


6个Python库解释机器学习模型并建立信任

在机器学习模型中建立信任的案例
全球道路上大约有12亿辆汽车。这是一个令人毛骨悚然的问题-您认为实际上有多少驾驶员了解车辆的内部运行情况?
正如您可能已经猜到的,答案只有少数几个人。我们不需要了解驾驶车辆的内部操作。因此,对于我们大多数人来说,这辆车是一个黑匣子,但它确实为驾驶员做好了工作。但是设计和制造车辆的人呢?他们需要彻底了解来龙去脉。
这正是我们使用 机器学习模型的方式。 非数据科学的受众通常可能不需要知道机器学习算法是如何工作的,但是我们数据科学家应该!实际上,您经常会遇到客户和利益相关者,要求您对机器学习模型如何达到最终结果进行解释。


数据科学家不能不说自己使用了复杂的 机器学习模型 集合,并且在评估指标(如ROC-AUC得分,准确性,RMSE等)方面表现出了出色的性能。您的客户将无法做出该声明的开头或结尾。
在大多数数据科学项目中,我们需要建立可信赖且 可解释的机器学习模型 。在本文中,我们将介绍各种Python库,这些库可用于部分或全部解释机器学习或深度学习模型。
请注意,我将讨论如何使用每个库来提高机器学习的可解释性。如果您想了解构建可解释模型的整个概念,建议查看以下文章:
用于构建可解释的机器学习模型的Python库
这是我们将在本文中讨论的6个Python库:
- 5级
- 酸橙
- 夏普
- 黄砖
- 阿里比
- 清醒的
让我们开始!
1.使用ELI5解释机器学习模型
ELI5是“像我五岁一样解释”的首字母缩写。这个恰当命名的Python库具有解释大多数机器学习模型的功能。解释机器学习模型有两种主要方法:
- 全局解释: 查看模型的参数并在全局级别确定模型的工作方式
- 本地解释: 查看单个预测并确定导致该预测的特征
对于全局解释,ELI5具有:
eli5 。show_weights (clf )#clf 是拟合的模型


对于本地解释,ELI5具有:
eli5 。show_predictions (clf,X_train.iloc [1],feature_names = list(X.columns))
#clf是拟合的模型
#X_train.iloc [1]是索引1处的记录
#feature_names是列名称/功能的列表
如我们所见,我们仅获得训练数据中第一条记录的预测:

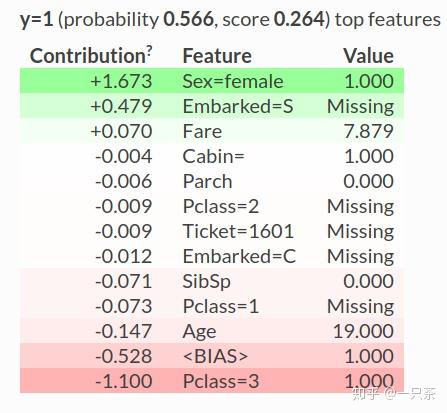
ELI5库的亮点之一是它已经为流行的库提供了支持,例如scikit-learn, XGBoost , Keras 等。
我们也可以将ELI5用于文本数据!它有一个用于解释 文本分类模型 的特殊模块,称为TextExplainer。另一个亮点是格式化程序模块,我们可以在其中生成我们解释的HTML,JSON甚至Pandas数据框版本。这也使得将解释集成到我们的机器学习管道中变得容易。
2.使用LIME解释机器学习模型
考虑一下–您是否愿意从一个随机的人那里观看电影,如果有人推荐,可以观看它?没有权利?您将阅读著名电影评论家对电影的评价,然后做出决定。这是因为您信任电影评论家的意见。
同样,根据LIME的作者,用于构建机器学习模型的关键字是 trust 。


在机器学习模型上获得最佳预测不是最终目标,不是吗?最终目标是根据这些预测做出决策,而这正是人类参与的地方。人类/决策制定者需要信任模型和预测才能做出决策-尤其是在生死攸关的情况下,关注金钱。
LIME( 本地可解释模型不可知的解释) 背后的想法是提供做出预测的原因。以同一示例为例,如果机器学习模型预测电影将成为大片,则LIME会突出显示电影的特征,这将使它成为超级热门。诸如流派和演员之类的功能可能有助于电影的出色表现,而诸如放映时间,导演之类的其他功能可能会不利于它。
LIME的创建者概述了必须满足的四个基本解释标准:
- 可解释的 :根据目标人群的解释必须易于理解
- 局部保真度 :解释应该能够解释模型对于单个预测的行为
- 与模型无关 :该方法应能够解释任何模型
- 全局角度 :在解释模型时应整体考虑
这些都是要遵循的极好的标准,我们一般可以将它们用于机器学习模型的可解释性。
使用LIME的语法是:
进口石灰
导入lime.lime_tabular
解释器= lime.lime_tabular.LimeTabularExplainer(np.array(X_train),feature_names,
class_names,categorical_features,mode)
#np.array(X_train):训练数据
#class_names:目标变量(用于回归),目标中的不同类
变量(用于回归)
#categorical_features:列出所有分类的列名
#模式:对于回归问题:“回归”,并且
对于分类问题,“分类上面的示例适用于表格数据(仅数字或类别)。这是显示多类分类问题的输出的方式:


对于单个预测:
exp = explorer.explain_instance(数据行,预测功能)
exp.as_pyplot_figure()#破坏解释
#data_row:我们要预测的单个测试数据点
#predict_function:预测模型
我们也可以将LIME用于图像和文本数据:
解释器 = lime_image 。LimeImageExplainer ()
解释器 = lime_image 。LimeTextExplainer()
- 以下是可用于图像数据的功能列表: 带LIME的图像数据
- 使用文本数据和LIME: 文本数据文档
要使用代码和示例全面了解LIME,可以参考以下两篇文章:
3.使用SHAP解释机器学习模型
“ SHapley Additive exPlanations” Python库(俗称SHAP库)是用于机器学习可解释性的最受欢迎的库之一。 SHAP库以Shapley值为核心,旨在解释各个预测。
但是,等等– Shapley的价值观是什么?简而言之,Shapley值是从 博弈论 得出的,其中数据中的每个特征都是玩家,而最终的回报就是预测。根据奖励,Shapley值告诉我们如何在玩家之间公平分配奖励。
我们不会在这里详细介绍这种技术,但是您可以参考这篇出色的文章,解释Shapley值的工作原理: 机器学习可解释性的独特方法:博弈论和Shapley值 !
SHAP最好的部分是它为基于树的模型提供了一个特殊的模块。考虑到黑客马拉松和行业中基于树的模型的流行程度,即使考虑相关功能,该模块也可以进行快速计算。
这是如何将SHAP库用于单个预测的基本语法( 基于树的模型 ):
进口杂货
#需要在笔记本中加载JS可视化
shap.initjs()
#假设我们正在使用XGBoost
解释器= shap.TreeExplainer(xgb_model)
shap_values = explorer.shap_values(X_train)
shap.force_plot(explainer.expected_value,shap_values [i],features = X_train.loc [i],
feature_names = X_train.columns)
#i:个人记录的ID


尽管SHAP试图解释单个预测,但我们也可以使用它来解释全局预测:
shap.summary_plot(shap_values,features,feature_names)
#features:我们的自变量训练集
#feature_names:上述训练集中的列名列表4.使用Yellowbrick解释机器学习模型
Yellowbrick库基于scikit-learn和 matplotlib 库。这使其与大多数scikit-learn的模型兼容。我们甚至可以使用我们在机器学习模型中使用的相同参数(当然基于scikit-learn)
Yellowbrick使用“可视化工具”的概念。 可视化工具是一组工具,可帮助我们考虑各个数据点来可视化数据中的功能。 将其视为所有功能的仪表板。Yellowbrick提供的主要展示台是:
- 等级特征:可视化单个特征及其与其他特征的相关性
- RadViz Visualizer:可视化类之间的可分离性
- 平行坐标:可视化目标类相对于其他要素的分布
- PCA投影:使用 主成分分析(PCA) 可视化组合/更高的尺寸
- 流形可视化:使用流形学习(如 t-SNE )可视化数据
- 直接数据可视化/联合绘图可视化器:可视化各个要素与目标变量之间的关系
使用这些展示台是一个非常简单的4行过程。语法类似于我们在scikit-learn中使用转换器的方式。
例如:
从 yellowbrick.features 导入 JointPlotVisualizer
visualizer = 关节图可视化器(列= [ 'col1' , 'col2' ])
可视化器。fit_transform (X , y )
可视化工具。显示()
#col1和col2是我们要探讨的2列。
#X是自变量
#y是目标变量5.使用Alibi解释机器学习模型
Alibi是一个开放源代码Python库,它基于实例的预测解释(在这种情况下,实例表示单个数据点)。该库由不同类型的解释程序组成,具体取决于我们处理的数据类型。这是创作者自己制作的便捷表格:

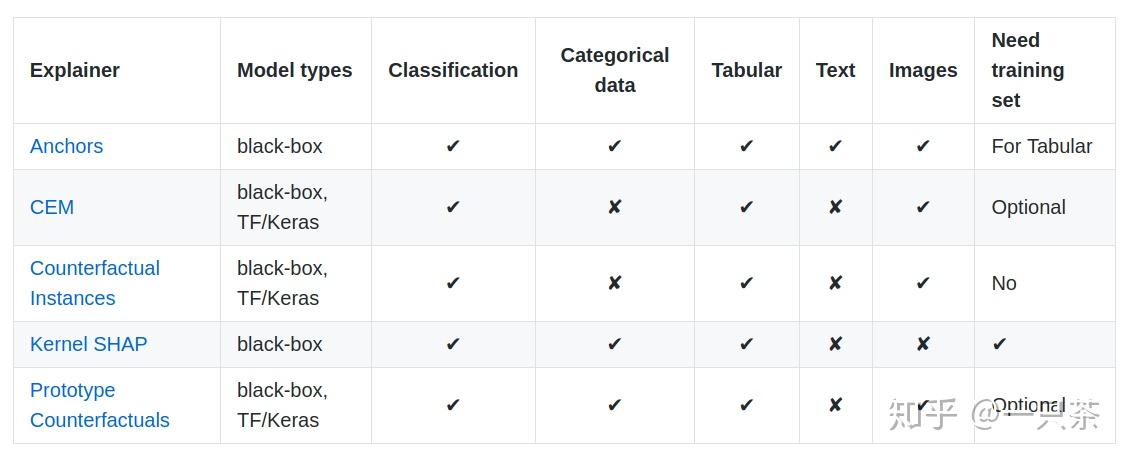
如您所见,该库基于不同的技术提供了不同类型的Explainer模型。尽管我们不会详细介绍它们,但需要注意的是该库是专门为黑盒模型设计的。本质上,您只需要最后使用模型预测即可使用该库。当我们不想篡改我们的机器学习模型的工作流程时,这特别有用。
安装Alibi会安装许多其他有用的库(作为其依赖项的一部分),例如scikit-learn,Pandas, spaCy , TensorFlow 等。这将使其对于深度学习模型特别有用。
这是其中一个解释器的示例(由于我们已经在上面进行了探讨,因此请使用内核SHAP):
从alibi.explainers导入KernelShap
说明者 = KernelShap (prediction_function)
说明者。适合(X_train )
说明= explorer.explain(X_test)
#prediction_function:本predcition功能
#X_train:训练独立变量集
X_test:独立变量的测试集
6.使用Lucid解释机器学习模型
随着深度学习在整个行业中变得越来越主流,解释这些深度学习模型的需求变得迫在眉睫。但是,考虑到我们必须处理的大量功能,这可能会变得特别具有挑战性。
Lucid库旨在通过提供可视化神经网络的工具来填补这一空白。最好的部分?您无需任何预先设置即可可视化神经网络!
由一组研究人员开发并由志愿者维护,Lucid专门致力于使用神经网络和深度学习模型。它由Modelzoo组成,该组件已经预装了各种深度学习模型。
这是可视化神经元的方法(我们采用了Inceptionv1):
将lucid.modelzoo.vision_models导入为模型
从lucid.misc.io导入显示
导入lucid.optvis.objectives作为目标
将lucid.optvis.param导入为param
导入lucid.optvis.render作为渲染
导入lucid.optvis.transform作为转换
#加载模型
模型=模型.InceptionV1()