLING 是B类,NAACL 、CoNLL、NLPCC则是C类。
国内外知名大佬博客
Ehud Reiter
Ehud Reiter是阿伯丁大学的计算机科学教授,同时也是Arria NLG的首席科学家,主要专注于自然语言生成(NLG)技术,即利用人工智能和自然语言处理技术,将非语言数据自动生成高质量文本和叙述文章。他的博客 Ehud Reiter's Blog 主要包括:NLG系统的搭建、NLG系统性能的评估、NLG的学术生活、NLG相关话题、个人生活等五个部分,该博客对NLG技术、评价与应用进行了深入的探讨与反思。其中有一篇文章我觉得写得特别不错‘How do I Learn about NLG?’,主要讲了自己学习NLG的一些方法及感悟,感兴趣的同学可以拜读一下。
Andrej Karpathy
Andrej Karpathy是计算机视觉和深度学习领域的专家之一,毕业于斯坦福人工智能实验室,博士师从李飞飞教授,在谷歌大脑、DeepMind 实过习,与吴恩达一起共事,业界几大深度学习实验室都待过。他经常会在个人 twitter 上以及 个人博客 上面分享一些关于深度学习相关想法和见解,比如前段时间他分享的 深度学习训练技巧 受到了很多人的关注。看过他博客的个人介绍,可以发现,他在2011年到2015年学习期间,主要研究的方向是自然语言处理,它的一篇文章: 神奇的递归神经网络(RNN) 是一篇相当不错的入门资料。并且还共享 文本生成 的代码。
万小军
万小军 是北京大学王选计算机研究所研究员,主要研究领域有自然语言处理,文本挖掘,人工智能。它是语言计算与互联网挖掘研究室(从属北京大学王选计算机科学技术研究所)的负责人。该研究室以自然语言处理技术、数据挖掘技术与机器学习技术为基础,对互联网上多源异质的文本大数据进行智能分析与深度挖掘,为互联网搜索、舆情与情报分析、写稿与对话机器人等系统提供关键技术支撑,并从事计算机科学与人文社会科学的交叉科学研究。 研究室当前研究内容包括:1)语义理解:研制全新的语义分析系统实现对人类语言(尤其是汉语)的深层语义理解;2)机器写作:综合利用自动文摘与自然语言生成等技术让机器写出高质量的各类稿件;3)情感计算:针对多语言互联网文本实现高精度情感、立场与幽默分析;4)其他:兴趣技术探索。
干货学习资源
文本生成资源大列表
文本生成资源大列表 ,该资源主要整理列举了2018年EMNLP的优秀文本生成模型及应用案例(主要以Paper的形式给出)。其中主要包括:模型(GAN based、VAE based、Autoencoder based、Reinforcement learning based、Alternative decode objective、Tool and others)、应用(基于文本的强化学习、基于GAN的对抗学习等)。
文本生成必读的几篇文章
1、
(GitHub)Character based Recurrent Neural Network(内含源码)
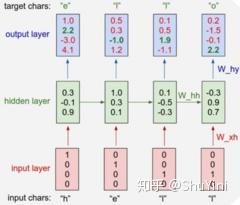
该篇文章主要讲述了最基本的Char-RNN文本生成原理,具体如下图所示。以要让模型学习写出“hello”为例,Char-RNN的输入输出层都是以字符为单位。输入“h”,应该输出“e”;输入“e”,则应该输出后续的“l”。输入层我们可以用只有一个元素为1的向量来编码不同的字符,例如,h被编码为“1000”、“e”被编码为“0100”,而“l”被编码为“0010”。使用RNN的学习目标是,可以让生成的下一个字符尽量与训练样本里的目标输出一致。在图一的例子中,根据前两个字符产生的状态和第三个输入“l”预测出的下一个字符的向量为<0.1, 0.5, 1.9, -1.1>,最大的一维是第三维,对应的字符则为“0010”,正好是“l”。这就是一个正确的预测。但从第一个“h”得到的输出向量是第四维最大,对应的并不是“e”,这样就产生代价。学习的过程就是不断降低这个代价。学习到的模型,对任何输入字符可以很好地不断预测下一个字符,如此一来就能生成句子或段落。
2、
(ACL2015)深度学习生成对话(诺亚方舟实验室--华为)
这篇文章尝试用encoder-decoder(编码-解码)的框架解决短文本对话(Short Text Conversation,缩写为STC)的问题。虽然encoder-decoder框架已经被成功应用在机器翻译的任务中,但是对话与翻译不同,对应一个输入文本(post)往往有多种不同的应答(responses)。文中举了一个例子,一个人说“刚刚我吃了一个吞拿鱼三明治”,不同的应答可以是“天哪,才早晨11点”、“看起来很美味哟”或是“在哪里吃的”。这种一对多的情况在对话中很普遍也很自然。的确,不同的人会对同一句话做出不同的反应,即使是同一个人,如果每次回答都一模一样也是很无趣的。 详细中文解读可见:
https://www.
cnblogs.com/DjangoBlog/
p/7270445.html
3、
(CONLL2016)谷歌人工智能写诗
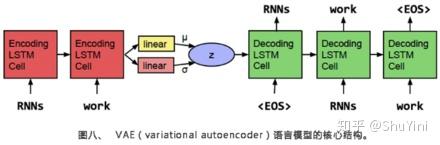
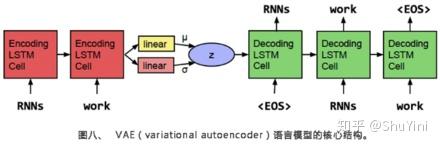
该篇文章的作者分别来自斯坦福大学、马萨诸塞大学阿姆斯特分校以及谷歌大脑部门,其主要工作是在谷歌完成的。这篇文章的想法非常有意思,他们想使用VAE(varationalautoencoder的简称)学习到一个更连续的句子空间。下图所示,作者使用了单层的LSTM 模型作为encoder(编码器)和decoder(解码器),并使用高斯先验作为regularizer(正规化项),形成一个序列的自动编码器。比起一般的编码解码框架得到的句子编码往往只会记住一些孤立的点,VAE框架学到的可以想象成是一个椭圆形区域,这样可以更好地充满整个空间。我的理解是,VAE框架将贝叶斯理论与深度神经网络相结合,在优化生成下一个词的目标的同时,也优化了跟先验有关的一些目标(例如KL cost和crossentropy两项,细节请参考论文),使对一个整句的表达更好。
自然语言生成(NLG)论文整理
1、
(NAACL2018)A Deep Ensemble Model with Slot Alignment for Sequence-to-Sequence Natural Language Generation
自然语言生成是生成对话系统和会话代理的核心。 本文首先描述了一个集成的神经语言生成器,并提出了几种新的数据表示和扩充方法,在我们的模型中产生了比较好的结果。 我们在餐厅,电视和笔记本电脑领域的三个数据集上测试模型,并报告我们最佳模型的客观和主观评估。 使用一系列自动度量标准以及人工评估器,我们表明我们的方法比相同数据集上的最新模型获得更好的结果。本文的工作主要建立在成功的注意力+编解码器框架的基础上,用于序列到序列学习并通过集成扩展它。 我们探索了一个独立于域的slot aligner的可行性,它可以应用于任何数据集,无论其大小如何,并且reranking task之外。 我们还解决了由于去词语化而导致的一些挑战,以提高表面实现的质量,同时保留神经模型的生成能力。
2、
(AAAI 2017)SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
作为一种新的生成模型训练方法,利用判别模型指导生成模型训练的生成对抗网(GAN)在生成实值数据方面取得了很大的成功。但是,当目标是生成离散标记序列时,它有局限性。一个主要原因是生成模型的离散输出使得梯度更新难以从判别模型传递到生成模型。此外,判别模型只能对一个完整的序列进行评价,而对于一个部分生成的序列,一旦生成了整个序列,平衡它当前的分数和未来的分数是不容易的。在本文中,我们提出了一个序列生成框架,称为SeqGAN来解决这些问题。SeqGAN在RL中将数据生成器建模为随机策略,通过直接执行梯度策略更新来绕过生成器的微分问题。RL奖励信号来自于根据完整序列判断的GAN鉴别器,并通过蒙特卡罗搜索返回到中间状态-动作步骤。对合成数据和实际任务的大量实验表明,在强基线上有显著的改进。
3、
(ICML 2016)Generative Adversarial Text to Image Synthesis
这篇文章的内容是利用GAN来做根据句子合成图像的任务。在之前的GAN文章,都是利用类标签作为条件去合成图像,这篇文章首次提出利用GAN来实现根据句子描述合成图像。根据句子描述合成图像的任务与其反过程相比(Image caption:给定一张图像,自动生成一句话来描述这张图),Image caption可以转化为根据图片内容和前面的词去预测下一个词,但是对于合成图像,可能有很多种像素的排列都能够表现出当前描述的内容,所以比较困难。要解决句子描述问题,要从两个子问题入手:一是学习好的文本表示,让模型能够准确地捕捉到文本描述信息;二是合成比较真实的图像。
4、
中文诗歌生成【微信AI团队】
(ACL 2019)Rhetorically Controlled Encoder-Decoder for Modern Chinese Poetry Generation,
为了将修辞学应用到中文汉语诗歌的生成上,本文提出了一种用于现代汉语诗歌生成的修辞控制编码器。我们的模型依赖于一个连续的潜在变量修辞控制器在编码器中捕获各种修辞模式,然后结合基于修辞的混合物,生成现代汉语诗歌。在隐喻、人格化、自动化的评估方面,我们的模型相比于最先进的基线具有很大的优势,并且人工评估显示,我们的模型生成的诗歌在流畅性、连贯性、意义和修辞美学方面都优于基本方法。
中文解读可见:
https://
blog.csdn.net/yinizhili
anlove/article/details/100054495
5、
会话响应生成【美国卡耐基梅隆大学】
(ACL 2019)Boosting Dialog Response Generation)
神经模型已成为对话响应生成的重要方法之一。然而,它们始终倾向于在语料库中生成最常见和通用的响应。针对这一问题,我们设计了一种基于boost的迭代训练过程和集成方法。该方法以不同的训练和解码范式为基础,包括基于互信息的解码和基于奖励增强的最大似然学习。实证结果表明,本文方法可以显著提高所有基本模型所产生的响应的多样性和相关性,并得到客观测量和人类评价的支持。
中文解读可见:
https://
blog.csdn.net/yinizhili
anlove/article/details/100054452
6、
电子邮件主题生成【美国耶鲁大学】
(ACL 2019)This Email Could Save Your Life: Introducing the Task of Email Subject Line Generation.)
提出并研究了电子邮件主题行生成任务:从电子邮件正文中自动生成电子邮件主题行。我们为这个任务创建了第一个数据集,并发现电子邮件主题行生成非常抽象,这与新闻标题生成或新闻单个文档摘要不同。然后,我们开发了一种新的深度学习方法,并将其与几种基线以及最新的最先进的文本摘要系统进行了比较。我们还研究了几种基于人类判断相关性的自动评价指标的有效性,并提出了一种新的自动评价指标。
中文解读可见:
https://
blog.csdn.net/yinizhili
anlove/article/details/100054826
7、
基于知识库的感知对话生成【腾讯AI Lab】
(ACL 2019)Improving Knowledge-aware Dialogue Generation via Knowledge Base Question Answering
本文的主要贡献有:1、提出了一种新的知识感知对话生成模型TransDG,该模型将知识库中的问题理解能力和事实提取能力转化为后理解能力和知识库中的事实知识选择能力。2、提出了一种多步译码策略,该策略能够捕捉到信息与响应之间的信息连接。第一步解码器产生的post和draft响应都与KB中的相关事实相匹配,使得第二步解码器产生的最终响应相对于post更合适、更合理。3、提出了一种响应引导注意机制,利用k-最佳响应候选项引导模型关注相关特征。4、在真实对话数据集上的大量实验表明,我们的模型在定量和定性两方面都优于比较方法。
中文解读可见:
https://
zhuanlan.zhihu.com/p/99
203505
8、
序列到序列自然语言生成(含源码)【微软亚洲研究院】
(ICML 2019)MASS: Masked Sequence to Sequence Pre-training
微软亚洲研究院的研究员在ICML 2019上提出了一个全新的通用预训练方法MASS,在序列到序列的自然语言生成任务中全面超越BERT和GPT。BERT通常只训练一个编码器用于自然语言理解,而GPT的语言模型通常是训练一个解码器。如果要将BERT或者GPT用于序列到序列的自然语言生成任务,通常只有分开预训练编码器和解码器,因此编码器-注意力-解码器结构没有被联合训练,注意力机制也不会被预训练,而解码器对编码器的注意力机制在这类任务中非常重要,因此BERT和GPT在这类任务中只能达到次优效果。源码地址:
https://
github.com/microsoft/MA
SS
中文解读可见:
https://
zhuanlan.zhihu.com/p/65
346812
未完待续。。。
Attention
更多自然语言处理相关知识,还请关注 AINLPer 公众号,极品干货即刻送达。

