

翻译论文 Delta Lake:基于云对象存储的高性能ACID表存储格式(一)

与 @汪涉洋 共同翻译了这篇DataBricks的数据湖产品Delta Lake在云上存储相关的论文。
文章较长,分为4篇,附带原文。
翻译论文 Delta Lake:基于云对象存储的高性能ACID表存储格式(一)
翻译论文 Delta Lake:基于云对象存储的高性能ACID表存储格式(二)
翻译论文 Delta Lake:基于云对象存储的高性能ACID表存储格式(三)
翻译论文 Delta Lake:基于云对象存储的高性能ACID表存储格式(四)
目录
摘要
- 引言
2. 动机: 云对象存储的特点及挑战
3. DELTA LAKE存储格式及访问协议
3.1 存储格式
3.1.1 数据对象
3.1.2 日志
3.1.3日志检查点
3.2 访问协议
3.2.1 读表操作
3.2.2 写事务
3.3 隔离级别
3.4 事务频率
4. DELTA中的高级功能
4.1 Time Travel和回滚
4.2 有效的更新、删除和合并
4.3 流式的数据导入和消费
4.4 数据布局和优化
4.5 缓存
4.6 审计日志
4.7 schema演进和增强
4.8 Connectors to Query and ETL Engines
5. DELTA LAKE 使用案例
5.1 数据工程&ETL
5.2 数据仓库&BI
5.3 合规&重新生成数据
5.4 Specialized案例
6 性能实验
6.1 多对象 or 分区的影响
6.2 Z-Ordering 影响
6.3 TPC-DS 性能测试
6.4 写入性能
7. 探讨&局限
8. 相关工作
9. 结论
摘要
云对象存储如Amazon S3,作为目前最大且最节约成本的存储系统,用于实现数据仓库和数据湖的存储非常具有吸引力。但由于其实现的本质是键值存储,保证ACID事务性和高性能具有很大的挑战:元数据操作,比如list对象是很昂贵的操作;一致性保证也受限。在本论文中,我们向大家介绍Delta Lake,一个由Databricks开源的基于云对象存储的ACID表存储层技术。Delta Lake通过使用压缩至Apache Parquent格式的事务性日志来提供ACID,Time Travel以及海量数据集的高性能元数据操作(比如快速搜索查询相关的上亿个表分区)。同时Delta Lake也提供一些高阶的特性,比如自动数据布局优化,upsert,缓存以及审计日志等。Delta Lake表可以通过Apache Spark, Hive, Presto, Redshift等系统访问。Delta Lake目前已被上千个Databriks用户使用,每天处理exabytes级数据,最大的应用实例管理EB级数据集以及上亿对象。
Cloud object stores such as Amazon S3 are some of the largest and most cost-effective storage systems on the planet, making them an attractive target to store large data warehouses and data lakes. Unfortunately, their implementation as key-value stores makes it difficult to achieve ACID transactions and high performance: metadata operations such as listing objects are expensive, and consistency guarantees are limited. In this paper, we present Delta Lake, an open source ACID table storage layer over cloud object stores initially developed at Databricks. Delta Lake uses a transaction log that is compacted into Apache Parquet format to provide ACID properties, time travel, and significantly faster metadata operations for large tabular datasets (e.g., the ability to quickly search billions of table partitions for those relevant to a query). It also leverages this design to provide high-level features such as automatic data layout optimization, upserts, caching, and audit logs. Delta Lake tables can be accessed from Apache Spark, Hive, Presto, Redshift and other systems. Delta Lake is deployed at thousands of Databricks customers that process exabytes of data per day, with the largest instances managing exabyte-scale datasets and billions of objects.
1.引言
云对象存储如Amazon S3以及Azure Blob存储已成为最大且最广泛使用的存储系统,为上百万用户存储EB级数据。除了云服务传统的优点,如按需付费,规模效益,专业的管理等,云对象存储特别具有吸引力的原因是允许用户对存储和计算资源进行分离;举例来说,用户可以存储PB数据,但是仅运行一个集群执行几个小时的查询。
Cloud object stores such as Amazon S3 [4] and Azure Blob Storage [17] have become some of the largest and most widely used storage systems on the planet, holding exabytes of data for millions of customers [46]. Apart from the traditional advantages of clouds services, such as pay-as-you-go billing, economies of scale, and expert management [15], cloud object stores are especially attractive because they allow users to scale computing and storage resources separately: for example, a user can store a petabyte of data but only run a cluster to execute a query over it for a few hours.
因此,目前许多组织使用云存储来管理数据仓库以及数据湖上的大型结构化数据。主流的开源大数据系统,包括Apache Spark, Hive以及Presto支持Apache Parquet,ORC格式云对象存储的读写。商业服务包括AWS Athena, Google BigQuery和Redshift Spectrum 查询也支持以上这些系统及这些文件格式。
As a result, many organizations now use cloud object stores to manage large structured datasets in data warehouses and data lakes. The major open source “big data” systems, including Apache Spark, Hive and Presto [45, 52, 42], support reading and writing to cloud object stores using file formats such as Apache Parquet and ORC [13, 12]. Commercial services including AWS Athena, Google BigQuery and Redshift Spectrum [1, 29, 39] can also query directly against these systems and these open file formats.
不幸的是,尽管许多系统支持云对象的读写,实现高性能及可变的表存储非常有挑战,同时也使得在其上构建数仓很困难。与分布式文件系统如HDFS, 或者DBMS的定制存储引擎不同,大多数云存储对象都仅仅只是键值存储,并没有跨键的一致性保证。它们的性能特点也与分布式文件系统非常不同因此需要获得特殊的关注。
Unfortunately, although many systems support reading and writing to cloud object stores, achieving performant and mutable table storage over these systems is challenging, making it difficult to implement data warehousing capabilities over them. Unlike distributed filesystems such as HDFS [5], or custom storage engines in a DBMS, most cloud object stores are merely key-value stores, with no crosskey consistency guarantees. Their performance characteristics also differ greatly from distributed filesystems and require special care.
在云存储对象中存储关系型数据最常见的方式是使用列存储格式,比如Parquet和ORC,每张表都被存储为一系列对象(parquet或者ORC文件)的集合,通过某些列做分区。这种方式在对象文件的数量适中时,扫描文件的性能尚可接受。但对于更复杂的扫描工作,正确性以及性能都将受到挑战。首先,多对象的更新并不是原子的,查询之间没有隔离:举例来说,如果一个查询需要更新表中的多个对象(比如从表的所有parquet文件中删除某个用户的相关记录),由于是逐个object更新,因此读客户端将会看到部分更新。另外,写回滚也很困难:如果一个更新失败,那么表将处于被污染的状态。第二,对于有上百万对象的大表,元数据操作非常昂贵。比如,parquet文件中footer包含了min/max等统计信息在查询时用来帮助跳过读文件。在HDFS上读footer信息只需要几毫秒,云对象存储的延迟非常高使得跳过读操作甚至比实际的查询花费时间还要长。
The most common way to store relational datasets in cloud object stores is using columnar file formats such as Parquet and ORC, where each table is stored as a set of objects (Parquet or ORC “files”), possibly clustered into “partitions” by some fields (e.g., a separate set of objects for each date) [45]. This approach can offer acceptable performance for scan workloads as long as the object files are moderately large. However, it creates both correctness and performance challenges for more complex workloads. First, because multi-object updates are not atomic, there is no isolation between queries: for example, if a query needs to update multiple objects in the table (e.g., remove the records about one user across all the table’s Parquet files), readers will see partial updates as the query updates each object individually. Rolling back writes is also difficult: if an update query crashes, the table is in a corrupted state. Second, for large tables with millions of objects, metadata operations are expensive. For example, Parquet files include footers with min/max statistics that can be used to skip reading them in selective queries. Reading such a footer on HDFS might take a few milliseconds, but the latency of cloud object stores is so much higher that these data skipping checks can take longer than the actual query.
从我们与云客户工作的经验来看,这些一致性以及性能方面的问题对企业的数据团队产生了很大的挑战。大多数的企业数据是持续更新的,所以需要原子写的解决方案;多数涉及到用户信息的数据需要表范围的更新以满足GDPR这样的合规要求。即使是内部的数据也需要更新操作来修正错误数据以及集成延迟到达的记录。有趣的是,在Databricks提供云服务最初的几年,我们收到的客户服务支持升级中,约有一半都是由于云存储策略导致的数据损毁,一致性以及性能等方面的问题。(比如,取消更新任务失败造成的影响,或者改进读取上万个对象的查询性能)。
In our experience working with cloud customers, these consistency and performance issues create major challenges for enterprise data teams. Most enterprise datasets are continuously updated, so they require a solution for atomic writes; most datasets about users require table-wide updates to implement privacy policies such as GDPR compliance [27]; and even purely internal datasets may require updates to repair incorrect data, incorporate late records, etc. Anecdotally, in the first few years of Databricks’ cloud service (2014–2016), around half the support escalations we received were due to data corruption, consistency or performance issues due to cloud storage strategies (e.g., undoing the effect of a crashed update job, or improving the performance of a query that reads tens of thousands of objects).
为了解决这些挑战,我们设计了Delta Lake,基于云存储对象的ACID表存储层。Delta Lake从2017年开始服务于客户,并于2019年开源。Delta Lake的核心概念很简单:我们使用存储在云对象中的预写日志,以ACID的方式维护了哪些对象属于Delta table这样的信息。对象本身写在parquet文件中,使已经能够处理Parquet格式的引擎可以方便地开发相应的connectors。这样的设计可以让客户端以序列化的方式一次更新多个对象,替换一些列对象的子集,同时保持与读写parquet文件本身相同的高并发读写性能。日志包含了为每一个数据文件维护的元数据,如min/max 统计信息。相比“对象存储中的文件”这样的方式,元数据搜索相关数据文件速度有了数量级的提升。 最关键的是,我们设计Delta Lake使所有元数据都在底层对象存储中,并且事务是通过针对对象存储的乐观并发协议实现的(具体细节因云厂商而异)。这意味着不需要单独的服务来维护Delta table的状态;用户只需要在运行查询时启动服务器,享受存储计算扩展分离带来的好处。
To address these challenges, we designed Delta Lake, an ACID table storage layer over cloud object stores that we started providing to customers in 2017 and open sourced in 2019 [26]. The core idea of Delta Lake is simple: we maintain information about which objects are part of a Delta table in an ACID manner, using a write-ahead log that is itself stored in the cloud object store. The objects themselves are encoded in Parquet, making it easy to write connectors from engines that can already process Parquet. This design allows clients to update multiple objects at once, replace a subset of the objects with another, etc., in a serializable manner while still achieving high parallel read and write performance from the objects themselves (similar to raw Parquet). The log also contains metadata such as min/max statistics for each data file, enabling order of magnitude faster metadata searches than the “files in object store” approach. Crucially, we designed Delta Lake so that all the metadata is in the underlying object store, and transactions are achieved using optimistic concurrency protocols against the object store (with some details varying by cloud provider). This means that no servers need to be running to maintain state for a Delta table; users only need to launch servers when running queries, and enjoy the benefits of separately scaling compute and storage.
基于这样的事务性设计,我们能够加入在传统云数据湖上无法提供的解决用户痛点的特性,包括:
- Time travel:允许用户查询具体时间点的数据快照或者回滚错误的数据更新。
- Upsert,delete以及merge操作:高效重写相关对象实现对存储数据的更新以及合规工作流(比如GDPR)
- 高效的流I/O:流作业以低延迟将小对象写入表中,然后以事务形式将它们合并到大对象中来提高查询性能。支持快速“tail”读取表中新加入数据,因此作业可以将Delta表作为一个消息队列。
- 缓存:由于Delta表中的对象以及日志是不可变的,集群节点可以安全地将他们缓存在本地存储中。我们在Databricks云服务中利用这个特性为Delta表实现透明的SSD缓存。
- 数据布局优化:我们的云服务包括一个特性,能够在不影响查询的情况下,自动优化表中对象的大小,以及数据记录的聚类(clustering)(将记录存储成Zorder实现多维度的本地化)。
- Schema演进:当表的schema变化时,允许在不重写parquet文件的情况下读取旧的parquet文件。
- 日志审计:基于事务日志的审计功能。
Based on this transactional design, we were also able add multiple other features in Delta Lake that are not available in traditional cloud data lakes to address common customer pain points, including:
- Time travel to let users query point-in-time snapshots or roll back erroneous updates to their data.
- UPSERT, DELETE and MERGE operations, which efficiently rewrite the relevant objects to implement updates to archived data and compliance workflows (e.g., for GDPR [27]).
- Efficient streaming I/O, by letting streaming jobs write small objects into the table at low latency, then transactionally coalescing them into larger objects later for performance. Fast “tailing” reads of the new data added to a table are also supported, so that jobs can treat a Delta table as a message bus.
- Caching: Because the objects in a Delta table and its log are immutable, cluster nodes can safely cache them on local storage. We leverage this in the Databricks cloud service to implement a transparent SSD cache for Delta tables.
- Data layout optimization: Our cloud service includes a feature that automatically optimizes the size of objects in a table and the clustering of data records (e.g., storing records in Zorder to achieve locality along multiple dimensions) without impacting running queries.
- Schema evolution, allowing Delta to continue reading old Parquet files without rewriting them if a table’s schema changes.
- Audit logging based on the transaction log.
这些特性改进了数据在云对象存储上的可管理性和性能,并且结合了数仓和数据湖的关键特性创造了“湖仓”的典范:直接在廉价的对象存储上使用标准的DBMS管理功能。事实上,我们发现很多Databricks的客户希望使用Delta Lake简化他们整体的数据架构,替换之前分离的数据湖,数仓,以及流存储系统,用Delta表来为所有用例提供适用的功能。表格1展示了一个例子,数据管道包括对象存储,消息队列以及为两个不同商业智能服务的数仓(每一个使用独立的计算资源),替换为只包含云存储对象上的Delta表,使用Delta的流I/O以及性能特性来执行ETL和BI。这种新的管道只用到了廉价的对象存储并产生了更少数量的数据备份,在存储和运维方面降低了成本。
Together, these feature improve both the manageability and performance of working with data in cloud object stores, and enable a “lakehouse” paradigm that combines the key features of data warehouses and data lakes: standard DBMS management functions usable directly against low-cost object stores. In fact, we found that many Databricks customers could simplify their overall data architectures with Delta Lake, by replacing previously separate data lake, data warehouse and streaming storage systems with Delta tables that provide appropriate features for all these use cases. Figure 1 shows an extreme example, where a data pipeline that includes object storage, a message queue and two data warehouses for different business intelligence teams (each running their own computing resources) is replaced with just Delta tables on object storage, using Delta’s streaming I/O and performance features to run ETL and BI. The new pipeline uses only low-cost object storage and creates fewer copies of the data, reducing both storage cost and maintenance overheads.
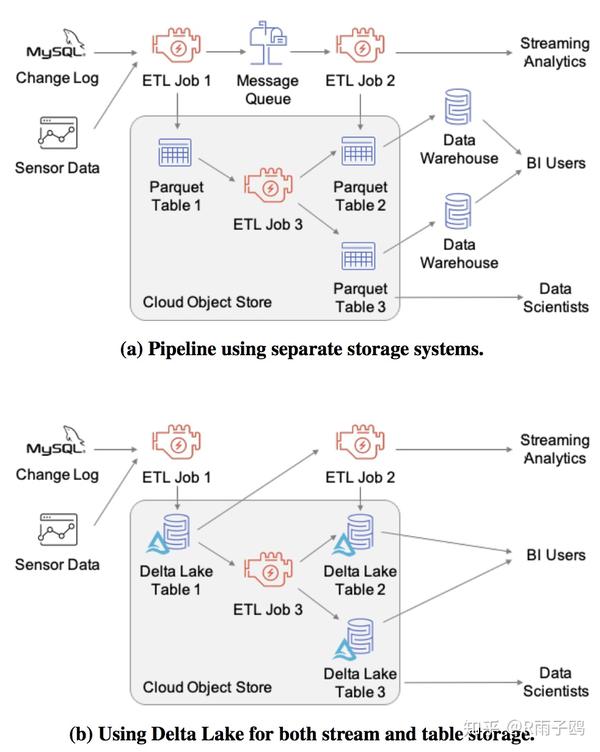

图1: 使用3个存储系统实现的数据pipeline(1个消息队列, 1个对象存储 和 1个数据仓库), 或者使用 Delta Lake去同时实现流和表存储. Delta Lake的实现使得不需要维护多份copy,只需要使用最便宜的对象存储.
Delta Lake目前被大多数Databricks的大客户采用,每天处理exabyte数据(约占我们整体工作需求的一半),其他云厂商如Google Cloud,Alibaba,Tencent,Fivetran,Informatica,Qlik,Talend以及其他产品也支持Delta Lake。在Databricks的客户中,Delta Lake的使用用例非常多样化,从传统的ETL和数仓的工作流,到生物信息学,实时网络安全分析(每天处理数百TB流事件数据),GDPR合规性以及用于机器学习的数据管理(管理数以百万计的图像作为Delta表中的记录而不是S3对象,以获取ACID并提高性能)。我们将在Section 5具体讨论这些使用用例。
Delta Lake is now used by most of Databricks’ large customers, where it processes exabytes of data per day (around half our overall workload). It is also supported by Google Cloud, Alibaba, Tencent, Fivetran, Informatica, Qlik, Talend, and other products [50, 26, 33]. Among Databricks customers, Delta Lake’s use cases are highly diverse, ranging from traditional ETL and data warehousing workloads to bioinformatics, real time network security analysis (on hundreds of TB of streaming event data per day), GDPR compliance, and data management for machine learning (managing millions of images as records in a Delta table rather than S3 objects to get ACID and improved performance). We detail these use cases in Section 5.
有趣的是,Delta Lake将Databricks的云存储相关支持问题比例从一半降为接近于零。Detla Lake为大多数客户改善了负载性能,在某些极端用例下,使用Delta Lake的数据布局以及快速访问统计信息对高维数据集(比如网络安全和生物信息学等场景)查询,甚至可以获得100倍的速度提升。开源的Delta Lake项目包含了Apache Spark(流批), Hive, Presto,AWS Athena,Redshift以及Snowflake的connectors,能够运行在多种云对象存储或者HDFS之上。在本文中,我们将展示Delta Lake的设计初衷,设计理念,用户使用案例以及推动设计的性能测试。
Anecdotally, Delta Lake reduced the fraction of support issues about cloud storage at Databricks from a half to nearly none. It also improved workload performance for most customers, with speedups as high as 100× in extreme cases where its data layout optimizations and fast access to statistics are used to query very high-dimensional datasets (e.g., the network security and bioinformatics use cases). The open source Delta Lake project [26] includes connectors to Apache Spark (batch or streaming), Hive, Presto, AWS Athena, Redshift and Snowflake, and can run over multiple cloud object stores or over HDFS. In the rest of this paper, we present the motivation and design of Delta Lake, along with customer use cases and performance experiments that motivated our design.
2.动机:云对象存储的特点及挑战
本节,我们将对云对象存储的API及性能特点进行描述,以阐述在云对象存储之上为什么高效的表存储非常具有挑战,并介绍一些现有的管理表数据集的方法。
In this section, we describe the API and performance characteristics of cloud object stores to explain why efficient table storage on these systems can be challenging, and sketch existing approaches to manage tabular datasets on them.
2.1 对象存储API
云对象存储,比如Amazon S3,Azure Blob存储,Google云存储,以及OpenStack Swift,都提供了简单但容易扩展的键值存储接口。这些系统允许用户创建桶,每个桶存储多个对象,每个对象都是一个二进制blob,大小可到几TB(比如,在S3上对象最大为5TB),每个对象都由一个字符串作为key来标识。通常的方式是将文件系统的路径作为云对象存储的key。但云对象存储不能像文件系统那样,提供廉价的对“目录”或者对象的重命名操作。云对象存储提供元数据API,比如S3的List操作,根据给定的起始键,列出在某个桶中按键的字典序排序的所有对象。这使得通过发起一个LIST请求,给定一个代表目录前缀的key(比如 warehouse/table1/)能够有效地列出目录下的所有对象。但很可惜的是,元数据的API操作通常很昂贵,比如S3的LIST调用每次只能返回1000个key,每次调用花费几十至上百毫秒,所以当以顺序的方式列出一个有数百万对象的数据集可能需要好几分钟。
Cloud object stores, such as Amazon S3 [4] and Azure Blob Storage [17], Google Cloud Storage [30], and OpenStack Swift [38], offer a simple but easy-to-scale key-value store interface. These systems allow users to create buckets that each store multiple objects, each of which is a binary blob ranging in size up to a few TB (for example, on S3, the limit on object sizes is 5 TB [4]). Each object is identified by a string key. It is common to model keys after file system paths (e.g., warehouse/table1/part1.parquet), but unlike file systems, cloud object stores do not provide cheap renames of objects or of “directories”. Cloud object stores also provide metadata APIs, such as S3’s LIST operation [41], that can generally list the available objects in a bucket by lexicographic order of key, given a start key. This makes it possible to efficiently list the objects in a “directory” if using file-system-style paths, by starting a LIST request at the key that represents that directory prefix (e.g., warehouse/table1/). Unfortunately, these metadata APIs are generally expensive: for example, S3’s LIST only returns up to 1000 keys per call, and each call takes tens to hundreds of milliseconds, so it can take minutes to list a dataset with millions of objects using a sequential implementation.
读取对象时,云对象存储支持字节范围的请求,读取某个大对象的某个字节范围(比如,从10000字节到20000字节)通常是高效的。这样就可以利用对常用值进行聚类的存储格式。
When reading an object, cloud object stores usually support byterange requests, so it is efficient to read just a range within a large object (e.g., bytes 10,000 to 20,000). This makes it possible to leverage storage formats that cluster commonly accessed values.
更新对象通常需要重写整个对象。这些更新需要是原子的,以使读对整个新版本对象或者老版本对象可见。有些系统也支持对象的追加写。
Updating objects usually requires rewriting the whole object at once. These updates can be made atomic, so that readers will either see the new object version or the old one. Some systems also support appends to an object [48].
一些云厂商也在blob存储上实现了分布式文件系统接口,比如Azure的ADLS Gen2与Hadoop的HDFS具有相似的语义(比如目录的原子rename)。然而,Delta Lake解决的许多问题,如小文件问题,对多个目录的原子更新问题即使在分布式系统中也依然存在。事实上,有很多用户是在HDFS上使用Delta Lake。
Some cloud vendors have also implemented distributed filesystem interfaces over blob storage, such as Azure’s ADLS Gen2 [18], which over similar semantics to Hadoop’s HDFS (e.g., directories and atomic renames). Nonetheless, many of the problems that Delta Lake tackles, such as small files [36] and atomic updates across multiple directories, are still present even when using a distributed filesystem—indeed, multiple users run Delta Lake over HDFS.
2.2 一致性属性
如引言中所述,大多数云对象存储对单个key提供最终一致性保证,对跨key不提供一致性保证, 这对包含多对象的数据集管理提出了挑战。特别是当客户端提交了新的对象,其他客户端不能够保证在LIST或者读操作中立即看到这个对象。类似地,对现有对象的更新对其他客户端也不能够立即可见。更严重的是,有些对象存储系统,即使同一客户端执行了写操作也不能够立即读到新对象。
The most popular cloud object stores provide eventual consistency for each key and no consistency guarantees across keys, which creates challenges when managing a dataset that consists of multiple objects, as described in the Introduction. In particular, after a client uploads a new object, other clients are not necessarily guaranteed to see the object in LIST or read operations right away. Likewise, updates to an existing object may not immediately be visible to other clients. Moreover, depending on the object store, even the client doing a write may not immediately see the new objects.
精确的一致性模型因不同的云厂商而异,且相当复杂。举个具体的例子,Amazon S3提供了写后读的一致性,S3的客户端在PUT操作后可以通过GET返回这个对象的内容。一个例外是:如果客户端在PUT之前对不存在的Key先调用了GET,那么后续的GET操作可能由于S3的逆向缓存机制在一段时间内读不到这个对象。S3的LIST操作是最终一致的,这意味着在PUT之后LIST操作可能无法返回新的对象。其他的云对象存储提供更强的一致性保证,但在跨key的情况下仍然无法提供原子性操作。
The exact consistency model differs by cloud provider, and can be fairly complex. As a concrete example, Amazon S3 provides readafter-write consistency for clients that write a new object, meaning that read operations such as S3’s GET will return the object contents after a PUT. However, there is one exception: if the client writing the object issued a GET to the (nonexistent) key before its PUT, then subsequent GETs might not read the object for a period of time, most likely because S3 employs negative caching. Moreover, S3’s LIST operations are always eventually consistent, meaning that a LIST after a PUT might not return the new object [40]. Other cloud object stores offer stronger guarantees [31], but still lack atomic operations across multiple keys.
2.3 性能特点
根据我们的经验,通过对象存储实现高吞吐量需要在大型顺序I / O和并行性之间取得平衡。
In our experience, achieving high throughput with object stores requires a careful balance of large sequential I/Os and parallelism.
对于读取,如前所述,最小粒度的操作是读取连续字节范围。 每个读取操作通常会有至少5–10 ms的延迟,然后以大约50–100 MB / s的速度读取数据,因此,一个操作需要读取至少数百KB,才能达到顺序读取的峰值吞吐量的一半;读取数MB才能以接近峰值吞吐量。 此外,在典型的VM配置上,应用程序需要并行运行多个读取以最大化吞吐量。 例如,在AWS上最常用于分析的VM类型具有至少10 Gbps的网络带宽,因此它们需要并行运行8-10次读取才能充分利用此带宽。
For reads, the most granular operation available is reading a sequential byte range, as described earlier. Each read operation usually incurs at least 5–10 ms of base latency, and can then read data at roughly 50–100 MB/s, so an operation needs to read at least several hundred kilobytes to achieve at least half the peak throughput for sequential reads, and multiple megabytes to approach the peak throughput. Moreover, on typical VM configurations, applications need to run multiple reads in parallel to maximize throughput. For example, the VM types most frequently used for analytics on AWS have at least 10 Gbps network bandwidth, so they need to run 8–10 reads in parallel to fully utilize this bandwidth.
LIST操作也需要高并行度才能快速列出大数量的对象。比如S3的LIST操作每个请求只能返回1000个对象,耗时十到数百毫秒,因此客户端对大桶或者目录进行list时需要并行发出上百个LIST请求。在针对云上Apache Spark的优化运行时中,除了在Spark集群的driver节点中并行执行线程外,有时我们还会在worker节点上并行执行LIST操作以使它们更快地运行。 在Delta Lake中,可用对象的元数据(包括它们的名称和数据统计信息)是存储在Delta日志中的,我们也会并行从该日志中读取数据。
LIST operations also require significant parallelism to quickly list large sets of objects. For example, S3’s LIST operations can only return up to 1000 objects per requests, and take tens to hundreds of milliseconds, so clients need to issue hundreds of LISTs in parallel to list large buckets or “directories”. In our optimized runtime for Apache Spark in the cloud, we sometimes parallelize LIST operations over the worker nodes in the Spark cluster in addition to threads in the driver node to have them run faster. In Delta Lake, the metadata about available objects (including their names and data statistics) is stored in the Delta log instead, but we also parallelize reads from this log over the cluster.
如2.1节所述,写操作通常要求必须重写整个对象(或者追加),这意味着如果一张表期望得到点更新,那么对象文件必须小一些,这与大量读对文件大小的要求是矛盾的。一种替代方案是使用日志结构的存储格式。
Write operations generally have to replace a whole object (or append to it), as discussed in Section 2.1. This implies that if a table is expected to receive point updates, then the objects in it should be kept small, which is at odds with supporting large reads. Alternatively, one can use a log-structured storage format.
表存储的含义。 对于分析型工作负载,对象存储的性能特征引出的三点考虑:
- 将需要经常访问的数据就近连续存储,这通常要求选择列存储格式。
- 使对象较大,但不能过大。 大对象增加了更新数据的成本(例如,删除某个用户的所有数据),因为需要全部重写。
- 避免使用LIST操作,并在可能的情况下按字典顺序的键范围发送请求。
Implications for Table Storage. The performance characteristics of object stores lead to three considerations for analytical workloads:
- Keep frequently accessed data close-by sequentially, which generally leads to choosing columnar formats.
- Make objects large, but not too large. Large objects increase the cost of updating data (e.g., deleting all data about one user) because they must be fully rewritten.
- Avoid LIST operations, and make these operations request lexicographic key ranges when possible.
2.4 现有的表存储方法
基于对象存储的特征,目前主要有三种方法在对象存储之上管理表格数据集。 我们将简述这些方法及其面临的挑战。
Based on the characteristics of object stores, three major approces are used to manage tabular datasets on them today. We briefly sketch these approaches and their challenges.
1.目录文件 目前开源大数据技术栈以及云服务支持的最通用的方式是将表存储为对象集合,通常采用列存,比如Parquet。作为一种改进,可以基于一个或多个属性将记录“分区”到目录中。 例如,对于具有日期字段的表,我们可以为每个日期创建一个单独的对象目录,例如,mytable / date = 2020-01-01 / obj1 以及mytable / date = 2020-01-01 / obj2用于记录从1月1日的数据,mytable / date = 2020-01-02 / obj1,1月2日的数据,依此类推,然后根据该字段将传入的数据拆分为多个对象。 这样的分区减少了LIST操作以及仅访问某几个分区的查询读操作的成本。
1. Directories of Files. The most common approach, supported by the open source big data stack as well as many cloud services, is to store the table as a collection of objects, typically in a columnar format such as Parquet. As a refinement, the records may be “partitioned” into directories based on one or more attributes. For example, for a table with a date field, we might create a separate directory of objects for each date, e.g., mytable/date=2020-01-01/obj1 and mytable/date=2020-01-01/obj2 for data from Jan 1 st , then mytable/date=2020-01-02/obj1 for Jan 2 nd , etc, and split incoming data into multiple objects based on this field. Such partitioning reduces the cost of LIST operations and reads for queries that only access a few partitions.
这种方式具有吸引力是因为整个表仅由一些对象组成,可以通过许多工具访问 而无需运行任何其他数据存储或系统。这种方式起源于HDFS之上的Apache Hive,并且与Parquet,Hive和文件系统上的其他大数据软件配合使用。
This approach is attractive because the table is “just a bunch of objects” that can be accessed from many tools without running any additional data stores or systems. It originated in Apache Hive on HDFS [45] and matches working with Parquet, Hive and other big data software on filesystems.
如引言中所述,这种方式的挑战是 “一堆文件”在云对象存储上有性能和一致性方面的问题。 客户遇到的最常见挑战是:
- 跨多个对象没有原子性:任何需要写入或更新多个对象的事务都可能导致其他客户端只可见部分写入。 此外,如果事务失败,数据将处于损坏状态。
- 最终一致性:即使事务成功,客户端也有可能只看到部分更新对象。
- 性能差:查找与查询相关对象时的LIST操作很昂贵,即使它们被键划分到分区目录中。 此外,访问存储在Parquet或ORC文件中的对象统计信息很昂贵,因为它需要对每个文件的统计信息进行额外的高延迟读取。
- 没有管理功能:对象存储没有实现数据仓库中常用的标准工具,例如表版本控制或审核日志。
Challenges with this Approach. As described in the Introduction, the “just a bunch of files” approach suffers from both performance and consistency problems on cloud object stores. The most common challenges customers encountered are:
- No atomicity across multiple objects: Any transaction that needs to write or update multiple objects risks having partial writes visible to other clients. Moreover, if such a transaction fails, data is left in a corrupt state.
- Eventual consistency: Even with successful transactions, clients may see some of the updated objects but not others.
- Poor performance: Listing objects to find the ones relevant for a query is expensive, even if they are partitioned into directories by a key. Moreover, accessing per-object statistics stored in Parquet or ORC files is expensive because it requires additional high-latency reads for each feature.
- No management functionality: The object store does not implement standard utilities such as table versioning or audit logs that are familiar from data warehouses.
2. 自定义存储引擎 . 为云构建的“闭源”存储引擎,例如Snowake数据仓库[23],可以通过在单独的,强一致性的服务中管理元数据来绕过云对象存储的许多一致性挑战。 这种服务保存着哪些对象构成了表这样的事实。 在这些引擎中,可以将云对象存储视为笨拙的块设备,并且可以使用标准技术在云对象上实现有效的元数据存储,搜索,更新等。 但是,此方法需要运行一个高可用服务来管理元数据,这可能很昂贵,在使用外部计算引擎查询数据时可能会增加成本,而且有可能将用户锁定在某个特定厂商。
2. Custom Storage Engines. “Closed-world” storage engines built for the cloud, such as the Snowflake data warehouse [23], can bypass many of the consistency challenges with cloud object stores by managing metadata themselves in a separate, strongly consistent service, which holds the “source of truth” about what objects comprise a table. In these engines, the cloud object store can be treated as a dumb block device and standard techniques can be used to implement efficient metadata storage, search, updates, etc. over the cloud objects. However, this approach requires running a highly available service to manage the metadata, which can be expensive, can add overhead when querying the data with an external computing engine, and can lock users into one provider.
这种方式的挑战:尽管这种从头开始的“闭源”设计是有好处的,但使用这种方法遇到的一些具体挑战是:
- 所有对表的I / O操作都需要连接元数据服务,增加了资源成本并降低了性能和可用性。 例如,当用Spark访问Snow flake数据集时,使用Snow flake的Spark connector通过Snow service的服务读取数据,与直接从云对象存储中读取数据相比性能下降。
- 与重用现有开放格式(例如Parquet)的方法相比,开发现有计算引擎的connector需要更多的工作量。 根据我们的经验,数据团队希望在数据上使用多种计算引擎(例如Spark,TensorFlow,PyTorch等),因此使connector易于实现非常重要。
- 专有的元数据服务将用户与特定厂商绑定,相比之下,基于直接访问云存储的方式使用户总是能够使用各种技术访问他们的数据。
Challenges with this Approach. Despite the benefits of a clean-slate “closed-world” design, some specific challenges we encountered with this approach are:
- All I/O operations to a table need contact the metadata service, which can increase its resource cost and reduce performance and availability. For example, when accessing a Snowflake dataset in Spark, the reads from Snowflake’s Spark connector stream data through Snowflake’s services, reducing performance compared to direct reads from cloud object stores.
- Connectors to existing computing engines require more engineering work to implement than an approach that reuses existing open formats such as Parquet. In our experience, data teams wish to use a wide range of computing engines on their data (e.g. Spark, TensorFlow, PyTorch and others), so making connectors easy to implement is important.
- The proprietary metadata service ties users to a specific service provider, whereas an approach based on directly accessing objects in cloud storage enables users to always access their data using different technologies.
Apache Hive ACID 也是一种基于HDFS或对象存储的存储实现, 使用Hive Metastore(一种事务性关系型数据库,例如MySQL)跟踪每张表相关的更新,更新以多个文件的形式存储在表的元数据信息中,一般为ORC格式。 但是,这种方法受限于metastore的性能,根据我们的经验,它可能成为具有数百万个对象的表的瓶颈。
Apache Hive ACID [32] implements a similar approach over HDFS or object stores by using the Hive Metastore (a transactional RDBMS such as MySQL) to keep track of multiple files that hold updates for a table stored in ORC format. However, this approach is limited by the performance of the metastore, which can become a bottleneck for tables with millions of objects in our experience.
3.在对象存储中保存元数据 Delta Lake的方法是将事务日志和元数据直接存储在云对象存储中,并在对象存储操作上使用一组协议来实现可序列化。 表中的数据以Parquet格式存储,只要实现一个最基本的connector去发现要读取的对象集,就可以使用任何已经支持Parquet的软件访问数据。 尽管我们认为Delta Lake是第一个使用该设计的系统(从2016年开始),但现在另外两个软件Apache Hudi 和Apache Iceberg 也支持这种方式。 Delta Lake提供了一系列这些系统不支持的独特功能,例如Z序聚类,缓存和后台优化。 我们将在Section 8中详细讨论这些系统之间的异同。
3. Metadata in Object Stores. Delta Lake’s approach is to store a transaction log and metadata directly within the cloud object store, and use a set of protocols over object store operations to achieve serializability. The data within a table is then stored in Parquet format, making it easy to access from any software that already supports Parquet as long as a minimal connector is available to discover the set of objects to read. 1 Although we believe that Delta Lake was the first system to use this design (starting in 2016), two other software packages also support it now — Apache Hudi [8] and Apache Iceberg [10]. Delta Lake offers a number of unique features not supported by these systems, such as Z-order clustering, caching, and background optimization. We discuss the similarities and differences between these systems in more detail in Section 8.
翻译论文 Delta Lake:基于云对象存储的高性能ACID表存储格式(一)
翻译论文 Delta Lake:基于云对象存储的高性能ACID表存储格式(二)
翻译论文 Delta Lake:基于云对象存储的高性能ACID表存储格式(四)
