meta-learning区别于pretraining,它主要通过多个task来学习不同任务之间的内在联系,通俗点说,也即是通过多个任务来学习共同的参数。
举个例子,人类在进行分类的时候,由于见过太多东西了,且已经学过太多东西的分类了。那么我们可能只需每个物体一张照片,就可以对物体做到很多的区分了,那么人是怎么根据少量的图片就能学习到如此好的成果呢?
显然 ,我们已经掌握了各种用于图片分类的较巧了,比如根据物体的轮廓、纹理等信息进行分类,那么根据轮廓、根据纹理等区分物体的方法,就是我们在meta learning中需要教机器进行学习的学习技巧。
meta-learning主要有以下几个概念,理解了概念我们就更容易理解这个算法到底在干什么。
meta-learning主要分为两个阶段:
-
meta-train
:用来训练模型参数,使得模型能够学到不同任务中的共同参数
-
meta-test
:类似于fine-tuneing阶段,用来微调下游任务。
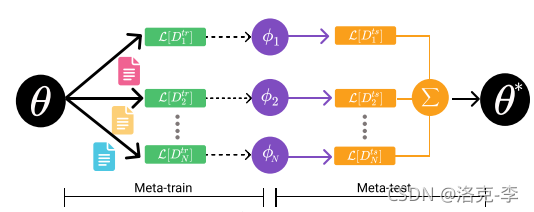
首先假设我们首先有数据集
D
,这个数据集有10个类别,每个类别有100个样本,共1000个样本数聚集。
我们把数据集进行分割,把100个样本分成3份,比例是1:4:5。这三份的样本数量为10,40,50。
-
N-way K-shot
:在meta-train阶段,假设实验中设置
5-way 10-shot
,也就是在每个任务task中抽样5个类别,每个类别10份数据,构成一个
support set
,用在
meta-train
阶段。这5个类别中,另外的40份数据为
query set
,可以用在
meta-test
阶段;而还剩10个类别的50份数据,用来进行微调任务。
MAML是用来实现meta-learning的一种算法。下面用例子来说明MAML的算法实现过程。
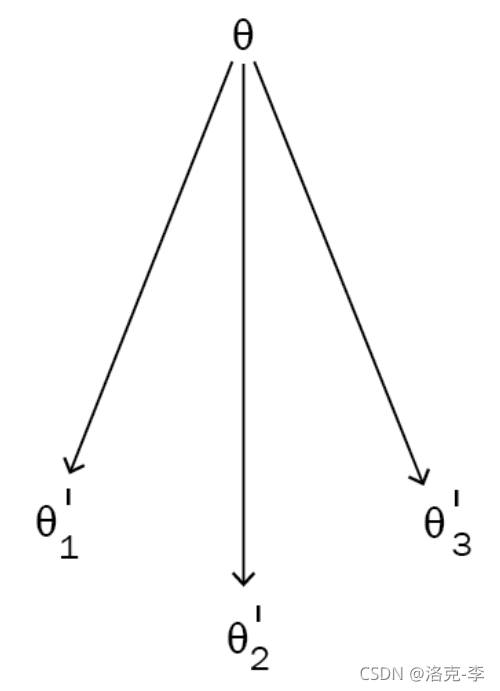
假设我们目前有3个tasks,分别为
def sample_points(k):
x = np.random.rand(k,50)
y = np.random.choice([0, 1], size=k, p=[.5, .5]).reshape([-1,1])
return x,y
x, y = sample_points(10)
print x[0]
print y[0]
输出结果:

利用简单的前馈神经网络作例子:
a = np.matmul(X, theta)
YHat = sigmoid(a)
MAML实现代码:
class MAML(object):
def __init__(self):
定义参数,实验中用到10-way,10-shot
self.num_tasks = 10
self.num_samples = 10
self.epochs = 10000
self.alpha = 0.0001
self.beta = 0.0001
self.theta = np.random.normal(size=50).reshape(50, 1)
def sigmoid(self,a):
return 1.0 / (1 + np.exp(-a))
def train(self):
for e in range(self.epochs):
self.theta_ = []
for i in range(self.num_tasks):
XTrain, YTrain = sample_points(self.num_samples)
a = np.matmul(XTrain, self.theta)
YHat = self.sigmoid(a)
loss = ((np.matmul(-YTrain.T, np.log(YHat)) - np.matmul((1 -YTrain.T), np.log(1 - YHat)))/self.num_samples)[0][0]
gradient = np.matmul(XTrain.T, (YHat - YTrain)) / self.num_samples
self.theta_.append(self.theta - self.alpha*gradient)
meta_gradient = np.zeros(self.theta.shape)
for i in range(self.num_tasks):
XTest, YTest = sample_points(10)
a = np.matmul(XTest, self.theta_[i])
YPred = self.sigmoid(a)
meta_gradient += np.matmul(XTest.T, (YPred - YTest)) / self.num_samples
self.theta = self.theta-self.beta*meta_gradient/self.num_tasks
if e%1000==0:
print "Epoch {}: Loss {}\n".format(e,loss)
print 'Updated Model Parameter Theta\n'
print 'Sampling Next Batch of Tasks \n'
print '---------------------------------\n'
最后输出结果:
model = MAML()
model.train()
1.[meta-learning] 对MAML的深度解析
2.https://github.com/sudharsan13296/Hands-On-Meta-Learning-With-Python
文章目录1.背景2.Meta-learning理解2.1 Meta-learning到底做什么2.2 MAML算法2.3 MAML算法步骤2.4 MAML代码分析和实现3.参考文章1.背景meta-learning区别于pretraining,它主要通过多个task来学习不同任务之间的内在联系,通俗点说,也即是通过多个任务来学习共同的参数。举个例子,人类在进行分类的时候,由于见过太多东西了,且已经学过太多东西的分类了。那么我们可能只需每个物体一张照片,就可以对物体做到很多的区分了,那么人是怎么根据少量
|| | | | | | | | | | | | | | [ ] | | | 真棒元学习| 使用Python进行动手元学习||
元学习与通用AI之间的关联的简要调查
联合学习的新兴趋势:从模型融合到联合X学习
多目标元学习
不断变化的机器人动力学和环境中的自适应电动机控制的元强化学习
CATCH:用于可转移架构搜索的基于上下文的元强化学习
MGHRL:分层强化学习的元目标生成
元图:通过元学习进行的少量射击链接预测|英特尔:registered:开发人员专区元图
进化神经体系结构搜索综述
神经网络中的元学习:一项调查
ES-MAML:简单的无粗麻布的元学习
通过子任务依赖项的自主推断进行元强化学习
通过元参数分区学习推荐
零镜头和少镜头面部反欺骗的学习元模型
从观测数据进行元强化学习
端到端低资源语音识别的元学习
具有无偏梯度聚合和可控元更新的联合学习
元学习与可区分的闭合
元学习算法MAML简介1.元学习(meta learning)2.模型无关元学习2.1 元学习问题建模2.2 MAML算法3.将MAML应用到回归分类任务上的算法流程参考资料
论文: Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks Chelsea
代码: https://github.com/cbfinn/maml
ICML2017的一篇论文,作者Chelsea Finn是斯坦福的老师,一步小心去作者主页看了下,MIT和
meta learning
K-shot learning
这种方法与转移学习非常相似,在转移学习中,先在ImageNet上训练了一个网络后对该网络进行微调可以轻松地学习具有更少数据的另一个图像数据集。
但二者区别在于,meta learning的训练目标是易于泛化,而迁移学习只是“偶然地”发生了作用,因此可能无法达到最佳效果。
确实,找到一个其中转移学习未能学习良好初始化的方法相当容易。 为此,我们需要研究一维正弦
一文入门元学习(Meta-Learning)(附代码)
写在前面:迄今为止,本文应该是网上介绍【元学习(Meta-Learning)】最通俗易懂的文章了( 保命),主要目的是想对自己对于元学习的内容和问题进行总结,同时为想要学习Meta-Learning的同学提供一下简单的入门。笔者挑选了经典的paper详读,看了李宏毅老师深度学习课程元学习部分,并附了MAML的代码。为了通俗易懂,我将数学推导和工程实践分开两篇文章进行介绍。如果看不懂,欢迎来捶我( )~~
如果大家觉得有帮助,可以帮忙点个赞或者收藏一
李宏毅的Lectures:https://www.youtube.com/watch?v=EkAqYbpCYAc
论文原文:https://arxiv.org/abs/1703.03400
一篇知乎笔记:https://zhuanlan.zhihu.com/p/66926599
用一句话概括MAML的灵魂,大概就是
(ICLR 2017) Optimization As a Model For Few-Shot Learning
Paper: https://openreview.net/pdf?id=rJY0-Kcll
Code: https://github.com/twitter/meta-learning-lstm
元学习Meta Learning,含义为学会学习,即learn to learn,带着对人类的“学习能力”的期望诞生的。Meta Learning希望使得模型获取一种 “学会学习” 的能力,使其可以在获取已有“知识”的基础上快速学习新的任务。
从传统学习引出元学习
传统的机器学习方法是针对一个特定的,一般是有大量数据的数据集 ,试图学习出一个预测模型 ,使得模型对于测试集上的数据的预测有最小的误差。这个思路在数据集 D
Meta-learning(元学习)方法是近期的研究热点,加州伯克利大学在这方面做了大量工作。这周阅读了相关论文,总结一下自己的知识。
论文题目:
1.Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks ;
2.One-S...
MATLAB是一种高级编程语言和环境,被广泛应用于科研、工程和数据分析领域。而meta-learning是一种机器学习的方法,旨在通过学习一系列不同任务的经验,来改善学习算法的性能。那么,MATLAB meta-learning是指在MATLAB环境下进行meta-learning的实践和应用。
在MATLAB中,可以利用丰富的机器学习工具箱和函数,实现不同的meta-learning算法。首先,可以使用MATLAB提供的数据预处理函数来准备输入数据,比如对数据进行清洗、归一化和特征选择等操作。然后,可以使用MATLAB的分类、回归或聚类算法,将数据分为训练集和测试集,并训练学习模型。
在meta-learning中,通常需要通过学习一系列不同任务的经验,来得到适用于新任务的学习模型。MATLAB提供了一些元学习框架和算法,如Adaptive Boosting、Gradient Boosting和Random Forest等。这些算法可以通过集成或组合基本学习算法,来改善整体学习性能。
使用MATLAB进行meta-learning的好处是,它提供了丰富的工具和函数,可以减少编程的复杂性,并实现高效的数据处理和模型训练。此外,MATLAB还支持可视化和结果分析工具,可以直观地展示模型的性能和预测结果。
总而言之,MATLAB meta-learning是指在MATLAB环境下实践和应用meta-learning的方法。通过使用MATLAB的机器学习工具箱和函数,可以实现数据预处理、模型训练和结果分析等操作,从而改善学习算法的性能。

