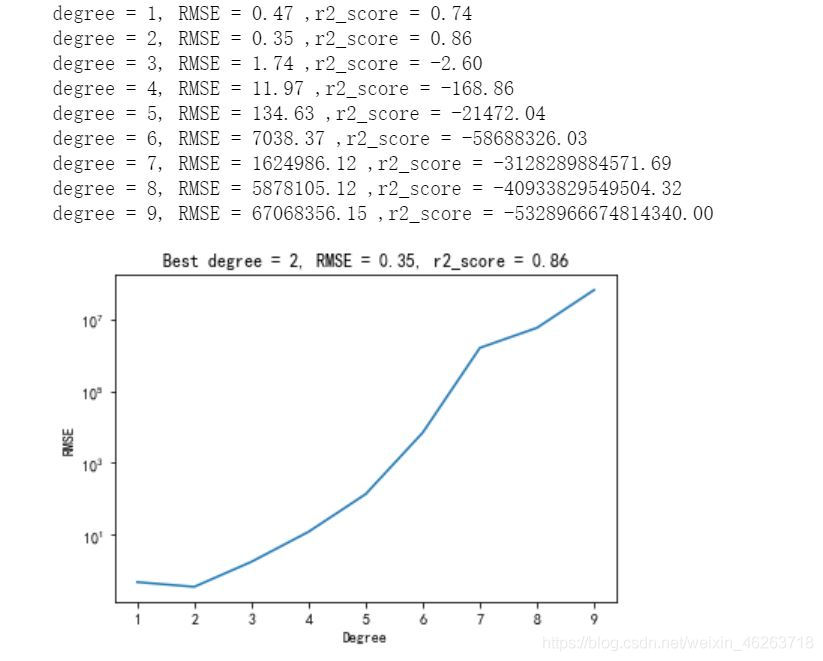
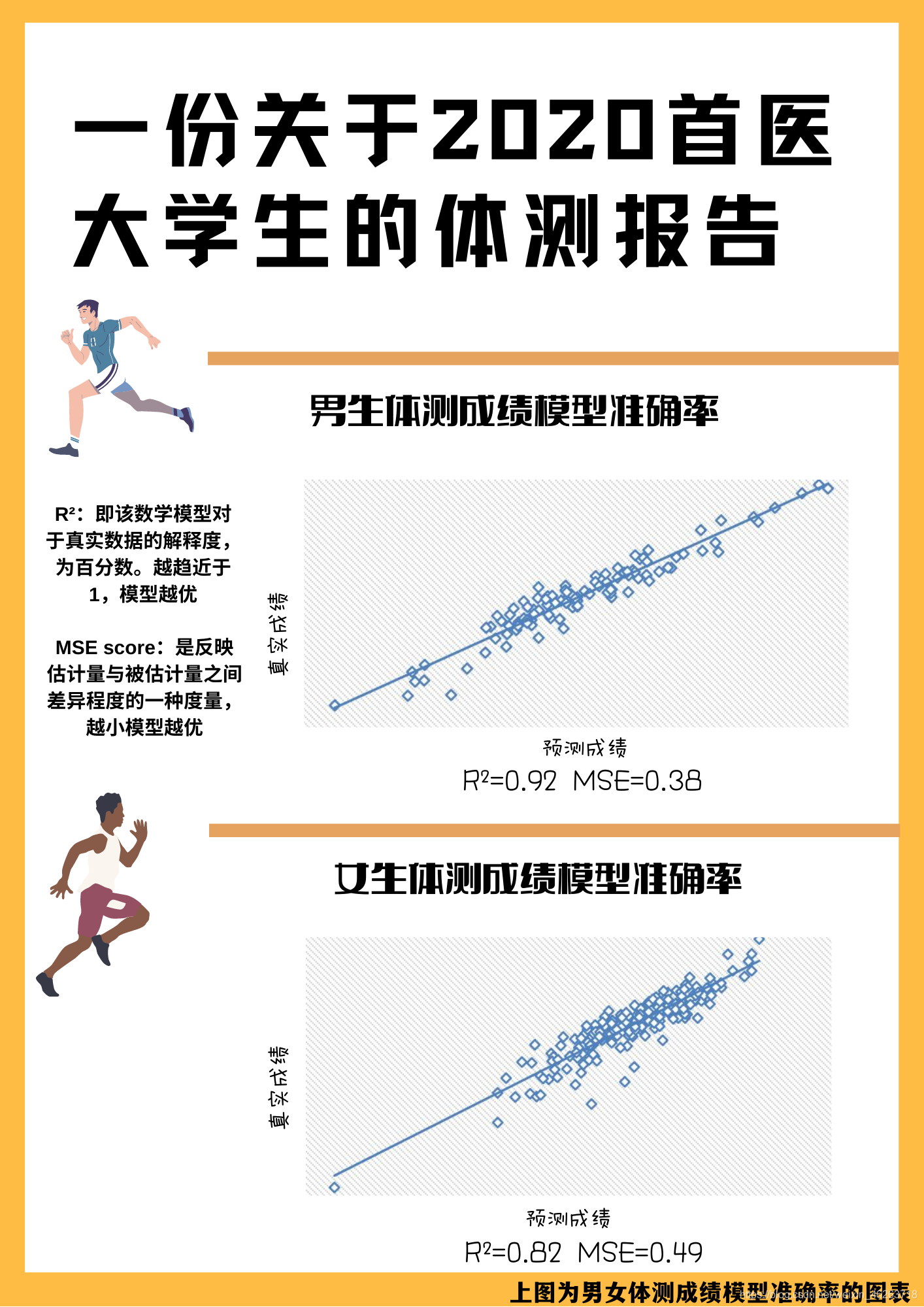
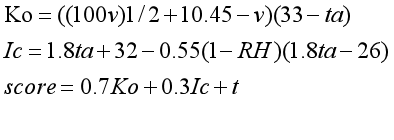在建立了完整的天气影响模型之后我们首先找到了男女生体测的最适天气因素(总成绩最高的)
#得到最适三个参数(对总成绩影响最小)
#ta 空气温度 RH相对湿度 v风速
x_poly = poly_reg.fit_transform(yd_df_)
y_pred = model.predict(x_poly)
par_best=[]
y_best=[]
for i in range(len(y_pred)):
if y_pred[i]==y_pred.max():
x_v_i=v_list[i]
x_RH_i=RH_list[i]
x_ta_i=ta_list[i]
par_best.append([x_v_i,x_RH_i,x_ta_i])
y_best.append(y[i])
par_best#得到最适三个参数(对800成绩影响最小)
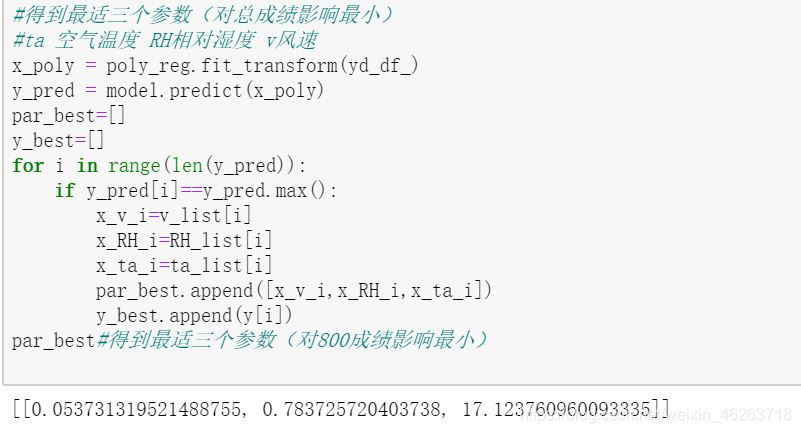
从这里我们看出最适天气因素是无风,凉爽的天气,这也符合我们的普适认知。
随后我们统计了在0~3级微风,4-5级和风,5-6级劲风的天气条件下在这1000次随机试验中长跑平均多花的时间。通过调整蒙特卡洛模拟中温度、湿度,风速等随机取样的范围实现。
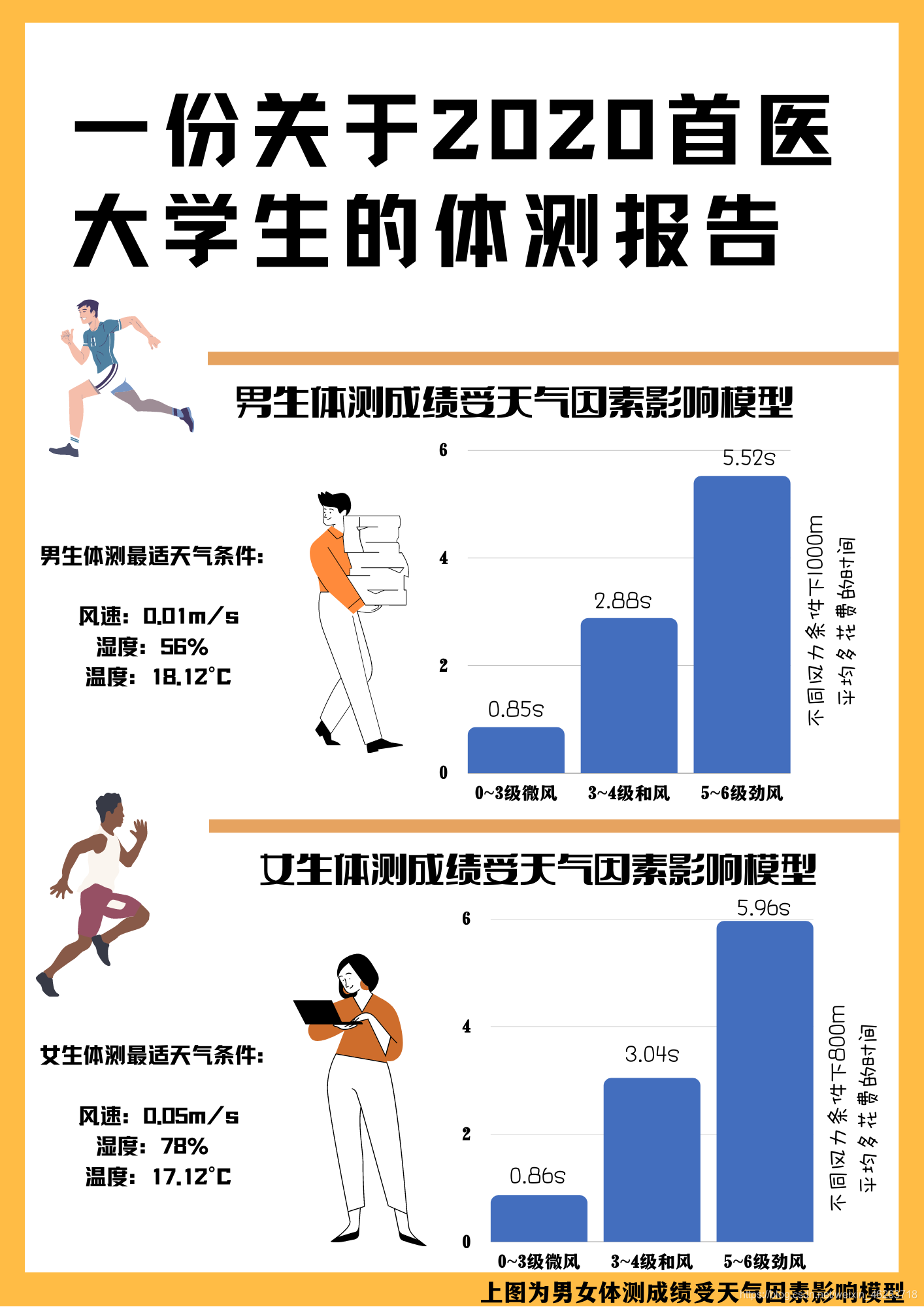
结论:我们发现和大多数人想的一样,适宜跑步的天气是凉爽湿润且无风的好天气,在这种天气体测身心愉悦,可以发挥得更好。
而相比较而言的大风天也是真的很夺命,大风给长跑带来的不仅仅是在跑步的我们的生理上的痛苦,还有成绩上的下滑!
但是大家可以松一口气的是,基于我们的模型而言,大风对于长跑的影响是在6s以内的,所以大风并不能阻挡任何人奔向体测的及格线,只不过就是会比平常更加的难受罢了。
喜欢这篇数学建模案例的话,欢迎关注我们和我们一起交流!
奇趣多多,数模多多!

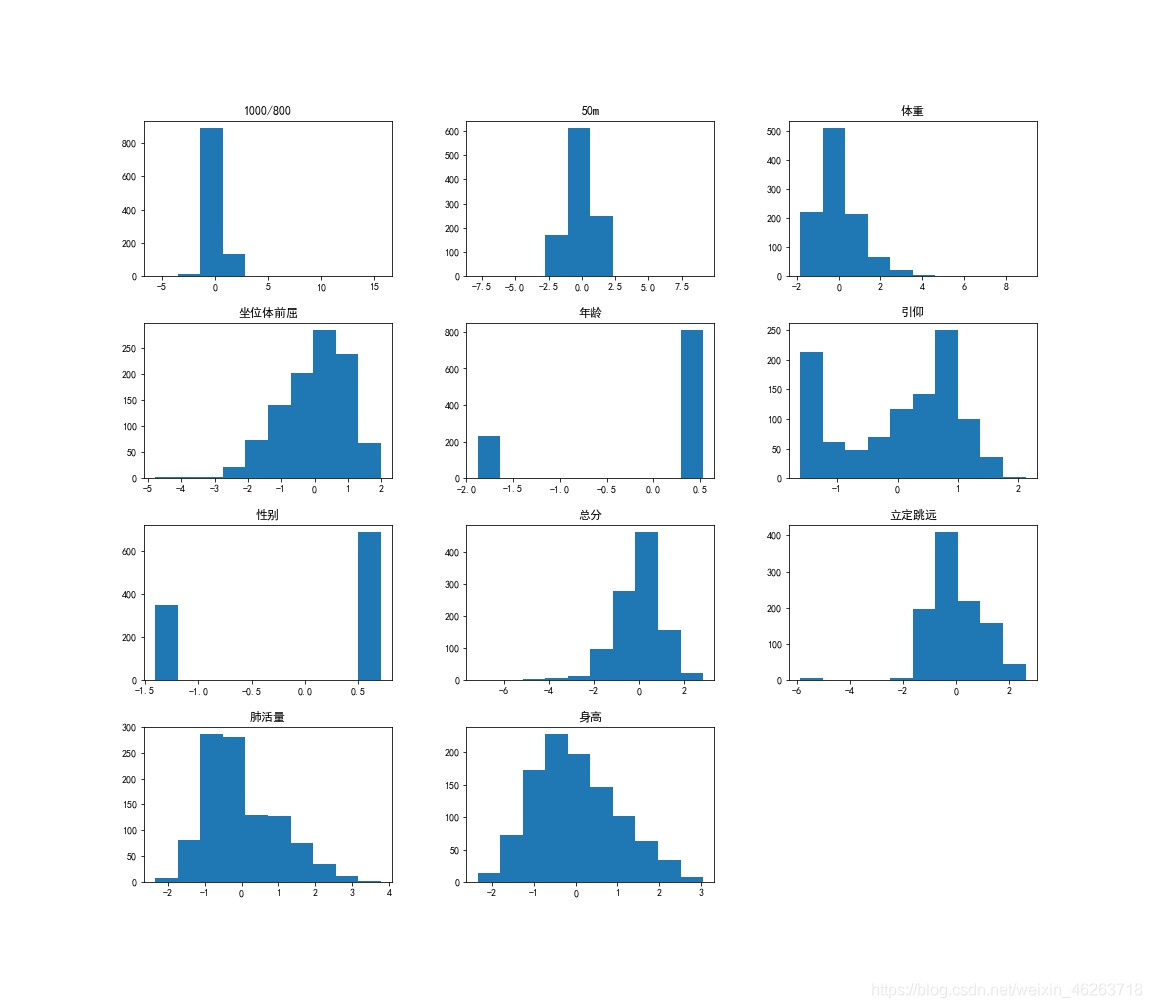
数学建模预测模型实例–大学生体测数据模型建立模型的目的本篇文章中,假设获取到了某大学两个年级共1000人的大学生体质健康测试的每项测试成绩及总分,测试项目包括:身高,体重,肺活量,50m,1000/800,引体向上/仰卧起坐,坐位体前屈。目的是通过前期数据挖掘探索性数据分析等建立大学生体测成绩预测模型,进而在模型里添加天气(温度、湿度、风速)影响因子,模拟得出天气因素对于体测成绩的具体影响程度。数据分析基本过程包括:获取数据、数据清洗、构建模型、数据可视化以及天气影响下的体测成绩的变化趋势的分析。数
数学建模是对现实世界的特定对象,为了特定的目的,根据特有的内在规律,对其
进行必要的抽象、归纳、假设和简化,运用适当的数学工具建立的一个数学结构。数学
建模就是运用数学的思想方法、数学的语言去近似地刻画一个实际研究对象,构建一座
沟通现实世界与数学世界的桥梁,并以计算机为工具应用现代计算技术达到解决各种实
际问题的目的。建立一个数学模型的全过程称为数学建模。因此“数学建模”(或数学
实验)课程教学对于开发学生的创新意识,提升人的数学素养,培养学生创造性地应用
数学工具解决实际问题的能力,有着独特的功能
MATLAB—常用
数学建模算法大全(26种):理论介绍+源代码+
实例分析
1. 全国
大学生数学建模比赛介绍及其入门(国赛+美赛)
2. 使用MATLAB进行灰色预测 GM(1,1)
3. 使用MATLAB进行多元线性回归预测
4. 使用MATLAB进行BP神经网络数值预测
5. MATLAB-自定义函数拟合(lsqcurvefit)
6. MATLAB: 0-1规划(背包问题)
7. MATLAB-线性规划求最优解
8. MATLAB-随机森林实现数据回归分析预测
9. MATLAB-GM(1,N)灰色
预测模型的建立
10. MATLAB-偏最小二乘回归分析
11. MATLAB-基于灰色神经网络的预测算法研究(订单需求预测)
12. MATLAB-遗传算法-求解多元非线性规划问题
13. MATLAB-综合评价与决策(
数学建模)
14. MATLAB-模拟退火算法
15. MATLAB-主成分分析法CCC
16. MATLAB-多目标线性规划问题
17. MATLAB-熵权法
由于字数限制,其它算法见压缩包。
毕业设计基于VUE的学生体测管理系统项目源码,也可作为期末大作业。
老师 ry admin123 刘三国 123456 管理员 manager 123456 学生 20220102 123456
使用教程如下:
# 进入项目目录
cd ruoyi-ui
# 安装依赖
npm install
# 建议不要直接使用 cnpm 安装依赖,会有各种诡异的 bug。可以通过如下操作解决 npm 下载速度慢的问题
npm install --registry=https://registry.npm.taobao.org
# 启动服务
npm run dev
浏览器访问 ..
# 构建测试环境
npm run build:stage
# 构建生产环境
npm run build:prod
【内容简介】
本书将应用数学的基本理论、
实例、应用数学软件有机地结合成一体,既简要介绍一些最常用的解决实际问题的应用数学知识,又联系实际介绍应用相应的数学知识建立数学模型,并用合适的数学软件包来求解模型在大多数章的最后一节。结合相应知识和软件包介绍一个大型的
数学建模案例,这些案例主要取材于最近几年全国
大学生数学建模竞赛题.
第1章 线性规划
1.1 线性规划模型
1.2 单纯型算法
1.3 对偶单纯型算法
1.4 灵敏度分析及影子价格
1.5 用MATLAB优化工具箱解线性规划
1.6 习题
第2章 整数线性规划
2.1 割平面法
2.2 分枝定界法
2.3 习题
第3章 无约束优化
3.1 数学预备知识
3.2 无约束最优化问题的解
3. 3 用MATLAB优化工具箱解无约束最优化
3.4 习题
第4章 非线性规划
4.1 非线性规划的数学模型 等等
双色球概率预测模型
最近新晋彩民佩瑞对于双色球产生了极为浓厚的兴趣,在买过几注随机号码中奖无果后,决心潜心修炼,钻研一个比较靠谱的预测方法!所以有了这篇文章,文章思路及结果仅供娱乐,请勿当真!
在产生这个想法之后我首先查阅了网络上各种各样的双色球预测模型,发现了几类具有代表性的:
1.基于神经网络的回归预测模型
2.基于LSTM的预测模型
3.基于深度学习的预测模型
看到这三种预测模型是不是觉得很高深,没错!我也是这样的感觉!所以我又开始了新一轮的资料搜索,这次去详细的了解了一下有关双色球的