|
|
|


目前语音情感识别的发展前景?
关注者
134
被浏览
87,223
16 个回答

2019年4月19日更新:
马上要毕业了,以后就要跳出情感识别的坑了,这可能是我最后一次更新这个回答了。ps: 这个回答也是我在贵乎上最用心的回(guang)答(gao)~
我们工作的假设就是情感的稀疏性。语音和视频中的情感信息属于稀疏信息。并非语音中的所有时刻或者视频中的所有帧都包含情感信息。如果能够利用到这种稀疏性并按照信号不同位置与情感的相关性自适应地分配不同的权重,就能够设计出更精致,更高效的系统。佐治亚理工李锦辉老师(李老师是IEEE FELLOW,语音领域顶级大佬)认为目前关于情感的研究都不够深入,都只停留在表面,目前都把情感当成一个分类任务来进行。李老师认为,更精细地考虑,一段视频或语音中不同时段其情感状态可能不一样,因此我们应该把情感作为一个检测任务,检测每个时刻起情感状态的变化。诚然,这种方案目前难以实现,因为现在主流的情感数据集都是一个语音或视频只有一个情感标签。我们认为利用到情感的稀疏性,检测语音或视频不同位置与情感的相关性,也是我们更加靠近情感检测研究的重要一步,并为此项研究提供基础与启发。
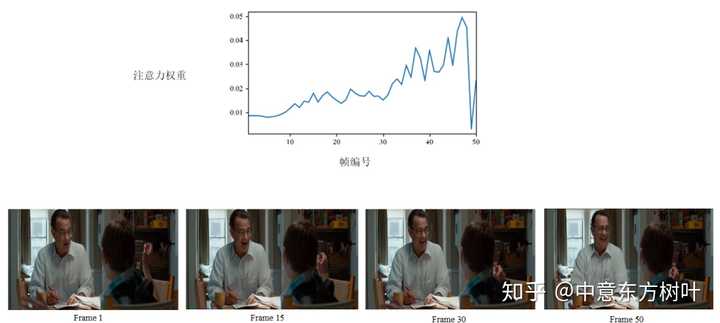
我们之前的工作集中在语音情感识别领域,希望通过注意力机制检测出和情感更相关的频谱区域。现在我们将这种注意力机制扩展到视频信号的情感识别上,通过注意力机制检测出和情感更相关的视频帧,然后通过双线性的方法融合语音和视频特征。从目前来看,我们的系统做到了音视频融合情感识别最好的结果。而且注意力机制学到的结果也非常有意思,比如这个样例中这个男性笑的越来越开心,我们的注意力机制学到的权重也呈现一个逐渐变大的趋势。
大家感兴趣可以看看我们这篇paper:
最后:情感有风险,入坑需谨慎啊,做情感是真的不好找工作。。。
~~~~~~~~~~~我是分割线~~~~~~~~~~~
其实就像 @王赟 Maigo 提到的,这个领域挺无聊的,没有突破性的进展,主要原因我认为应该是:
- 情感这个label太主观了,类别之间没有特别硬性的边界
- 目前的语音情感数据集太小
之前佐治亚理工的李锦辉老师就建议语音情感任务应该做检测,而不是简单的识别。我们目前是基于注意力机制希望通过注意力机制检测出跟语音情感更加相关的频谱区域,如果感兴趣可以看看我们的paper(打个小广告~):
最后,希望大家能多多引用,拯救0引用惨剧~~~

就我个人观点来说,我觉得情感识别的研究挺没意思的 = =
没意思的一个方面,是识别方法。现在的套路方法,就是大规模提取特征,然后用深度学习做分类或者回归。实在是太套路了。
另一个方面,就是在数据量有限的情况下,能识别的情感类型实在是很有限。一般的研究,都脱不开喜、悲、怒、惊、惧这几个传统类别。心理学上有把情感放在二维或三维坐标系下的理论,坐标轴一般包括 valence、arousal、dominance 这几维。其中 valence 表示情感是正面的还是负面的,arousal 表示人在这种情感下是激动还是抑制,dominance 表示人在这种情感下感觉强大还是弱小。由此,可以把情感的分类转换成「预测情感的坐标」这样的回归问题,但由于数据有限,不足以覆盖整个空间,所以也很难识别出训练数据中没有的复杂情感。
我的了解可能比较有限,如果有谁了解情感识别中比较有意思的课题,欢迎告诉我~