OpenGL ES 应用程序可能会遇到内存带宽限制的瓶颈。这是 GPU 在给定时间范围内可以访问多少数据的物理限制的体现。该比率不是恒定的,而是根据许多因素而变化,包括但不限于:
-
数据的位置 – 是存储在 RAM、VRAM 还是 GPU 缓存之一中?
-
访问类型 – 是读操作还是写操作?它是原子的吗?一定要连贯吗?
-
缓存数据的可行性——硬件能否缓存数据以供 GPU 将执行的后续操作使用,这样做是否有意义?
缓存未命中可能导致应用程序带宽受限,从而导致性能显着下降。当应用程序绘制或生成许多图元时,或者当着色器需要访问纹理中的许多位置时,通常会导致这些缓存未命中。
可以采取两种措施来最大程度地减少缓存未命中问题:
-
提高传输速率——确保客户端顶点数据缓冲区用于尽可能少的绘制调用;理想情况下,应用程序永远不应该使用它们。
-
减少 GPU 执行满足此约束的调度或绘制调用所需访问的数据量。
OpenGL ES 提供了多种方法,开发人员可以使用这些方法来减少传输特定类型数据所需的带宽。
第一种方法是压缩纹理内部格式,它牺牲纹理质量以减少 mipmap 大小。OpenGL ES支持的许多压缩纹理格式将输入图像划分为4x4的块,并对每个块单独执行压缩过程,而不是对整个图像进行操作。虽然从数据压缩理论的角度来看它似乎效率低下,但它确实具有每个块在 4 像素边界上对齐的优点。这允许 GPU 使用单个提取指令检索更多数据,因为每个压缩纹理块保存 16 个像素,而不是像未压缩纹理那样保存单个像素。此外,如果着色器不需要对相距太远的纹素进行采样,则可以减少纹理获取的数量。
第二种方法是使用打包顶点数据格式。这些格式基于这样的前提:许多顶点数据集不会因其组件精度的降低而受到很大影响。强烈建议尽可能使用打包顶点数据格式。
对于预先已知范围跨度的某些资源,尝试将数据映射到受支持的打包顶点数据格式之一。以普通数据为例,通过将 10 位无符号整数数据范围 <0, 1024> 标准化到浮点范围 <-1, 1>,可以将 XYZ 分量映射到 GL_UNSIGNED_INT_2_10_10_10_REV 格式。
第三种方法是始终使用索引绘制调用。始终使用尽可能小的索引类型,同时仍然能够寻址正在绘制的网格的所有顶点。这减少了 GPU 为每个绘制调用需要访问的索引数据量,但代价是应用程序逻辑稍微复杂一些。
3D 渲染过程是一项计算密集型活动。屏幕分辨率越来越大,有些即将达到超高清分辨率。这意味着 GPU 需要在同一固定时间段内光栅化更多片段。假设目标帧率为 30 fps,游戏单帧时间不得超过 33 毫秒。如果是这样,那么每秒的屏幕更新次数将会下降,用户将更加难以完全沉浸在游戏中。
此外,硬件越繁忙,产生的热量就越多。如果在很长一段时间内,GPU 在帧之间没有任何空闲时间,设备可能会变得很热并且握起来不舒服。如果温度超过一定的安全阈值,设备甚至可能会自动降低GPU时钟频率以防止过热。这将进一步降低用户体验。
为了减少渲染硬件上的负载,应用程序可以减小所使用的渲染目标的大小,例如,如果本机屏幕分辨率是 1080p (1920x1080),则可以将其渲染为 720p (1280x720) 渲染目标。由于两种分辨率的长宽比相同,因此图像的比例不会受到影响。缩小尺寸的渲染目标不会完全填满屏幕,但 OpenGL ES 提供了针对此问题的修复。
OpenGL ES 3.0 引入了对帧缓冲区 blit 操作的支持。绘制缓冲区的内容可以从一个帧缓冲区传输到另一个帧缓冲区。作为 blit 操作的一部分,该 API 还支持放大,可用于将较小分辨率的纹理的内容复制到另一个较大分辨率的纹理。使用放大来放大缩小尺寸的渲染目标,以匹配完整的本机显示尺寸。最佳策略取决于 GPU 必须为应用程序执行的计算强度。放大可以在渲染过程结束时完成,也可以在渲染管道中的某个时刻完成;例如,一种方法可能是以 1:1 分辨率渲染几何体,但使用分辨率稍低的渲染目标应用后处理效果。
笔记:使用帧缓冲区位块传输进行升级比直接将全屏四边形渲染到后台缓冲区的替代方法更快,将缩小尺寸的渲染目标作为纹理输入。
或者,通过 Android API 控制缩放:
对于用 Java 编写的应用程序,配置 GLSurfaceView 实例的固定大小属性(自 API 级别 1 起可用)。使用 setFixedSize 函数设置属性,该函数采用两个定义最终渲染目标分辨率的参数。
对于用本机代码编写的应用程序,使用函数 NativeWindow_setBuffersGeometry 定义最终渲染目标的分辨率,该函数是 NativeActivity 类的一部分,在 Android 2.3(API 级别 9)中引入。
在每次交换操作中,操作系统都会获取最终渲染目标的内容并将其放大,以使其与显示器的本机分辨率相匹配。
该技术已成功应用于主机游戏,其中许多游戏对 GPU 提出了很高的要求,如果以全高清分辨率进行渲染,则可能会受到所讨论的硬件限制的影响。
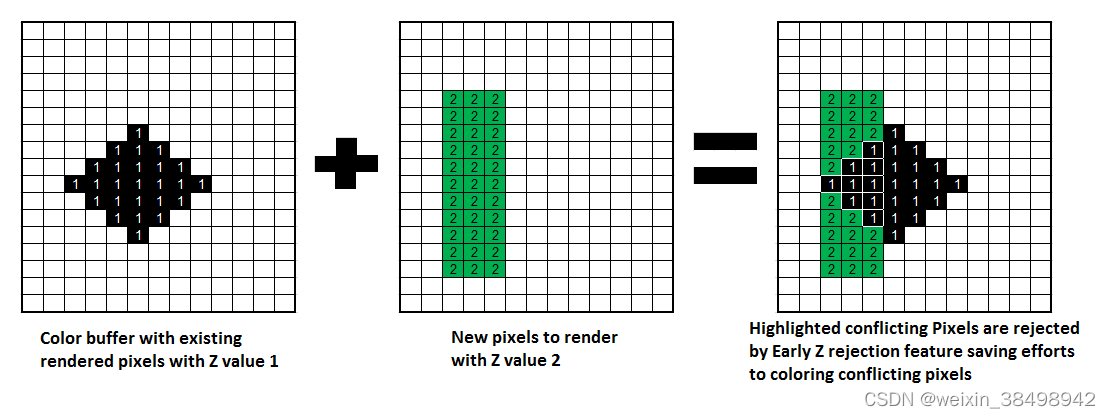
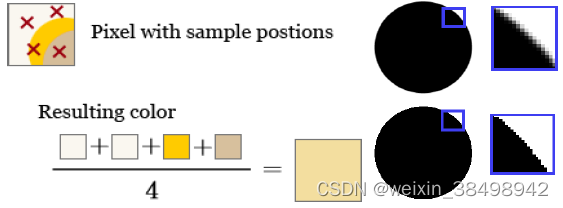
早期 Z 拒绝提供了一种快速遮挡方法,可以拒绝从视图位置不可见(隐藏)的对象的不需要的渲染通道。Adreno GPU 可以以高达 4 倍绘制像素填充率的速度拒绝遮挡像素。下图显示了表示为网格的颜色缓冲区,每个块表示为一个像素。该网格上的渲染像素区域为黑色。这些渲染的黑色像素的 Z 缓冲区值为 1。如果您尝试将新基元渲染到 Z 缓冲区值为 2 的现有颜色缓冲区的相同像素(带有绿色块的第二个网格),则该新基元中的冲突像素将被拒绝(代表最终颜色缓冲区)。
本系列的相关文章将会介绍关于Qualcomm Adreno GPU Android 平台的OpenGL ES应用的开发以及优化。OpenGL ES是OpenGL 2D和3D图形库的一个子集,主要是为受到处理器能力、内存以及电源功耗的嵌入式系统而设计。这篇文章适合对3D图像API(例如OpenGL ES等)有了解的应用开发者。
2 Adreno GPU
Adreno GPU作为Qualc...
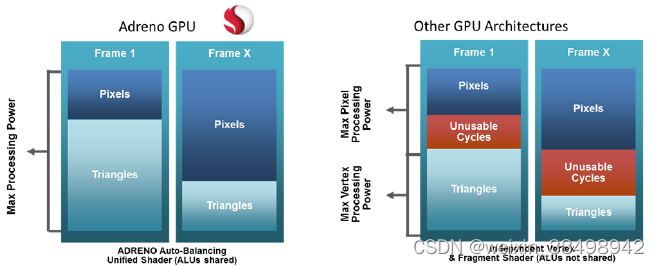
Adreno GPU为无缝配合骁龙CPU和DSP而设计,帮助支持处理密集型GPGPU(通用GPU)计算任务[18]。和其它移动GPU一样,受限于芯片的面积、功耗以及成本等因素,Adreno GPU只能牺牲部分性能和带宽来求得性价比和电池续航力的平衡[7]。移动GPU的劣势主要表现在理论性能和带宽[7],因此其构架和PC GPU有所不同。
1 GPU构架
目前在GPU...
GPU 捕获(用于 Arm64 的 Unreal Engine 4.25)
在此示例中,引擎在 WinPixEventRuntime 库的帮助下将 PIX 事件插入到 GPU 命令流中。 这有助于跟踪帧渲染操作。
启动 CPU 捕获
CPU 捕获
此示例显示了 UE4 4.25 的单个渲染帧的 CPU 捕获。 针对 CPU 和 GPU 捕获报告 PIX 事件