|
|
|

本文介绍 云原生数据仓库AnalyticDB MySQL版 的功能特性。
计算引擎
AnalyticDB MySQL版 支持Spark、XIHE MPP和XIHE BSP三种计算引擎。
Spark引擎
湖仓版(3.0) 采用多语言可编程计算引擎,完全兼容开源Spark接口,支持应用无缝迁移,适合SQL无法满足的复杂离线处理(ETL)场景和机器学习场景。
XIHE MPP引擎
采用MPP计算架构,调度粒度为整个查询的所有任务。计算过程采用pipeline流式计算,满足低延迟的交互式分析(Ad-hoc)场景。
XIHE BSP引擎
采用批计算架构,通过DAG进行任务切分,分批调度,满足有限资源下大数据量计算。XIHE BSP引擎支持计算数据落盘,适用于计算量大,吞吐高的复杂分析场景。资源按量收费,每个查询独享计算资源,隔离性强,不同查询间不会互相干扰。具备很强的Failover能力,支持Task粒度失败重试。
XIHE BSP引擎暂不支持UDF和写Hudi表。
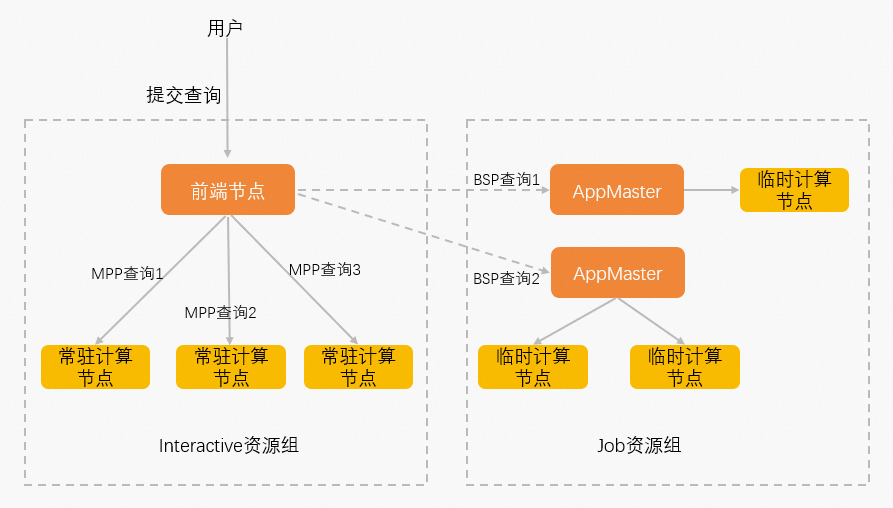
XIHE MPP和XIHE BSP对比
用户在提交查询到前端节点时,如果指定Interactive型资源组,则查询在常驻计算节点中以XIHE MPP方式执行;如果指定Job型资源组,则查询在临时计算节点中以XIHE BSP方式执行。
|
对比项 |
XIHE MPP |
XIHE BSP |
|
资源组 |
Interactive型资源组。 |
Job型资源组。 |
|
响应时间 |
毫秒级。 |
秒级或分钟级。 |
|
适用场景 |
RT敏感、高QPS的查询。 |
RT不敏感、大数据量吞吐的查询。 |
|
隔离性 |
资源组级别隔离。 |
查询级别隔离。 |
|
SQL语法 |
无差异。 |
|
存储引擎
玄武分析型存储(C-Store)
提供高可靠、高可用、高性能、低成本的企业级数据存储能力,是实现高吞吐实时写入、高性能实时查询的基础支撑。
Hudi低成本存储
湖仓版(3.0)基于低成本的OSS存储,提供开放标准的Hudi格式,支持近实时的增量数据处理能力。
连接
AnalyticDB MySQL 支持以下连接方式。
|
连接方式 |
文档 |
|
MySQL命令行 |
|
|
业务系统 |
|
|
客户端 |
DBeaver 、 DBVisualizer 、 Navicat 和 SQL WorkBench/J 。 |
|
BI工具 |
FineBI 、 Quick BI 、 永洪BI 、 有数BI 、 DataV 、 Tableau 、 QlikView 、 FineReport 、 Power BI 和 Smartbi 。 |
安全性
白名单
默认情况下, AnalyticDB MySQL版 集群拒绝所有连接和访问。要访问 AnalyticDB MySQL 集群,您可以添加客户端IP地址或地址段到白名单。详情请参见 设置白名单 。
SQL审计
SQL审计实时记录了数据库DML和DDL操作信息,方便您进行故障分析、行为分析、安全审计等,提高了数据库的安全性。详情请参见 SQL审计 。
云盘加密
您可以在创建 AnalyticDB MySQL版 集群时开启云盘加密功能,开启后,系统会基于块存储对整个数据盘进行加密,即使数据备份泄露也无法被解密,保护数据安全。详情请参见 云盘加密 。
访问控制
访问控制RAM(Resource Access Management)是阿里云提供的权限管理系统,用于管控不同RAM用户对云资源的访问权限。RAM用户创建 AnalyticDB MySQL版 集群后,仅允许该RAM用户和所属阿里云账号查看和管理该集群。如果您的组织里有多个用户需要使用 AnalyticDB MySQL 集群,您可以创建多个RAM用户,并授予RAM用户查看或管理 AnalyticDB MySQL 集群的权限。详情请参见 RAM用户与权限 。
数据库权限控制
数据库账号用于操作数据库,例如创建或删除数据库、创建或删除表、创建或删除视图、插入或变更数据、查询数据等。数据库账号分为高权限账号与普通账号。高权限账号可为普通账号授予不同级别(包括集群级别、数据库级别、表级别、列级别)的操作权限。详情请参见 账号类型 和 数据库权限模型 。
监控报警
AnalyticDB MySQL版 提供集群性能指标数据,方便您查看集群节点的健康状态和性能。详情请参见 查看监控信息 。同时, AnalyticDB MySQL 的报警功能支持实时监控集群CPU使用率、磁盘使用率、IOPS使用率、查询耗时以及数据库连接数等指标。如果指标超过设定的阈值,系统将自动给相关联系人发送报警通知。详情请参见 设置报警规则 。
备份恢复
AnalyticDB MySQL版 支持周期性的全量备份和日志备份,可以有效防止数据丢失。
全量备份
全量备份将集群全量数据快照压缩后存储在其它离线存储介质的方式。基于备份集的全量恢复采用集群克隆的方式,通过下载远程存储备份集的方式将数据恢复到一个新集群中。详情请参见 管理备份 。
日志备份
日志备份通过集群内多节点并行上传Redo日志到OSS的方式来保存实时日志,通过一个完整的全量备份以及后续一段时间的Redo日志,可以将一个新集群恢复到任意时间点,保证了这段时间的数据安全性。详情请参见 管理备份 。
备份恢复
AnalyticDB MySQL版 支持全量恢复和时间点恢复。备份恢复采用集群克隆的方式,每次恢复会生产一个新的集群,同时恢复数据将被下载并导入到该集群中。详情请参见 克隆集群 。
智能诊断优化
库表结构优化
库表结构的设计和优化对数据库整体使用成本和查询性能影响显著。 AnalyticDB MySQL 将持续收集SQL查询的性能指标及SQL查询使用到的数据表、索引等信息,并进行算法统计分析,自动给出调优建议,并支持一键应用调优建议,减少手动调优的负担。详情请参见 库表结构优化 。
SQL Pattern
SQL Pattern是依托于全量且实时的SQL而产生的。通过聚合相似SQL为SQL Pattern,对SQL Pattern进行诊断和分析,可以有效提升智能诊断的效率。SQL Pattern的诊断结果可以成为数据库优化的有效依据。详情请参见 SQL Pattern 。
SQL诊断
AnalyticDB MySQL 的SQL诊断功能分别统计SQL查询的查询级别、Stage级别和算子级别的信息,并基于统计信息,提供诊断结果与调优建议。详情请参见 SQL诊断功能介绍 。
导入导出
您可以将数据从其他数据库、OSS、OTS、HDFS、MaxCompute、Kafka、SLS导入 AnalyticDB MySQL ,也可以导出 AnalyticDB MySQL 的数据到其他数据库、OSS、HDFS、MaxCompute。详情请参见 数据导入概览 和 数据导出概览 。
数据接入
数据源管理
云原生数据仓库AnalyticDB MySQL版 湖仓版(3.0) 支持创建Kafka、SLS和Hive数据源。每个同步或迁移任务都需要一个数据源,数据源可以在不同同步或迁移任务之间复用,简化对重复链路创建的复杂度。数据源管理功能支持新增、查询、修改、删除数据源。
数据同步
云原生数据仓库AnalyticDB MySQL版 湖仓版(3.0) 支持创建Kafka和SLS数据同步链路,通过同步链路从指定时间位点,实时同步Kafka和日志服务LogStore中的数据至 湖仓版(3.0) ,以支持近实时产出、全量历史归档、弹性分析等需求。详情请参见 通过数据同步功能同步Kafka数据至湖仓版 和 通过数据同步功能同步SLS数据至湖仓版 。
数据迁移
云原生数据仓库AnalyticDB MySQL版 湖仓版(3.0) 支持创建Hive数据迁移任务,通过迁移链路将Hive数据导入OSS。详情请参见 通过数据迁移功能迁移Hive数据至湖仓版 。
元数据发现
元数据发现功能可以自动发现与 云原生数据仓库AnalyticDB MySQL版 湖仓版(3.0) 集群相同地域下OSS的Bucket和数据文件,并自动创建和更新数据湖元数据。详情请参见 通过元数据发现导入至湖仓版 。
数据管理
云原生数据仓库AnalyticDB MySQL版 湖仓版(3.0) 控制台提供了可视化的集群库表管理。支持展示库、表和视图的信息。详情请参见 数据管理 。
作业开发
云原生数据仓库AnalyticDB MySQL版 湖仓版(3.0) 提供开源的Spark引擎和 AnalyticDB MySQL 自研的XIHE引擎,通过选择不同的引擎实现不同的作业开发方式。详情请参见 作业开发 。
作业调度
云原生数据仓库AnalyticDB MySQL版 湖仓版(3.0) 具备离线SQL应用、Spark应用的作业调度能力,帮助您完成复杂的ETL数据处理。详情请参见 湖仓版作业调度 。
SQL
XIHE SQL
执行XIHE SQL时,使用 AnalyticDB MySQL 自研的XIHE引擎,高度兼容MySQL协议。XIHE SQL支持语法、函数及数据类型如下。
|
类别 |
文档 |
|
DDL |
|
|
DML |
INSERT INTO 、 INSERT OVERWRITE SELECT 、 INSERT ON DUPLICATE KEY UPDATE 、 INSERT SELECT FROM 、 REPLACE INTO 、 REPLACE SELECT FROM 、 UPDATE 和 DELETE 。 |
|
DQL |
SELECT 。 |
|
DCL |
CREATE USER 、 RENAME USER 、 DROP USER 、 GRANT 和 REVOKE 。 |
|
函数 |
控制流函数 、 算术运算符 、 数值函数 、 日期和时间函数 、 字符串函数 、 正则函数 、 位函数和操作符 、 操作函数 、 空间关系函数 、 访问器函数 、 空间构造函数 、 JSON函数 、 窗口函数 、 聚合函数 、 可变长二进制函数 、 CAST函数 、 Roaring Bitmap函数 和 漏斗留存函数 。 |
|
数据类型 |
Spark SQL
AnalyticDB MySQL 湖仓版(3.0) 支持Spark引擎,完全兼容开源Spark接口。您可以使用Spark SQL操作数据湖。详情请参见 开源社区Spark SQL参考文档 。