|
|
|


重要
算法实验功能仅对标准版实例开放。
智能推荐根据不同的行业提供了归档的如下几类算法模型,您可以通过在线实验平台的实验参数配置针对性的进行开启或关闭以及具体算法子类型的优化。
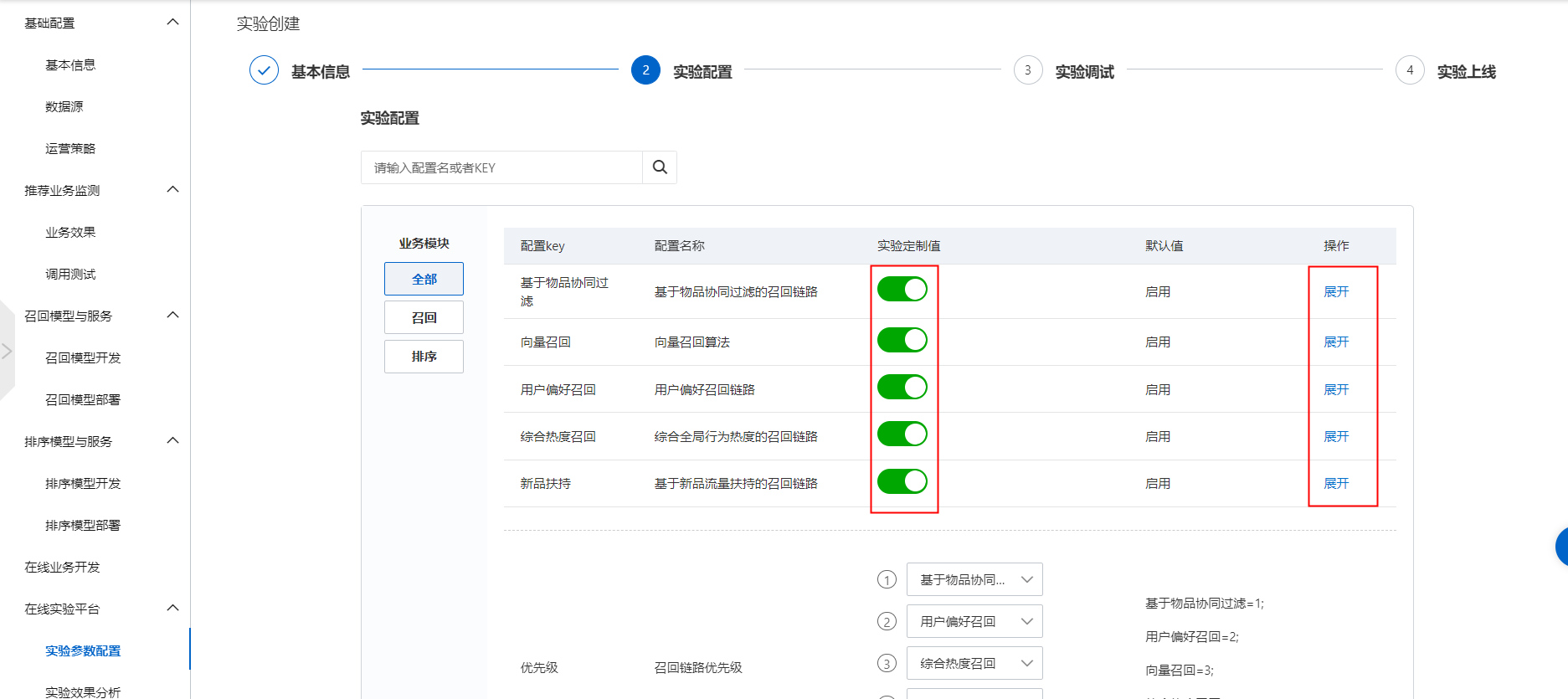
一、基于物品的协同过滤算法
协同过滤算法主要分为基于物品的协同过滤算法、基于用户的协同过滤算法。
目前智能推荐在协同过滤链路中主要以基于物品的协同过滤算法为主。
基于物品的协同过滤算法实现步骤:
-
计算物品之间的相似度。
-
根据物品的相似度和用户的历史行为记录给用户生成推荐列表。
各类协同过滤召回链路
基准基于物品协同过滤
基于传统CF协同过滤的协同过滤算法,是一种基于关联规则的算法。
相对于swing,除了找相似,找同款之外,多关注一些发现性、物品的多样性。
例如,当用户反馈在首页推荐中看到的物品种类比较少的时候,可以考虑适当提升此召回链路的优先级。
swing
即基于Swing的i2i算法,Swing是一种基于图结构计算商品相似度的算法, 以高维的网络结构向二跳节点扩展,抗噪能力强,相比传统的CF准确性有较大的提升。
相对于基准基于物品协同过滤更聚焦于找相似、找同款,更关注相关性,但计算复杂度更高 。
子类目收敛优化
限制叶子类目的传统CF协同过滤的i2i算法,即只召回和当前trigger item叶子类目一致的相似物品。
在基于物品协同过滤的基础上增加了叶子类目的限制,更突出和之前行为例如点击物品的叶子类目一致性。
例如用户点了口红之后,希望下一次请求实时推荐口红,适用该链路。
父类目收敛优化
限制一级类目的传统CF协同过滤的i2i算法,即只召回和当前trigger item一级类目一致的相似物品。
在基于物品协同过滤的基础上增加了一级类目的限制,更突出和之前行为例如点击物品的一级类目一致性。
例如用户点了口红之后,希望下一次请求实时推荐其他美妆类物品,例如粉底,适用该链路。
渠道收敛优化
限制渠道的传统CF协同过滤的i2i算法,即只召回和当前trigger item(用户行为关联的物品,例如点击行为的点击物品) channel 一致的相似物品。
在的基础上增加了渠道的限制,更突出和之前行为。
例如点击物品的渠道一致性。例如在新闻行业,用户点了财经新闻之后,希望下一次请求实时推荐财经新闻物品,适用该链路。
二、用户偏好二阶传导召回算法
各类用户偏好二阶传导召回链路
用户偏好类目二阶传导:
对应 数据规范 中item表的category_path字段。
基于终端用户历史行为,推算终端用户的偏好类目寻找相似物品的算法。
相对于协同过滤,更聚焦用户对于物品类目偏好。需要强依赖客户上传的行为数据和物品类目等信息,需要按数据规范要求上传行为以及物品类目信息。
用户偏好标签二阶传导:
对应 数据规范 中item表的tags字段。
基于终端用户历史行为,推算终端用户的偏好物品tag,寻找相似物品的算法。
相对于协同过滤,更聚焦用户对于物品tag偏好。需要强依赖客户上传的行为数据和物品tags等信息,需要按数据规范要求上传行为以及物品tag信息。
用户偏好渠道二阶传导:
对应 数据规范 中item表的channel字段。
基于终端用户历史行为,推算终端用户的偏好物品渠道,寻找相似物品的算法。
相对于协同过滤,更聚焦用户对于物品渠道偏好。需要强依赖客户上传的行为数据和物品渠道等信息,需要按数据规范要求上传行为以及物品类目信息。
用户偏好作者二阶传导:
对应 数据规范 中item表的author字段。
基于终端用户历史行为,推算终端用户的偏好作者,寻找相似物品的算法。
相对于协同过滤,更聚焦用户对于物品类目偏好。需要强依赖客户上传的行为数据和物品作者等信息,需要客户按数据规范要求上传行为以及物品类目信息。
用户偏好店铺二阶传导:
对应 数据规范 中item表的shop_id字段。
基于终端用户历史行为,推算终端用户的偏好店铺,寻找相似物品的算法。
相对于协同过滤,更聚焦用户的店铺偏好。需要强依赖客户上传的行为数据和物品店铺等信息,需要按数据规范要求上传行为以及物品店铺信息。
用户偏好品牌二阶传导:
对应 数据规范 中item表的brand_id字段。
基于终端用户历史行为,推算终端用户的偏好品牌,寻找相似物品的算法。
相对于i2i,更聚焦用户的品牌偏好。需要强依赖客户上传的行为数据和物品品牌等信息,需要按数据规范要求上传行为以及物品品牌信息。
用户偏好机构二阶传导:
对应 数据规范 中item表的organization字段。
基于终端用户历史行为,推算终端用户的偏好机构,寻找相似物品的算法。
相对于协同过滤,更聚焦用户对于物品的机构偏好。需要强依赖客户上传的行为数据和物品机构等信息,需要按数据规范要求上传行为以及物品机构信息。
三、热门召回算法
全局行为热度召回:
根据站内(app/小程序/网页端等)的行为数据进行汇总分析计算,得出站内的热门物品。新用户默认优先走热门召回链路。
区分场景的热门物品召回,一般用于个性化物品不足的时候补全兜底。
四、新品召回算法
智能推荐可以根据站内用户行为分析、兴趣分析,结合新品特征属性,小流量个性化探测新品潜力,从而逐渐扶持或打压新品的推荐流量。
各类新品算法召回链路:
基于用户偏好类目新品扶持:
当前算法是基于用户偏好类目(category_path)的个性化新品召回,如果希望使用本算法,需要将物品的发布时间、类目字段按数据规范要求上传准确。
基于用户偏好品牌新品扶持:
当前算法是基于用户偏好品牌(brand_id)的个性化新品召回,如果希望使用本算法,需要将物品的发布时间、品牌字段按数据规范要求上传准确。
基于用户偏好店铺新品扶持:
当前算法是基于用户偏好店铺(shop_id)的个性化新品召回,如果希望使用本算法,需要将物品的发布时间、店铺字段按数据规范要求上传准确。
基于用户偏好标签新品扶持:
当前算法是基于用户偏好标签(tags)的个性化召回,如果希望使用本算法,需要将物品的发布时间、tags字段按数据规范要求上传准确。
基于用户偏好渠道新品扶持:
当前算法是基于用户偏好渠道(channel)的个性化新品召回,如果希望使用本算法,需要将物品的发布时间、渠道字段按数据规范要求上传准确。
基于新品综合行为热度扶持:
当前算法是基于发布时间(pub_time)内新品的行为推算出来的热门新品,如果希望使用本算法,需要将物品的发布时间、行为数据按数据规范要求上传准确。
基于新品发布时间优先扶持:
按照发布时间(pub_time)倒序排序召回的新品,发布时间距当前时间越短,在当前算法中排序越靠前。
当前算法基于发布时间的新品召回,如果希望使用本算法,需要将物品的发布时间按数据规范要求上传准确。
五、向量召回算法
基于用户行为序列向量召回:
当前算法会根据用户点击序列商品作为输入,计算物品向量,计算物品之间的相似度或者用户对于物品兴趣程度,较传统i2i算法有更好的泛化性。
基于word2vec算法,共同用户行为越丰富,item间向量越相近。相对于I2I,可建模高阶相似度,从而提升召回覆盖率。适合item行为丰富的场景。相对于对i2i算法,此算法对于行为丰富度要求更高,比较适合行为丰富的业务场景。
基于标签向量召回:
基于item的tag的向量召回,通过向量描述物品各种tag,计算物品之间的相似度或者用户对于物品兴趣程度,较传统i2i算法有更好的泛化性。
基于物品tag的语义内容理解,推算物品的特征向量,所以对于tag质量要求比较高,如果物品tag的质量较好,可以考虑提升当前链路的优先级。
基于标题向量召回:
基于item的title的向量召回,通过向量描述物品标题,计算物品之间的相似度或者用户对于物品兴趣程度,较传统i2i算法有更好的泛化性。
基于物品标题的语义内容理解,推全出物品的特征向量,所以对于物品标题的质量要求较高。如果物品的标题质量较好,可以考虑适当调整当前链路的优先级。