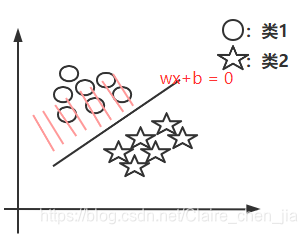
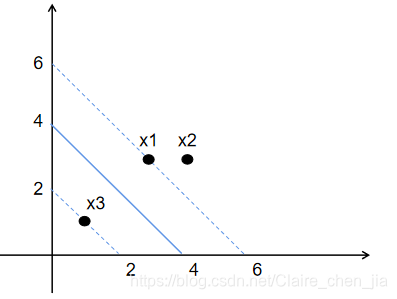
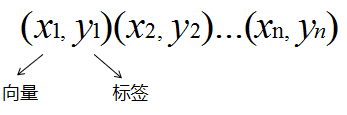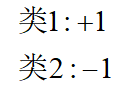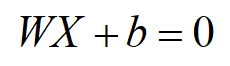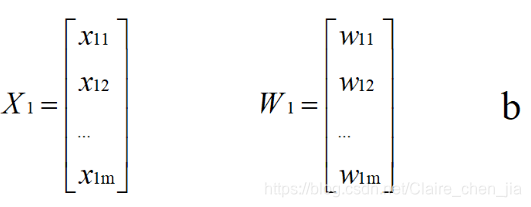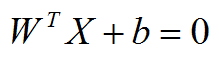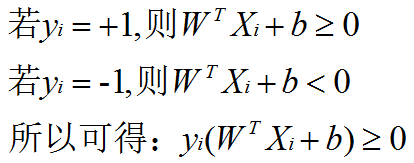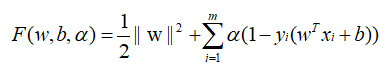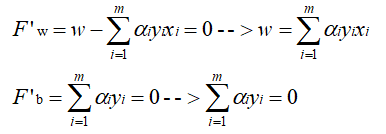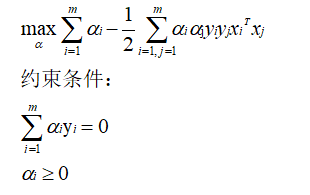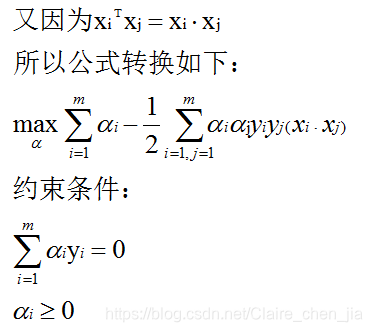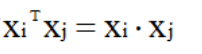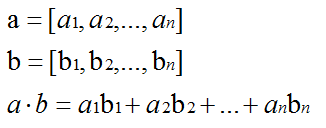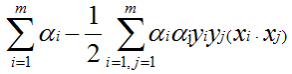from sklearn import svm
import numpy as np
import pandas as pd
- 569条样本数据
- 字段:32个
- 目标(标签):diagnosis
- 特征:除了标签以外的字段
- id对分类毫无意义:去除
- 其它30个字段:mean,se,worst 分为三组
df = pd.read_csv("svm_data.csv")
df.info()
df.head()

2. 数据处理
- B良性-->0
- M恶性-->1
B映射为0
M映射为1
df["diagnosis"] = df["diagnosis"].map({"M":1,"B":0})
id无用,删除
df = df.drop("id",axis=1)
特征字段分为三组
- _mean(特征均值)为一组
- _se(特征标准差)为一组
- _worst(特征最差值)为一组
实现:[radius_mean,texture_mean...]
features_mean = df.loc[:,"radius_mean":"fractal_dimension_mean"].columns.tolist()
features_se = df.loc[:,"radius_se":"fractal_dimension_se"].columns.tolist()
features_worst = df.loc[:,"radius_worst":"fractal_dimension_worst"].columns.tolist()
print(features_mean,features_se,features_worst,sep="\n")
特征筛选原因:
30个特征很容易过拟合
训练时间消耗过长
import seaborn as sns
from matplotlib import pyplot as plt
sns.countplot(df["diagnosis"])
plt.show()
筛选特征-->降维
- 选择mean这组特征。在mean这组特征里面每个特征都一定需要嘛?
- 观察mean这组特征里面两两特征之间的相关性
- 相关程度非常高:选择其中一个作为代表即可
mean_corr = df[features_mean].corr()
mean_corr
来进行相关性的可视化
- 热力图:颜色越浅说明相关程度越大
- annot=True-->显示每个方格的数据
plt.figure(figsize=(14,8))
sns.heatmap(mean_corr,annot=True)
plt.show()
得出来radius perimeter area 之间的相关程度很高。任意一个代表
得出来compatctness,concavity,concave_points 之间的相关程度很高。任意一个代表
features_remain = ['radius_mean',
'texture_mean',
'smoothness_mean',
'compactness_mean',
'symmetry_mean',
'fractal_dimension_mean']
4 数据分割
from sklearn.model_selection import train_test_split
train,test = train_test_split(df,test_size=0.3)
train_X = train[features_remain]
test_X = test[features_remain]
train_y = train["diagnosis"]
test_y = test["diagnosis"]
- 数据归一化
5 数据归一化
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
train_X = ss.fit_transform(train_X)
test_X = ss.fit_transform(test_X)
- 模型训练及预测
6 模型训练及预测
from sklearn.svm import SVC
model = SVC()
model.fit(train_X,train_y)
predictions = model.predict(test_X)
predictions
7 模型评价
from sklearn.metrics import accuracy_score
accuracy_score(test_y,predictions)

整体来说,效果相比我们之前的分类模型,效果可以说是很不错滴,另外也可以选择其他特征组,或者三个特征组一起加入~
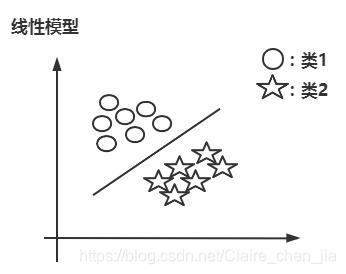
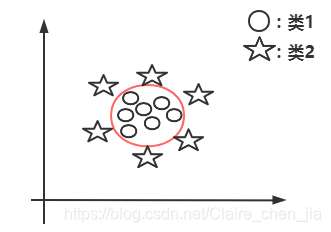
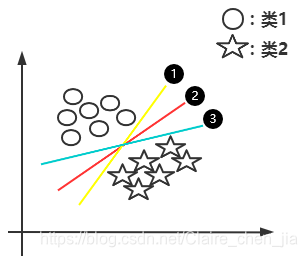
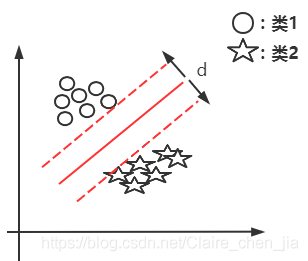
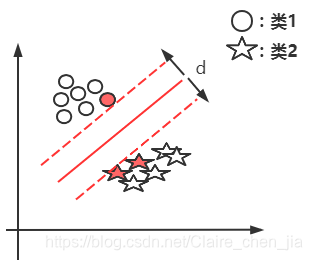
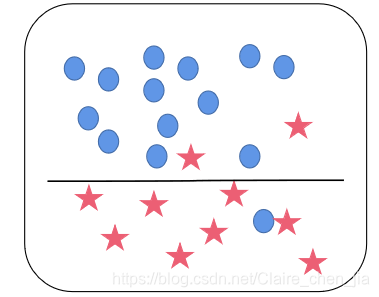
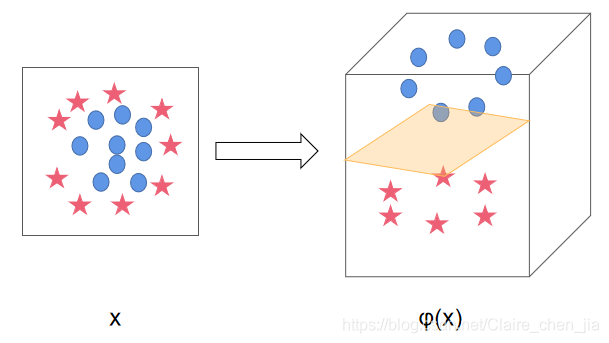
本篇博客具体学习参考:1 【机器学习】支持向量机SVM及实例应用2 【ML】支持向量机(SVM)从入门到放弃再到掌握这两篇文章讲得特别清楚,数学推导(第一篇)也能看明白,强烈推荐学习~~本篇博文介绍仅在二维展开,以此推展到多维。整体思路大致为:先整体介绍SVM,然后介绍线性可分样本集下SVM的应用思路是如(重点概念,数学推导);接着推到非线性可分样本集;最后介绍SVM的api应用和举例实现SVM算法介绍及实现1 SVM算法介绍-线性可分思路1.1 线性可分样本集与非线性可分样本集1.1.1 线性