


使用正则表达式

正则表达式(regular expression)简称regex,是一种文本模式的描述方法,它让你可以指定要查找的”模式“,相比之下,按Ctrl+F输入要查找的词只是匹配你输入的字符串,只能用于精确查找,对于像”找出邮件中出现的所有邮箱名和银行卡号“这种问题就完全无能为力。
I. re.search()方法
II. re.findall()方法
III. re.match()方法
IV. 用正则表达式匹配更多模式
(1)利用括号分组
(2)用管道字符匹配多个分组
(3)用问号实现可选匹配
(4)用星号匹配零次或多次
(5)用加号匹配一次或多次
(6)用花括号匹配特定次数
V. 贪心匹配和非贪心匹配
VI. 字符分类
VII. 插入字符和美元字符
VIII. 通配字符
IX. 点-星匹配所有字符
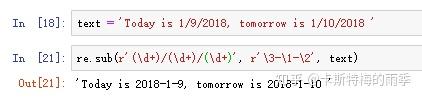
X. 用sub()方法替换字符串
XI. re.DOTALL、re.VERBOSE、re.IGNORECASE
以一个查找电话号码的例子作为开头:


上面分别使用了re.compile().search()、re.search()和re.findall()三种方法来搜索目标字符串中的电话号码,详细的讲解留到后面,暂时不深究。
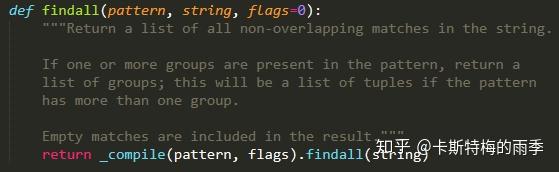
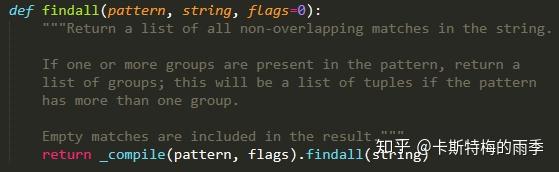
再打开re.py,我们发现re.search()和re.findall()方法内部都调用了re.compile()中的_compile()方法,这里要说的其实就是我们完全可以用re.search()取代传统的re.compile().search(),用re.findall()取代re.compile.findall():




I. re.search()方法
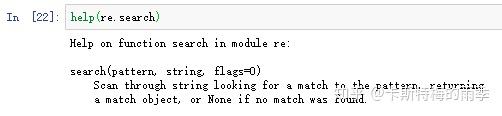
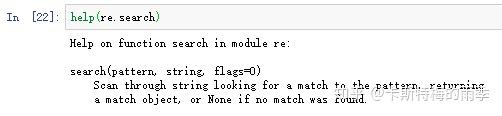
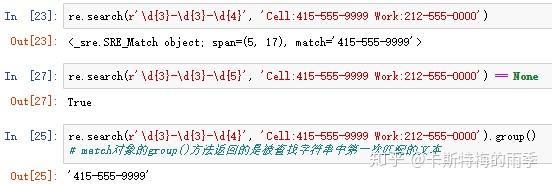
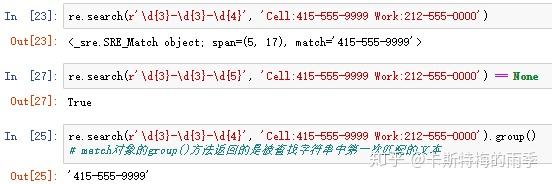
re.search()方法对应被查找字符串中第一次出现的匹配文本,返回一个match对象;如果被查找字符串中没有匹配的文本,则返回None
用re.compile()实现同样的效果明显要繁杂一些:


II. re.findall()方法


re.findall()方法对应被查找字符串中所有的匹配文本,返回一个 字符串的列表 或 字符串的元组的列表, 具体取决于分组的数量:如果没有分组或分组数为1,返回一个字符串的列表;如果分组数大于1,则返回一个字符串的元祖的列表。


当需要提取某些内容的时候,可以用小括号将内容括起来,这样就不会得到不相干的信息:


III. re.match()方法
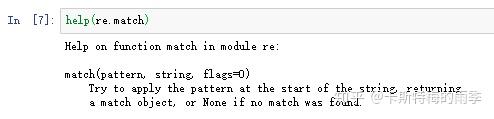
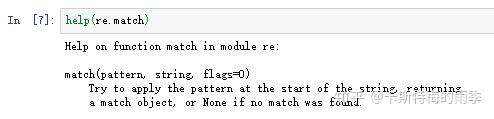
re模块还有一个match()方法,用于在字符串的 开头 匹配正则表达式,如果能匹配,返回一个match对象,如果不能,返回None


IV. 用正则表达式匹配更多模式
(1)利用括号分组
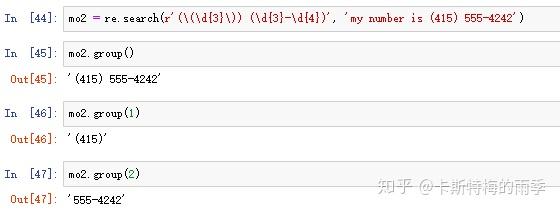
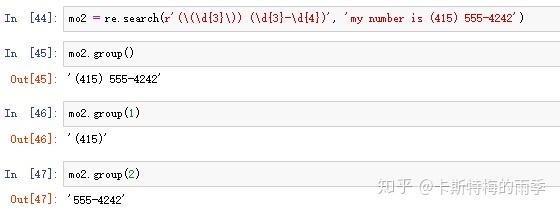
如果想要把区号从电话号码中分离,可以在正则表达式字符串中添加括号来创建分组,如(\d{3})-(\d{3}-\d{4}),正则表达式中第一对括号是第一组(数字1),第二对括号是第二组(数字2),以此类推。
- 想group()传入1或2——返回匹配文本的不同部分
- 向group()传入0或不传入参数——返回整个匹配的文本
- 如果想要一次获得所有分组,就用groups()方法,返回一个多个字符串的元组


匹配括号
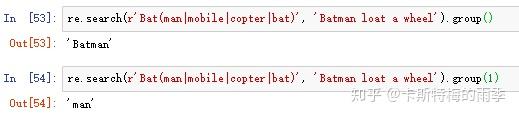
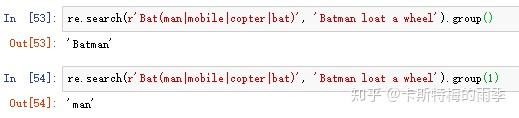
(2)用管道字符匹配多个分组
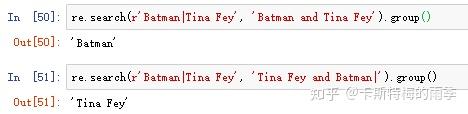
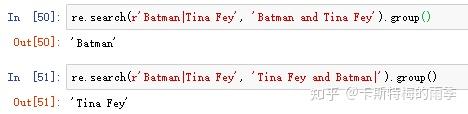
字符'|'称为管道字符,匹配许多表达式中的一个时,第一次出现的匹配文本,将作为match对象返回(换言之,search()方法返回的match对象对应的只是被查找字符串中第一次匹配的文本,而多个表达式只是看谁才是那个第一次匹配的文本)
管道字符另一种形式的用法:
如果匹配真正的管道字符,就用倒斜杠转义,即\|
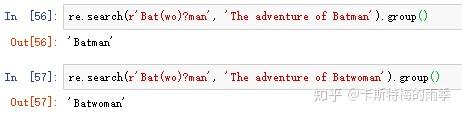
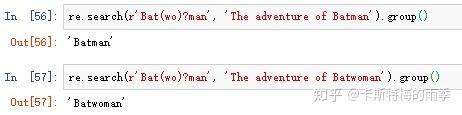
(3)用问号实现可选匹配
可选匹配:就是说,想匹配的模式是可选的,不论这段文本在不在,正则表达式都会认为匹配
字符?表明它前面的分组在这个模式中是可选的,正则表达式将匹配这个问号之前的分组零次或一次
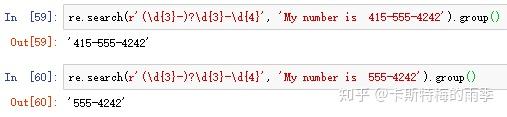
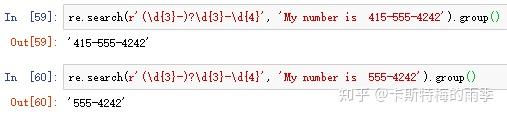
如果要匹配真正的问号,就使用转义字符\?
(4)用星号匹配零次或多次
字符*表明它前面的模式将出现零次或多次


如果要匹配真正的*,就在正则表达式的星号字符前加上倒斜杠,即\*
(5)用加号匹配一次或多次
字符+表明它前面的分组在这个模式中将出现一次或多次


(6)用花括号匹配特定次数
- 如果想要一个分组(不一定得是分组)重复特定次数,就在正则表达式中该分组的后面,跟上花括号包围的数字,如(Ha){3}
- 除了一个数字,还可以指定一个范围,即在花括号中写下一个最小值、一个逗号和一个最大值,如(ha){3,5}
- 也可以不写花括号中的第一或第二个数字,不限定最小值或最大值,如(Ha){3,}、(Ha){,5}

V. 贪心匹配和非贪心匹配
- 贪心匹配:正则表达式在有二义的情况下,会尽可能匹配最长的字符串
- 非贪心匹配:匹配尽可能最短的字符串,即在结束的花括号后面跟一个问号
Python的正则表达式默认是”贪心“的,这表示在有二义的情况下,会尽可能匹配最长的字符串。
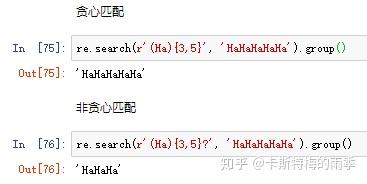
所以,问号在正则表达式中有两种含义:声明非贪心匹配或表示可选的分组。具体的含义要视情况而定。
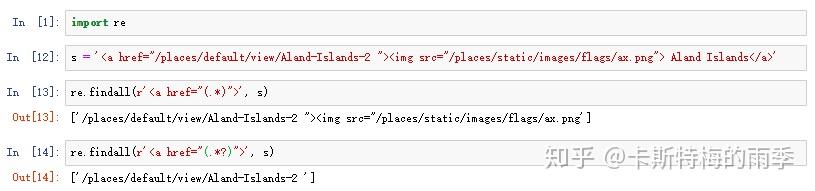
一种常用来表示“非贪心匹配”的正则表达式字符串是.*?
举个例子:
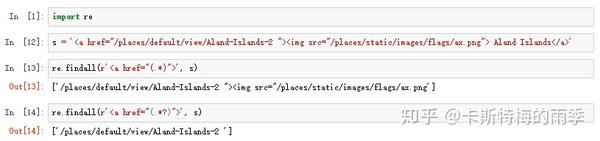
VI. 字符分类
常用字符分类的缩写代码:
缩写字符分类 表示
\d 0-9的任何数字
\D 除0-9的数字之外任何字符
\w 任何字母、数字或下划线(可以认为是匹配‘单词’字符)
\W 除字母、数字和下划线以外的任何字符
\s 空格、制表符或换行符(可以认为是匹配‘空白’字符)
\S 除空格、制表符和换行符之外的任何字符字符分类有助于缩短正则表达式,如(0|1|2|3|4|5)可以写成[0-5]
可以用方括号定义自己的字符分类:


可以使用短横表示字母或数字的范围。


字符分类的方括号中,普通的正则表达式符号不会被解释,也就是说,不需要在.、*、?或()等字符前面加上倒斜杠转义
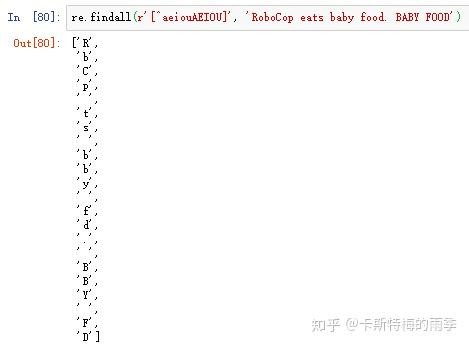
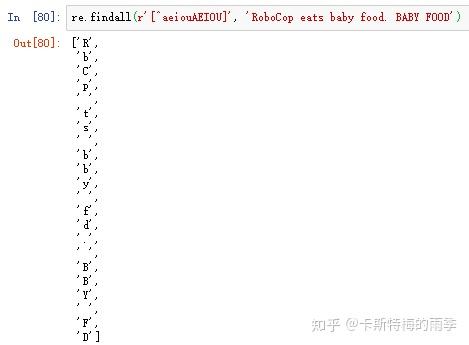
通过在字符分类的左方括号后加上一个插入字符(^),就可以得到”非字符类“(匹配不在这个字符分类中的所有字符)
VII. 插入字符和美元字符
- 正则表达式的开始处使用插入符号(^),表明匹配必须发生在被查找文本的开始处
- 正则表达式的末尾使用美元符号($),表明该字符串必须以这个正则表达式的模式结束
- 同时使用^和$,表明整个字符串必须匹配该模式,只匹配该字符串的某个子集是不够的


VIII. 通配字符
在正则表达式中,.(句点)字符称为”通配符“,它匹配除了换行之外的所有字符。


IX. 点-星匹配所有字符
可以用点-星(.*)表示”任意文本“,句点字符表示”除换行外所有单个字符“,星号字符表示”前面的字符出现零次或多次“


点-星总是使用”贪心“模式,他总是匹配尽可能多的文本,要用”非贪心“模式匹配所有文本,就使用点-星和问号。
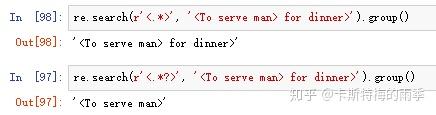
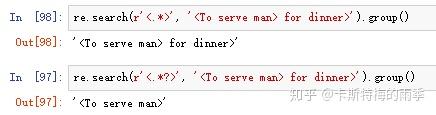
也可以将.*?搭配其他字符使用
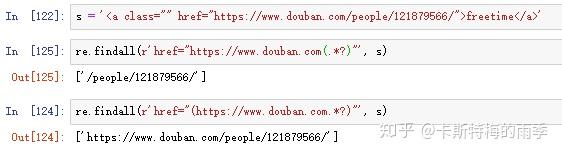
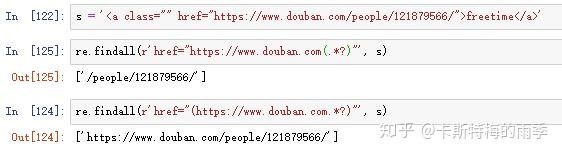
X. 用sub()方法替换字符串


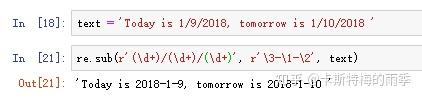
re.sub(正则表达式, 用于取代大字符串中发现的匹配的字符串,大字符串),用新字符串替换旧字符串中被发现的匹配。


如果需要使用匹配的文本本身作为替换的一部分,在sub()的第二个参数中,可以输入\1、\2、\3......表示”在替换中输入分组1、2、3......的文本“


XI. re.DOTALL、re.VERBOSE、re.IGNORECASE
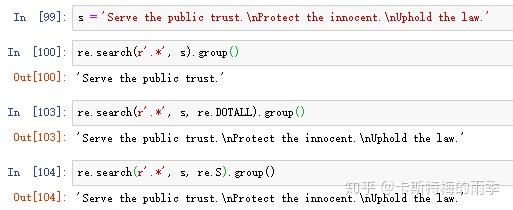
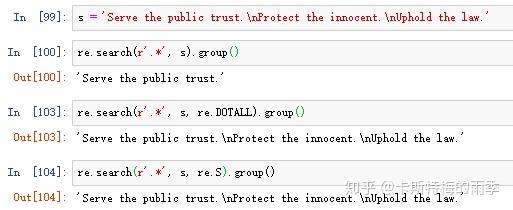
(1)向re.search()、re.findall()传入re.DOTALL或re.S,作为第三个参数,让句点字符可以匹配换行
点-星将匹配除换行外的所有字符,通过传入re.DOTALL / re.S作为re.search()或re.findall()的第三个参数,可以让句点字符匹配所有字符,包括换行符。
(2)向re.search()、re.findall()传入re.VERBOSE,作为第三个参数,忽略正则表达式字符串中的空白符和注释
phoneRegex = re.compile(r'''
(\d{3}|\(\d{3}\))? #area code
(\s|-|\.)? #seperator