


使用Huginn自动化抓取大学学院通知

我真的爱发明

深度学习 代码搬用工
前言
- Huginn对于js的动态页面抓取,需要借助一些第三方的工具,我们的helloworld不考虑那种难度的页面,我们考虑一些静态页面,比如一些学院的官网通知之类的,这里就以清华大学计算机学院的通知为例进行抓取展示,其他类型的通知抓取方法类似。
- 通知公告-清华大学计算机科学与技术系
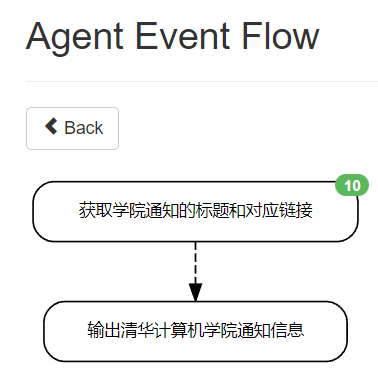
总体流程图
- 新建一个任务组Scenario,然后在Scenario下面再新建两个对应的Agent(一个获取信息,一个输出RSS信息)即可
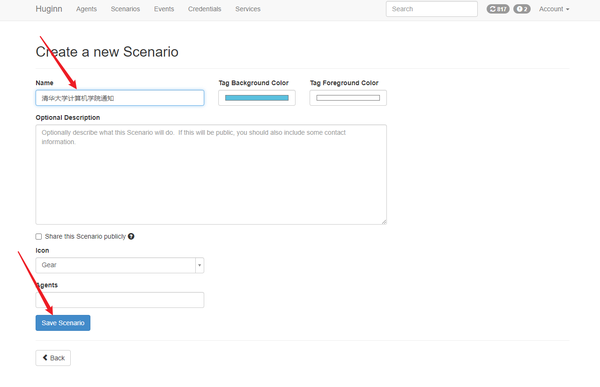
- 输入对应任务组的标题和描述,这里这个icon可以设置对应的皮肤,我这里使用默认的齿轮gear了
- 配置参数
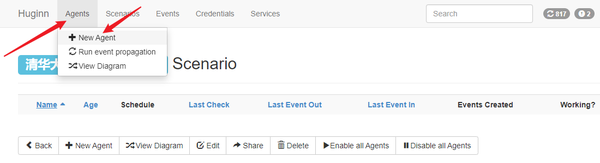
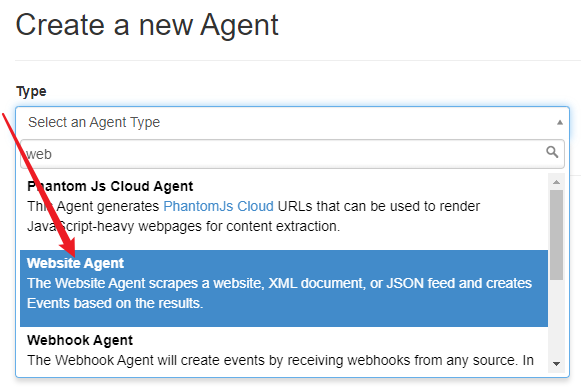
- 初始化已经有一些Agents,你可以从里中学习到一些使用方法。点击+ New Agent添加第一个Agent,Type选择 Website Agent 。
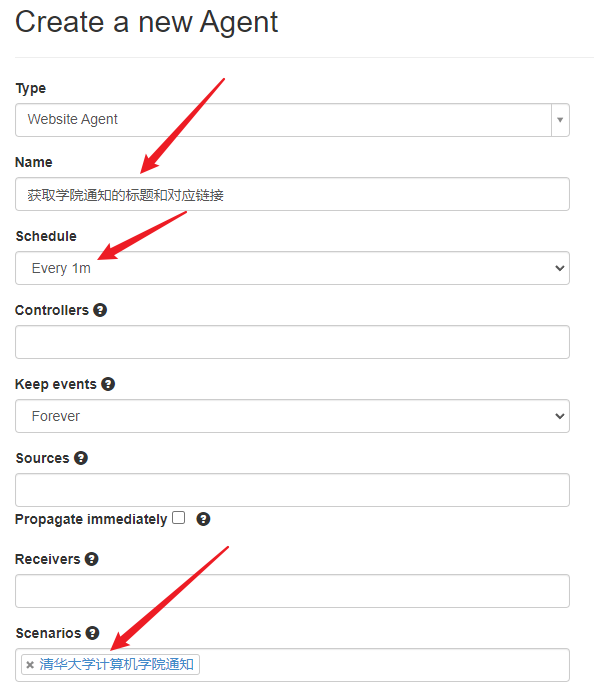
- Name框 输入名称 , Schedule 下拉框选择执行的 间隔时间 , Scenarios 选择自己刚才创建的任务组,其他 默认 即可。
- Options参数最为关键,右侧都有英文说明的,字段简要说明如下:
- url : 网址链接 ,填写需要抓取的通知页面网址
- type :返回的 数据类型 ,支持xml,、html、json、text,此处默认填写 html
- mode : 抓取模式 ,可选all, on_change, merge,这里填写 on_change ,表示页面有变化才会抓取
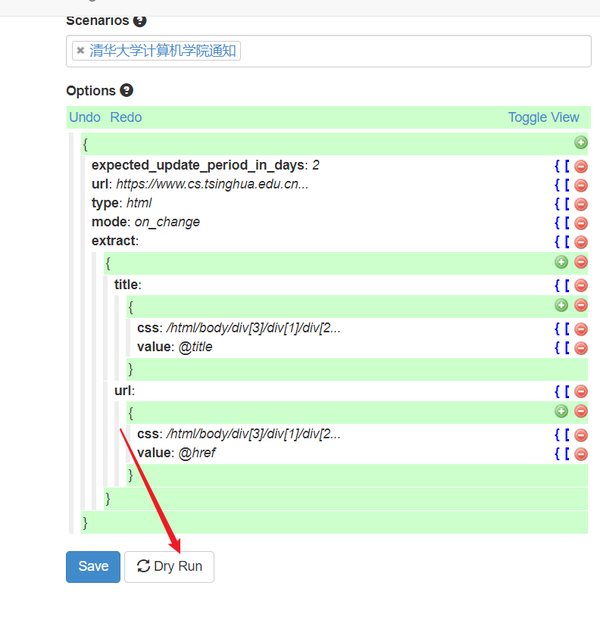
- extra :表示 抓取规则 ,这是这个配置文件中最重要的一个参数或者代码
- url和title表示 抓取字段 的 名称 ,可 随意命名 ;(后面用得着, 作为参数 传给其他 Agent )
- css表示 抓取内容 的 css路径 ,value表示抓取的值,@href表示抓取对应css标签的href属性值,还有@src,@title等等;
- 如果要抓取对应标签的值,可填.(包括html代码的全部内容),string(.)(只包含对应标签的值),text()等同string(.)
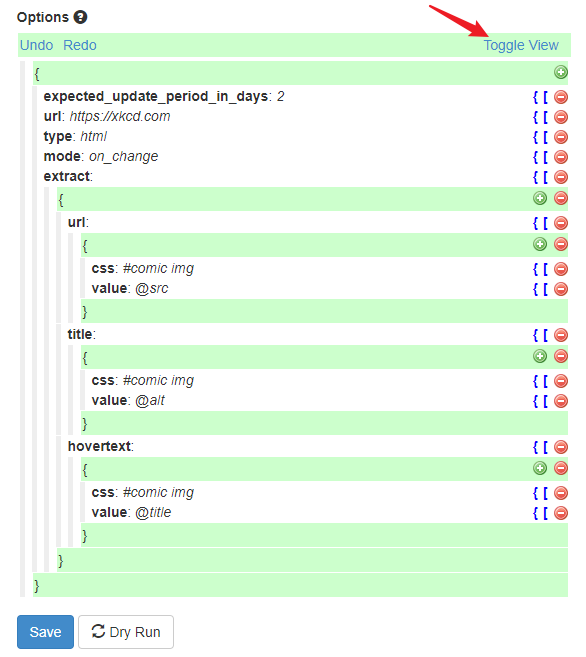
- 点击Toggle View进行编辑
- extract内容。主要就是 标题 、 链接 、 内容 和时间等,我们只需要填写相关内容的 Xpath路径
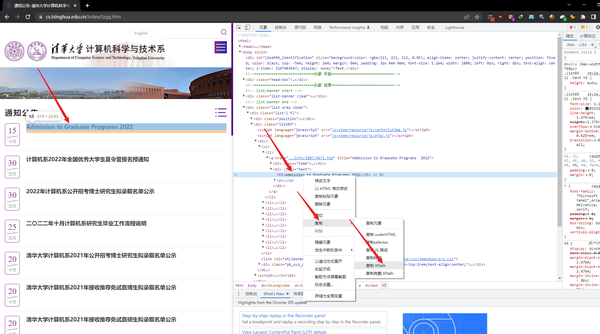
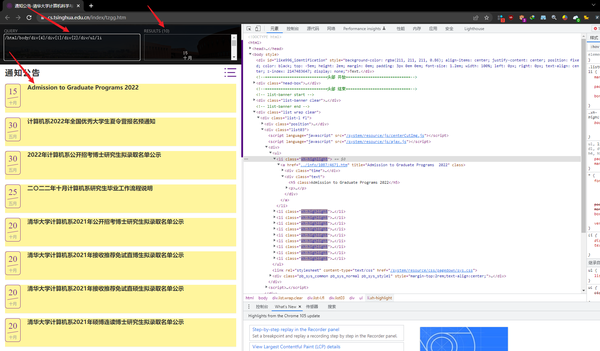
- 关于获取网页的Xpath的方法,直接使用火狐浏览器 (这里有个坑,是其他教程上都没有提到的,就是应该使用 火狐浏览器 而非谷歌浏览器,来抓取这个Xpath,这样更不容易出错),右击我们要获取的内容,然后选择“ 审查元素 ”,再到控制面板右击,选择复制 Xpath 。例如清华大学计算机学院通知的最新文章的url的Xpath是:/html/body/div[4]/div[1]/div[2]/div/ul/li[1]/a/div[2]/h5。
- 另外,由于我们获取到的 Xpath 往往是 某一个具体的元素的 ,想要匹配 所有的符合要求的元素 ,
- 例如我们获取一般是:/html/body/div[3]/div[1]/div[2]/div/ul/li[1]/a,我们将最后一个元素li的编号去掉,变为/html/body/div[3]/div[1]/div[2]/div/ul/li/a,于是就匹配了所有的最新文章链接地址了。
- 其它的标题、内容、时间等都可以参考上面的方法获取到。
- 预览
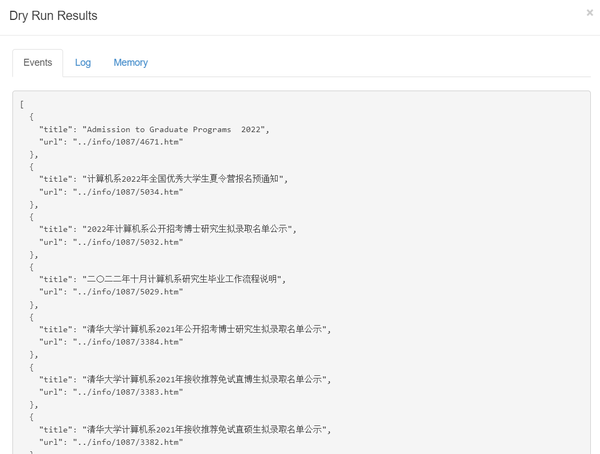
- 完成上面的配置之后,点击“Dry Run”,你就可以预览抓取结果了。注意到“事件”中看到抓取了结果,就表示该Website Agent设置成功了。
- 如图已经可以看到抓取到的标题和URL了,只不过这个URL不完整,我们后面再进行拼接处理一下
- 自己所使用的extract代码,可以直接粘贴进去
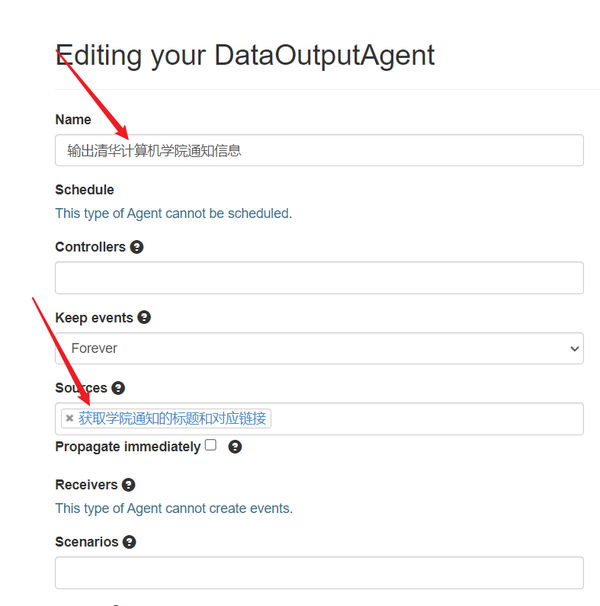
- 新建一个Data Output Agent,Data Output Agent可以将上一步agent获得的events输出为RSS和JSON(我们一般使用RSS的信息),
- Name:输入对应的Agent名称,这个就根据自己的命名喜好来输入了,我这里输入的是“输出清华计算机学院通知信息”,
- Sources:源的话就接上一步获得的Agent
- Scenarios:选择清华大学计算机学通知那个任务组(具体根据你之前的命名来)
- 每一条信息一共输出title、description、link、guid、pubDate五个字段,其中title和link是必须的
- 这里的语法是用{{}}把上一个agent得到的变量括起来进行输出,需要注意的是之前获得的每一条通知的链接是 ../info/1087/3380.htm 这种类型的,不是完整的网址,所以我们在这里需要对它进行如下的网址组合
-
https://www.
cs.tsinghua.edu.cn/
{{url}}
- 可以参考下面的填法和代码
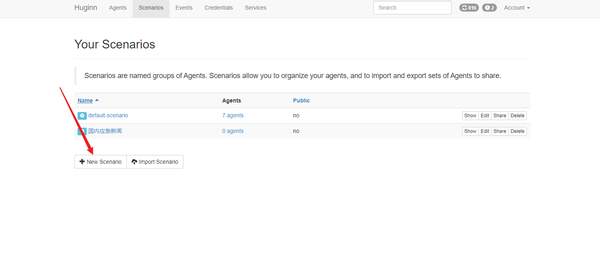
新建一个任务组Scenario
新建第一个Agent,获得 标题 和对应链接
{
"expected_update_period_in_days": "2",
"url": "https://www.cs.tsinghua.edu.cn/index/tzgg.htm",
"type": "html",
"mode": "on_change",
"extract": {
"title": {
"css": "/html/body/div[3]/div[1]/div[2]/div/ul/li/a",
"value": "@title"
"url": {
"css": "/html/body/div[3]/div[1]/div[2]/div/ul/li/a",
"value": "@href"
}
新建第二个Agent,将抓取到的内容输出为RSS
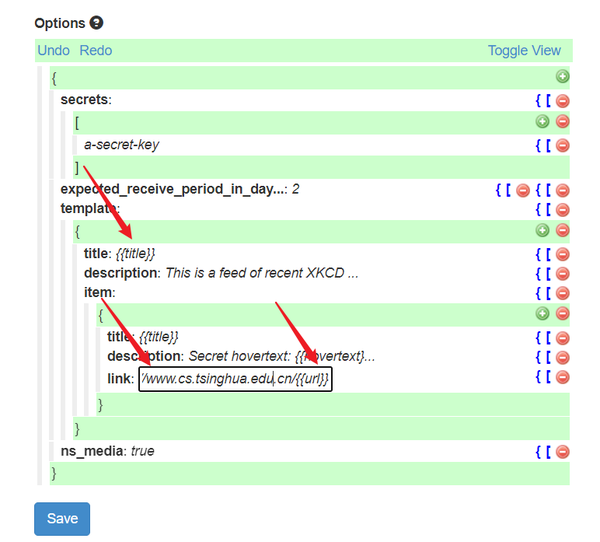
{
"secrets": [
"a-secret-key"
"expected_receive_period_in_days": 2,
"template": {
"title": "{{title}}",
"description": "This is a feed of recent XKCD comics, generated by Huginn",
"item": {
"title": "{{title}}",
"description": "Secret hovertext: {{hovertext}}",