


浅谈延迟渲染、移动GPU架构和Metal

本文介绍目前业界常用的前向渲染以及延迟渲染,分析如何根据应用场景进行选择。结合移动端GPU架构分析延迟渲染瓶颈,提出一种利用Metal特性以及PowerVR GPU架构实现Single-Pass Deferred Shading的渲染方法。
对实时渲染有了解的小伙伴想必听过前向渲染(Forward Rendering),或许还对延迟渲染(Deferred Rendering)或者他的后继者Deferred lighting延迟光照有所耳闻。Deferred Rendering一般不会单独出现,有时还会带上tile-base这小朋友。偶尔还会有forward plus这小哥带着他的cluster-base朋友出来添乱。今天这篇文章会给大家聊聊前向渲染和延迟渲染这两位同学,当然主要是这位还没有在移动端取得成功的延迟渲染,并说说他相对不为人所知的原因,还有我们这些从业者想把他推出去变成当红炸子鸡的努力。
0x00 这个你会,可编程渲染管线
在说那几位之前,我们先聊点轻松的东西,在gles1.0时代,硬件渲染管线还是固定的,就像是一个已经设计好的流水线,旁边有几个开关,程序员能做的就是切换这一个个开关,修改纹理、渲染状态、在几个固定的光照模型之间切换。有限的开关越来越难满足大家对效果无止境的需求。可编程渲染管线随之而来,取代了这一个个固定的开关的是几个坐在固定位置的工人(vertex stage/fragment stage),这些工人可以接受我们的指令进行绘制。vertex shader、geometry shader、fragment shader就是这几个勤劳的工人,通过他们,我们就可以控制GPU是如何绘制物体的。
0x01 前向渲染
借助上面几个勤劳工人的帮助,前向渲染闪亮登场。前向渲染是一种非常直接的渲染方式,我们提交的mesh,经过vs、gs、fs等shader,直接绘制到color buffer等待输出到屏幕。在考虑光照的情况下,在场景中我们根据所有光源照亮一个物体,之后再渲染下一个物体,以此类推,很线性的Per-Object/Per-Light方式进行绘制。
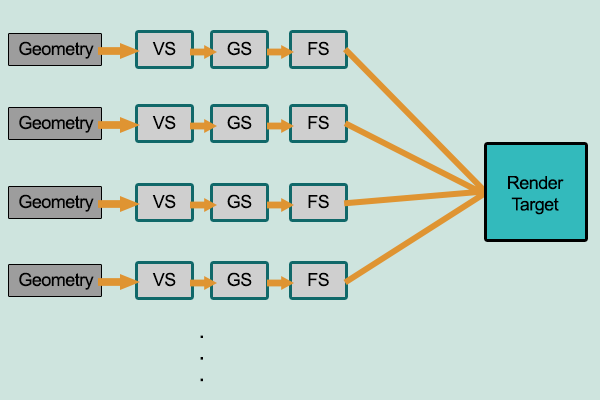
贴一下前向渲染的伪代码:

这位直接了当的老哥有如下特点:
- 先执行着色计算,再执行深度测试。
- 前向渲染渲染n个物体在m个光源下的着色,复杂度为O(n*m)次。
- 光源数量对计算复杂度影响巨大,适合户外等光源较少的场景。
正如最后一点特点,当场景复杂度上升,大量光源大量物件的时候,前向渲染O(n*m)的复杂度就是不能承受的。另外因为一般情况下只绘制color buffer,对需要法线和深度进行计算的后处理算法支持不好,这些后处理往往对性能影响很大。
0x02 延迟渲染

先贴一张图片。说实话上图场景物件并不算多,只是光源太多足有1000以上。在当前硬件水平下,这种场景传统前向渲染只能表示无能为力。
为了解决这种问题,延迟渲染在2004年GDC上被正式提出。延迟渲染( Deferred Rendering),即延迟着色(Deferred Shading),顾名思义,是将着色计算延后进行处理的一种渲染方法,可以将延迟渲染( Deferred Rendering)理解为先将所有物体都先绘制到屏幕空间的缓冲(即G-buffer,Geometric Buffer,几何缓冲区)中,再逐光源对该缓冲进行着色的过程,从而避免了因计算被深度测试丢弃的片元着色而产⽣的不必要的开销。也就是说延迟渲染基本思想是,先执行深度测试,再进行着色计算,将本来在物空间(三维空间)进行光照计算放到了像空间(二维空间)进行处理。对应于前向渲染O(m*n)的复杂度,经典的延迟渲染复杂度为O(n+m)。
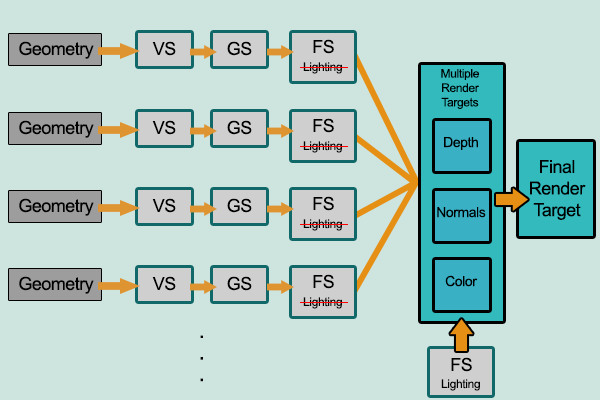
此处呈上经典延迟渲染的伪代码

目前看起来延迟渲染把复杂度降了下来,面对复杂场景+多光源的需求面前有了办法。然而这也带来了其他的问题。对比前向和延迟的流程图可以发现,延迟管线下多了深度、法线、颜色等几张G-Buffer。这些都是屏幕大小的尺寸的Render Target,所带来的内存以及带宽压力很大。
延迟渲染有以下特点:
- 内存开销较大。
- 读写G-buffer的内存带宽用量是性能瓶颈。
- 对透明物体的渲染存在问题。在这点上需要结合前向渲染进行渲染。
- 对多重采样抗锯齿(MultiSampling Anti-Aliasing, MSAA)的支持不友好,主要因为需开启MRT。
- 由于Deferred Shading的Deferred阶段是在完全基于G-Buffer的屏幕空间进行,这也导致了物体材质信息的缺失,这样在处理多变的渲染风格时就需要额外的操作。
针对上文的问题,业界有主流有两种优化方式。
- Light Pre-Pass即Deferred Lighting 延迟光照技术,通过减少经典延迟渲染所使用的G-Buffer数量来提高性能,最早由 Wolfgang Engel于2008年在他的博客中提到的。
-
分块延迟渲染,tile-based Deferred Rendering(记得开篇提到的tile-base小兄弟没,这会出场了)。该方法通过可以在一次绘制处理多个光源,以及来降低对G-Buffer的读写开销。
延迟光照有对MSAA支持良好、可以使用更多材质等等优点,由于数据证明大量光源下性能不及分块延迟渲染,该部分不会介绍,感兴趣的同学可以在引用中的链接自行查阅。下面我们会重点说说分块延迟渲染。
0x03 分块延迟渲染
经典延迟渲染的瓶颈在对G-Buffer的读取上,在存在大量光源的前提下,每个光源绘制都需要读取G-Buffer,并和color buffer进行混合。考虑到每个光源都有各自覆盖的面积,不同光源覆盖区域重叠的情况会非常多,被多光源覆盖的像素还是需要在各自光源的绘制过程中被重复计算。
针对这一个问题,分块延迟渲染把屏幕分成很多个tile,然后计算一下每个tile被哪些光源覆盖到,把覆盖tile的光源保存在tile的光源列表中,绘制tile时一次绘制完成所有覆盖光源光照计算。tile以及光源列表见下图。
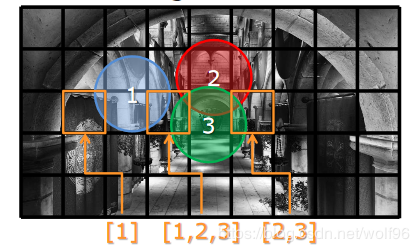
分块延迟渲染流程一般为:
- 生成G-Buffer。
- 将G-Buffer分tile,每个tile用compute shader(偶见在cpu中间计算的实现)计算出depth bound。
- 进行light cull,得到light index list。
- color pass,使用G-Buffer信息,用该fragment所在tile的light index list进行绘制。
实验数据证明分块延迟渲染的在大量光源存在的情况下性能明显好于延迟光照。
0x04 小结
上文介绍了前向渲染和延迟渲染,在延迟渲染及其优化版本用了较大篇幅分析延迟渲染出现理由以及优缺点。而对两种渲染方式的选择也很简单,就像是一个天枰,一边放着复杂场景和多光源的需求,还有低代价使用依赖深度和法线的后处理,而另一边就是内存开销大以及频繁读写G-Buffer的性能开销。如何选择已经看需求,也需考虑技术团队的经验能力。而前向渲染因为没有G-Buffer以及light cull的存在,所以在简单场景下效率颇高,光照多其实也有解,lightmap配合IBL的方案很成熟的。
只是目前对比3A大作颇多采用延迟渲染的现状相比,手机端市场占有率最高的两款商业引擎unity3d和ue4阵营中也未见几款延迟渲染渲染的作品。难道限于手机相对孱弱的性能大家都放弃了大场景多光源的需求么?并不尽然,原因如何且看下文。
0x05 移动端GPU两三事
移动端的硬件设计最初要考虑的其实是功耗,功耗会影响耗电、发热、芯片大小等等。移动端GPU肯定也必然优先考虑功耗,没有人愿意面对分分钟没电的烤手宝,过热也必然带来降频影响本就不是很优秀的处理器性能。那么问题来了,影响功耗的最大因素是什么?带宽。
看到多次出现的带宽,读者大人应该能感受到移动端针对延迟渲染深深的恶意。在得出某种结论之前,还是有必要在对移动端GPU的背景再多介绍一下。
目前移动GPU领域,高通的adreno、ARM的mali、Imagination PowerVR占据了主要市场。在GPU设计上,这三家都没有采用桌面GPU主流的IMR(Immediate Mode Rendering)架构。以PowVR为例,Imagination 设计采用了Tile Based Deferred Rendering架构,简称TBDR,为了和上面的分块延迟渲染区分开来,这里姑且先叫做硬件TBDR。
要区分两者,容我先介绍一下IMR架构。
IMR就像opengl等图形API书籍中介绍的标准图形渲染管线,顶点阶段之后裁剪投影剔除,光栅化然后着色再之后像素操作。直来直去的有些像开篇介绍的forward render。因为桌面GPU的功耗、散热限制条件较少,带宽以及显存也明显高于移动端。GPU在没有诸多限制的情况下,这种直接的方式效率是最高的。
移动端上处处限制,设计架构也不得不采用牺牲效率换取带宽的方案,且看PowerVR的渲染流程。
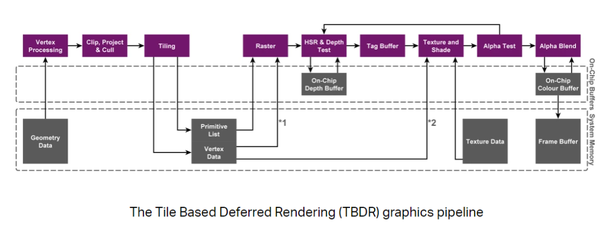
TBDR该词分两部分来理解。tile-base讲的是将需要渲染的画面分成一个个tile,这里一般是4x4或者8x4的矩形块。模型的顶点经过Vertex Shader运算以后会组装成一个个的triangle,这些triangle会被缓存在一个triangle cache里面。如果某个triangle需要在某个tile里面绘制,那么就会在该tile的triangle list中存一个索引。等一帧里面所有的渲染命令都经执行完Vertex Shader生成triangle以后,每个tile就会有一个triangle list,这list就包含了需要在该tile内部绘制的所有triangle。然后GPU再基于triangle list执行每个tile的raster和Per-fragment operation。是不是有点上文提到的软件TBDR的感觉了?
DR实际上出现在两个地方,一是在光栅化之前,绘制指令被缓存到Primitive List和Vertex Data中,所有指令处理完毕之后再进行光栅化。第二是在纹理采集和着色阶段之前,像素会进行名为HSR(Hidden Surface Removal)的early-z阶段,这一波会进行On-chip(片上)深度测试以及深度缓存写入,着色再次延迟在深度测试之后。
PowerVR之外的另外两家GPU架构也都是基于tile实现的,Mali同样有类似HSR的early-z技术。Adreno自家的FlexRender技术会在TBR和IMR针对效率自行切换,小尺寸的rendertarget使用IMR提升速度,反之则使用TBR拯救带宽。
大家在设计架构上用的努力折射出移动端上带宽问题影响确实严重。诚然软件TBDR在目前的中高端手机上运行帧率已经问题不大,不过发热和耗电问题却不易解决。另外light-cull等操作对图形要求gles3.1以上,国内市场虽然问题不大,但是东南亚群体gles2.0比例却依然不低。
问题虽然很多,不过大多时候我们依然要目光向前。架构某种程度反应所面对的问题,但更多的是体现解决问题的方法。
0x06 基于metal的TBDR渲染设计
说到现在,我们已经说了两种形式的TBDR了,一种是软件TBDR,完全程序控制,划分tile,计算光源列表再进行着色。另外一种是则是硬件TBDR,GPU架构实现。两者的目的也不尽相同,前者为了解决多光源问题,同时带来了廉价的后处理,问题是增加了带宽开销。后者用效率(HSR的存在未必见得效率影响很大)换带宽。
Apple在自家的metal demo中提供了一种可能性,即利用on-chip内存实现的Single-Pass Deferred Rendering。这个示例在桌面端以及移动端使用了两种渲染器,这两种都基于传统的延迟渲染。

即在第一个pass先生成G-Buffer,在第二个pass进行光照计算。
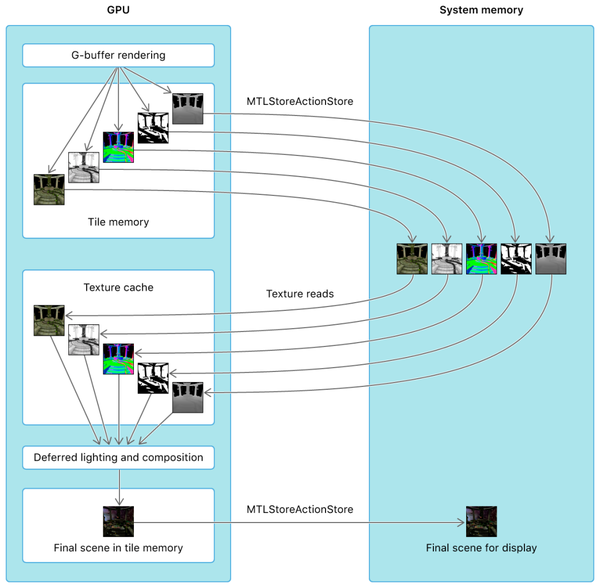
在非TBDR(Mac)的架构之下,第一个pass的G-Buffer会被缓存到系统内存中,第二个pass读取G-Buffer,频繁读写大图片,在桌面端问题并不大。而在IOS上,Apple使用了Single-Pass Deferred Rendering渲染器,收益于TBDR的硬件架构,通过显式的设置ColorAttachment的store&loadAction,gpu会将硬件拆分的tile的render target放在on-chip memory中,在lighting阶段所有需要的render target都不需要在从系统内存中读取,光照计算结束之后on-chip memory中的渲染结果再统一写回系统内存。
流程如下图:
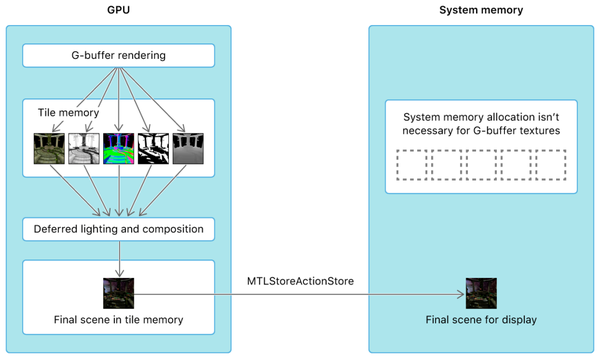
至此,由硬件处理TB,软件处理DR的渲染流程完成了。在这个基础上,我们可以使用metal2的新特性Raster Order Group以及Image Blocks进一步优化Pipeline,有兴趣的同学可以在引用链接中查找并自行实现。
在整个渲染流程中,依赖硬件TBDR框架,完成了软件延迟渲染配合硬件分块,使用on-chip memory减少带宽压力,在此基础上,使用metal2的新特性Raster Order Group以及Image Blocks可以进一步优化Pipeline,有兴趣的同学可以在引用链接中自行了解,这里不再介绍了。
0x07 总结
本文中介绍了前向渲染以及延迟渲染,结合移动端GPU架构进行分析,旨在帮助大家结合自身技术以及需求合理选择,并展示了利用GPU架构以及现代图形API优化渲染流程的方案。因为篇幅问题,对Clustered方法以及Forward Plus没有介绍,望理解。
感谢阅读,谢谢。
参考文献
1. [forward-rendering-vs-deferred-rendering]
https://
gamedevelopment.tutsplus.com
/articles/forward-rendering-vs-deferred-rendering--gamedev-12342
2. [《Real-Time Rendering 3rd 第七章续 · 延迟渲染]
https://
blog.csdn.net/poem_qian
mo/article/details/77142101?utm_source=blogxgwz4
3. [Rendering a Scene with Deferred Lighting]
https://
developer.apple.com/doc
umentation/metal/rendering_a_scene_with_deferred_lighting
4. [针对移动端TBDR架构GPU特性的渲染优化]
https://
gameinstitute.qq.com/co
mmunity/detail/123220
5. [Apple - Understanding GPU Family 4]
https://
developer.apple.com/doc
umentation/metal/gpu_features/understanding_gpu_family_4
6. [Apple - About Raster Order Groups]
https://
developer.apple.com/doc
umentation/metal/gpu_features/understanding_gpu_family_4/about_raster_order_groups
7. [Deferred Lighting]
http://
diaryofagraphicsprogrammer.blogspot.com
/2008/03/light-pre-pass-renderer.html
8. [移动端gpu架构浅析]
https://
gameinstitute.qq.com/co
mmunity/detail/103959
9. [imgtec TBDR]
https://www.
imgtec.com/blog/underst
anding-powervr-series5xt-powervr-tbdr-and-architecture-efficiency-part-4/
10.[Light Pre-Pass Renderer]
http://
diaryofagraphicsprogrammer.blogspot.com
/2008/03/light-pre-pass-renderer.htm

快手Y-tech介绍(公众号同名)
Y-tech团队是快手公司在人工智能领域的探索者和先行者,致力于计算机视觉、计算机图形学、机器学习、AR/VR等领域的技术创新和业务落地,不断探索新技术与新用户体验的最佳结合点。Y-tech在北京、深圳、杭州、Seattle、Palo Alto有研发团队,成员来自于国际知名高校和公司。
长期招聘(全职和实习生):计算机视觉、计算机图形学、多模态技术、机器学习、AI工程架构、美颜技术、特效技术、性能优化、平台开发、工具开发、技术美术、产品经理等方向的优秀人才。如果你对我们做的事情感兴趣,欢迎联系并加入我们,一起做酷炫的东西,创造更大的价值。
联系方式:y-techservice@kuaishou.com
AIGC开放平台:即将上线,敬请期待~