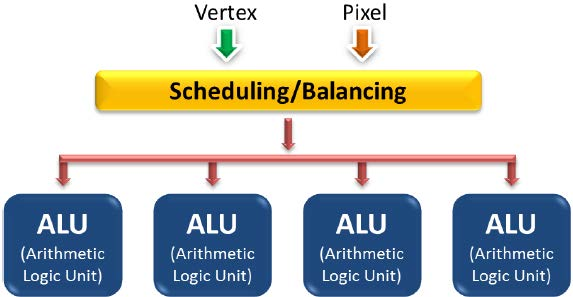
Adreno GPU是美国Qualcomm为移动平台设计的集成GPU。支持最先进的移动API,同时具有优异的性,应用于对带宽、功耗、散热等方面都有限制的移动芯片。Adreno GPU支持任意复杂的API,比如OpenGL ES(2.0、3.0、3.1等)、OpenCL、RenderScript、DirectX等。目前发布的分别有Adreno 130、Adreno 200、Adreno 203、Adreno 205、Adreno 220、Adreno 225、Adreno 302、Adreno 305、Adreno 306、Adreno 320、Adreno 330、Adreno 420、Adreno 430系列。Qualcomm可以为移动终端带来台式机品质的游戏体验。
Epic Games 高级引擎程序师 Niklas Smedberg 表示: “Epic 现在已经通过 Qualcomm Technologies 的骁龙 805 芯片组将虚幻引擎 4 ( Unreal Engine 4 )引入到了 Android 终端上。最近,我们还与Qualcomm Technologies 合作,通过骁龙 Adreno GPU 硬件将图形体验提升至一个全新的水平 ,为Android 智能手机和平板电脑带来前所未有的高效统一着色功能。 ”
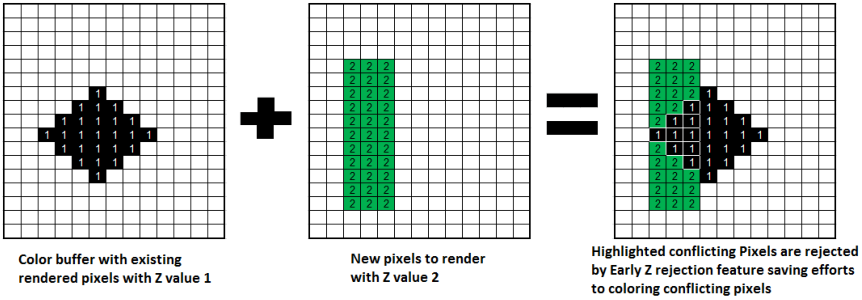
Adreno GPU包含高速缓存(GMEM)来存储深度、模板和颜色信息,类似PC显卡的显存。GPU可以以很高的速度访问GMEM,访问速度到什么程度呢?到访问时间可以忽略不计,同时耗电量也可以忽略不计。所以,使用GMEM是高效低耗的。同时,还可以降低alpha混合和抗锯齿的成本。
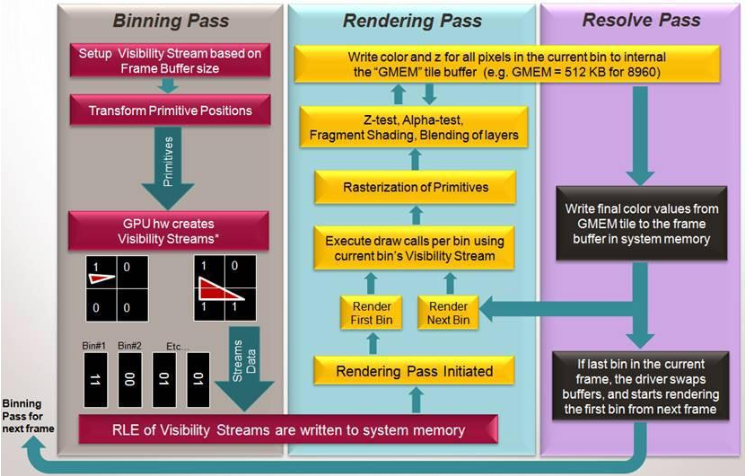
既然GMEM这么好,是不是越大越好呢?回答是肯定的,但是这会导致成本的急剧增加。所以,GMEM一般不会太大,比如1M。GMEM这么小怎么来使用呢?这就需要基于Tile的渲染架构。
Tile渲染不同于一次渲染整个场景,而是分多次渲染。要渲染的面被分割为一些小的“bin”. Bin 的大小由GMEM的大小除以渲染目标的格式(包括深度缓存的格式)和大小来决定。
每个bin的所有像素都被画到GMEM里面,GMEM有着非常高的带宽足以匹配GPU的能力。等这个bin绘制完成后,GPU将GMEM中混合好的像素以一个整体的形式高效写回到系统内存的帧缓冲区,这叫做一次“Resolve”。
我们知道GPU对内存的访问是最耗时间、性能和功耗的。而有了Tile架构,我们就可以大大减少对内存的访问。如上图画面,有12个Tile,所以GPU只需要访问12次内存即可。
当然上面说的12次内存访问只是理论值,如果用户的程序写的不规范的话,不但不会提高性能还会降低性能。数据通过系统总线在内部存储和外部帧缓冲区之间的传输是非常耗资源的操作,应该尽量避免。特别是在一个帧的中间调用glTexImage2D, glBufferData, glReadPixels, glCopyTexImage2D等函数, 强迫驱动从外部低速存储加载一个tile到内部高速存储。
-
使用额外的/复杂的着色器而不会影响性能
-
更低的功耗,更好的性能
原文地址:http://blog.csdn.net/cuichuankai/article/details/49331049
Adreno GPU详细介绍Adreno GPU是美国Qualcomm为移动平台设计的集成GPU。支持最先进的移动API,同时具有优异的性,应用于对带宽、功耗、散热等方面都有限制的移动芯片。Adreno GPU支持任意复杂的API,比如OpenGL ES(2.0、3.0、3.1等)、OpenCL、RenderScript、DirectX等。目前发布的分别有Adreno 130、Adreno
Ad
reno
GPU
为无缝配合骁龙CPU和DSP而设计,帮助支持处理密集型GP
GPU
(通用
GPU
)计算任务[18]。和其它移动
GPU
一样,受限于芯片的面积、功耗以及成本等因素,
Ad
reno
GPU
只能牺牲部分性能和带宽来求得性价比和电池续航力的平衡[7]。移动
GPU
的劣势主要表现在理论性能和带宽[7],因此其构架和PC
GPU
有所不同。
1
GPU
构架
目前在
GPU
...
GPU
捕获(用于 Arm64 的 Unreal Engine 4.25)
在此示例中,引擎在 WinPixEventRuntime 库的帮助下将 PIX 事件插入到
GPU
命令流中。 这有助于跟踪帧渲染操作。
启动 CPU 捕获
CPU 捕获
此示例显示了 UE4 4.25 的单个渲染帧的 CPU 捕获。 针对 CPU 和
GPU
捕获报告 PIX 事件
Ad
reno
GPU
SDK提供了非常完善的框架,我们可以通过制作出很多有趣的东西,在Sample路径下的实例中,也提供了大量的实例来向大家展示其强大的功能。那么在接下来,我将带领大家对这些例程进行分析和学习。
二、OpenGL ES例程分析
进入Sample下的OpenGLES文件夹,大家可以看到大量的实例:
我们选择Skining例程吧,进入后会看到Scene.cpp和Scene....
一、APK简介
本文将
介绍
基于
Ad
reno
GPU
SDK开发Smoke Model过程遇到的一些问题及解决办法。APK最终的效果为,当在搭载骁龙
GPU
的Android手机上运行Smoke APK时,将可以看到一个烟雾模型的效果,同时也可以在屏幕的四个角落分别显示APK的名字、FPS以及Logo等信息。
二、开发流程及问题解决
基于
Ad
reno
GPU
SDK开发APK时,需要准备好开发环境,之后...
下面我们继续高通
Ad
reno架构应用优化的内容。
顶点着色器计算胜于片段着色器计算
通常,顶点数显着小于片段数。通过将计算从片段着色器移动到顶点着色器,可以减少
GPU
的工作量。这有助于消除冗余计算。
测量,测试和验证结果
查找瓶颈对于优化应用程序是顶点绑定,片段绑定还是纹理获取绑定而言都是必需的。在尝试使代码更快之前,请先测量性能。使用工具进行这些测量,例如Snapdragon Profiler甚至是软件计时器。不要仅仅凭直觉就假定某些东西运行得更快。修改代码以使其表现更好时,它可以禁用更有益的编译器/硬件
Ad
reno 660是高通公司的最新一代
GPU
,下面是
Ad
reno 660的
详细
规格:
1.
GPU
架构:
Ad
reno 600系列的第三代
GPU
架构,采用7nm工艺制程,具有更高的效率和性能。
2.
GPU
核心数:
Ad
reno 660有512个计算单元,比前一代
Ad
reno 650多了35%,可以提供更快的图形渲染速度和更高的图形质量。
3. 最高主频:840MHz,比
Ad
reno 650的最高主频提高了20MHz,可以提供更快的图形处理速度。
4. 支持的API和标准:
Ad
reno 660支持OpenGL ES 3.2、Vulkan 1.1、OpenCL 2.0等图形和计算API和标准,可以满足各种应用的需求。
5. 支持的分辨率:
Ad
reno 660最高支持4K分辨率,可以提供更高清的图形显示效果。
6. 支持的显示接口:
Ad
reno 660支持HDMI 2.1、DisplayPort 1.4、USB-C等多种显示接口,可以满足各种设备的需求。
7. 支持的存储器类型:
Ad
reno 660支持LPDDR5、LPDDR4X等多种存储器类型,可以提供更高的存储器带宽和更快的数据传输速度。
8. 支持的存储器带宽:
Ad
reno 660最高支持275GB/s的存储器带宽,比
Ad
reno 650提高了25%,可以提供更快的数据传输速度和更流畅的图形渲染效果。
9. 支持的视频编解码器:
Ad
reno 660支持H.264、H.265/HEVC、VP9等多种视频编解码器,可以提供高效的视频处理和更清晰的视频显示效果。
10. 支持的AI加速器:
Ad
reno 660内置了Hexagon 780 DSP,提供26TOPS的AI性能,可以提供更快的AI计算速度和更高的AI计算效率。
以上是
Ad
reno 660的
详细
规格,它具有更高的计算单元数量、更高的存储器带宽和更强的AI性能,可以提供更出色的图形处理和深度学习性能,适用于高端移动设备和虚拟现实、增强现实等应用场景。