一 Double Machine Learning——一种去偏方法
DML是一种处理
基于观测数据进行因果建模
的方法。
大家已知的是,观测数据是有偏的,即存在特征X既影响目标outcome Y,又影响Treatment T。那么在进行因果建模之前,我们需要进行去偏处理,使得Treatment Y独立于特征X,此时的观测数据近似相当于RCT数据,之后我们就可以使用因果模型进行CATE评估了。
HTE旨在量化Treatment对不同人群的差异影响,进而通过人群定向/数值策略的方式进行差异化处理。Double Machine Learning--DML是在研究HTE (Heterogenous Treatment Effect)过程中,通过残差估计矩(服从Neyman orthogonality),即使W(nuisance parameter)估计有偏,依旧可以得到无偏ATE估计的算法框架
构建模拟数据
在介绍DML之前,我们首先给定模拟数据——冰淇淋价格和销量之间的因果效应评估数据集。
该数据集中,特征X包括温度、成本和一周中的周几三个变量,Treatment T为价格,outcome Y为销售量。其中,T影响Y,X影响T和Y,即存在混淆。
探索冰淇淋销量和价格之间的关系,可以看到weekday是confounder,周末时价格和销量均更高。如果要得到准确的causal effect,需要矫正confounders带来的偏差。此数据集中包含的confounders有温度、周几、成本
我们使用观测数据进行训练,在RCT数据上进行模型评估。(
一种正确而标准的因果建模评估流程
)
通过可视化,我们可以很明显看到,在周末(weekday=1和7)的时候,价格比平常要高很多,即存在混淆。
二 从线性回归说起
一种简单的去偏方法就是线性回归,我们拟合一个线性回归模型,然后固定其他变量不变,去估计平均因果效应(ATE)。
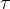 是我们唯一需要关注的,因为
是需要求的价格对销量的因果效应,其他变量我们并不关心,但是在线性模型中需要正确对待,否则得到的
是错误估计。
是我们唯一需要关注的,因为
是需要求的价格对销量的因果效应,其他变量我们并不关心,但是在线性模型中需要正确对待,否则得到的
是错误估计。
但特征X与Y的关系可能是非线性的,如温度temp。当温度升高时,人们可能都去沙滩玩耍,买冰淇淋吃,销量Y升高,但当温度过高时,人们可能只想呆在家,这时销量Y就下降了。
因此,我们需要利用一个线性回归的非常重要的特性:
假设现在有一个LR模型,以及特征集 X1 和特征集X2 . 我们可以通过以下两种方式来估计参数,而这两种方式估计出来的参数是相同的
1. HTL无偏估计
直观角度上,这里对回归比较熟悉的朋友可以知道,线性回归是拟合Y在特征空间X的最佳投影(既误差最小化),所以残差是垂直样本空间X的,既最大限度消除了(独立)X的相关性!如下图所示。
2. 使用DML估计ATE
具体到因果推断的例子上,我们只关心Treatment T 对 outcome Y的影响,因此我们可以首先使用X回归T,得到一个T的残差(实际T - 预测T),然后使用X回归Y,得到一个Y的残差(实际Y - 预测Y),最后使用T的残差回归Y的残差,估计的参数即我们想要的ATE。
于是乎,具体的DML方法也就出来了,其核心思想即分别用机器学习算法基于X预测T和Y,然后使用T的残差回归Y的残差:
那么问题来了,为什么说DML能去偏呢?
 它对Treatment实施了去偏。T的残差可以看作将X对T的作用从T中去除后剩下的量,此时T的残差独立于X。
它对Treatment实施了去偏。T的残差可以看作将X对T的作用从T中去除后剩下的量,此时T的残差独立于X。
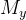 的作用在于去除Y的方差,即将X引起的Y的方差从Y中去除。最后,我们再对残差建模lr,即得到ATE。
的作用在于去除Y的方差,即将X引起的Y的方差从Y中去除。最后,我们再对残差建模lr,即得到ATE。
3. 使用DML估计CATE
同样地,我们首先基于X使用ML获得T的残差和Y的残差,之后使用lr拟合残差,不同的是,这次我们把X和T的交互项加进来,即
然后我们就可以计算CATE的值了:
4. 直接预测反事实的Y
在处理非线性CATE时,另一种方案是我们将不再尝试估计CATE的线性近似。相反,我们将做出反事实的预测。 (这种方案在实际中使用也很多,但并没有严格的理论证明!)
5. 从线性到非线性
虽然DML可以去混淆,让我们可以只关注T对Y的影响。但是,在使用ML对T和Y残差化后,我们仍然使用的是
线性模型
。当价格在小范围内变化时,这种方法可能还适用。然而,通常的情况是,在价格比较低的时候,价格增加1元,需求量可能减少2个,而在价格比较高的时候,价格增加1元,需求量可能只减少1个。显然,这是一种非线性关系。
此时,我们就会想,难道我们就不能不用线性模型,而使用其他模型,如利用ML去学习非常复杂的非线性?
答案是可以!
我们可以通过对目标函数进行转换,实现非线性建模
:
 那么我们在使用非线性模型时,学的到底是线性呢还是非线性呢?
其实,在非线性CATE估计时,DML估计的是CATE的局部线性近似!(也就是导数)
那么我们在使用非线性模型时,学的到底是线性呢还是非线性呢?
其实,在非线性CATE估计时,DML估计的是CATE的局部线性近似!(也就是导数)
举个例子,假设我们通过模型对一个顾客估计出CATE=2,意思是指我们在价格上减少一个单位,顾客买的量就会多出2个单位,但是我们不能据此就做出决策,在价格上减少5个单位,这样,我们就可以在减少的每个单位上都多获得销量上的2个单位,然而这样会赔死!因为当价格过低时,CATE可能就变成0.5了,即我们在价格上减少一个单位,顾客买的量只会多出0.5个单位!
因此在处理非线性CATE的时候,要格外注意不同Treatment下的CATE可能是不同的!
Double
ML:Python中的双重
机器学习
框架
double
ml-for-py
Double
ML -
Double
Machine
L
ear
ning
in Python项目地址:https://gitcode.com/gh_mirrors/do/
double
ml-for-py 项目
介绍
Double
ML 是一个基于Python的开源包,专门用于实现双重/去偏
机器学习
框架。该项目由@MalteK...
试图利用一个近期的或容易得到的中间指标来替代远期的或难以得到的终点指标。
抑制心律失常能降低发生心脏骤停的可能性,曾将[抑制心律失常]作为评价[治疗猝死药物]的替代指标。
因为混杂因子而造成了很多的悖论:
Yule-Simpson 悖论:吸烟分别对男性和对女性都有害,但是吸烟对人类有益
替代指标悖论:临床试验将心律失常作为猝死的替代指标。但是,一些能有效纠正心律失常的药物,后来发现不但不能减少猝死,反而导致数万人过早死亡
http://www.engin
从线性回归说起
从观测数据获得
因果
效应的一个简单方式是使用线性回归,控制confounders的影响:
Salesi=α+τPircei+β1tempi+β2Costi+β3Weekdayi+eiSales_i = \alpha+\tau Pirce_i+\beta_1 temp_i+\beta_2 Cost_i+\beta_3 Weekday_i+e_iSalesi=α+τPircei+β1tempi+β2Costi+β3Weekdayi+ei
τ\tauτ是我们唯一需要关注的,因为τ\
文章目录1 导言1.1 价格需求弹性
介绍
1.2 由盒马反事实预测论文开始1.3
DML
- 价格弹性预测推理步骤2 案例详解2.1 数据清理2.2 [v1版]求解价格弹性:OLS回归2.3 [v2版]求解价格弹性:Poisson回归+多元岭回归2.4 [v3版]求解价格弹性:
DML
2.4.1
DML
数据准备 + 建模 + 求残差2.4.2 三块模型对比2.4.3 稳健性评估
1.1 价格需求弹性
介绍
经济学课程里谈到价格需求弹性,描述需求数量随商品价格的变动而变化的弹性。价格一般不直接影响需求,

