

《切韵》记录了南北朝时期标准汉语的音系。这一时期的标准汉语一般称为早期中古汉语(Early Middle Chinese),因此切韵拟音J( Qieyun Reconstruction J)实际上就是早期中古汉语的拟音。J为拟音的版本号,代表2020年,来自unt的 字母纪年法 (Alphabetic Year Numbering)。
“ 废 话少说,放码过 来 ” (Talk is cheap. Show me the code)。切韵拟音J一改以往中古汉语拟音以音值和证据为导向的方式,而是以音系和工程为导向, “ 先 码后 文 ” 地实现切韵拟音的流水线生产。文章分成两篇先后发布:
- 音系规则和代码实现
- 语音描写和拟音说明
切韵拟音J已在 《切韵》音系自动推导器 中上线,可选择 “ u nt切韻擬音 J ” 后点击 “ 加 載 ” 使用。特别感谢 思無邪SyiMyuZya 和 三日月 綾香 的帮助支持。
目录
音系规则和代码实现
因为音位、区别性特征(distinctive feature)、音系规则(phonological rule)等已在推导方案代码中用
/** ... */
式注释写出,所以下面直接摘录推导方案完整代码,但是把这些注释打开到正文中以便阅读。想阅读音系部分的人直接忽略下文代码部分,只看正文和注释部分即可。原始代码见
unt_j.js
。
const is = (x) => 音韻地位.屬於(x.replace(/ /g, ''));
下面语音学术语对应的音韵学术语将用 〈全角尖括号〉 在语音学术语后注明。代码中的流程控制开关用 绿框 表明。音系规则代号用 紫底 表明。
一、流程控制开关
音韵地位对应音位开关:
| 开关 | 默认 | 说明 |
|---|---|---|
| 肴豪韵韵核归为低元音 | 关 | 关闭:e͇w əw(实现为 œ͇w ʌw),打开:a͇w aw |
音系规则开关:
| 开关 | 默认 | 说明 |
|---|---|---|
| 祭泰夬废韵尾推导为ɹ | 开 | 4 关闭:-j,打开:-ɹ |
| 要推导松元音 | 开 | 5 普通用户请保持打开,否则后面一些推导可能出错 |
| 要推导二合元音 | 开 | 6 关闭:iə ɨə ia ɨa,打开:iɛ ɨɜ iæ ɨɐ |
| 要推导a | 开 | 7 关闭:a,打开:a ɑ |
| 庄组臻摄开口推导为ɹ̩ | 开 | 9 关闭:in,打开:ɹ̩n。不包括合口 “ 率 ” 小韵 |
| 豪覃韵韵核推导为ʌ | 开 | 10 关闭:əw əm,打开:ʌw ʌm |
| 肴凡韵韵核推导为œ | 开 | 11 关闭:e͇w βəm,打开:œ͇w βœm |
| 精三寅合口介音推导为ɥ | 关 | 12 关闭:sʷɹ-,打开:sʷɥ-。关闭 |
| 蒸幽韵合口增生ɹ滑音 | 开 | 13 “ 冰 ” ,关闭:pîŋ,打开:pɹîŋ |
| 云母推导为ɹ | 开 | 14 关闭:ɣɹ- ɣj̈-,打开:ɹ-。不论三 B 还是三 C |
| 见系非三推导为软腭后音 | 开 | 15 包含匣母 |
| 晓母非三推导为软腭后音 | 开 | 16 按常理,需要 见系非三推导为软腭后音 打开才能打开 |
| 通江宕摄推导为软腭后音 | 开 | 17 如果 要推导a 没有打开,那么不推导宕摄韵尾 |
| 侯韵裂化为ɘu | 开 | 18 关闭:u,打开:ɘu |
| 精组非后高元音省略介音 | 开 | 21 “ 踪 ” ,关闭:tsɹʉ̂ɜɴ,打开:tsʉ̂ɜɴ |
后处理开关:
| 开关 | 默认 | 说明 |
|---|---|---|
| 知组写成卷舌塞音 | 关 | 关闭:tɹ,打开:二等 ʈ、三等 ʈɹ |
| 中元音写成半低元音 | 关 | 关闭:e o,打开:ɛ ɔ。不转换ə |
| ɑ写成a | 开 | |
| 半元音介音写成元音 | 关 | |
| 半元音韵尾写成元音 | 关 | |
| 二等元音写成r音钩 | 关 | |
| 二等元音写成双下横线 | 关 |
关闭:下等号a͇(
U+0347
),打开:双下横线a̳(
U+0333
)。一些字体(如Times New Roman、Arial)把这两个附加符号弄反了,为了显示的效果要打开。只在
二等元音写成r音钩
关闭时有效
|
声调开关:
| 开关 | 默认 | 说明 |
|---|---|---|
| 声调分阴阳 | 开 | |
| 声调写成五度标记 | 关 | |
| 声调附加符号写在音节前 | 关 | 只在 声调写成五度标记 关闭时有效 |
二、音节结构
切韵拟音J的音节结构是CʷGVCᵀ。
Cʷ:辅音或唇化辅音,作为声母(initial)
G:滑音(glide),作为介音(medial)
V:单元音或二合元音,作为韵核(nucleus)。成音节辅音[ɹ̩]也可以作韵核
〈臻韵〉
C:辅音,作为韵尾(coda)。韵核和韵尾加在一起叫作韵基(rime)
ᵀ:声调(tone)
介音和韵尾可有可无,声母、韵核、声调是必须出现的。
三、音韵地位对应音位(及其代码实现)和区别性特征
1. 辅音的特征
发声态和调音方式:
| [±voi] | 带声(voice) |
| [±sg] |
展声门(spread glottis),即辅音送气。注意
|
| [±son] |
响音(sonorant)性,包括鼻音和近音(本文的响音不包含元音)。相反的
|
| [±stop] |
塞音性,包括鼻塞音(即鼻音)和口塞音(即爆发音和塞擦音)。包含鼻音的
“
塞
音
”
严格来说应该叫 occlusive 而非 stop,本文从简直接用
|
| [±fric] |
擦音(fricative)性。本文将塞擦音也算入
|
调音部位:
| [LAB] | 唇(labial) | |
| [±rnd] | 圆唇(round),包括唇化辅音和圆唇元音 | |
| [COR] |
舌冠(coronal),即锐音(acute)。本文为了简便将硬腭辅音也算入舌冠音。本文从简仍然使用
“
锐
音、钝
音
”
的叫法,但不用
|
|
| [±ant] | 前部(anterior)。前部锐音包括齿–龈、龈,后部锐音包括龈后、卷舌、龈–腭等 | |
| [±r] | r色彩 | |
| [DOR] | 舌面(dorsal) | |
| [±high] |
高,对辅音而言
|
|
2. 音韵地位对应辅音音位
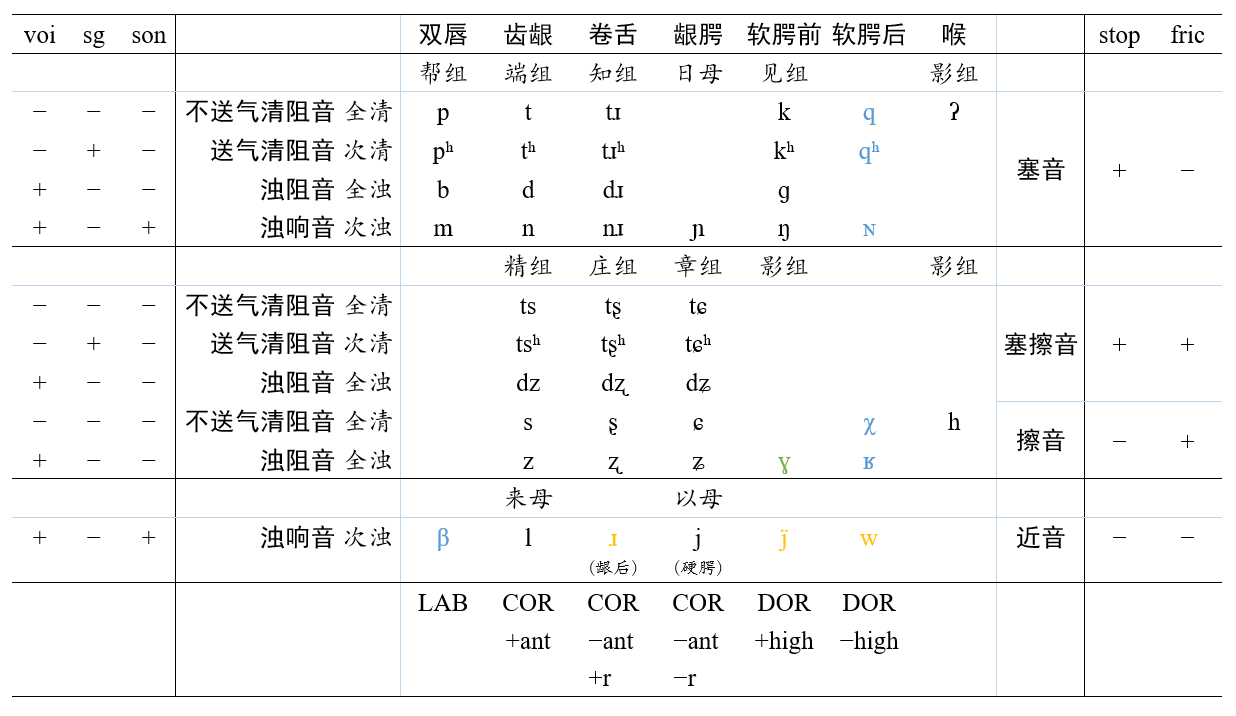
详见下面代码实现。
// 函数:将声母的音韵地位转换为音位,不含开合信息
// 介音音位和条件变体也在下面列出,以说明其区别性特征,尽管在代码中用不到
function getInitialWithoutRounding() {
return {
// 不送气 送气 浊阻音 浊响音
// 清阻音 清阻音
//〈全清〉 〈次清〉 〈全浊〉 〈次浊〉
// −voi −voi +voi +voi
// −sg +sg −sg −sg
// −son −son −son +son
幫: 'p', 滂: 'pʰ', 並: 'b', 明: 'm', // +stop, −fric; LAB 双唇塞音 〈帮组/唇音〉
帮三C介音: 'β', // −stop, −fric; LAB 双唇近音
端: 't', 透: 'tʰ', 定: 'd', 泥: 'n', // +stop, −fric; COR, +ant 齿龈塞音 〈端组/舌头音〉
精: 'ts', 清: 'tsʰ', 從: 'dz', // +stop, +fric; COR, +ant 齿龈塞擦音〈精组/齿头音〉
心: 's', 邪: 'z', // −stop, +fric; COR, +ant 齿龈擦音 〈精组/齿头音〉
來: 'l', // −stop, −fric; COR, +ant 齿龈近音 〈来母/半舌音〉
知: 'tɹ', 徹: 'tɹʰ', 澄: 'dɹ', 孃: 'nɹ', // +stop, −fric; COR, −ant, +r 卷舌塞音 〈知组/舌上音〉
莊: 'tʂ', 初: 'tʂʰ', 崇: 'dʐ', // +stop, +fric; COR, −ant, +r 卷舌塞擦音〈庄组/正齿音〉
生: 'ʂ', 俟: 'ʐ', // −stop, +fric; COR, −ant, +r 卷舌擦音 〈庄组/正齿音〉
钝三B介音: 'ɹ', // −stop, −fric; COR, −ant, +r 龈后近音
日: 'ɲ', // +stop, −fric; COR, −ant, −r 龈腭塞音 〈日母/半齿音〉
章: 'tɕ', 昌: 'tɕʰ', 常: 'dʑ', // +stop, +fric; COR, −ant, −r 龈腭塞擦音〈章组/正齿音〉
書: 'ɕ', 船: 'ʑ', // −stop, +fric; COR, −ant, −r 龈腭擦音 〈章组/正齿音〉
以: 'j', // −stop, −fric; COR, −ant, −r 硬腭近音 〈以母/喉音〉
見: 'k', 溪: 'kʰ', 羣: 'ɡ', 疑: 'ŋ', // +stop, −fric; DOR (+high) 软腭前塞音〈见组/牙音〉
匣: 'ɣ', 云: 'ɣ', // −stop, +fric; DOR (+high) 软腭前擦音〈影组/喉音〉
见三C介音: 'j̈', // −stop, −fric; DOR (+high) 软腭前近音
見1: 'q', 溪1: 'qʰ', 疑1: 'ɴ', // +stop, −fric; DOR (−high) 软腭后塞音【带1的是非三等变体】
曉1: 'χ', 匣1: 'ʁ', // −stop, +fric; DOR (−high) 软腭后擦音
影: 'ʔ', // +stop, −fric 喉塞音 〈影组/喉音〉
曉: 'h', // −stop, +fric 喉擦音 〈影组/喉音〉
}[音韻地位.母];
const is全清 = is('幫端精心知莊生章書見影曉母'); // [−voi, −sg, −son]
const is次清 = is('滂透清 徹初 昌 溪 母'); // [−voi, +sg, −son]
const is全浊 = is('並定從邪澄崇俟常船羣 匣母'); // [+voi, −sg, −son]
const is次浊 = is('明泥來 孃 日以疑云 母'); // [+voi, −sg, +son]
const is清 = is全清 || is次清;
// 云母已按推导后的结果 [ɹ] 算入次浊
const is锐前 = is('端精組 或 來母 一二四等'); // [COR, +ant]
const is锐后 = is('知莊章組 或 日以母'); // [COR, −ant]
const is锐 = is锐前 || is锐后 || is('來母'); // [COR]
// 来母按推导后只有非三等 [l] 算入前部锐音,但来母三等 [lɹ] 不算前部也不算后部
// 函数:将声母的音韵地位转换为音位,包含开合信息
function getInitial() {
let result = getInitialWithoutRounding();
// 音韵学术语开合对应 [±rnd]。如果主要调音部位就是 [LAB]〈帮组〉,那么本文一律视为 [−rnd]
// 没有开合对立的韵母一般视为开口,但虞韵本文视为鱼韵对应的合口;平行地,钟韵也视为合口
// 𠑆𦑣䎎小韵算合口
if (is('合口 或 虞鍾韻 或 知組 嚴凡韻') && !is('幫組')) { // [+rnd]
result += 'ʷ';
result = result.replace('ʰʷ', 'ʷʰ');
} // else [−rnd]
return result;
// 函数:将软腭前音转换为软腭后音
function velarToUvular(consonant) {
switch (consonant[0]) {
case 'k': return 'q' + consonant.substring(1);
case 'ɡ': return 'ɢ' + consonant.substring(1);
case 'ŋ': return 'ɴ' + consonant.substring(1);
case 'ɣ': return 'ʁ' + consonant.substring(1);
return consonant;
// 函数:将知组转换为卷舌塞音
function retroflexToStop(consonant) {
switch (consonant.substring(0, 2)) {
case 'tɹ': return 'ʈ' + consonant.substring(2);
case 'dɹ': return 'ɖ' + consonant.substring(2);
case 'nɹ': return 'ɳ' + consonant.substring(2);
return consonant;
// 函数:将介音的音韵地位转换为音位,不含开合信息
function getGlide() {
if (is('云母 灰韻')) return 'ɹ'; // “倄”小韵
// 一二四等无介音
if (!is('三等')) return '';
// 锐音声母三等介音一律用 /ɹ/
if (is锐) return 'ɹ';
// 钝音声母分三 A、B、C
if (is('重紐B類 或 庚臻韻')) return 'ɹ';
if ('抑𡊁烋'.includes(字頭)) return 'ɹ'; // 蒸韵“抑𡊁”二字、幽韵“烋”字归三 B
if (is('云母 支脂祭眞臻仙宵麻庚清蒸幽侵鹽韻')) return 'ɹ'; // 云母前元音韵归三 B
if (is('重紐A類 或 麻蒸清幽韻')) return 'j'; // 三 A
return 'j̈'; // 三 C
// 函数:将韵尾的音韵地位转换为音位
function getCoda() {
if (is('通江宕梗曾攝')) return is('入聲') ? 'k' : 'ŋ';
if (is('深咸攝')) return is('入聲') ? 'p' : 'm';
if (is('臻山攝')) return is('入聲') ? 't' : 'n';
if (is('佳韻')) return ''; // 从蟹摄中排除无韵尾的佳韵
if (is('微韻 或 蟹攝')) return 'j';
if (is('幽韻 或 效攝')) return 'w';
return '';
3. 元音的特征
| [±high] | 高 |
| [±low] | 低 |
| [±front] | 前 |
| [±back] | 后 |
| [±rnd] | 圆唇(round) |
| [±tense] | 紧。三子韵及其对应的三寅韵是松元音,三丑韵及其对应的三寅韵是紧元音,非三等韵都是紧元音 |
| [±divII] | 二等(division-II)。本文不指定它的具体语音实现 |
列表如下。[ʉ] 是音位变体,也加入下表
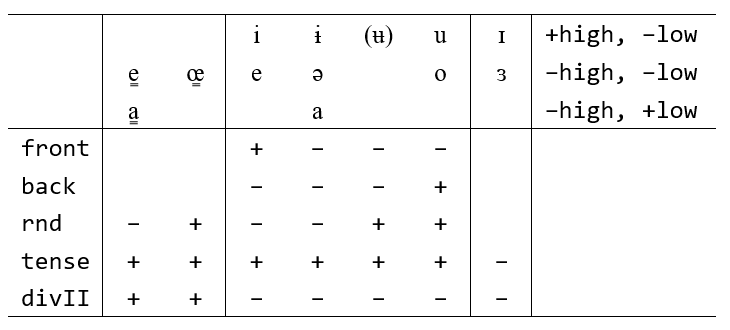
4. 音韵地位对应元音音位
详见下面代码实现。
// 函数:将韵核的音韵地位转换为音位
function getNucleus() {
// 松元音
// 韵尾: m j n w
if (is('侵 微 眞臻欣文 韻')) return 'ɪ'; // +high, −tense
if (is('鹽嚴凡祭廢仙 元 宵韻')) return 'ɜ'; // −high, −tense
// 紧元音
if (選項.肴豪韵韵核归为低元音) {
if (is('肴韻')) return 'a͇';
if (is('豪韻')) return 'a';
// 脂韵、尤韵的韵基也可分别视为 /ɪj/、/ɪw/,本文从简直接视为紧元音 /i/、/u/
// 韵尾: ŋ m j n w
if (is('脂蒸 幽韻')) return 'i'; // +high, −low, +front, −back, −rnd, +tense
if (is('之 韻')) return 'ɨ'; // +high, −low, −front, −back, −rnd, +tense
if (is('尤東 侯韻')) return 'u'; // +high, −low, −front, +back, +rnd, +tense
if (is('佳耕咸皆山肴韻')) return 'e͇'; // −high, −low, +divII, −rnd, +tense
if (is(' 江 韻')) return 'œ͇'; // −high, −low, +divII, +rnd, +tense
if (is(' 青添齊先蕭韻')) return 'e'; // −high, −low, +front, −back, −rnd, +tense
if (is(' 登覃咍痕豪韻')) return 'ə'; // −high, −low, +front, −back, −rnd, +tense
if (is('模冬 灰魂 韻')) return 'o'; // −high, −low, +front, −back, −rnd, +tense
if (is('麻庚銜夬刪 韻 二等')) return 'a͇';
// −high, +low, +divII, −rnd, +tense
if (is('麻庚 韻 三等') ||
is('歌唐談泰寒 韻')) return 'a'; // −high, +low, −front, −back, −rnd, +tense
// 二合元音
if (is('支韻')) return 'iə'; // +front, −back, −rnd, +tense
if (is('魚虞鍾韻')) return 'ɨə'; // −front, −back, −rnd, +tense
if (is('清韻')) return 'ia'; // +front, −back, −rnd, +tense
if (is('陽韻')) return 'ɨa'; // +front, −back, −rnd, +tense
throw new Error('无元音规则');
// 函数:将半元音转换为元音
function semivowelToVowel(consonant) {
switch (consonant) {
case 'j': return 'i';
case 'ɥ': return 'y';
case 'j̈': return 'ɨ';
case 'ɥ̈': return 'ʉ';
case 'w': return 'u';
return consonant;
5. 声调
本文从简,声调无视音系层级范式,直接转换为最终形式。
声调写成五度标记
、
声调分阴阳
、
声调附加符号写在音节前
也在这里应用。详见下面代码实现。
// 函数:将声调的音韵地位转换为语音
function getTone() {
if (選項.声调写成五度标记) {
if (選項.声调分阴阳) {
if (is('平聲')) return is清 ? '˦˧' : '˨˩';
if (is('上聲')) return !is全浊 ? '˦˥' : '˨˧';
if (is('去聲')) return is清 ? '˥˦˥' : '˧˨˧';
if (is('入聲')) return !is全浊 ? '˥' : '˨˩';
} else {
if (is('平聲')) return '˧˩';
if (is('上聲')) return '˧˥';
if (is('去聲')) return '˦˨˦';
if (is('入聲')) return '˧';
} else {
if (選項.声调分阴阳) {
if (is('平聲')) return is清 ? '̂' : '̏';
if (is('上聲')) return !is全浊 ? '̋' : '̌';
if (is('去聲')) return is清 ? '᷇' : '᷅';
if (is('入聲')) return !is全浊 ? '́' : '̀';
} else {
if (is('平聲')) return 選項.声调附加符号写在音节前 ? 'ˋ' : '̀'; // 写在音节前时直接用独立的附加符号
if (is('上聲')) return 選項.声调附加符号写在音节前 ? 'ˊ' : '́';
if (is('去聲')) return 選項.声调附加符号写在音节前 ? 'ˉ' : '̄';
if (is('入聲')) return '';
throw new Error('无声调规则');
四、音系规则(及其代码实现)
// 获取音节的各部分
let initial = getInitial();
let glide = getGlide();
let nucleus = getNucleus();
let coda = getCoda();
let tone = getTone();
1 介音在后部锐音后被声母吸收而删除
/**
G -> ∅ / [COR, −ant]__
if (is('知莊章組 或 日以母')) glide = '';
2 舌面介音被唇音或唇化声母同化 〈帮组或合口三 A、C〉
/**
j -> ɥ / [+rnd]__
j̈ -> ɥ̈ / [+rnd]__
β / [LAB, −rnd]__
if (initial.includes('ʷ')) {
glide = glide.replace('j', 'ɥ');
} else if (is('幫組')) {
if (glide == 'j̈') glide = 'β';
3 唇化的声母j实现为ɥ 〈以母合口〉
/**
jʷ -> ɥ
if (initial == 'jʷ') initial = 'ɥ';
4 j韵尾在低元音和中松元音后 〈祭泰夬废〉 实现为 ɹ
/**
j -> ɹ / {[+low], [−high, −tense]}__
if (選項.祭泰夬废韵尾推导为ɹ && is('去聲')) {
if (nucleus.includes('a') || nucleus == 'ɜ') {
if (coda == 'j') coda = 'ɹ';
5 松元音的前后被前接辅音的锐钝同化
/**
ɪ -> i / [COR]__
ɨ / 其他环境
ɜ -> e / [COR]__
ə / 其他环境
if (選項.要推导松元音) {
if ([...'ɹjɥ'].includes(glide) || is锐) { // 不包含 glide 为零的情况,所以用 [...'ɹjɥ']
if (nucleus == 'ɪ') nucleus = 'i';
if (nucleus == 'ɜ') nucleus = 'e';
} else {
if (nucleus == 'ɪ') nucleus = 'ɨ';
if (nucleus == 'ɜ') nucleus = 'ə';
6 二合元音的后滑音(off-glide)部分被元音的前后同化
/**
ə -> ɛ / i__
-> ɜ / ɨ__
a -> æ / i__
-> ɐ / ɨ__
if (選項.要推导二合元音) {
if (nucleus == 'iə') nucleus = 'iɛ';
if (nucleus == 'ɨə') nucleus = 'ɨɜ';
if (nucleus == 'ia') nucleus = 'iæ';
if (nucleus == 'ɨa') nucleus = 'ɨɐ';
7
一等韵的韵核
三等韵的韵核
/**
a -> a / {[COR, +ant, −rnd]G, [COR, −ant]}__
-> ɑ / 其他环境
if (選項.要推导a && nucleus == 'a') {
nucleus = 'ɑ';
if (is锐 && glide && !initial.includes('ʷ') || is锐后 || !is锐 && [...'ɹjɥ'].includes(glide)) {
// 音系规则本来不限制韵尾,但章组谈韵有“㶒譫”两小韵,需要归到 ɑ,所以在这里过滤
if ('ŋk'.includes(coda)) nucleus = 'a'; // 注意 'ŋk'.includes(coda) 包含的是 ŋ、k 和零韵尾这 3 种
8 央高元音被唇音或唇化声母同化(包括二合元音ɨɜ -> ʉɜ 〈虞钟阳韵〉 )
/**
ɨ -> ʉ / [LAB]__
if (initial.includes('ʷ') || initial == 'ɥ' || glide == 'β') {
nucleus = nucleus.replace('ɨ', 'ʉ');
9 i在卷舌咝音和龈韵尾之间 〈庄组真臻欣韵开口〉 舌冠化为ɹ̩
/**
i -> ɹ̩ / [COR, −ant, +r, +fric, −rnd]__[COR]
if (選項.庄组臻摄开口推导为ɹ̩ && is('莊組') && !initial.includes('ʷ') && [...'nt'].includes(coda)) {
if (nucleus == 'i') nucleus = 'ɹ̩';
10 零介音、唇音或唇化韵尾前的ə 〈豪覃韵〉 实现为ʌ
/**
ə -> ʌ / 非G__[LAB]
if (選項.豪覃韵韵核推导为ʌ && !glide && [...'mpw'].includes(coda)) {
if (nucleus == 'ə') nucleus = 'ʌ';
11 e͇w 〈肴韵〉 、βəm 〈凡韵〉 的韵核实现为圆唇元音
/**
e͇ -> œ͇ / __w
{e, ə} -> œ / [LAB]G__m
// 先转换𠑆𦑣䎎小韵,它们属于凡韵
if (is锐 && initial.includes('ʷ') && [...'mp'].includes(coda)) {
if (nucleus == 'e') nucleus = 'ə';
if (選項.肴凡韵韵核推导为œ) {
if (nucleus == 'e͇' && coda == 'w') nucleus = 'œ͇';
if (nucleus == 'ə' && (initial.includes('ʷ') || is('幫組')) && [...'mp'].includes(coda)) nucleus = 'œ';
12 齿龈阻音 〈端精组〉 后的介音接前元音时被同化(圆唇时可选)
/**
G -> j / [COR, +ant, −son, −rnd]__[+front]
ɥ / [COR, +ant, −son, +rnd]__[+front]
if (is锐前 && 'ieæa'.includes(nucleus[0])) {
if (!initial.includes('ʷ')) {
if (glide) glide = 'j';
} else if (選項.精三寅合口介音推导为ɥ) {
if (glide) glide = 'ɥ';
13 i在唇音或唇化声母和软腭韵尾之间 〈蒸幽韵〉 增生ɹ滑音
/**
G -> ɹ / [LAB]__i[DOR]
if (選項.蒸幽韵合口增生ɹ滑音 && (initial.includes('ʷ') || is('幫組')) && nucleus == 'i' && [...'ŋkw'].includes(coda)) {
glide = 'ɹ';
14 接介音的ɣ 〈云母〉 实现为ɹ
/**
ɣG -> ɹ
ɣʷG -> ɹʷ
if (選項.云母推导为ɹ && initial.includes('ɣ') && glide) {
initial = initial.replace('ɣ', 'ɹ'); // ɹ 视为声母
glide = '';
15 软腭音直接后接元音时 〈见系和匣母非三等〉 实现为软腭后音
/**
[DOR] -> [−high] / __V
if (選項.见系非三推导为软腭后音 && !glide) {
initial = velarToUvular(initial);
16 h直接后接元音时 〈晓母非三等〉 实现为软腭后音
/**
h -> χ / __V
if (選項.晓母非三推导为软腭后音 && !glide) {
initial = initial.replace('h', 'χ');
17 圆唇元音和低非前元音后的软腭韵尾 〈通江宕摄〉 实现为软腭后音
/**
[DOR] -> [+back] / {[+round], [+low, −front]}__
if (選項.通江宕摄推导为软腭后音) {
if ('ʉuoœɑ'.includes(nucleus[0]) || (nucleus.includes('ɐ') && 選項.要推导a)) {
coda = velarToUvular(coda);
18 u在钝音声母和无介音齿龈声母后 〈侯韵〉 裂化
/**
u -> u / [COR, −ant]__#
ɘu / 其他__#
if (選項.侯韵裂化为ɘu && nucleus == 'u' && !coda) {
nucleus = 'ɘu';
if (is锐后 || is('云母') || glide) nucleus = 'u';
19 高元音 + 半元音韵尾 〈微幽韵〉 实现为二合元音
/**
j -> i / [+high]__
w -> u / [+high]__
if ('iɨʉuɪ'.includes(nucleus)) {
if (coda == 'j') coda = 'i';
if (coda == 'w') coda = 'u';
20 移除与韵核同部位介音
/**
[DOR, +son] -> ∅ / C__[+high, −back]
if ('iɨʉ'.includes(nucleus[0])) {
if (['j', 'ɥ', 'j̈', 'ɥ̈'].includes(glide)) glide = '';
21 齿龈音 〈端精组〉 接非后高元音时省略介音
/**
{j, ɥ} -> ∅ / [COR, +ant, −son]__[+high, +front, −back]
G -> ∅ / [COR, +ant, −son]__[+high, −front, −back]
if (選項.精组非后高元音省略介音 && is锐前) {
if (nucleus[0] == 'i' && [...'jɥ'].includes(glide)) glide = '';
if ('ɨʉ'.includes(nucleus[0])) glide = '';
五、后处理的代码实现
if (選項.知组写成卷舌塞音 && is('知組 或 來母')) {
initial = retroflexToStop(initial);
if (is('知組 三等')) glide = 'ɹ'; // 还原出三等介音
if ('iɨʉ'.includes(nucleus[0])) glide = ''; // 再次应用音系规则 (21)。平行地,也要应用给来母
if (選項.中元音写成半低元音) {
nucleus = nucleus.replace('e', 'ɛ');
nucleus = nucleus.replace('o', 'ɔ');
if (選項.ɑ写成a) {
nucleus = nucleus.replace('ɑ', 'a');
if (選項.半元音介音写成元音) {
glide = semivowelToVowel(glide);
if (選項.半元音韵尾写成元音) {
coda = semivowelToVowel(coda);
if (is('二等')) {
if (選項.二等元音写成r音钩) {
nucleus = nucleus.replace('͇', '˞');
} else if (選項.二等元音写成双下横线) {
nucleus = nucleus.replace('͇', '̳');
if (選項.声调写成五度标记) return initial + glide + nucleus + coda + tone;
if (選項.声调附加符号写在音节前) {
if (選項.声调分阴阳) return '\xA0' + tone + initial + glide + nucleus + coda; // 需要用无中断空格(U+00A0),否则位于行首的空格可能被浏览器忽略
return tone + initial + glide + nucleus + coda;