


DIM:通过最大化互信息来学习深度表征

话先说到前面, 这篇文章我感兴趣的不是它的实验! 原文是CV领域,无监督学习再加上一些变分自编码器的东西。我还没有研究到那一步,模型实现细节我没有看懂,但整体框架还可以捋一捋说一说。 我真正感兴趣的是它的思路---从整体走向局部。最为关心的是理论上的推导 ,尤其是互信息那一块。 对数学有高度不适者慎入。
0 来源
原文作者:R Devon Hjelm、Alex Fedorov、Samuel Lavoie-Marchildon、Karan Grewal、Phil Bachman、Adam Trischler、 Yoshua Bengio(深度学习三巨头之一)
原文下载:
1 概述
深度学习的核心目标之一就是:从数据中学到好的表征 。什么叫好的表征?就是找到可以明确区分数据集样本的表征,就是包含了该样本最为独特信息的表征。换句话说:给出一图片X,模型学习到的这张图片的表征Y可以重构这张照片。常用的衡量方法是 互信息 I(X;Y) 。但是互信息在连续高维的随机变量中非常难以计算,但是在神经估计的最新进展中,已经有能够有效计算深度神经网络的高维输入/输出对之间的互信息。 原文要做的就是训练表征学习函数(即编码器)以最大化其输入和输出之间的互信息,在此基础上提出了DEEP INFOMAX(DIM)模型 。本文模型主要有四方面:
(1)不仅考虑整体输入与输出的互信息,而且
将局部输入与输出的互信息考虑进去
优化。
(2)
采用了噪声对比估计
(Noise Contrastive Estimation,NCE)方法训练鉴别器。在NLP任务 中它还有另外一个名字--'负采样',后面会介绍它的用处。
(3)使用
对抗学习来约束具有特定于先验的期望统计特性的表征
。说白了就是让表征向量的先验分布是高斯分布。
(4)引入了
两种新的表征质量的度量
,一种基于 MINE,另一种是 Brakel&Bengio 研究的的依赖度量,研究者用它们来比较不同无监督方法的表示。
原文作者认为他们的方法可用于学习期望特征的表示,并且在分类任务按经验结果优于许多流行的无监督学习方法。同时 DIM 开辟了无人监督学习表示的新途径 ,是面向特定最终目标而灵活制定表征学习目标的重要一步。
2 推导
原文很多公式都是高度简练,对于这方面没有基础的新手看起来超级麻烦。 我也是综合了几篇别人的阅读笔记以及翻看原文涉及的相关细节,整理出一系列理论的推导。 按照这种逻辑和公式推演DIM背后的数学公式应该还能讲得通吧。当然, 弱水三千,只取一瓢。这一瓢合不合读者的胃口不敢说,出发点不同,自然侧重点不同。
引入符号-- x 表示样本集的某一张图片, z 表示的是编码向量(也就是表征),在原文中加了约束--服从高斯分布。 p(z|x) 表示的是 x 所产生的编码向量的分布。那么编码器的输入 x 与输出 z 的互信息为:
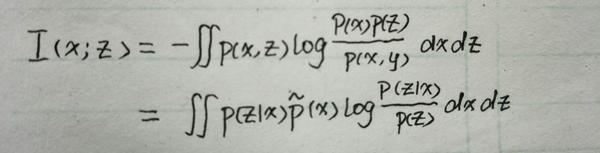
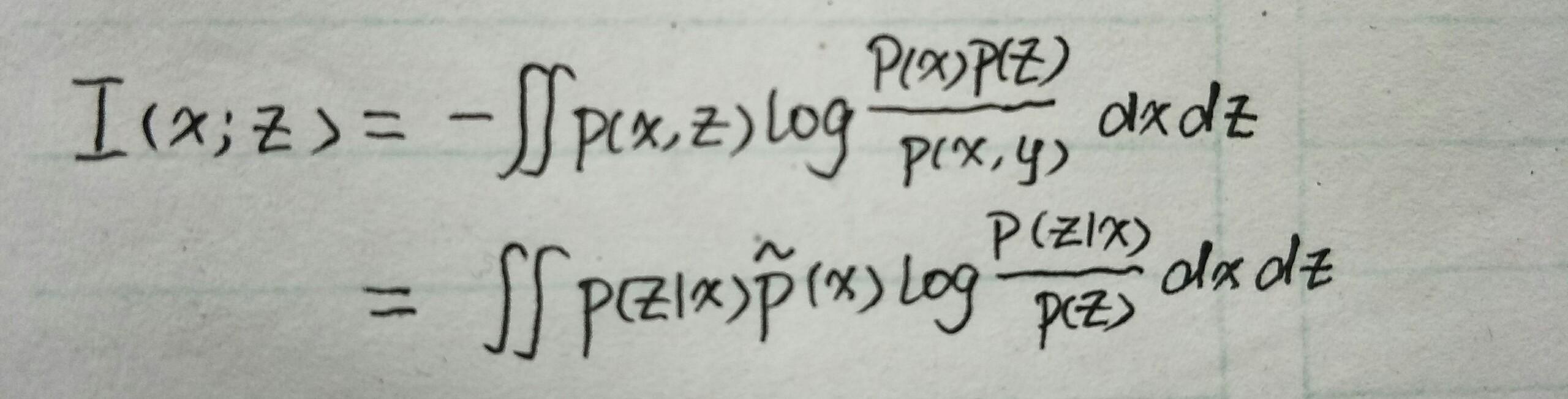
其中 \tilde{p}(x) 表示的是原始数据的分布。另外 p(z) 为:
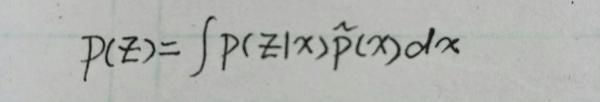
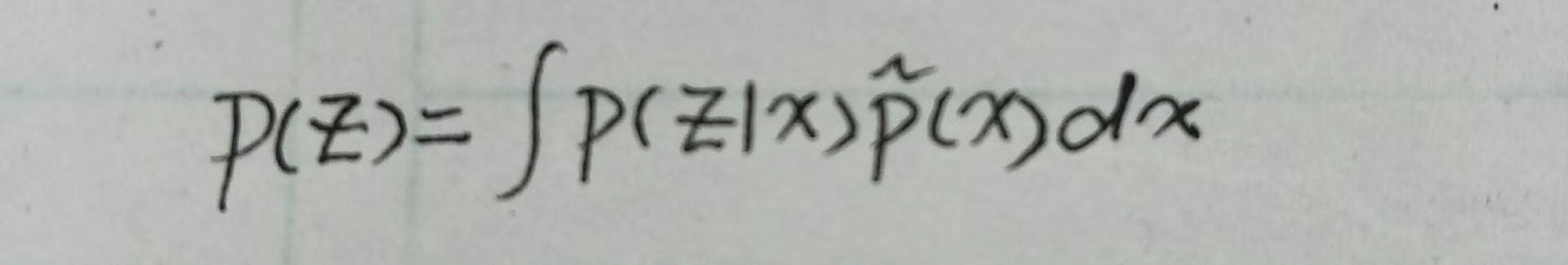
从函数角度看互信息就是 p(z|x) 的泛函。从第一个公式就可以看出对于好的编码器来讲,互信息越大越好。因为 I(x;z) 其实就是 KL(p(x,z)||p(x)p(z)) ,衡量两个概率分布 p(x,z) 和 p(x)p(z) 的距离。距离越大,那么 x 和 z 的相关性就越高--这不就是我们想要的吗?另外从公式中也可以看到,如果想要互信息大,那么就要使对数项 log\frac{p(z|x)}{p(z)} 大,也即让 p(z|x) 远大于 p(z) ,这样找到的 z 就是属于 x 的最为独特的表征向量。因此最大互信息就是: p(z|x)=arg(max_{p(z|x)}I(x;z))
原文使用 对抗学习来约束具有特定于先验的期望统计特性的表征,就是让 p(z) 服从高斯分布。 做法可以这样,构建一个符合高斯分布的模型 q(z) ,然后计算两者的KL散度:
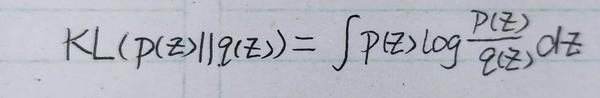
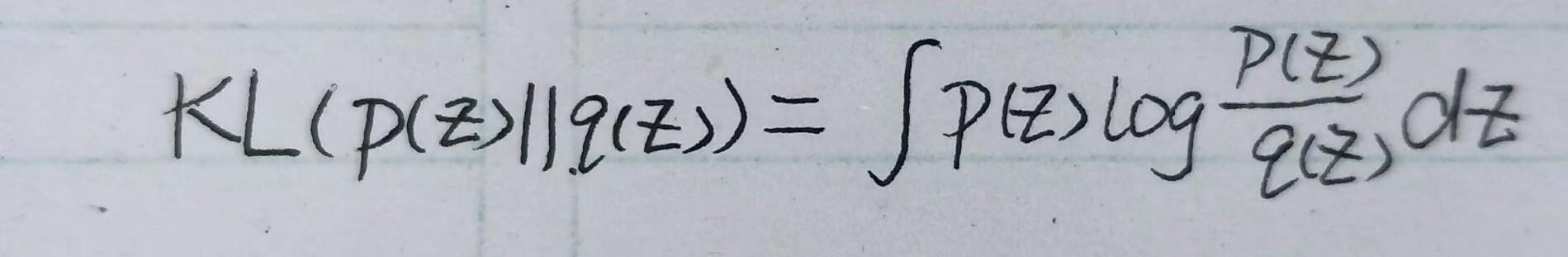
将这个KL散度作为约束项和互信息加权就得到了新的目标函数:

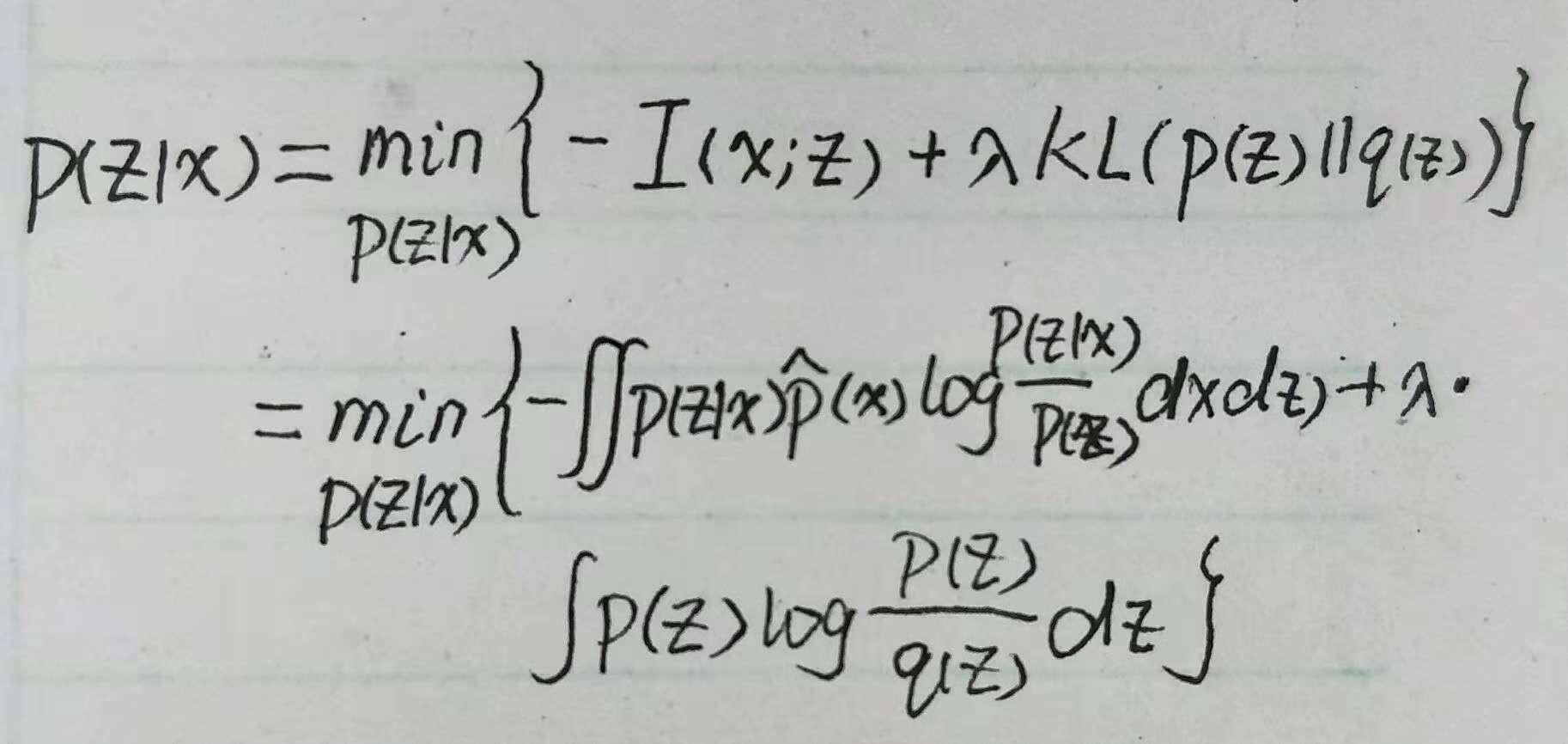
用第三个式子替换下约束项中 p(z) 就可以将第四个式子改写为:
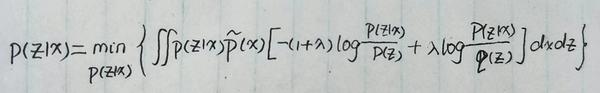
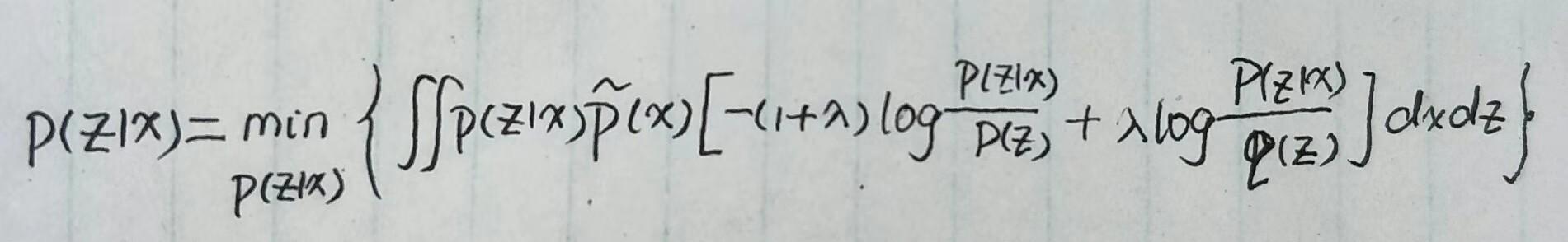
注意上式正好是 互信息 与 E_{x\sim{\tilde{p}(x)}}(KL(p(z|x)||q(z))) 的加权求和,因此上式就变为:
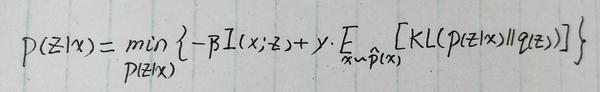
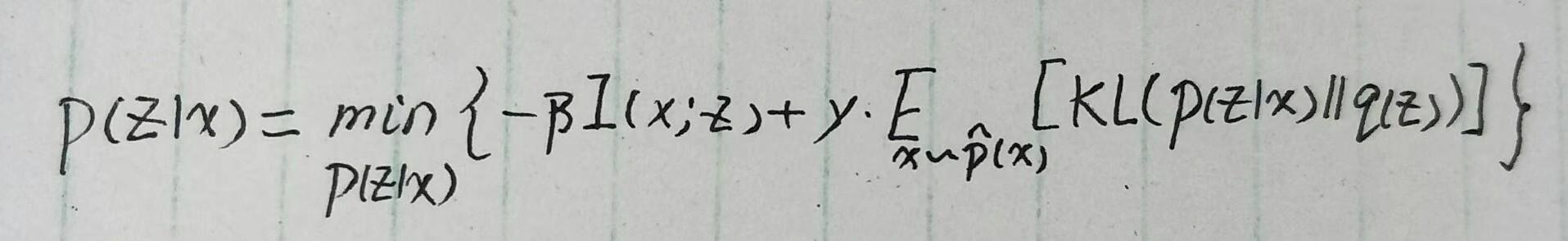
其中 \beta 和 \gamma 是加权系数。而 KL(p(z|x)||q(z)) 这一项正好是VAE的那一项KL散度,是可以算出来的。所以上式就主要需要攻克互信息的计算。
上文提到 I(x;z) 其实就是 KL(p(x,z)||p(x)p(z)) ,这里使用KL散度来衡量两个概率分布的距离,但是KL散度是有一定问题的---它是一个无上界的量。如果最大化互信息是一个无上界的量那么就容易导致无穷大的出现。原文中也提到了这点,因为我们只需要让互信息尽可能地大,不关心互信息最终的取值,只关心去拉大 p(x,z) 和 p(x)p(z) 的过程。所以原文使用了另外一种计算方式JS散度。它定义为:
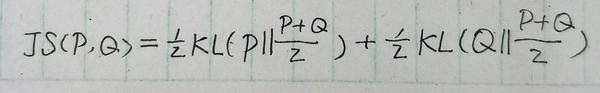
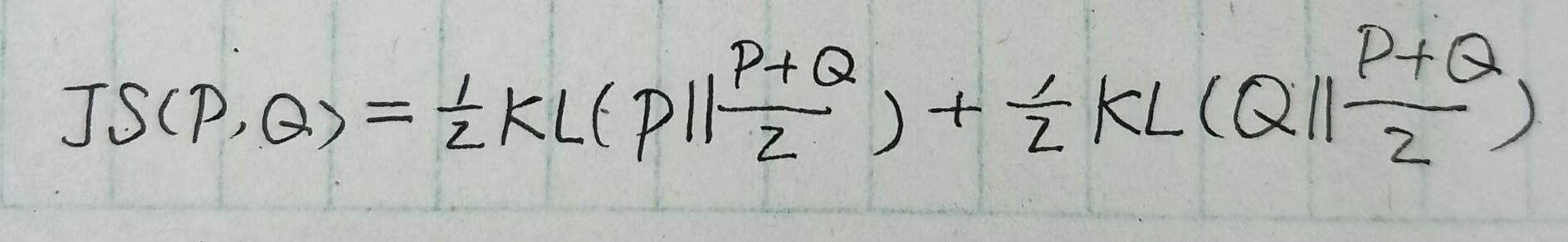
这时将目标函数改写为:
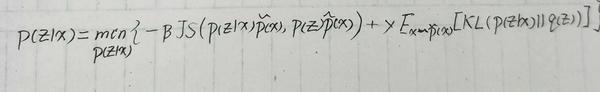
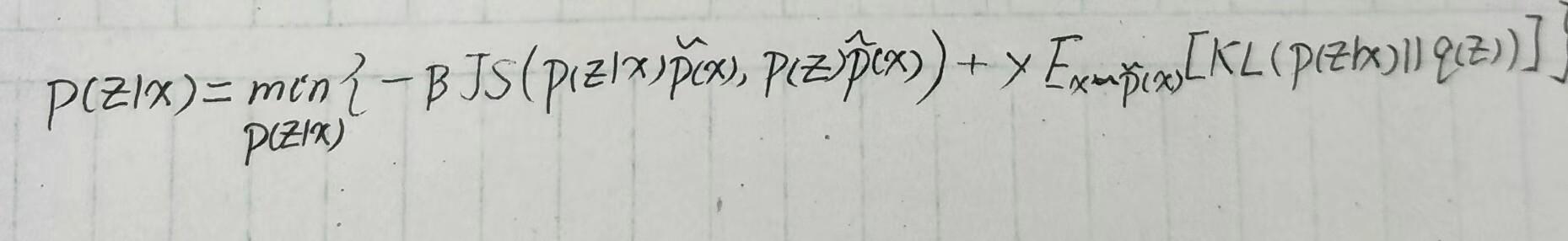
后面加速了,可能会有些许不适~~
为了攻克出互信息,我们使用了
局部变分法
来推JS散度,局部变分法式JS散度:
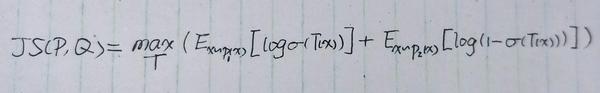
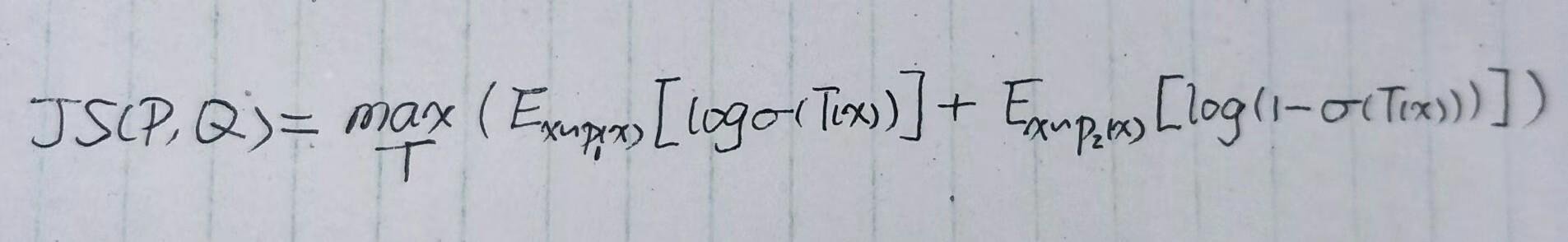
代入 p_1(x)=p(z|x)\tilde{p}(x) 和 p_2(x)=p(z)\tilde{p}(x) 得到:
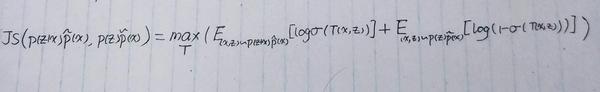

观察上式,这不就是NCE吗?不就是NLP中的负采样吗? 真实样本来自于 p(z|x)\tilde{p}(x) ,负样本来自 p(z)\tilde{p}(x) 。通俗说 x 及其对应的 z 视为一个正样本对, x 及随机抽取的 z 则视为负样本,然后最大化似然函数,等价于最小化交叉熵。 T(x,z) 就是上文(2)中提出的鉴别器。
到此理论部分已经推导完毕,后面的修修补补就是加上一个局部的互信息鉴别器 T_{2}(x,z) ,后面介绍模型的时候会说。
3 模型
3.1 通用模型
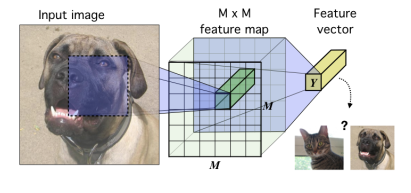
输入图像,经过CNN层得到M*M的特征图,接着池化等操作变成一维的特征向量,这个特征向量就是输出表征。也就是说原始图像变成了一维表征,然后用到后续的任务中。
3.2 DIM模型
DIM模型分为两部分,但是是一起训练的。第一部分:
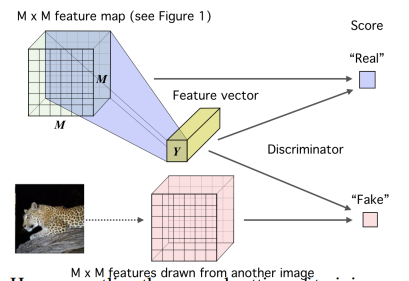
第一部分是全局特征鉴别器 T_1(x,z) 的训练,具体做法是将上文得到的特征向量分别与真实样本(正样本)和随机选取样本(负样本)计算互信息,然后打分。
第二部分就是局部互信息了:
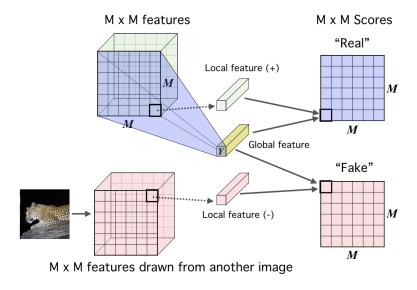
局部互信息做法和全局互信息类似,将上文中的特征向量和特征图张量的每一个局部特征向量送入到局部特征鉴别器 T_2(x,z) 中打分训练(其实就是一个二分类器)。
3.3 DIM的损失函数
通过上述的两部分完成了局部和全局的互信息最大化优化,那么我们就很容易得到它整体损失函数(也就是原文的公式(8)):
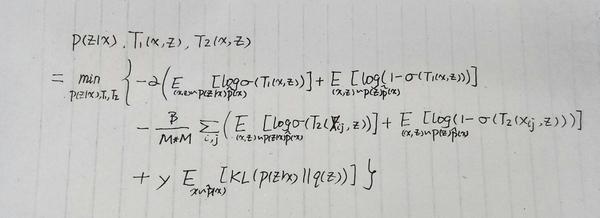
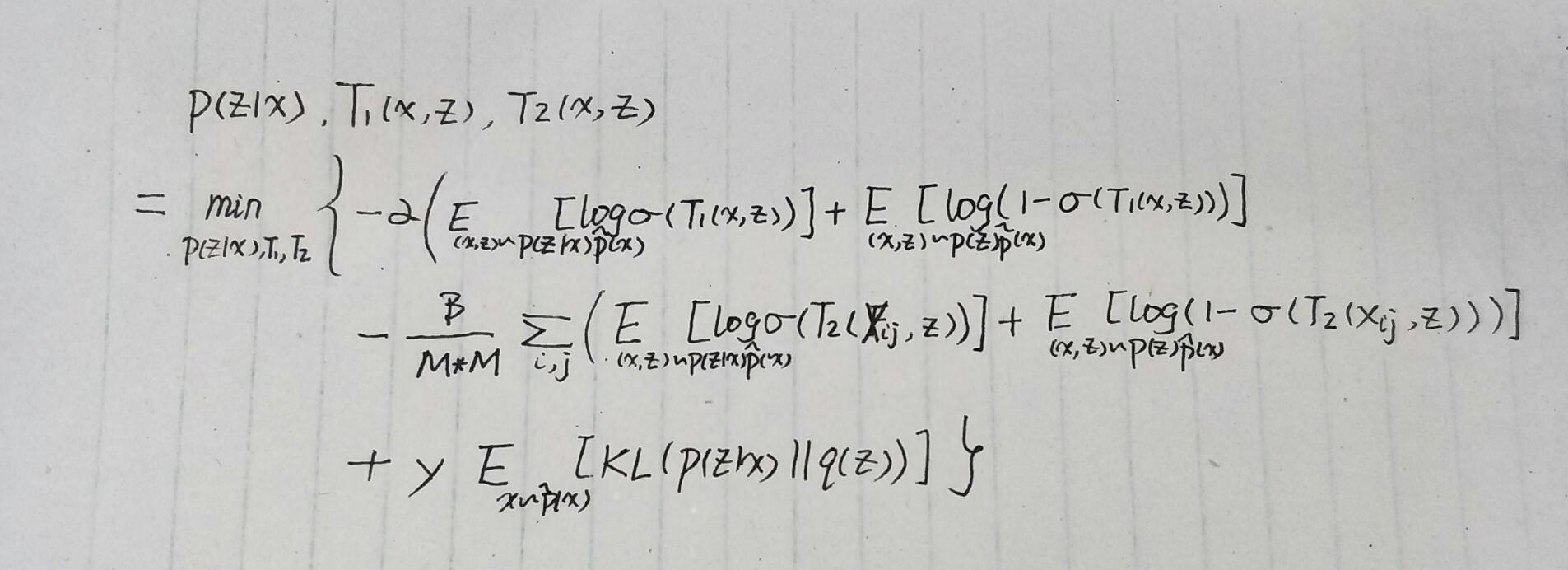
4 实验
4.1 实验数据集


4.2 实验结果
DIM(G)是只使用了全局互信息,DIM(L)是只是使用了局部互信息。然后与流行的无监督学习方法以及监督学习方法对比。
(1)在CIFAR10和CIFAR100中的实验结果:
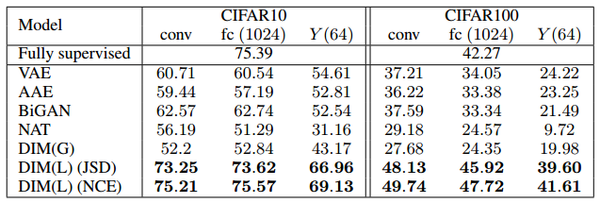
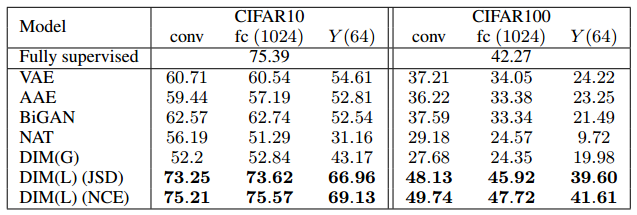
CIFAR10 和 CIFAR100 的分类准确率(top-1)结果。DIM(L)显著优于之前提出的所有其他无监督方法。此外,DIM(L)接近甚至超过具有类似架构的全监督分类器。具有全局目标的 DIM 表现与任务中的某些模型相似,但不如 CIFAR100 上的生成模型和 DIM(L)。表中提供全监督分类结果用于比较。
(2)在Tiny ImageNet和STL-10的数据集上的实验结果:
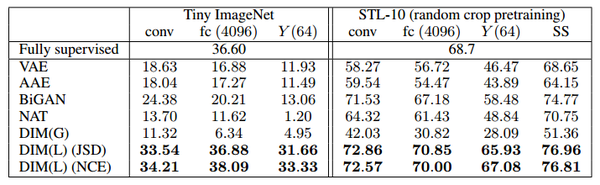
TinyImageNet和 STL-10 的分类准确率(top-1)结果。对于 TinyImageNet,具有局部目标的 DIM 优于所有其他模型,并且接近全监督分类器的准确率,与此处使用的AlexNet架构。
原文中还有其他的评估实验不一一列举,有兴趣可以看看原文,原文附录描述了模型详细的实现细节。 加入了局部互信息后,模型的分类能力简直恐怖。
