|
|
|


如何看待明星行为经济学家 Ariely 被发现疑似造假的事?
关注者
241
被浏览
117,818
登录后你可以
不限量看优质回答
私信答主深度交流
精彩内容一键收藏



杜克大学的教授,畅销书作者,Dan Ariely是真的明星经济学家。这篇出事的文章是发表在PNAS上的。
Shu, L. L., Mazar, N., Gino, F., Ariely, D., & Bazerman, M. H. (2012). Signing at the beginning makes ethics salient and decreases dishonest self-reports in comparison to signing at the end. Proceedings of the National Academy of Sciences , 109 (38), 15197-15200.
和保险公司合作的,发现如果让用户在填报行车里程的表格上方而不是下方签名,用户撒谎的概率更低。签名具有一定的道德提示,所以先签名,能够潜移默化的让人更诚实。
这个结论很有趣,公司真的实施起来几乎没有成本,听起来也非常有道理,数据也支持。所以就发表了。
但是现在被DataColada发现数据存在很多问题:
- 里程分布问题:
真的里程分布,一般来说是长尾的,类似于对数正态分布。
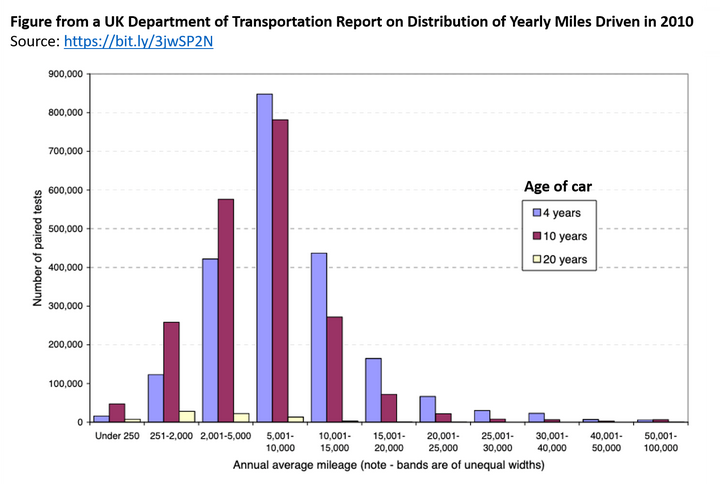
但是数据中分布是这样的:
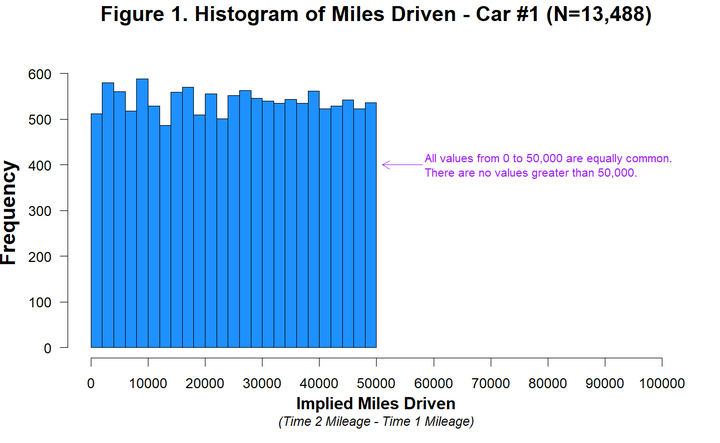
现实中的抽样几乎不可能抽出这种高度一致的结果。
2. 没有估算
正常来说,人们汇报的时候现喜欢取整,在1000,10000这样的数字会比较多。体现在数据上,真实数据最后一位是0的比例应该远远超过其他的,比如下图的左边。这篇文章的数据里面的基础数据很正常,但是更新的数据不正常。显示出成百上千的人完全不取整,直接精确的汇报自己的里程。左边是基础的,右边是更新的,这个差距表明更新的数据可能是有一个随机数生成器在作假。
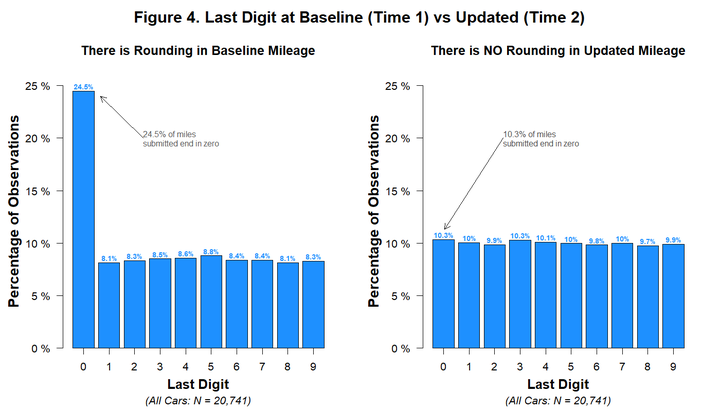
3. 数据重复
实验中的被试随机的看两种字体Calibri和Cambria,结果这两批人填写的里程数分布无比的相似:

这在现实中几乎是不可能发生的。
发现了这些疑点之后,联系作者。其余的四个作者要么说对数据不熟悉,没有进行数据处理工作,要么就说自己不负责这方面,但是都承认数据是有问题的。这时有一个卖队友的作者说Dan Ariely是负责数据的……这下有点尴尬了。
其实我怀疑这些人之前是知道数据有问题的,因为他们在2020年又发了一篇PNAS,推翻了自己以前的说法。所以发现一个结果,很有趣,发了PNAS,然后过几年推翻这个结果,又很有趣,又是一篇PNAS。
Kristal, A. S., Whillans, A. V., Bazerman, M. H., Gino, F., Shu, L. L., Mazar, N., & Ariely, D. (2020). Signing at the beginning versus at the end does not decrease dishonesty. Proceedings of the National Academy of Sciences , 117 (13), 7103-7107.
说到解决方法,建议学术界对『重复前人实验』和『检验已发表数据』给予一定的实在的激励。 别的激励也都是虚的,最好的就是在刊物每期留一篇到两篇的篇幅,专门发表对过去实验的重复和讨论。
经济学在过去其实不算是造假的重灾区,而是秀技巧的战场。因为经济学的数据很多都是现实中产生的,每个国家的GDP数字,人均可支配收入,这些数字如何造假?经济学过去的争议主要来自于p-hacking,也就是通过各种计量技术和对数据的处理,来获得统计上显著的结果,把自己的故事讲圆满了。
比如提出一个观点:一个地区历史上商业发达程度,会影响现代人和人之间的信任。
是不是感觉非常的『有洞见』?里面既包含了历史深度,又包含了商业契约、文明和信任之间的关系。学术课题其实也讲究吸引人的兴趣,一般来说大众感兴趣的,学术界也感兴趣,只是很多时候大众感兴趣的话题不太能够正规化成为一个符合学术范式的研究课题。而凡是能成功转换的,几乎个个都是顶刊。
故事讲的很完美,然后数据拿过来一做,发现商业发达程度和信任指数不显著…… 这怎么办呢?
那就可以重新定义地区,比如有的国家之前在丝绸之路上,现在不在了,那么这个国家是不是可以进入到样本里面就比较灵活,调一调国家范围,换一换度量的单位和控制变量,然后……显著了!那这就是一篇有理论,有数据证明的好文章可以投稿了。
这种文章不是造假,甚至于标准选择也不能说有问题,毕竟如果没有公认标准的话,自己就是标准的制定者,有一定的灵活范围。只是称之为『结果不太稳健』。经济学家之间也喜欢调侃这种行为。
但是后来经济学也越来越多元化。尤其是行为经济学引入了『做实验』的方法。行为经济学和心理学一样,做实验的样本都是『人』。而人是比较不可控的。
这个和物理、化学的实验还不一样。物理和化学的实验理论上是一定可以复现的,如果不能复现,要么是实验室条件干扰,要么是作假。但是心理行为的实验,人的行为倾向是A还是B,就算后来再做一次实验结果不一样,也不能断定是作假,因为没准人家找来的那一批人类样本就是这样的呢?
所以要认定行为心理的实验作假是很难的,因为实验者只要一口咬定自己做的就是这样的,那也没办法。但是这次数据作假实在是太假了,类似于用PS来P细胞,被DataColada抓了一个正着, 对Dan Ariely来说,这将是他学术生涯的一次严重的危机。
Dan Ariely有回应了,这个回应可以说是对他伤害最小的一个选择。那就是说数据的收集和整理都是保险公司做,他完全没有参与,他和合作者所做的仅仅就是拿到数据之后分析。
所以如果有数据造假,那也是保险公司造假,和他本人无关。同时他也承认他是和保险公司合作的唯一联系人。
在这个事情上很难公然撒谎,所以我倾向于认为事实发生至少表现上确实如此——这里面和普通的实验室实验有区别,实验室实验自己是没法洗的,因为自己和助手肯定是参与了的;但是因为是田野实验(field experiment),也就是和保险公司合作的,在真实世界做的真实的实验,那么保险公司怎么做,理论上确实是学者无法控制的。当然,真实是不是完全没有参与,连私下的联系也没有,这些没有书面证据的猜测,事情也过去很多年了,也只能停留在猜测上,不可能用莫须有的罪名去指责其他人。
虽然可以解释过去,但是我觉得这事情依然是有疑点的。保险公司为什么会有动机在田野实验上作假?他们又不要发论文,他们希望知道的是到底哪种形式对自己能获得客户的真实信息有利不是么?为什么要修改数据到一个可以发表的结果?
不过无论如何,如果没有进一步的反转——比如保险公司跳出来说没有,Ariely参与了——否则的话,这次危机Ariely还是能过去的。不过他过去的文章,和将来的文章肯定会被重点的看顾,一般来说,大学者不作假则已,作假肯定不止一次。所以如果有人再发现他其他文章有作假的痕迹,那么就真的名声扫地了。