


一篇文章教会你利用Python网络爬虫实现爬取起点中文网月票榜前100名网络小说信息

一、项目背景
起点中文网是中国大陆一个原创网络文学网站,成立于2003年5月,前身为玄幻文学协会。起点以收录玄幻、武侠、军事等原创网络小说而著名,主要提供由网络作家独立创作的小说。对于已经发表完成的作品,也会进行出版为实体书或者电子书版本。人们可以在上面找到自己喜欢看的小说,极大地方便了人们的小说阅读。
今天以起点月票榜为例,爬取对应小说的书名,作者,类型,简介,最新章节,书的地址链接,写入csv文档 。用户可以通过月票数,更好的选择自己想要的小说。
二、项目目标
获取对应的小说排行,书名,作者,类型,简介,最新章节,书的地址链接,图片链接,保存文档。

三、涉及的库和网站
1、网址如下:
https://www.qidian.com/rank/yuepiao?chn=-1&page=1
2、涉及的库:
- requests
- fake_useragent
- lxml
- csv
- pandas
3、软件:PyCharm
四、项目分析
1、如何多网页请求?
https://www.qidian.com/rank/yuepiao?chn=-1&page=1
https://www.qidian.com/rank/yuepiao?chn=-1&page=2
点击下一页时,每增加一页page自增加1,用{}代替变换的页数,再用for循环遍历这网址,实现多个网址请求。
2、接下来,回到网页看一下页面的真实源码。在开发者模式下的 Network 监听组件中查看源代码
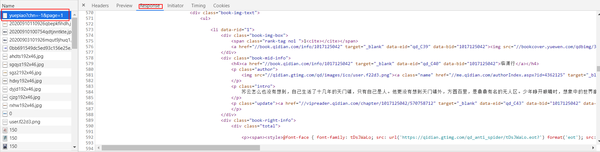
注意,这里不要在 Elements 选项卡中直接查看源码,因为那里的源码可能经过 JavaScript 操作而与原始请求不同,而是需要从 Network 选项卡部分查看原始请求得到的源码。
五、反爬措施
1、获取正常的 http请求头,并在requests请求时设置这些常规的http请求头。
2、使用 fake_useragent ,产生随机的UserAgent进行访问。
六、项目实施
1、我们定义一个class类继承object,然后定义init方法,再定义一个主函数run。导入需要的库和请求网址。
import requests
from fake_useragent import UserAgent
import csv
class QiDian(object):
def __init__(self):
self.url = "https://www.qidian.com/rank/yuepiao?chn=-1&page={}"
def run(self):
def main():
qidian = QiDian()
qidian.run()
if __name__ == '__main__':
main()
2、主方法(run):列表生成式拼接生成所有请求url。
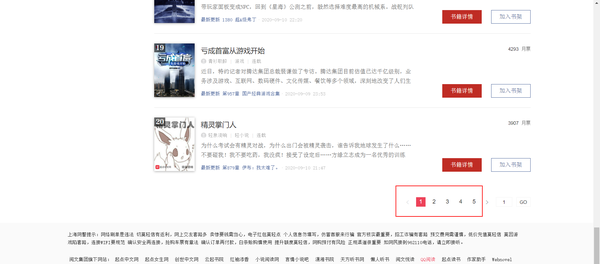
因为只有5页数据,所以只需要拼接构造5个url。
# 拼接请求的url
urls = [self.url.format(i) for i in range(1, 6)]
3、随机产生UserAgent,构造请求头,防止反爬。
@property
def generate_random_ua(self):
生成随机User-Agent
:return:
headers = {
'User-Agent': self.ua.random
return headers
4、发送请求 ,获取响应结果并返回。
def get_one_page(self, url):
请求url返回响应结果
:param url:
:return:
print(self.generate_random_ua
)
try:
response = requests.get(url, headers=self.generate_random_ua)
if response.status_code == 200:
return response.content
return None
except RequestException:
return None
5、xpath解析页面数据,获取目标数据并返回。
@staticmethod
def parse_one_page(self, content):
解析页面数据,提取数据
:param content:
:return:
html = etree.HTML(content)
items = html.xpath('//*[@id="rank-view-list"]/div/ul/li')
for item in items:
index = item.xpath('.//div[1]/span/text()') #排行
book = item.xpath('.//div[2]/h4/a/text()')# 书名
author = item.xpath('.//div[2]/p[1]/a[1]/text()')#作者
type_ = item.xpath('.//div[2]/p[1]/a[2]/text()')# 类型
intro = item.xpath('.//div[2]/p[2]/text()')#简介
update = item.xpath('.//div[2]/p[3]/a/text()')# 最新章节
book_link = item.xpath('.//div[1]/a/@href')# 书的地址链接
image = item.xpath('.//div[1]/a/img/@src')# 图片链接
yield [index[0], book[0], author[0], type_[0], intro[0].strip(), update[0], ''.join(('https:', image[0])),
''.join(('https:', book_link[0]))]
6、将提取好的数据保存到文件中
方法1,通过csv模块写入文件:
def write_to_file_by_csv(content):
将数据写入文件
:param content:
:return:
with open('result.csv', 'w', newline='', errors='replace') as f:
writer = csv.writer(f)
writer.writerow(self.fieldnames)
writer.writerows(content)
方法2:通过pandas模块操作,将数据写入文件
def write_to_file_by_pandas(self, content):
通过pandas模块将数据写入文件
:param content:
:return:
# 输入到to按住Tab有很多格式,储存
df = pd.DataFrame(content, columns=self.fieldnames)
df.to_excel('results.xlsx')
7、完整代码如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2020/9/10 21:08
# @Author : 一叶知秋
# @File : qidian.py
# @Software: PyCharm
import csv
import requests
from fake_useragent import UserAgent
from lxml import etree
from requests import RequestException
import pandas as pd
class QiDian(object):
def __init__(self):
self.url = "https://www.qidian.com/rank/yuepiao?chn=-1&page={}"
self.ua = UserAgent()
self.fieldnames = ['排行', '书名', '作者', '类型', '简介', '最新章节', '书的地址链接', '图片链接']
@property
def generate_random_ua(self):
生成随机User-Agent
:return:
headers = {
'User-Agent': self.ua.random
return headers
def get_one_page(self, url):
请求url返回响应结果
:param url:
:return:
print(self.generate_random_ua)
try:
response = requests.get(url, headers=self.generate_random_ua)
if response.status_code == 200:
return response.content
return None
except RequestException:
return None
@staticmethod
def parse_one_page(content):
解析页面数据,提取数据
:param content:
:return:
html = etree.HTML(content)
items = html.xpath('//*[@id="rank-view-list"]/div/ul/li')
for item in items:
index = item.xpath('.//div[1]/span/text()') # 排行
book = item.xpath('.//div[2]/h4/a/text()') # 书名
author = item.xpath('.//div[2]/p[1]/a[1]/text()') # 作者
type_ = item.xpath('.//div[2]/p[1]/a[2]/text()') # 类型
intro = item.xpath('.//div[2]/p[2]/text()') # 简介
update = item.xpath('.//div[2]/p[3]/a/text()') # 最新章节
book_link = item.xpath('.//div[1]/a/@href') # 书的地址链接
image = item.xpath('.//div[1]/a/img/@src') # 图片链接
yield [index[0], book[0], author[0], type_[0], intro[0].strip(), update[0], ''.join(('https:', image[0])),
''.join(('https:', book_link[0]))]
def write_to_file_by_csv(self, content):
将数据写入文件
:param content:
:return:
with open('result.csv', 'w', newline='', errors='replace') as f:
writer = csv.writer(f)
writer.writerow(self.fieldnames)
writer.writerows(content)
def write_to_file_by_pandas(self, content):
通过pandas模块将数据写入文件
:param content:
:return:
# 输入到to按住Tab有很多格式,储存
df = pd.DataFrame(content, columns=self.fieldnames)
df.to_excel('results.xlsx',index=False)
def run(self):
:return:
results = []
# 拼接请求的url
urls = [self.url.format(i) for i in range(1, 6)]
for url in urls:
content = self.get_one_page(url)
for item in self.parse_one_page(content):
print(item)
results.append(item)
self.write_to_file_by_csv(results)
self.write_to_file_by_pandas(results)
def main():
qidian = QiDian()
qidian.run()