这里我们再讲一种和Bagging类似但是又不同的正则化方法:
Dropout
。 这是DNN中最常用也是最有效的正则化方法。
所谓的Dropout指的是在用前向传播算法和反向传播算法训练DNN模型时,一批数据迭代时,随机的从全连接DNN网络中去掉一部分隐藏层的神经元。
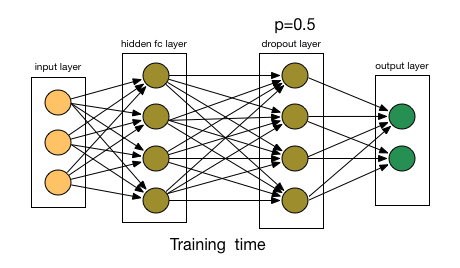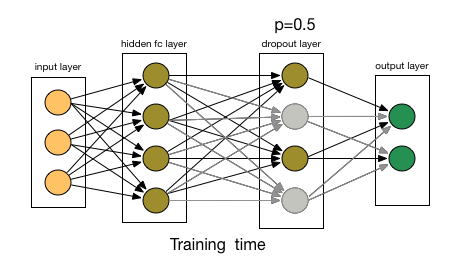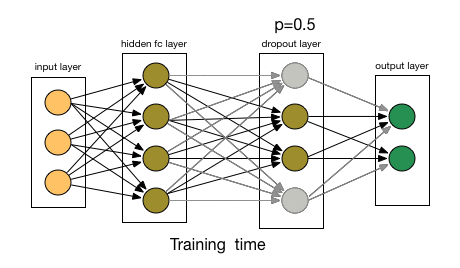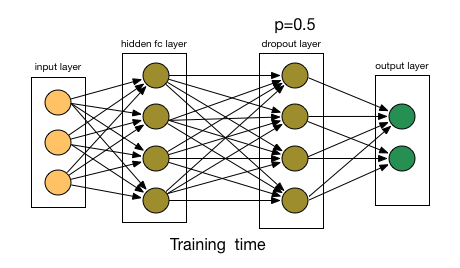
比如我们本来的DNN模型对应的结构是这样的:

在对训练集中的一批数据进行训练时,我们随机去掉一部分隐藏层的神经元,并用去掉隐藏层的神经元的网络来拟合我们的一批训练数据。如下图,去掉了一半的隐藏层神经元:

然后用这个去掉隐藏层的神经元的网络来进行一轮迭代,更新所有的
W
,
b
。当然,这次用随机的方法去掉部分隐藏层后的残缺DNN网络和上次的残缺DNN网络并不相同。
如下图所示:
总结下dropout的方法: 每轮梯度下降迭代时,它需要将训练数据分成若干批,然后分批进行迭代,每批数据迭代时,需要将原始的DNN模型随机去掉部分隐藏层的神经元,用残缺的DNN模型来迭代更新$W,b¥。每批数据迭代更新完毕后,要将残缺的DNN模型恢复成原始的DNN模型。
从上面的描述可以看出dropout和Bagging的正则化思路还是很不相同的。dropout模型中的
W
,
b
参数,相互之间是独立的。当然他们每次使用基于原始数据集得到的分批的数据集来训练模型,这点是类似的。
使用基于dropout的正则化比基于bagging的正则化简单,这显而易见,当然天下没有免费的午餐,由于dropout会将原始数据分批迭代,因此原始数据集最好较大,否则模型可能会欠拟合。
增强模型泛化能力最好的办法是
有更多的训练数据
,但是在实际应用中,更多的训练数据往往很难得到。有时候我们不得不去自己想办法能无中生有,来增加训练数据集,进而得到让模型泛化能力更强的目的。
对于我们传统的机器学习分类回归方法,增强数据集还是很难的。你无中生有出一组特征输入,却很难知道对应的特征输出是什么。但是对于DNN擅长的领域,比如图像识别,语音识别等则是有办法的。以图像识别领域为例,对于原始的数据集中的图像,我们可以将原始图像稍微的平移或者旋转一点点,则得到了一个新的图像。虽然这是一个新的图像,即样本的特征是新的,但是我们知道对应的特征输出和之前未平移旋转的图像是一样的。
举个例子,下面这个图像,我们的特征输出是5。

我们将原始的图像旋转15度,得到了一副新的图像如下:

我们现在得到了一个新的训练样本,输入特征和之前的训练样本不同,但是特征输出是一样的,我们可以确定这是5.
用类似的思路,我们可以对原始的数据集进行增强,进而得到增强DNN模型的泛化能力的目的。

