


机器学习项目交通标志图片识别你做过吗?这个过程并不难

自动驾驶汽车现在可谓是“站在风口上的猪”,就连小米都加入了这一阵营。在国外很多人工智能和互联网大型公司如特斯拉,Uber,谷歌,梅赛德斯 - 奔驰,丰田,福特,奥迪等都早已在研究自动驾驶汽车。在我们可以预见的未来,或许真的可以实现这个目标,就像汽车刚出现的时候我们也不相信它能够跑得比马快,说不定若干年后我们的子孙见不到人开车的场景了。
自动驾驶级别分为L0到L5,其中0-2级为驾驶辅助类,3-5级为自动驾驶类。目前普遍都还在L2级,要实现L5级自动驾驶,车辆必须了解并遵守所有交通规则,也就是说为了在自动驾驶技术中实现准确性,车辆最基本应该能够识别交通标志并做出相应的决策。
对于机器学习初学者来说,即使学习了很多相关知识,但是没见过它的效用,会对自己产生怀疑,到底学的东西学会了吗?它有用吗?如果你学的扎实,看完这个案例,觉得你也可以做出来,你就能自信点,并且感受到这一个小小项目的用处。下面就是关于这个项目的演示,你给它上传一个交通标志的图片,它就能识别出这个标志的内容是什么。
在这个Python项目示例中,有几种不同类型的交通标志,如限速,禁止进入,交通信号灯,左转或右转,儿童交叉口,重型车辆不得通过等。我们把交通标志分类化简为识别交通标志属于哪个类别的过程,然后构建一个CNN神经网络模型,这个模型可以将图像中存在的交通标志分类为不同的类别。通过这个模型,我们能够读入和识别交通标志,然后给汽车后续3自动操作提供依据。
对于这个项目,我使用的是Kaggle提供的公共数据集: 交通标志数据集 。这个数据集包含超过 50000 张不同交通标志的图像。它进一步分为43个不同的类别。数据集的差异很大,有些类有很多图像,而有些类有很少的图像。数据集的大小约为316MB。数据集有一个"train"文件夹,其中包含每个类中的图像;还有一个“test”文件夹,用来测试我们的模型。
这个项目需要tensorflow,Matplotlib,Scikit-learn,Pandas,PIL和图像分类的先验知识。如果没有的话,需要先在终端中使用“pip install ”命令安装这些辅助包。
1.数据下载好后,将文件解压缩到一个文件夹中,包括train,test和meta文件夹。
2.创建一个 Python 脚本文件,并将其命名为项目文件夹中traffic_signs.py。构建这个交通标志分类模型的方法分为四个步骤:查看数据集;搭建CNN模型;训练和验证模型;使用测试数据集测试模型。下面就开始正式建模。
步骤 1:查看数据集
"train"文件夹包含43个文件夹,每个文件夹代表不同的类,每个类表示一种交通规则含义。文件夹的命名范围是从0到42。通过os模块来循环访问所有类,并将图像及其各自的标签(也就是父文件名)添加到数据和标签列表中。PIL库用于打开并读取图像内容转换为数组。
1.1 导入必要的库
#导入必要的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
import PIL
from PIL import Image
from Pillow import Image
import os
os.chdir(r"E:\app\archive" )
from sklearn.model_selection import train_test_split
#用于将图片数组转化为keras里的数据格式
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.layers import Conv2D, MaxPool2D, Dense, Flatten, Dropout1.2 查看数据特征
data = []
labels = []
classes = 43
cur_path = os.getcwd()
#读取图片文件和它们对应的标签
for i in range(classes):
path = os.path.join(cur_path,'train',str(i))
images = os.listdir(path)
for a in images:
image = Image.open(path + '\\'+ a)
image = image.resize((30,30))
image = np.array(image)
#sim = Image.fromarray(image)
data.append(image)
labels.append(i)
except:
print("Error loading image")
#转换为numpy数组
data = np.array(data)
labels = np.array(labels)
print(data.shape, labels.shape)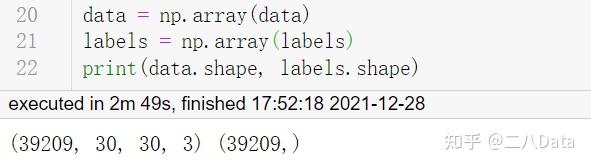
上述代码的目的是读进图像文件,把所有图像及其标签存储到列表(数据和标签)中,然后转换为numpy数组,以便喂给模型进行训练。数据的形状为(39209,30,30,3),这意味着有39209张大小为30×30像素的图像,第四维的“3”表示数据包含彩色图像(RGB值)。
1.3 切分数据集
通过sklearn包,我们使用 train_test_split()方法来拆分训练和测试数据。
#切分训练集和验证集
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
1.4 从tensorflow.keras.utils包中,我们使用to_categorical方法将y_train和y_test编码为独热码。
#把训练集和测试集的标签都转换为keras里的独热码
y_train = to_categorical(y_train, 43)
y_test = to_categorical(y_test, 43)步骤 2:构建CNN模型
为了将图像分类到各自的类别中,我们将构建一个CNN模型(卷积神经网络),CNN最适合用于图像分类。这个模型的体系结构是:
- 2 Conv2D layer (filter=32, kernel_size=(5,5), activation=”relu”)
- MaxPool2D layer ( pool_size=(2,2))
- Dropout layer (rate=0.25)
- 2 Conv2D layer (filter=64, kernel_size=(3,3), activation=”relu”)
- MaxPool2D layer ( pool_size=(2,2))
- Dropout layer (rate=0.25)
- Flatten layer to squeeze the layers into 1 dimension
- Dense Fully connected layer (256 nodes, activation=”relu”)
- Dropout layer (rate=0.5)
- Dense layer (43 nodes, activation=”softmax”)
我们使用Adam优化器来训练模型,如果你看了我之前的优化算法的话,应该知道神经网络模型一般都是用“Adam”,损失评估函数是"categorical_crossentropy"(类别交叉熵),因为我们有多个类需要分类。
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(5,5), activation='relu', input_shape=X_train.shape[1:]))
model.add(Conv2D(filters=32, kernel_size=(5,5), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.25))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(rate=0.5))
model.add(Dense(43, activation='softmax'))
#把上面设置的网络组建编译到模型实例中来
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])步骤 3:训练和验证模型
构建模型架构后,我们使用 model.fit()训练模型。我尝试了Batch size为32和64,其中在Batch size为64大小下表现更好。在15个epoches之后,模型精度逐渐趋于稳定。
epochs = 15
history = model.fit(X_train, y_train, batch_size=32, epochs=epochs, validation_data=(X_test, y_test))
model.save("my_model.h5")
我们的模型在训练数据集上达到了99.02% 的准确率。 下面使用matplotlib绘制accuracy和loss随着迭代次数的增加而变化的图。
plt.figure()
plt.plot(history.history['accuracy'], label='training accuracy')
plt.plot(history.history['val_accuracy'], label='val accuracy')
plt.title('Accuracy')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.legend()
plt.show()
plt.figure(1)
plt.plot(history.history['loss'], label='training loss')
plt.plot(history.history['val_loss'], label='val loss')
plt.title('Loss')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.legend()
plt.show()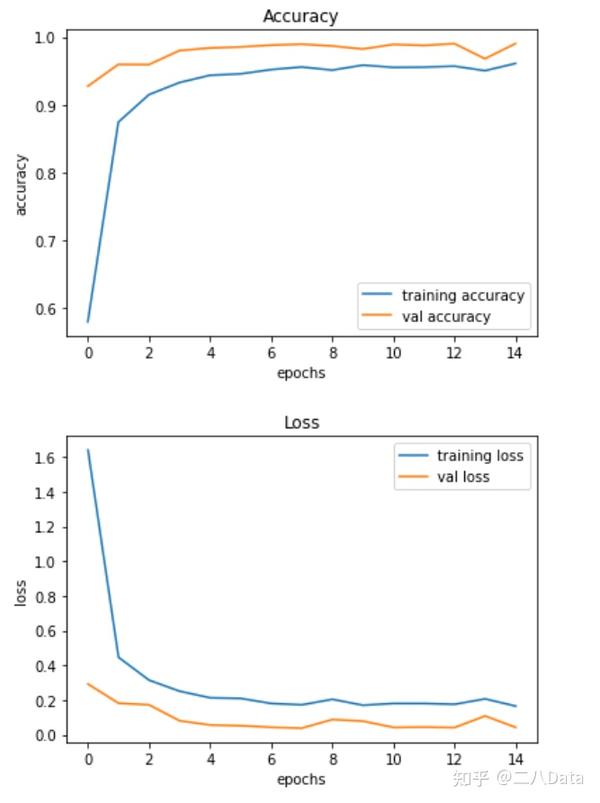
步骤 4: 用测试集测试模型
我们的数据集包含一个test文件夹,在test.csv文件中,有与图像路径和它们各自的类标签相关的详细信息。 使用pandas提取图像路径和标签, 然后为了预测模型,同样也需要把图像大小调整为30×30像素,并转化成一个包含所有图像数据的numpy数组。 从sklearn.metrics中导入了accuracy_score评估方法模型的好坏。
#在测试集上测试模型准确性
from sklearn.metrics import accuracy_score
y_test = pd.read_csv('Test.csv')
labels = y_test["ClassId"].values
imgs = y_test["Path"].values
data=[]
for img in imgs:
image = Image.open(img)
image = image.resize((30,30))
data.append(np.array(image))
X_test=np.array(data)
pred = model.predict_classes(X_test)
#评估准确性
from sklearn.metrics import accuracy_score
print(accuracy_score(labels, pred))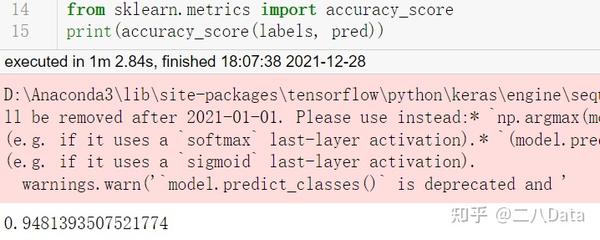
可以看到这个模型在测试集中实现了94.8% 的准确率,效果已经很不错了。我尝试肉眼自己去识别,有些图案比较暗或者不认识的图案,它基本都能快速识别出来。
最后使用Keras model.save() 函数保存训练好的模型:
model.save(‘traffic_classifier.h5’)步骤 5:创建 图形用户界面APP
保存了这个模型之后我们该怎么使用呢?接下来就使用一个python的GUI包tkinter把交通标志模型制作成一个可以交互使用的图形用户界面APP,方便大家使用。Tkinter是标准python库中的GUI工具包。你可以在这个项目文件夹中创建一个新文件并复制以下代码。将其另存为traffic_classifications.py,你可以像文章开头动图里那样通过在命令行中键入python traffic_classifications.py来运行代码。
在这个文件中,我们首先使用Keras.models.load_model加载了训练的模型"traffic_classifier.h5"。然后,我们构建用于上传图像的GUI,并使用一个按钮对调用classize()函数的按钮进行分类。classify() 函数将图像转换为为(1, 30, 30, 3)形状的数组,这是因为要预测交通标志,必须提供与构建模型时相同的维度。然后我们预测类,model.predict_classes(image)返回一个介于(0-42)之间的数字,表示它所属的类。我们使用字典来获取有关该类的信息。下面是traffic_classifications.py文件的代码。
import tkinter as tk
from tkinter import filedialog
from tkinter import *
from PIL import ImageTk, Image
import numpy
#加载训练模型的分类标志
from keras.models import load_model
model = load_model('traffic_classifier.h5')
#把所有交通标志分类放进一个字典中
classes = { 1:"限速(20km/h)",
2:"限速(30km/h)",
3:"限速(50km/h)",
4:"限速(60km/h)",
5:"限速(70km/h)",
6:"限速(80km/h)",
7:"限速结束(80公里/小时)",
8:"限速(100公里/小时)",
9:"限速(120公里/小时)",
10:"禁止通行",
11:"超过3.5吨的车辆不得通过",
12:"十字路口的路权",
13:"优先道路",
14:"让道",
15:"停止",
16:"禁止车辆",
17:"禁止>3.5吨",
18:"禁止入境",
19:"一般警告",
20:"危险的连续转弯左",
21:"危险的连续转弯右",
22:"双弯道",
23:"道路颠簸",
24:"路滑",
25:"道路在右边变窄",
26:"道路工程",
27:"交通信号灯",
28:"行人",
29:"儿童穿越",
30:"自行车穿越",
31:"当心冰雪",
32:"野生动物杂交",
33:"结束速度 + 通过限制",
34:"前方右转",
35:"前方左转",
36:"只可直行",
37:"直走或右走",
38:"直走或左转",
39:"保持右行",
40:"保持左行",
41:"环岛强制",
42:"禁止通行结束",
43:'> 3.5 吨车辆禁止通行结束'}
#初试话GUI实例
top=tk.Tk()
top.geometry('800x600')
top.title('交通标志识别')
top.configure(background='#46A3FF')
label=Label(top,background='#46A3FF', font=('arial',15,'bold'))
sign_image = Label(top)
def classify(file_path):
global label_packed
image = Image.open(file_path)
image = image.resize((30,30))
image = numpy.expand_dims(image, axis=0)
image = numpy.array(image)
pred = model.predict_classes([image])[0]
sign = classes[pred+1]
print(sign)
label.configure(foreground='#011638', text=sign)
def show_classify_button(file_path):
classify_b=Button(top,text="识别图片",command=lambda: classify(file_path),padx=10,pady=5)
classify_b.configure(background='#364156', foreground='white',font=('arial',10,'bold'))
classify_b.place(relx=0.45,rely=0.926)
def upload_image():
file_path=filedialog.askopenfilename()
uploaded=Image.open(file_path)
uploaded.thumbnail(((top.winfo_width()/3),(top.winfo_height()/4)))
im=ImageTk.PhotoImage(uploaded)
sign_image.configure(image=im)
sign_image.image=im
label.configure(text='')
show_classify_button(file_path)
except:
upload=Button(top,text="上传新图片",command=upload_image,padx=5,pady=5)
upload.configure(background='#364156', foreground='white',font=('arial',10,'bold'))
upload.pack(side=BOTTOM,pady=50)