


《深入理解并行编程》笔记


本文是《Is Parallel Programming Hard, And, If So, What Can You Do About It?》的中文翻译版《深入理解并行编程》的读书笔记(就是一些摘录整理,不想按照严格的文章进行书写,所以大佬们各取所需),虽然读书笔记一般是上传豆瓣,但是看到知乎上RCU内容很少,且自己有时从知乎上获得一些知识启发,算是回馈一下社区。由于时间不多,书没读完,内容也没贯通,后续会继续补更。
原著书作者Paul E.Mckenney,是Linux RCU Maintainer,本书很详细介绍了linux内核多核并行编程的干货,需要多精读。
硬件系统
霍金的半导体难题:1.有限的光速;2.物质的原子本质。这意味着在摩尔定律受阻,单核CPU性能难以提升,多核CPU大行其道的时代,多核CPU间通信代价高昂,需要注意性能影响。为了提升性能,硬件做了如下设计:
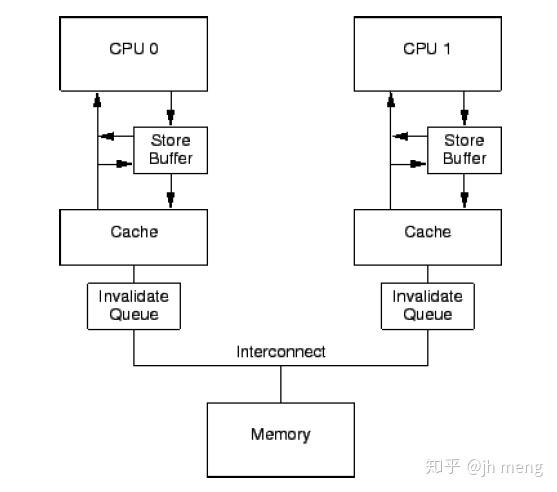

- 由于CPU速度远大于内存系统速度,CPU硬件中加入了缓存cache,cache与内存间数据传递是范围从16到256字节不等的缓存行cache-line。缓存缺失原因可能是startup cache miss(开始数据没有),capacity miss(容量满淘汰)以及communication miss(多个CPU间一致性同步使无效)。缓存缺失可能会导致CPU stall
- 由于一个变量可能缓存在多个CPU的cache中,多个CPU的cache需要一致性协议MESI进行同步。MESI协议即缓存行中modified(单CPU拥有最新修改的缓存数据),exclusive(单CPU独占缓存与内存最新数据),shared(数据由多个CPU共享),invalid(空数据)四种状态间进行转移
- CPU除了cache,还有存储缓冲store buffer。这是为了提高对于特定缓存行的第一次写操作的miss,比如foo = 1操作可能因为foo一致性同步而造成CPU停顿(等待使无效应答),这样CPU只需将新写数据保存到store buffer就可继续运行
- 由于store buffer通常很小,密集读写操作会造成大量使无效消息,因此增加使无效队列invalidate queue。带使无效队列的CPU可以迅速应答一个使无效消息,而不必等待相应的行真正变成无效状态。这意味着在没有真正将cache无效前,就告诉其他CPU已经使无效了。这多少有一点欺骗的意思
内存屏障
由于以上硬件设计,CPU被设计成在从内存中获取数据的同时可以执行其他指令,这明显会导致指令和内存引用的乱序执行(执行顺序与代码顺序不同),因而编译器和同步原语有责任通过对内存屏障的使用来保护在并行编程中用户的直觉。
简单规则:
- 一个特定CPU将像“编程顺序”那样看到它对内存的访问操作
- 单变量存储序列一致
- 内存屏障将成对操作。不能保证一个CPU将看到第二个CPU访问操作的正确顺序,即使第二个CPU使用一个内存屏障,除非第一个CPU也使用一个配对的内存屏障
- 互斥锁原语提供保护。申请,释放锁必须以全局顺序被看到
- 不能保证在内存屏障之前的内存访问将在内存屏障指令完成时完成
- 仅仅在两个CPU之间或者CPU与设备之间需要交互时,才需要内存屏障
内存屏障分类:
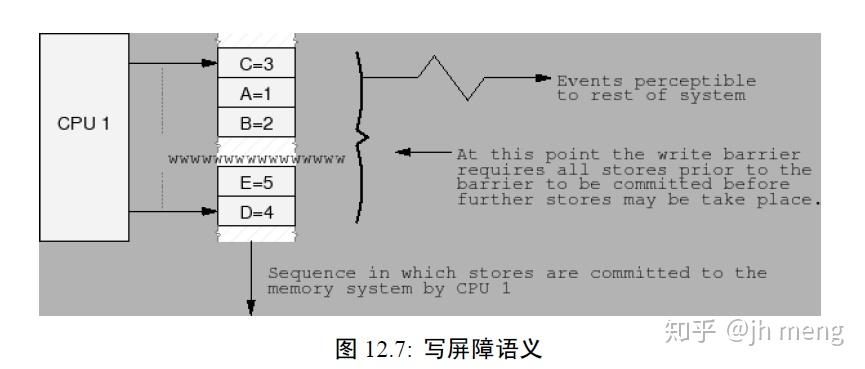
- 写内存屏障:CPU可以被视为按时间顺序提交一系列存储操作,所有在写屏障之前的存储操作将发生在所有屏障之后的存储操作之前。写屏障仅仅对写操作进行排序,对加载没有任何效果。注意写屏障通常应当与读或者数据依赖屏障配对使用
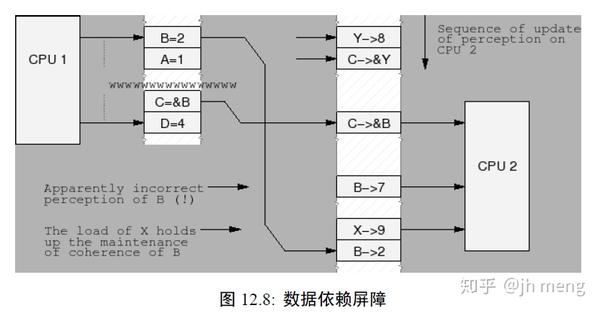
- 数据依赖屏障:弱的读屏障。当两个装载操作中,第二个依赖于第一个的结果时 (如第一个装载得到第二个装载的地址),需要一个数据依赖屏障,以确保第二个装载的目标将在第一个地址装载之后被更新。数据依赖屏障仅仅对相互依赖的加载进行排序。它对任何存储没有效果,对相互独立的加载或者重叠加载也没有效果。注意第一个装载实际上需要一个数据依赖而不是控制依赖。如果第二个装载的地址依赖于第一个装载,但是依赖的是一个条件而不是实际装载地址本身(if-else选择), 那么它就是一个控制依赖,这需要一个完整的读屏障
- 读内存屏障:所有在屏障之前的加载操作将在屏障之后的加载操作之前发生。读屏障仅仅对加载进行排序,它对存储没有任何效果。读内存屏障隐含数据依赖屏障,因此可以替代它。
- 通用内存屏障:通用内存屏障保证屏障之前的加载、存储操作都将在屏障之后的加载、存储操作之前被系统中的其他组件看到。通用内存屏障同时对加载和存储操作进行排序。通用内存屏障隐含读和写内存屏障,因此也可以替换它们中的任何一个
- 锁原语隐含内存屏障:LOCK操作确保所有LOCK操作后面的内存操作看起来发生在锁操作之后,LOCK锁操作之前的内存操作可能发生在它完成之后。UNLOCK 操作确保在UNLOCK操作之前的所有内存操作看起来发生在锁操作之前,UNLOCK操作之后的内存操作看起来可能发生在它完成之前。LOCK后面跟随UNLOCK不能设定为全内存屏障,因为LOCK之前的操作可能发生在LOCK之后,并且UNLOCK之后的访问可能发生在UNLOCK之前,因此这两个访问可能相互交叉
SMP屏障对:
一个写屏障应当总是与数据依赖屏障或者读屏障配对,虽然通用屏障也是可以的。类似的一个读屏障或者数据依赖屏障总是应当与至少一个写屏障配对使用,虽然通用屏障也是可以的。



写屏障图解:

数据依赖屏障图解:





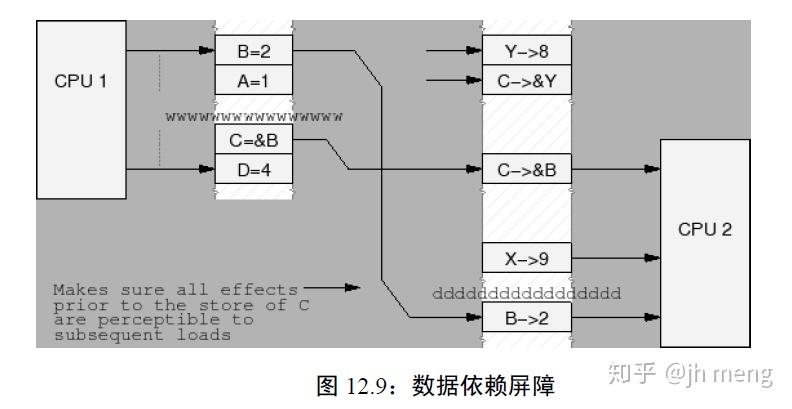

读内存屏障图解:
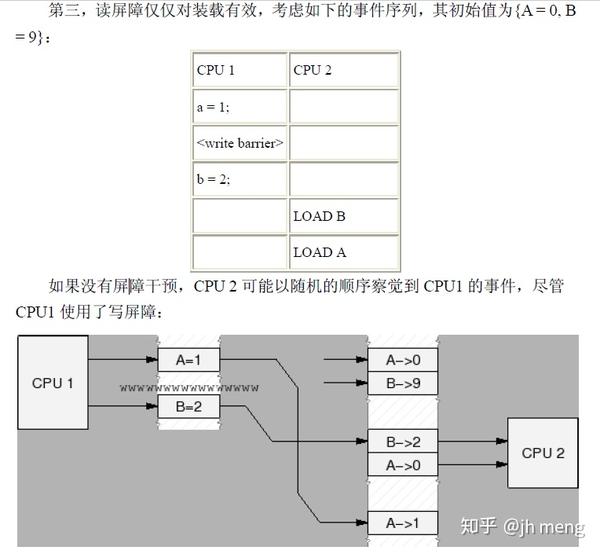

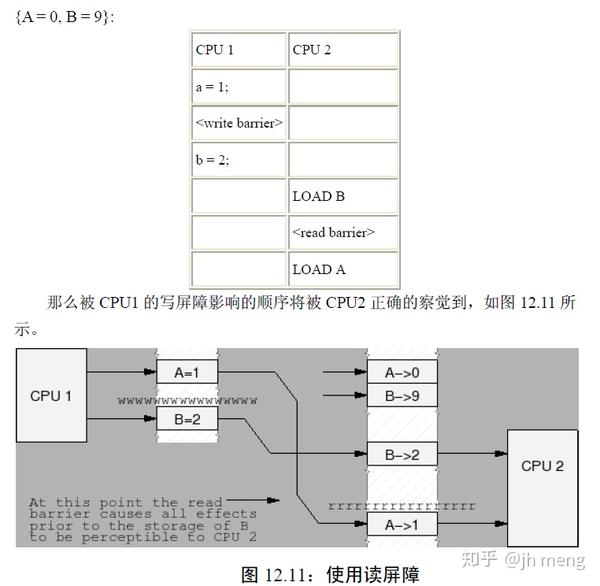



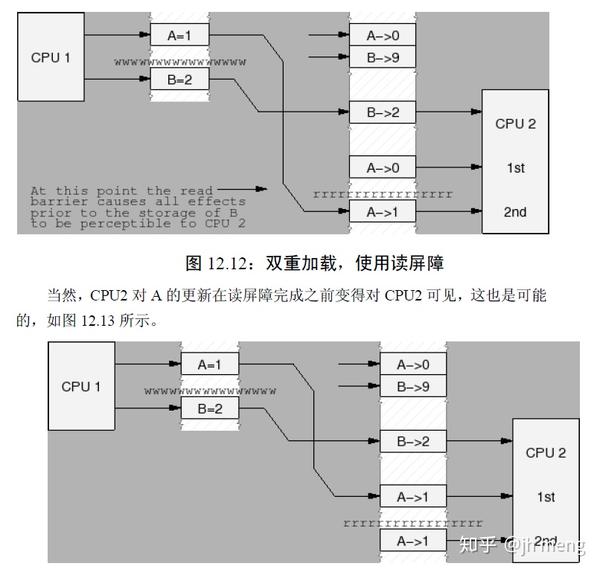

多CPU使用同一个锁的顺序:


c++11内存模型:


RCU
并行编程要注意性能与安全性。可以使用锁之类的同步原语,简单可靠,但是多核CPU同步造成扩展时性能降低。或者使用内存屏障与原子指令,但是编程复杂,很容易就犯难以察觉的错误。过于轻率地使用大锁或者原子变量,由于CPU缓存一致性同步造成可扩展性不够。这时有种策略就是延迟处理,通用的并行编程延后技术包括排队、引用计数和RCU。
引用计数跟踪一个对象被引用的次数,防止对象过早的被释放。Linux内核中kref:
1 struct kref {
2 atomic_t refcount;
3 };
5 void kref_init(struct kref *kref)
7 atomic_set(&kref->refcount,1);
10 void kref_get(struct kref *kref)
11 {
12 WARN_ON(!atomic_read(&kref->refcount));
13 atomic_inc(&kref->refcount);
14 }
16 int kref_put(struct kref *kref,
17 void (*release)(struct kref *kref))
18 {
19 WARN_ON(release == NULL);
20 WARN_ON(release == (void (*)(struct kref *))kfree);
22 if ((atomic_read(&kref->refcount) == 1) ||