|
|
|


histcite和citespace哪个引文分析能力更强?
histcite和citespace这两个软件,那个分析能力更强?
关注者
125
被浏览
72,397
9 个回答

Histcite主要的功能是统计分析,其在引文网络的分析构建分析上架构清晰,可以比较清楚的发现引文网络中关键文献及大概发展。
citespace中文献共被引分析是其最为突出的功能之一,可以很简单的找到引用次数高的文章,同时通过共被引聚类分析,可以分析研究的主要集中方向, 并且可以找到每个聚类中的关键文献。

最近刚用,理论上说,citespace应该是更强一些,不过他的难度比较大,看图什么的需要点时间去摸索,不容易快速掌握。但是histcite上手很快,而且他的分析比较明白,就几个参数,每个参数都简单明了,能快速定位经典文献,还可以构成引用图,我个人觉得比较好用。总的来说,citespace功能多,histcite相对少一些,看你用的方面,如果是找文献看的话,histcite就能满足。


一、背景介绍
Histcite 是一种文献索引分析软件,用来处理从Web Of Science输出的文献索引信息。它可以帮助我们迅速掌握某一领域的文献历史发展,发现关键研究和关键学者。它还能方便绘出这一领域文献历史关系,使得该领域的发展,关系,人物一目了然。HistCite 这款软件是 Thomson Reuters (汤森路透)公司开发的,和 Web Of Science 是一家公司,所以 HistCite 只支持 Web Of Science 数据库,对于 Scopus 等数据库则无能为力。我介绍的是一款由中国科学院王庆同学破解的一个软件版本, 只需下载解压,无需安装 。软件图片如下:

二、使用流程
使用流程主要分4个步骤:1、 获取数据 ,2、 导入数据 ,3 统计分析 ,4、 引证关系图 。下面将从这4个步骤依次介绍。
1、 获取数据
(1)、输入网址” http:// apps.webofknowledge.com / ”,进入Web Of Science,注意数据库要选择核心合集【web of Science Core Collection】!
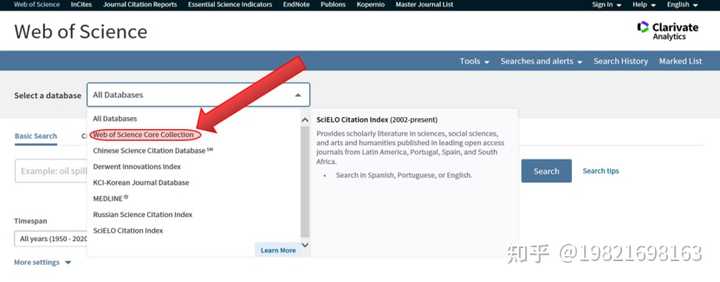

(2)、输入检索关键词,例如输入【neuro】和【pain】(我的研究领域是疼痛的神经机制),点击【search】进行检索。
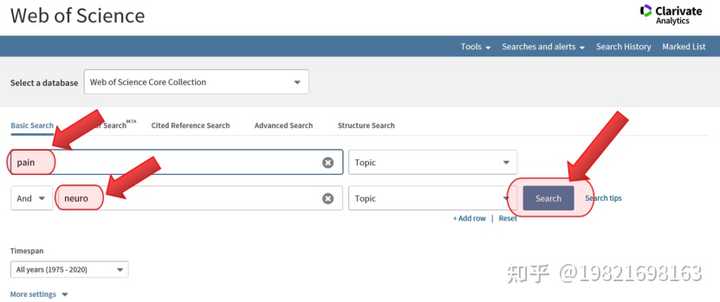

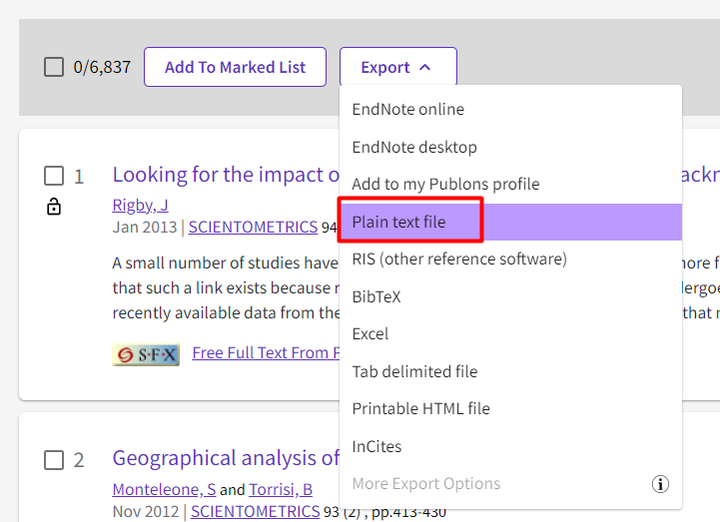
(3)、检索结果保证在2000~3000左右,因为我们需要导出文献,但Web Of Science每次只能导出500篇,如果检索结果太多甚至上万,不方便我们导出。点击【Export】,进行导出。
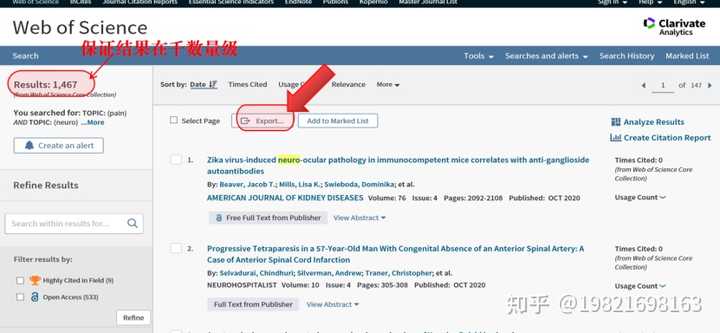

(4)、下面开始导出文献信息,点击【Other File Formats】.
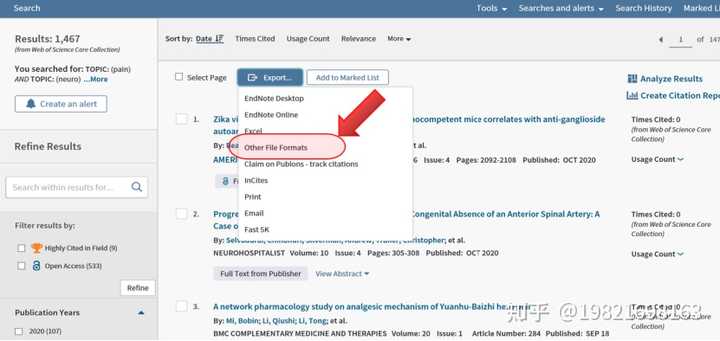

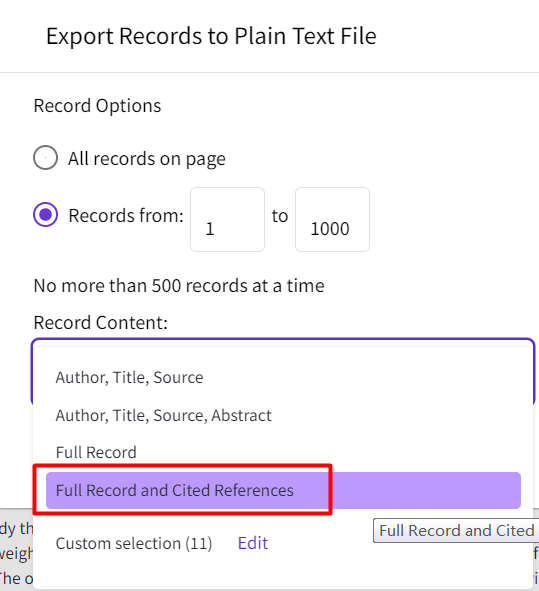
(5)、在弹出的菜单中,记录数填写1到500,因为每次最多只能导出500篇文献,所以上面的1467篇文献需要分成3次导出,后面导出的时候依次填写501到1000、1001到1476。“Record Content”选择【Full Record and Cited References】。“File Format”选择【Plain Text】,然后点击【Export】即可得到导出的 txt 文件,类似可以导出其他2个。
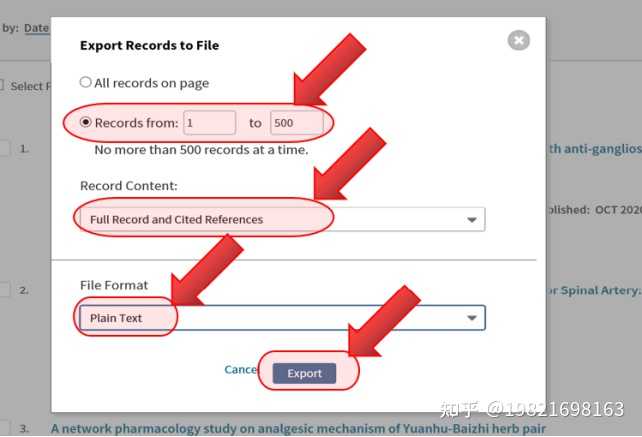

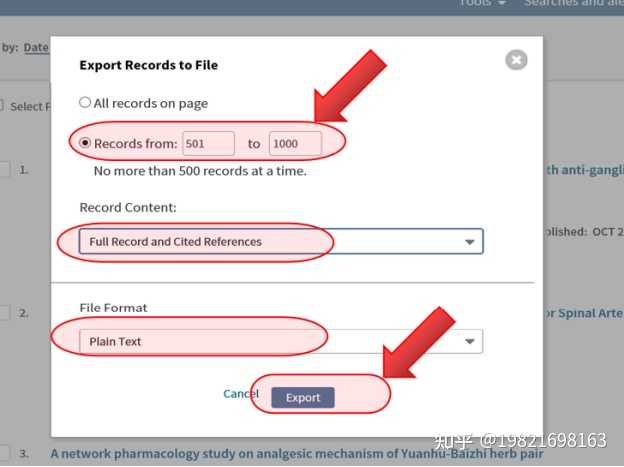

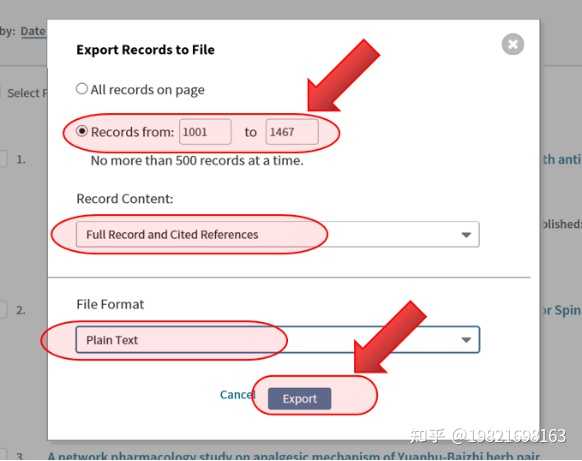

注意:含500个记录的txt文档一般是3M左右,如果你的只有几百K,请仔细按照上面这张图进行导出!!!
2、导入数据
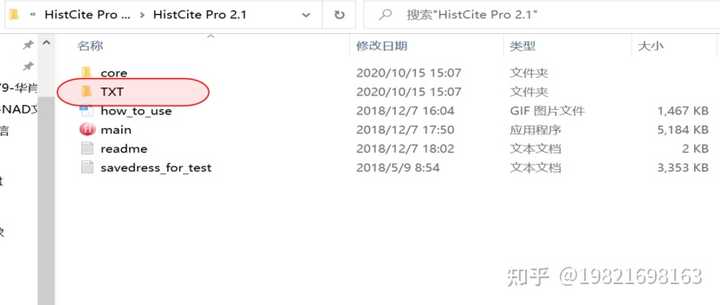
(1)、打开软件,把导出的3个文档拖入软件里的【TXT】里

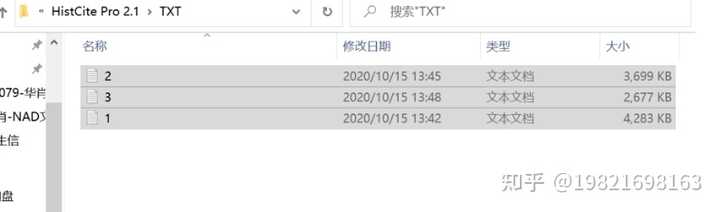

(2)、返回上一页面,点击【main】
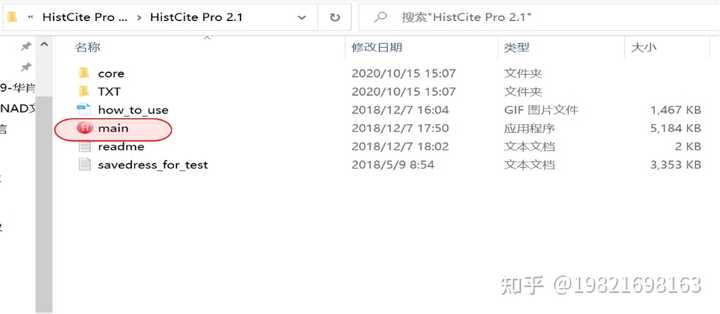

(3)、会自动弹出下列页面,输入【1】,点击【Enter】键
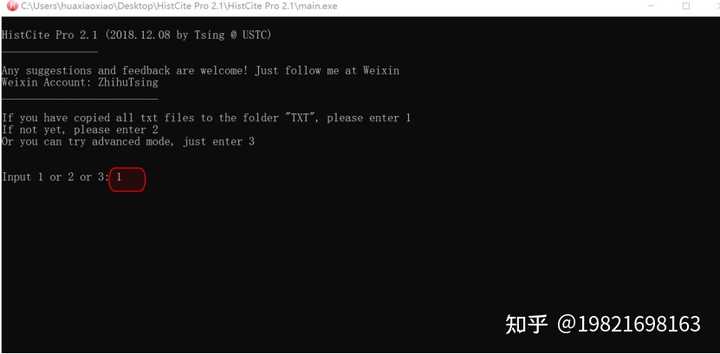

3、统计分析
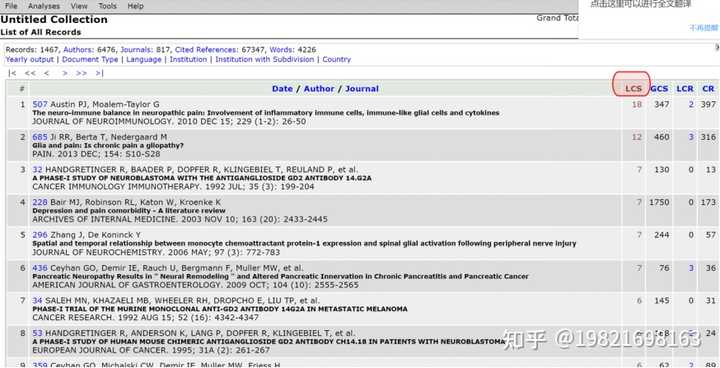
(1)、可以看到1467篇文献信息全部加载出来,点击【LCS】,对文章进行排序。LCS是Local citation score(本地引用次数),表示受同行的关注程度,LCS越大,说明此文献受到本领域关注越大,也就越值得我们去阅读。GCS是Global citation score(全球引用次数),它包含其他领域、专业对这篇文献的关注度。一般LCS与GCS会有偏差。一篇文献可能受到的同行关注度较高,但受到其他领域的关注程度较低。我们一般关注LCS,以它对文献进行排序。LCR是Local cited references(当前数据库中被引用的文献)。CR是Cited reference(文章引用的参考文献数量)。
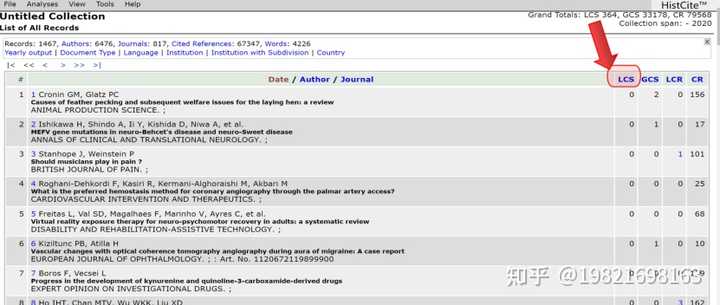

(2)、点击【LCS】,对文献进行从高到低排序。排名越靠前,说明受到同行关注度越高,也就越值得我们去阅读。序号为“507”这篇文献在导入的所有文献中,受到本领域的关注度最高。

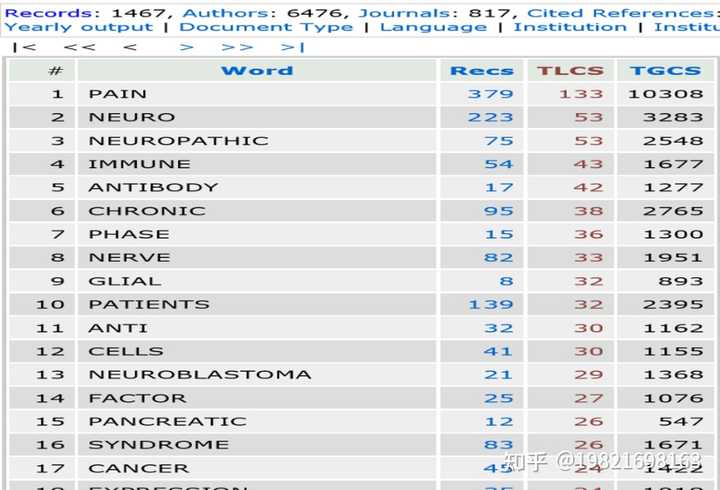
(3)、左上角还有“Records”, “Authors”, “Journals”等可以以它们对文献进行分析。这里以【Words】为例。点击【Words】


这里对关键词进行了排序分析,可以看出这个领域一些重要的关键词,有助于我们以后的文献关键词检索。

4、引证关系图
(1)、点击【Tools】里的【Graph Maker】

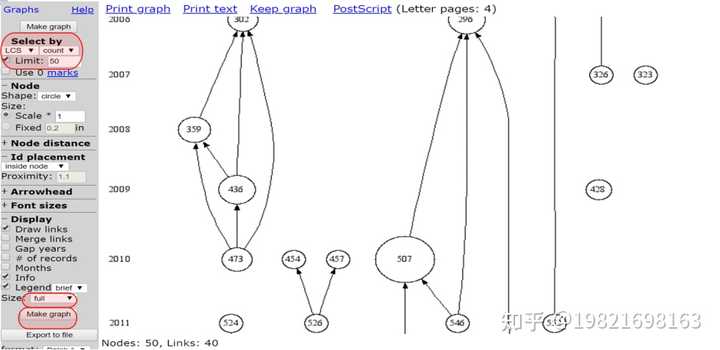
(2)、左侧”select by”选择【LCS】,【Limit】选择50,“size”选择【full】,点击【Make Graph】。出现右侧的图。每个圆圈表示一篇文献,中间的数字是这篇文献在数据库中的序号。其中圆圈大小代表LCS值,也就是受到同行关注的程度。圆圈越大,说明受到本领域关注程度越高。其中序号“507”圆圈最大,说明“507”这篇文献在所有导入的文献中受到关注程度最高。这与我们上图分析结果一致。箭头代表着每篇文献之间的联系,为我们梳理了此领域的脉络关系。这张图能更直观地反映了分析结果,有助于我们更好地理解。

三、结语
总之,这是一款非常强大的引文分析工具,可以快速绘制出某个研究领域的发展脉络,锁定某个研究方向的重要文献和学术大牛,还可以找到某些具有开创性成果的无指定关键词的论文。
引文分析是计量分析中经常用到的方法,有许多引文网络分析工具,但如何将下载的文献题录数据转换为引文数据是引文分析的第一步,也是许多同学经常遇到的问题,本文以wos数据为例,详细描述使用python构建引文网络过程。
注: 本文所述引文网络为 引用关系网络 , 非 共被引网络。
1 数据下载
目标:了解文献计量学领域的引用网络,从wos下载数据,选取 Scientometrics 期刊作为数据来源( 仅作演示使用,使用该期刊代替文献计量学内容不够严谨 )。
在 WOS 中使用ISSN号进行检索,获取6837篇文章。


由于要进行引文分析,选择“文本格式”数据和“包含引文的全纪录”进行下载,每次最多下载500条。


下载完成后的数据:

2 数据处理
分析文本中DOI所在位置,论文DOI为DI字段,引用论文的DOI为CR字段,但并非每条引文都有DOI,在这里我们只获取有DOI的数据。


通过以下代码进行文本读取和字段抽取,定义了两个函数,调用extract_all_text()函数,传入文件所在文件夹,即可抽取doi引文数据,同时为了便于后期展示,在代码中获取了每个DOI的时间数据作为备用,执行完成后,在当前目录生成相应的excel文件。
import os
import re
import pandas as pd
def extract_all_text(folder):
读取wos文件,抽取引文数据
:param folder: 文件所在文件夹
:return:
record_list = []
di_year_list = []
file_list = os.listdir(folder)
for file in file_list:
tmp_record_list, tmp_di_year_list = extract_text(os.path.join(folder, file))
print('{}读取完成,record数据量:{} , di数据量:{}'.format(file, len(tmp_record_list), len(tmp_di_year_list)))
record_list.extend(tmp_record_list)
di_year_list.extend(tmp_di_year_list)
print('总数据量:{}'.format(len(record_list)))
df1 = pd.DataFrame(record_list)[['DI', 'CR']]
df1.to_excel('wos_citation.xlsx', index=False)
df2 = pd.DataFrame(di_year_list)[['DI', 'PY']]
df2.drop_duplicates(subset=['DI'], keep='first', inplace=True)
df2.to_excel('di_py.xlsx', index=False)
return df1
def extract_text(file_name):
record_result = []
DI_year_result = []
with open(file_name, 'r', encoding='utf8') as text_file:
record = ''
while True:
line = text_file.readline()
if line.startswith("PT"):
record = ''
if line.startswith("ER"):
dict_result = {}
record = record + line
for col_name in ['CR', 'DI', 'PY']:
reg_str = r'\n' + col_name + '\s{1}((.*\n)+?)[0-9A-Z]{2}\s{1}'
p_reg = re.compile(reg_str)
m_reg = re.search(p_reg, record)
if m_reg:
target = m_reg.group(1)
if col_name in ['CR']:
target_origin = re.sub(r'\n\s{2,}', '#$$#', target)
target = ','.join([x.split(' ')[-1] for x in target_origin.split('#$$#') if 'DOI' in x])
DI_year_result.extend([{'DI': x.split(' ')[-1].replace('\n', ''), 'PY':x.split(',')[1].replace(' ', '')} for x in target_origin.split('#$$#') if 'DOI' in x])
else:
target = re.sub(r'\n\s{2,}', ' ', target)
target = re.sub(r'\n', '', target)
dict_result[col_name] = target
else:
dict_result[col_name] = ''
DI_year_result.append({'DI': dict_result['DI'], 'PY': dict_result['PY']})
record_result.append(dict_result)
record = record + line
if not line:
break
return record_result, DI_year_result
# 传入您的文件夹
record_df = extract_all_text(FOLDER_PATH_OF_DATA)程序执行过程如下:

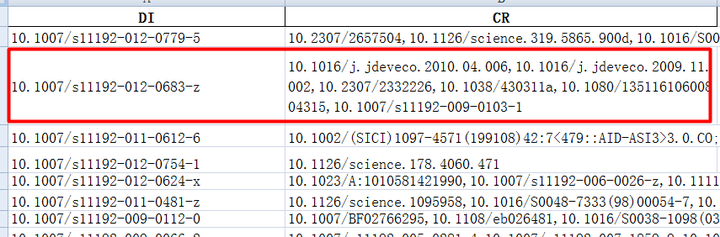
下图为抽取结果的excel文件截图,图中标出内容为上方文本中对应数据。

3 生成引文网络
根据第二步生成的结果,构建引文数据的边集合。由于引文关系存在方向,我们用以下方式来存储。
A引用了C和D,则用两条边表示:C->A,D->A。
详细代码如下:
def generate_citation_network(records_df):
生成邻接矩阵
:param records_df:
:return:
# 筛选不为空的数据
records_df = records_df[(records_df['DI'] != '') & (records_df['CR'] != '')]
result_list = []
for index, item in records_df.iterrows():
CR_list = item['CR'].split(',')
for CR in CR_list:
result_list.append({'s': CR, 'd': item['DI']})
matrix_df = pd.DataFrame(result_list)
matrix_df.to_excel('citation_network.xlsx', index=False)
return matrix_df
matrix_df = generate_citation_network(record_df)运行结束后,生成文件citation_network.xlsx, s列为被引文献,d列为施引文献。

4 引文网络可视化
使用networkx来简单展示下网络,由于数据量较大,通过限制出度大于45, 即在该集合中至少被45篇文章引用,同时找到最大弱联通子图,最终将节点个数减少到79个,画图函数如下。
def draw_graph(network_df, di_ti_year_dict):
画出引文网络图
:param network_df: 引文网络
:param di_ti_year_dict: DOI及其年份数据
:return:
# 创建有向图
G = nx.DiGraph()
# 加入边的集合
G.add_edges_from(network_df.to_records(index=False).tolist())
# 我们通过节点度数来筛选,出度大于45,即至少被45篇文章引用
outdeg = list(G.out_degree)
to_keep_out = [n[0] for n in outdeg if n[1] > 45]
print('keep out: {}'.format(len(to_keep_out)))
G_sub_1 = G.subgraph(to_keep_out)
# 再找到最大的联通子图(此处用若联通分量:同一弱连通分量里的任意两个点,保证至少一方能到达另一方)
components_list = list(nx.weakly_connected_components(G_sub_1))
count_list = [len(x) for x in components_list]
max_count = max(count_list)
print('最大弱联通分量的节点个数:{}'.format(max_count))
max_index = count_list.index(max_count)
max_components = components_list[max_index]
sub_set = set(to_keep_out).intersection(set(max_components))
print('最终节点数量: {}'.format(len(sub_set)))
G_sub_2 = G.subgraph(sub_set)
# 计算出度用于最终显示节点大小
out_degree_dict = dict(G_sub_2.out_degree)
year_di_group = {}
#得到年的列表
year_list = sorted(set([di_ti_year_dict[x] for x in sub_set]))
print(year_list)
# 得到每年的数据
# 年份太多,对年份分组, 1990以前, 1991-1995, 1996-2000, 2001-2005, 2006-2010, 2011-2015, 2016-2020
year_di_group[1990] = [x for x in sub_set if di_ti_year_dict[x] <= 1990]
year_di_group[1995] = [x for x in sub_set if di_ti_year_dict[x] > 1990 and di_ti_year_dict[x] <= 1995]
year_di_group[2000] = [x for x in sub_set if di_ti_year_dict[x] > 1995 and di_ti_year_dict[x] <= 2000]
year_di_group[2005] = [x for x in sub_set if di_ti_year_dict[x] > 2000 and di_ti_year_dict[x] <= 2005]
year_di_group[2010] = [x for x in sub_set if di_ti_year_dict[x]> 2005 and di_ti_year_dict[x] <= 2010]
year_di_group[2015] = [x for x in sub_set if di_ti_year_dict[x]> 2010 and di_ti_year_dict[x] <= 2015]
year_di_group[2020] = [x for x in sub_set if di_ti_year_dict[x]> 2015 and di_ti_year_dict[x] <= 2020]
# 根据年份确定点的位置
pos = {}
for year, node_list in year_di_group.items():
for index, node in enumerate(node_list):
pos[node] = (year, index)
#根据被引年份,修改边的颜色
year_color = {1990: '#CCFF00', 1995: '#E9967A', 2000: '#ADD8E6', 2005: '#D3D3D3', 2010: '#66FFE6',
2015: '#66FF00', 2020: '#CCCCFF'}
edge_colors = [year_color[pos[e[1]][0]] for e in G_sub_2.edges]
# 节点标签, 显示年+doi
label_dict = {}
for n in sub_set:
label_dict[n] = str(di_ti_year_dict[n]) + ' '+n
fig, ax = plt.subplots()
plt.axis("on")
nx.draw_networkx(G_sub_2, pos=pos, ax=ax, labels=label_dict, font_size=6, linewidths=0.5, node_color='#FFEF33',connectionstyle="arc3,rad=0.1" , edge_color=edge_colors, node_size=[v * 100 for v in out_degree_dict.values()])
ax.tick_params(left=False, bottom=True, labelleft=False, labelbottom=True)
plt.show()
network_df = pd.read_excel('citation_network.xlsx')
di_py_df = pd.read_excel('di_py.xlsx', dtype={'PY': np.int})