|
|
|

缺失值处理
操作视频
SPSSPRO教程-缺失值处理
# 缺失值处理
# 1、作用
缺失值即空值。数据集不含缺失值的变量被称为 完全变量 ,含有缺失值的变量被称为 不完全变量 。从缺失的分布来说,我们可以把缺失分为完全随机缺失,随机缺失和完全非随机缺失。
-
完全随机缺失(missing completely at random,MCAR)指的是数据的缺失是完全随机的,不依赖于任何不完全变量或完全变量,不影响样本的无偏性,如家庭地址缺失;
-
随机缺失(missing at random,MAR):指的是数据的缺失不是完全随机的,即该类数据的缺失依赖于其他完全变量,如财务数据缺失情况与企业的大小有关;
-
非随机缺失(missing not at random,MNAR):指的是数据的缺失与不完全变量自身的取值有关,如高收入人群不原意提供家庭收入;
对于缺失值,往往直接删除是不合适,于是我们需要进行缺失值处理,包括考虑是否剔除,或进行填充处理。
# 2、输入输出描述
输入
:一项或以上定量或定类变量。
输出
:对缺失值进行填补后的序列。
# 3、案例示例
案例 :示例,现有一个变量,对空值进行识别,并且用当前的均值对空值进行填补。
# 4、案例数据
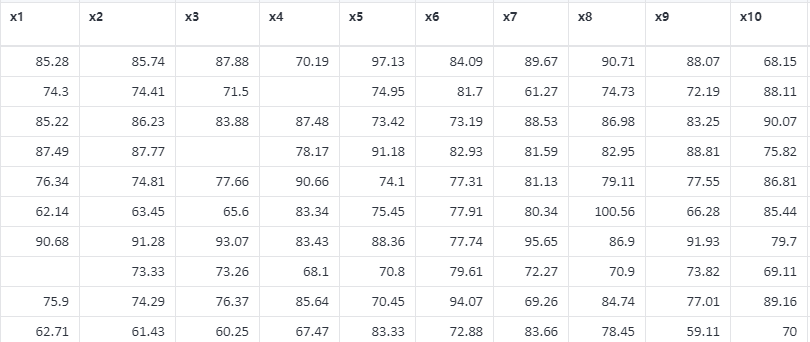
缺失值处理案例数据
# 5、案例操作
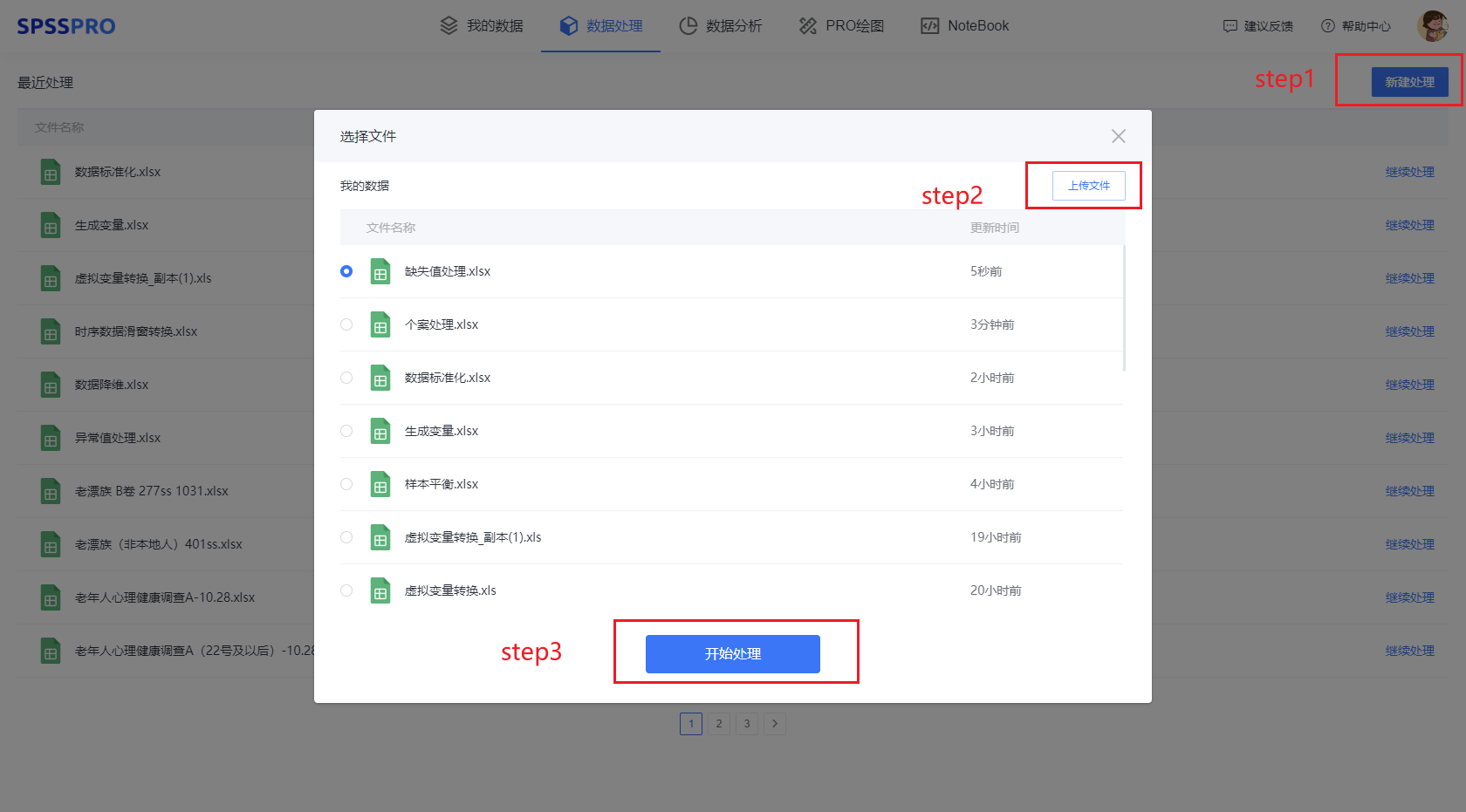
Step1:在“数据处理”模块新建处理;
Step2:上传文件;
Step3:选择对应数据打开后进行预览,确认无误后点击开始分析;
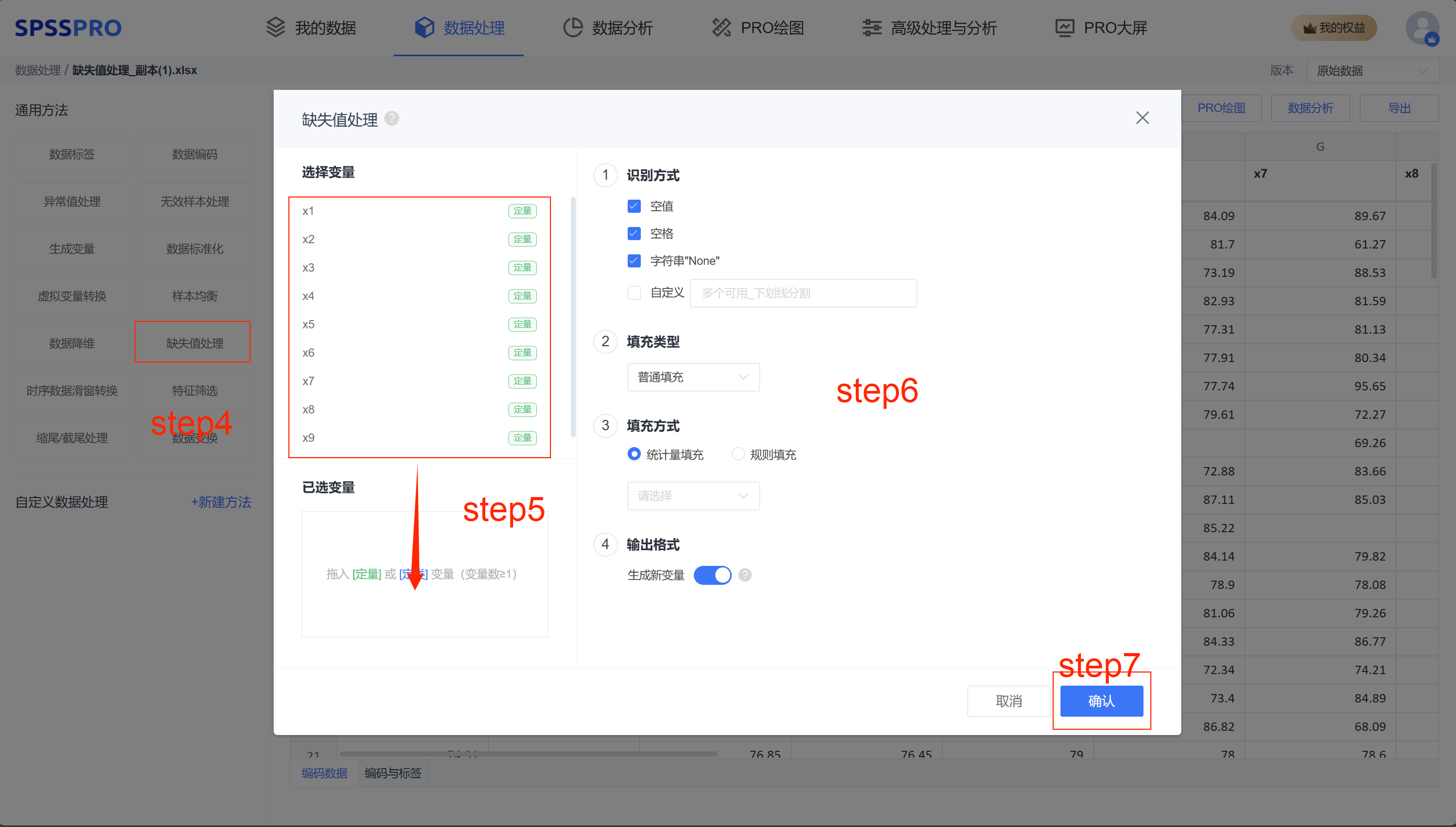
Step4:选择【缺失值处理】;
Step5:查看对应的数据数据格式,【缺失值处理】要求变量为定量或定类变量,且至少有一项;
Step6:确认参数,有不同的填充方法可选择;