|
|
|


华为推出基于 ARM 的鲲鹏 920 芯片以及三款泰山 ARM 服务器,对行业意味着什么,影响有多大?
关注者
2,424
被浏览
2,217,636
登录后你可以
不限量看优质回答
私信答主深度交流
精彩内容一键收藏

喜欢画画和摄影的硅工码农(滑稽)
幕间
在上篇中我们主要探究了鲲鹏920 TSV110微架构的取指前端和后端执行单元配置,下篇我们继续探究Mid Core、访存子系统、核外系统。
Mid Core
重命名消除
在实际应用程序中许多指令并不需要进入处理器后端被真正执行(如move指令);现代处理器普遍配备了各式各样的重命名消除机制,以减少处理器后端压力并加速程序执行。
| Elimination type | Throughput |
|---|---|
| move imm zero | 4 |
| move imm one | 4 |
| move chain | 1.3 |
| move single | 4 |
| move self | 1.3 |
| move bounce | 1.3 |
| sub self | 1 |
| xor self | 1 |
TSV110配备了基本的重命名消除机制,优于A78之流,但与X86竞品相比仍有相当的差距。X86处理器倾向于配备极强的重命名消除机制,可能源自于其寄存器数相对较少的历史包袱。令人惊喜的是,move置0以及move置立即数1都被特别消除了。TSV110的重命名可以消除不相关的move,但是不能在同一周期内处理move相关链;这样的取舍可以理解,一方面是在真实应用中这样的场景较少;另一方面是TSV110流水线可能偏较短,支持相关链重命名会给重命名级带来巨大的时序压力。
- move imm zero(mov x10, #0)吞吐为4说明重命名对置立即数0进行了消除,因为其仅有3个ALU。
- move imm one(mov x10, #1)吞吐为4说明重命名时对置立即数1进行了消除,因为其仅有3个ALU。
- sub与xor均未对置0情况进行特别优化,可能是ARM ISA的编译器极少进行此类操作;X86处理器普遍配备此类优化。
- move single(非相关的move消除)等的吞吐为4,超过了ALU数量(因此move并未由后端真正执行),说明其具备基本的重命名消除机制。
- move bounce与move chain等的吞吐为1.3,说明后端出现了数据相关或前端重命名吞吐量下降,无论如何均表明未被重命名消除。
- move self的吞吐为1.3,说明其未被重命名消除。虽然这一细节的实用意义不大,但是move self理应被识别为nop,TSV110没有做这一点可以说是向Intel致敬了。
乱序资源
乱序推测执行的处理器需要海量的队列空间来跟踪指令,确保指令最终的提交顺序正确。
| Icestorm | A78 | TSV110 | |
|---|---|---|---|
| ROB | ~108 | ~160 | ~92*n(coalesced ROB) |
| PRF(integer) | ~108 | ~160 | ~140 |
| PRF(float) | ~112 | ~92 | ~96 |
| PRF(conditional bit/flag) | ~36 | ~44 | ~42 |
TSV110在ROB设计上进行了大胆的尝试。倘若只使用Nop指令,我们会得到:
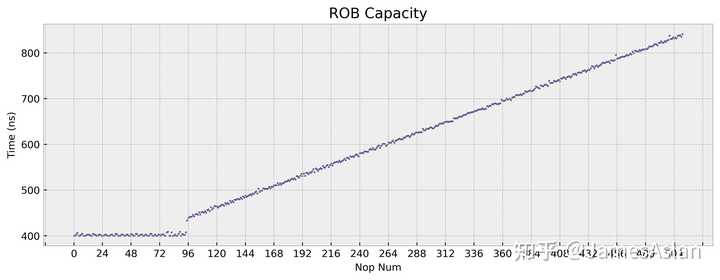

似乎ROB只有92项,小得异乎寻常。倘若我们交替混合Nop与Add指令,那么结论就大不一样:
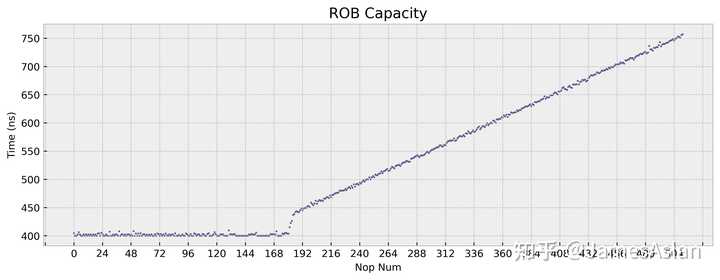

似乎ROB有180项。倘若使用精心配比的各种指令交替混合,结论又发生了变化:
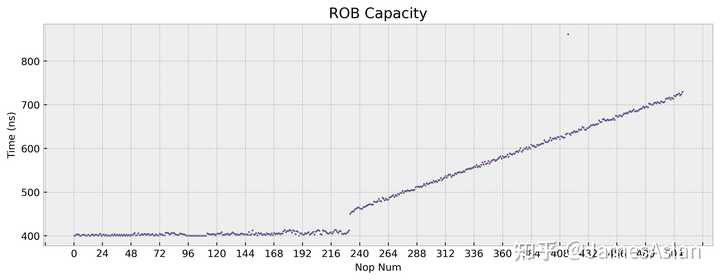

似乎ROB有230项,逐渐大得离谱。这是Coalesced ROB的特征,每个ROB表项可以追踪多条指令,古时的IBM、现如今的Apple、Sifive等公司也采用了这样的设计。但是TSV110的选择有些许令人困惑,即为什么nop指令没有被特别优化,甚至连续的nop都需要占据单独表项;在A78、Icestorm等微架构中,每个ROB表项都可以存储多条nop指令。TSV110似乎能将不同类型的指令合并存储在同一ROB表项中,但具体的规则我们没有探究。
从寄存器堆的配置来看TSV110倾向于优化定点性能。由于Coalesced ROB的特殊性,我们不能简单地判断各类寄存器堆是否足额或超额。不过单纯考虑各物理寄存器堆的规模,TSV110定点略大,浮点略小。虽然乱序资源的容量十分重要,但是使用效率的优化也是重中之重,因此我们不能简单地追求资源的堆砌。
乱序推测执行的处理器最为直接的调度窗口由各级发射队列的容量决定:
| Icestorm | A78 | TSV110 | |
|---|---|---|---|
| IssueQ+DispatchQ (Simple fix) | ~36 | ~56 | ~36 |
| IssueQ+DispatchQ (Complex fix) | ~14 | ~32 | ~28 |
| IssueQ+DispatchQ (Float) | ~32 | ~48 | ~28 |
| IssueQ+DispatchQ (Load) | ~20 | ~32 | ~42 |
| LDQ | ~54 | ~64 | ~48 |
| STQ | ~40 | ~48 | ~32 |
DispatchQ并不一定存在,且DispatchQ的容量并不是在任何微结构中都可以探测的,因此我们不分离计数。
- 整数发射队列为36项左右,不算小。可以认为是较为平衡的设计,代表了一般场景下足够的乱序调度能力。
- 复杂整数指令(如乘法指令)所享受到的发射队列项数为~28项,这个暧昧的数字不足以判断是否与简单整数指令共享了发射队列。我们首先测试了3 add + 1 mul的指令序列,发现能够保持4 inst/cycle的吞吐,因此发射队列拥有每周期同时发射4条指令的能力;再将add与mul指令混合以探测发射队列的大小,发现容量为~60,接近36与28的加和;因此执行复杂整数指令的MDU大概独享了~28项的发射队列。
- 由上条可知,TSV110具有分布式发射队列的特征,每个执行单元前有一个独立的发射队列。分布式发射队列的有效容量在极端情况下不及集中式发射队列,因此会与A78等新设计有较大的差距。
- 浮点发射队列为28项左右,相较整数大幅缩减。
- 访存发射队列为42项左右,十分巨大。足见对访存能力的追求是永无尽头的。
总体而言,TSV110的乱序调度窗口在当时已然十分巨大,但是容量的分配有些许奇怪,可能是我们测试方法的局限导致了TSV110上数据的异常。
TSV110的Load Queue容量为48项,Store Queue容量为32项。从执行单元的规格上来看(2 load AGU、1 store AGU),TSV110的LDQ与STQ容量是足额的。但是在接下来的访存测试环节中,我们可以看到其STQ的设计似乎有一定的局限性。
访存
访存是体系结构永恒的话题与难题,访存性能直接决定了处理器性能的上限(甚至取指也是一种形式的访存),访存子系统的表现体现了设计团队的综合实力(前端、后端)。为了缓解越发明显的缓存墙(memory wall)问题,现代处理器的访存子系统十分复杂;流水线内的LDQ、STQ,Dcache、DTLB,下级Cache、下级TLB,各级预取器等组件交织配合,尝试在延迟、带宽等多个维度提高访存性能。
load-store前递
当load指令命中STQ中还未来得及写回DCache的store指令(访问了相同的物理地址)时,配备了store-to-load forwarding的处理器无需等待store指令写回DCache后再执行load指令,而是可以直接将STQ中存储的相应数据发送至LSU,完成load指令的执行。


TSV110的Store-to-load forwarding图像并不传统。从计算得出的延迟来看,2.5ns约为6.5个时钟周期,其配备了store-to-load forwarding机制。与大部分其他处理器核不同的是,TSV110的前递粒度为8bit即1 Byte(STQ支持的查询和存储粒度为8bit),也就是说TSV110可以从任何非对齐位置对partial overlay的load指令进行store数据前递,而无需等待store指令的数据写入DCache再重新执行load指令,这一设计十分激进。更为激进的是,在store跨行、load跨行时都没有严重影响store-to-load forwarding的效率,其近乎完美地工作着。至于图中的其他条带,我们在后文中再尝试分析。
Dcache端口
store-to-load forwarding图像还包含了更多的信息,TSV110的访存子系统展现出了一些令人费解的特性。
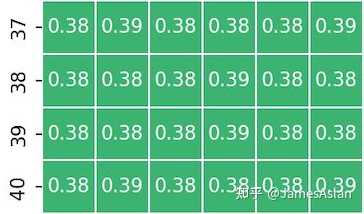
load、store均不跨16Byte时,每周期能够执行1组store-load指令对,符合TSV110只有1个AGU store(共两个AGU)的设计。
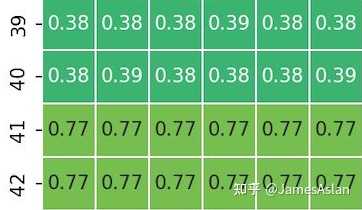
一旦store过16Byte对齐线,奇怪的现象便出现了:store写入Dcache的带宽下降了,2周期才能完成1条store指令。Zen4也有类似的现象,其store在跨32Byte时会被拆分为2条。这样的现象在早期的处理器上更为常见,如A75:


受制于“节俭”的Cache设计,这些处理器在跨越部分行内边界时也会需要拆分。但是TSV110的DCache似乎并不节俭,经过测试其应该是使用了体复制的方式实现了多端口设计(也就是说使用了镜像的2组SRAM),这一设计不算优雅。我猜测可能是STQ设计时只支持128bit对齐的存储,凡是越过128bit对齐的store都需要占据两项STQ,进而导致了写入DCache的带宽降低。也许是为了Neon才促成了这样的设计?这也印证了TSV110使用的是不支持同时读写的单口SRAM。但是不寻常的地方不止于此:
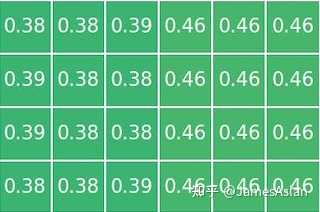
load跨16Byte,store不跨16Byte时居然也出现了吞吐量下降。完成一组store-load指令对的耗时由1周期上升至了1.2周期。这其中的原因难以捉摸,究竟是什么结构出现了瓶颈呢?难道是对STQ的查询?
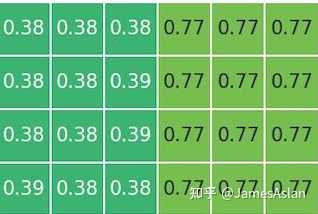
load跨行store不跨行时,load读取Dcache的带宽下降,load指令发生了拆分;此时每周期能够执行0.5组store-load指令对。store指令跨行时的行为参照跨16Byte的情形,而当load、store指令均跨行时没有额外的叠加损失。
总体而言TSV110的近核访存子系统表现出了较为奇怪的特性,较为严格的对齐约束也许会对实际应用的访存带宽造成不利影响。
Cache延迟
我们使用多种访存模式访问逐渐变大的数据集(直至内存),以探究TSV110的Cache层级设计、预取器效果、内存控制器效果。


TSV110采用了传统的3级Cache设计:
- DCache有效容量为64KB。
- L2Cache有效容量为512KB。
- Linear Chain不能做到无损预取,疑似没有直达L1的Stream和Stride预取器。
- 开页预取器或类Region预取器不存在或效果不佳。
- LLC有效容量为1MB/core,对于32核型号可访问总空间为32MB。
TSV110的一级和二级Cache访问延迟都不算高,表现较为优秀。Kunpeng920的LLC挂载在环形总线上,实测表现出了明显的local和remote特征,每个4核核心簇有3-4MB的快速访问区间,应该是直接所属的那部分LLC slice;超出这一空间后进入remote部分,延迟激增,但是从访问cycle数上仍然优于部分Intel处理器(同为ringbus,不过这一对比不甚科学,毕竟这些Intel SKU的频率倍增且定位不同)。数据预取器的缺失令人如鲠在喉。纵使是担心激进的数据预取影响全片满载表现,也不至于不配备基本的Stream、Stride预取器,这会极大影响很多应用的表现,个人十分好奇这其中的设计考量。
访存序
乱序推测执行的处理器中,store指令无法被推测执行但是load指令允许被推测执行,这就造成了访存的RAW和WAR问题。为了避免错误推测执行的load指令带来频繁的回滚或流水线清空,处理器内部普遍配备了访存违例预测器,预测可能会导致回滚和流水线清空的load指令,并强制这样的load指令不再完全推测执行。
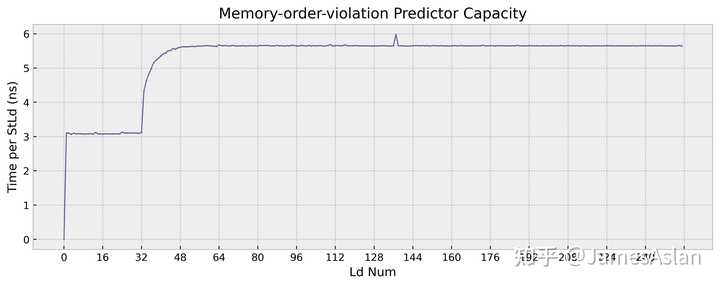

TSV110的访存违例预测器有32项容量,采用了较为传统的设计。现今处理器仍然广泛使用这样的传统设计而非store-set等机制(只有Intel的大核采用了类store-set设计),但是传统机制也有海量的设计细节,我们不在此展开。时至今日,业内主流设计的容量普遍在32项左右。
| Capacity | |
|---|---|
| TSV110 | 32 |
| Icestorm | 12 |
| A76 | 32 |
| A78 | 32 |
访存并行度
在该测试项目中,我们考察处理器同时面对多个访存流时的表现。每个访存流均是随机且独立的,因此可以规避预取器的有效介入,最大限度压榨核内流水线乱序结构、各级Cache乱序结构。
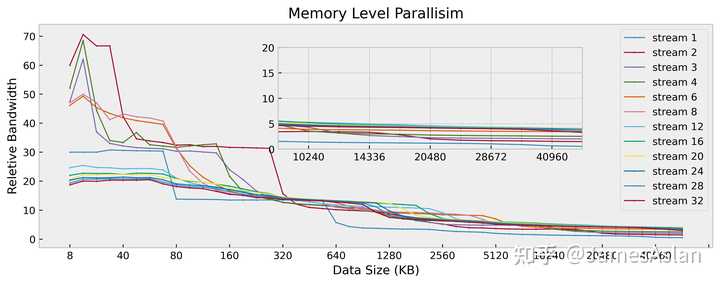

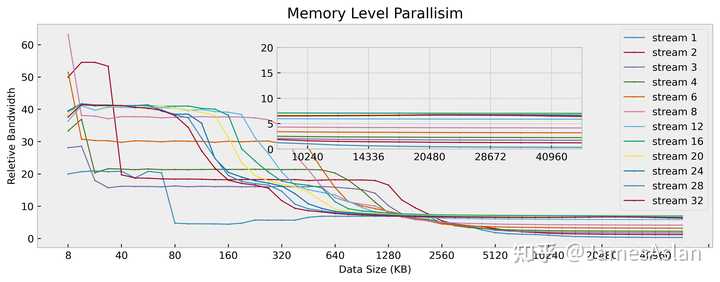

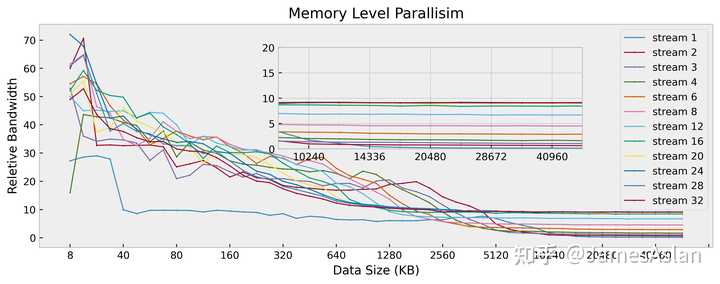

可见TSV110的图像清晰整洁,优于A78,近似Icestorm。其在双流访存时能够获得接近线性的带宽提升,但是更多的访存流已经无法提高近核区间的总带宽。在远端的内存段,最大的有收益流数量为16个,在现如今处理器中不算很多。但是考虑到TSV110极为保守的预取器表现,这样的MLP成绩就中规中矩了。
Pointer Chasing
Pointer chasing是现代高性能处理器中常见的访存优化,当一条load指令的结果用于下一条load指令的地址计算时,该结果会从快速通路进入AGU流水线,缩短这两条load指令的执行间隔。在配备了pointer chasing消除机制的处理器中,触发pointer chasing时load-to-use延迟会比正常情况减少1周期。
| Load-to-use latency | |
|---|---|
| Pointer-chasing Case | 4 |
| No-pointer-chasing Case | 4 |
从测试结果来看TSV110并没有配备pointer chasing优化。不过4周期的访存延迟本身较低,时至今日也不落伍。想要如苹果一样在4周期的访存延迟上更进一步,不仅仅需要强大的逻辑设计能力(从苹果的专利来看,其中有很多细节)还需要强悍的物理设计能力,这样的投入是否有足够的性价比各设计公司都会有自己的考量。题外话,从12代酷睿的GoldenCove开始,Intel裁撤了P core的pointer chasing优化,可能是超高目标频率的负影响。
核外
随着摩尔定律的放缓,即便是消费级处理器也被迫向多核方向发展,核外组件发挥着重要的作用。核外系统是个纷繁复杂的世界,无论是总线结构、一致性协议、LLC设计还是内存控制器调度,每项都复杂到读完1本书都无法入门。因此,我们只关注其中较为浅显、直观的部分。
核间延迟
我们通过CAS测量Soc中两两核间的延迟(脏数据传递),其反映了处理器的一致性协议效率、LLC设计、总线设计等多个维度特性的交叠。
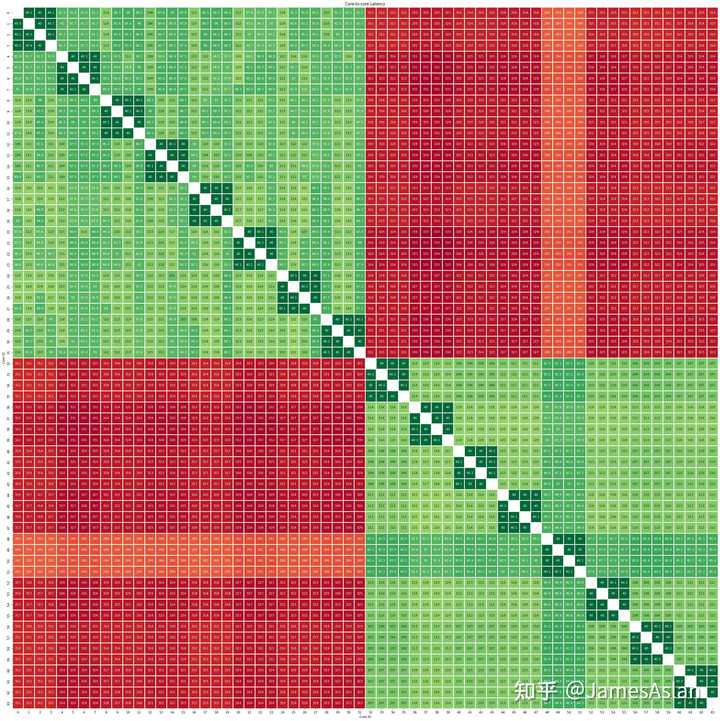

鲲鹏920的核间互联结构在HPCA等体系结构顶会上有论文介绍,我们只关注其实际表现。从测试结果来看,每个4核核心簇内部是类crossbar设计,延迟表现一般但也符合预期。核心簇挂载在双向bufferless ringbus上,在单socket内延迟与AMD EPYC 7003跨CCD延迟比肩,但是落后于使用mesh结构的intel。在跨片延迟方面,鲲鹏920还是落后于EPYC 7003(~200ns),但是优势在于其跨路时支持了更多的一致性操作,少了许多不必要的跨片传输(由peer to peer传输代替);intel的跨片则全面领先,仅需~140ns。总体而言,考虑到鲲鹏920超多的核心数量,其互联结构展现出了相当的实力,双路、四路互联都不在话下,初出茅庐已能与老牌巨头煮酒论剑。
访存带宽
我们通过Stream程序测试Soc中CPU单核的访存带宽,其反映了处理器核内的流水线设计、各级Cache设计、总线设计、内存控制器设计等多个维度特性的交叠。
| Function | Best Rate (MB/s) |
|---|---|
| Copy | 12185 |
| Scale | 11231 |
| Add | 9285 |
| Triad | 9274 |
TSV110的单核Stream带宽极为低下,甚至让我一度怀疑测试程序没有向量化;其效果仿佛整个平台只插了半截内存条。经由前文的微结构分析,有效数据预取器的缺失导致了Stream带宽的低下,进而也导致了基准测试部分浮点性能的低下。但数据预取是一把双刃剑,过于激进的预取在多核满载时反而可能导致带宽争抢、饥饿,也许是出于鲲鹏920的服务器定位TSV110才在这一方面保守了呢?事实上如果我们测试多线程的Stream,鲲鹏920的确表现出了较高的总带宽效率,不过鉴于其单核低得离谱的带宽,良好的多核延展性也是应该的。总体而言TSV110在这一方面的进步空间无限大。
总结
尽管TSV110有着为数众多的奇怪特性和肉眼可见的细节上的粗糙,但是与当年的国际同期微架构A76相去并不遥远。整数负载的优秀表现让我们看到了其不可小觑的潜力;互联与扩展设计可谓一鸣惊人,直达可用的状态;在尝试许多新技术的前提下仍然保证了相当的全片完成度。正如对体系结构的认知是螺旋上升的,TSV110的成功与失败都会成为财富,化作TSV120乃至其他后来者向顶峰发起冲击的长阶。随着国际对抗烈度的加剧,越来越多的芯片公司遭受了长臂管辖制裁,一个个熟悉的名字接连蒙上阴霾,颇有前赴后继的悲壮感。不过一代人有一代人的长征,我相信纵使当下黑云压城城欲摧,也终会峰回路转,守得拨云见日开。让我们共同期待鲲鹏们的涅槃归来,道一声同庆鲲鱼跃。
分析与测试:lyz、lxy
测试平台
我们共使用了两套平台,一套是清华同方主机,处理器为Kunpeng 920 8核SKU;另一套则是双路服务器平台,处理器为2颗Kunpeng 920 32核SKU。之所以使用了两套平台,是因为在部分测试中我们得到了“难以置信”的结论,以至于怀疑桌面版本的鲲鹏920有所阉割,只得又找来另一套平台进行对照测试。
(假装有图)
发布于 2023-03-25 10:22
・IP 属地北京