

【机器学习-因果推断】YLearn 官方文档上手小案例1 (Python)

写在前面:如果开发团队的大神有看到这个文章,希望你们抽空在估计器安排上因果森林——因为这个是AEA主席的作品,对于经济等学科来说实在太重要了。
YLearn 是国内团队推出的一个 机器学习+因果推断 包。其优点主要包括:
- 是目前本人见过整体框架最完善、清晰的包;
- 因果图DAG 分析识别的可操作性强;
- 提供其它一些小辅助功能。
缺点:
- 估计器就几种,太少,连因果森林 causal forest 都没有。
下面就跑一下官方给出的小案例(基于 因果树 causal tree ),并提供详细的说明。
1. 包的导入
import numpy as np
import matplotlib.pyplot as plt
from ylearn.estimator_model.causal_tree import CausalTree ## 本次使用的估计器是因果树
from ylearn.exp_dataset.exp_data import sq_data
from ylearn.utils._common import to_df ## ylearn 提供的很方便的数据框转换函数2. 构造训练数据
## 数据准备
n = 2000
d = 10
n_x = 1
y, x, v = sq_data(n, d, n_x)
y ## 2000x1
len(x) ## 2000x1
v.shape ## 2000x10
## 真实的干预效应
true_te = lambda X: np.hstack([X[:, [0]]**2 + 1, np.ones((X.shape[0], n_x - 1))])
data = to_df(treatment=x, outcome=y, v=v)
data ## 最终的数据集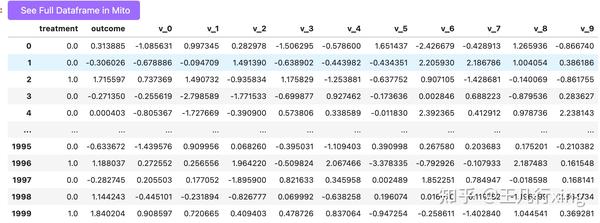

训练数据框包括:
- Y = outcome;
- T = Treatment;
- 其它X、W = v_0 - v_9
3. 构造测试数据
## 构造测试数据
v_test = v[:min(100, n)].copy()
v_test[:, 0] = np.linspace(np.percentile(v[:, 0], 1), np.percentile(v[:, 0], 99), min(100, n))
test_data = to_df(v=v_test)
test_data ## 100x10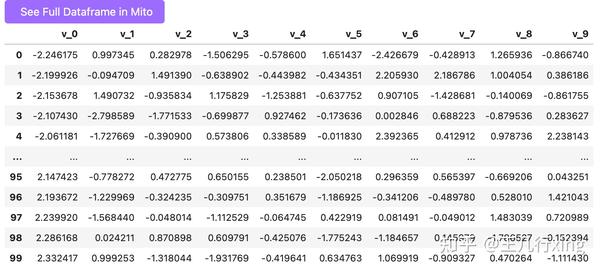

这里测试数据不包括 T = treatment 和 Y,只包括X和W。
4. 因果树的建模和拟合
## 因果树建模并拟合
outcome = 'outcome'
treatment = 'treatment'
adjustment = data.columns[2:]
#Index(['v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9'], dtype='object')
ct = CausalTree(min_samples_leaf=3, max_depth=5)