|
|
|


在华为2012实验室工作是一种怎样的体验?
关注者
271
被浏览
1,014,251
13 个回答

2012实验室不是一个实验室,它是华为的一个部门,而且在华为内部是与消费者BG平级的一级部门,下辖几十个研究院或研究中心,分布在全球各地,比较有名比如有俄罗斯的数学研究所、巴黎的美学研究中心、日本的材料研究所...广罗全球顶尖人才,是华为发展和保持领先的动力引擎。
我一个小小的外包,在其下属的最核心的部门-研发能力中心呆过两年,最大的感受就是华为招人不惜血本!只要你够牛逼,工资你自己开。除了社招专家外,也有校招,不过校招的要求也极高,至少211,一般都是985的。我在的那个部门基本上都是名校硕士以上学历,反正都是学霸来着。
他们有华为人特有的书生气质,比较单纯,好像没听说谁爱打牌赌博什么的,比较喜欢加班(不过也不是像外面传的那种华为加班狂文化——什么天天通宵,累了就睡在公司。确实都有那种行军床,不过是用来午休的,很少有人通宵加班),可能是受华为的奋斗者文化影响,总体印象中都比较上进吧。
华为的很大一部分专利都来自2012,所以部门里面好多同事都有专利在身,专利在这里一点都不稀奇。很多楼层的走廊墙上都贴满了专利。
华为是一家国际化的公司,很多项目都是在国外的,因为项目的原因,他们经常要出差,去国外一线或其他研究所做支援或交流学习,大多数老员工都有一年以内的国外公干经历,也有的一去要两三年,确实面临很大挑战,尤其是有家庭的。
所以印象中华为人都很拼,天道酬勤,他们也获得了丰厚的物资回报。部门里五年以上的老员工基本上都有房有车,很多老员工都不只一套房。
因为是研发部门,对员工的能力要求也是越来越高,外传的四十岁危机确实不假,我就亲眼见到好几个四十岁左右的老员工离职,人老了干不动了是天然规律,华为这方面确实做的有点残酷,让人唏嘘。所以华为人外表虽然风光,内心其实都有很强的焦虑感。
所以华为人都在拼命工作,争取在四十岁之前能实现财务自由,有房有车,还有不菲的存款。正所谓,有房在手,心里无忧,在深圳这地方,干到四十岁,有两三套房子,基本后半辈子都不愁了,到那时,离不离职都无所谓了,甚至很多人主动辞职去开创自己的第二事业。


我是华为 2012 实验室中央软件院分布式与并行软件实验室计算机网络与协议实验室的博士,这是我们实验室在做的工作,我相信是网络领域世界领先的研究。2022 年 12 月 12 日,我在北京大学做了一个报告,整理到这里,供大家参考。
按照知乎传统,先把总结放到前面,后面三万多字的演讲全文太长不看。
今天,我们讲到了数据中心、广域网、无线网络领域的一些最新进展。从 “把数据中心作为一台超级计算机”、“全国一体化大数据中心” 到 “鸿蒙分布式超级终端”,网络都是其中非常关键的组成部分。以往我们认为总线仅仅是单台服务器、单台设备内部的高速互联硬件,而如今高性能的数据中心网络和鸿蒙分布式软总线模糊了服务器和终端设备的边界,“总线网络化” 和 “网络总线化” 成为历史的潮流。未来的硬件总线需要吸收网络领域的设计以便扩展到更大的规模,而网络和通信原语的设计需要吸收高速总线的思想以提高性能。
我认为,网络和系统领域创新的两大驱动力是应用需求和硬件能力。
- 如今,在数据中心领域,AI、大数据、高性能存储、科学计算等对算力和存储容量的需求增长速度超过摩尔定律,使得我们需要越来越大的集群来做分布式并行计算,而网络是其中的关键瓶颈。在终端领域,工业互联网、AR、VR、高清实时音视频、分布式协同等应用也对广域网和无线网络的带宽和时延,特别是稳定的带宽和时延,提出了新的需求。
- 而在硬件能力方面,网络的性能尚未见顶:数据中心网络即使用了 RDMA,与 NVLink 等高速总线的性能之间仍有一条巨大的鸿沟;广域网的路由器交换性能远未达到光纤容量的上限;终端领域的 Wi-Fi 6、毫米波、卫星通信等也有巨大的挖潜空间。
- 再看软件,事实上厚重的软件协议栈和落后的传输协议远远不能充分利用现有硬件的能力,不管是数据中心还是广域网,内核的 TCP/IP 协议栈都浪费了数倍到数十倍的硬件能力。这是由于传统网络协议栈运行在通用处理器上,假定通用处理器的算力增长符合摩尔定律,但这已经不再是事实。随着异构算力和存储性能的快速增长,网络协议栈愈发成为瓶颈,因此需要软硬件协同设计,重新定义通信原语,也就是重新划分软件和硬件各自负责的事务。
因此,我认为计算机网络也进入了一个黄金时代,其中有无数的问题等待我们一起探索,特别是其中的软件部分,软硬件协同设计和软件协议栈优化都将是未来 10 年的重要课题。
计算机系统的三驾马车是计算、存储、网络。作为系统基础架构的一部分,网络往往是坏了的时候才会被人想起。只要哪个应用挂了,大家往往第一时间想到的就是网络问题。这说明我们的网络目前还不够鲁棒,而且故障定位、故障自愈的能力还不够强。但我认为网络的可靠性问题一定是可以解决的。就在短短 20 年前,我们还经常需要到处找地方上网。今天,网络已经几乎无处不在,但信号不好还是常事。未来,断网也许将成为罕见的事故。即使百年之后,我相信网络仍然会作为计算机系统的基石,成为万物互联的智能世界背后默默奉献的力量。
演讲全文
非常感谢黄群教授和许辰人教授邀请,很荣幸来到北京大学为两位教授的计算机网络课程做客座报告。我听说你们都是北大最优秀的学生,我可是当年做梦都没进得了北大,今天能有机会来跟大家交流计算机网络领域学术界和工业界的一些最新进展,实在是非常荣幸。
图灵奖得主 David Patterson 2019 年有一个非常有名的演讲,叫做《计算机体系结构的新黄金时代》( A New Golden Age for Computer Architecture ),它讲的是通用处理器摩尔定律的终结和领域特定体系结构(DSA)兴起的历史机遇。我今天要讲的是,计算机网络也进入了一个新黄金时代。
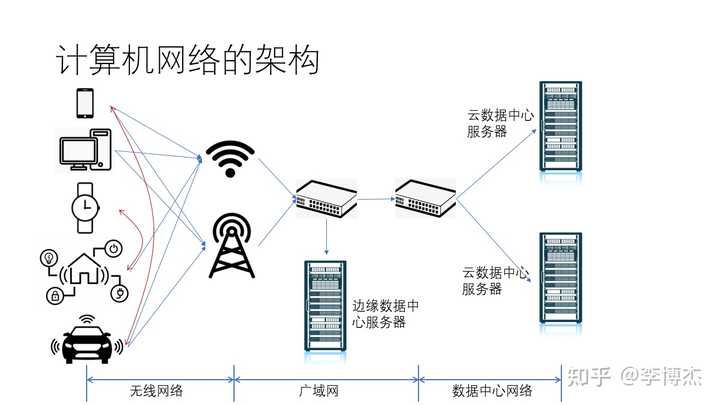
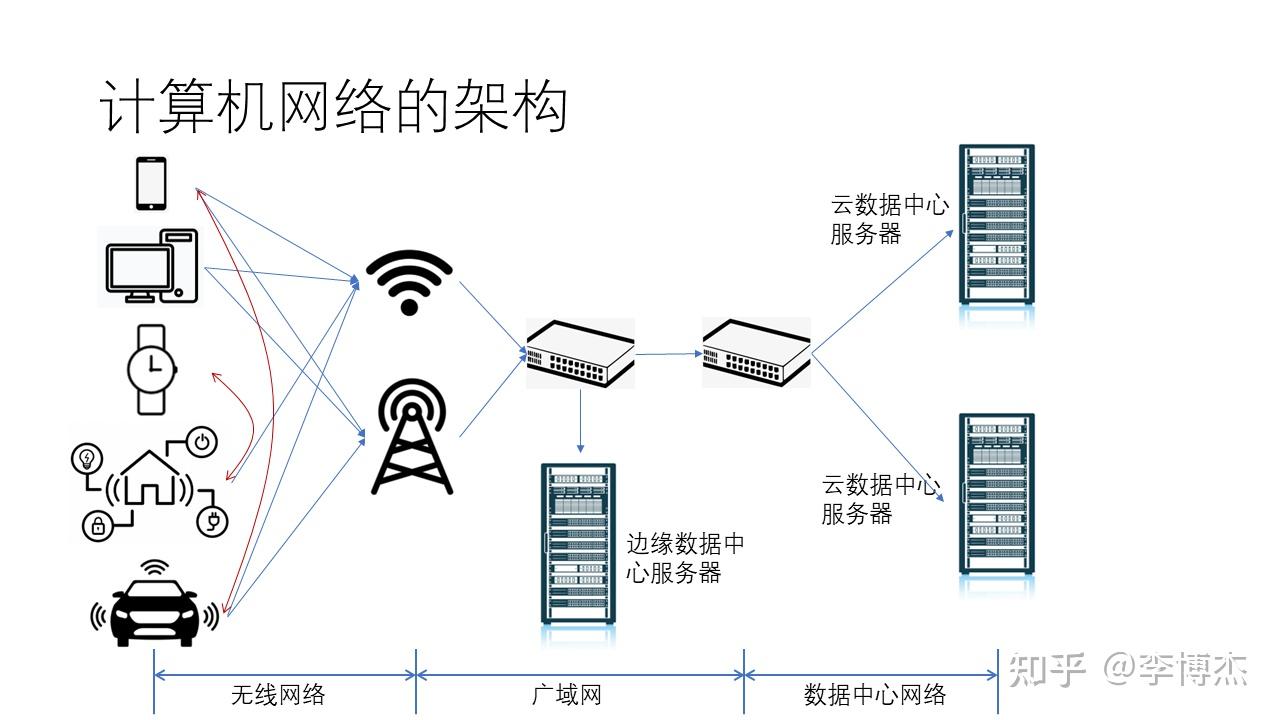
我们日常接触到的计算机网络主要由三大部分组成:无线网络、广域网和数据中心网络。它们为万物互联的智能世界提供了通信基石。
其中,无线网络的终端设备包括手机、PC、手表、智能家居、智能汽车等各种设备。这些设备通常是通过无线方式(如 Wi-Fi 或 5G)访问网络。经过 5G 基站和 Wi-Fi 热点之后,设备将进入广域网。广域网中还有一些 CDN 服务器,这些服务器属于边缘数据中心。接下来,设备将进入数据中心网络。在数据中心网络中,还有许多不同类型的设备,如网关、服务器等。


今天,我将分别从数据中心网络、广域网和终端无线网络这三个领域给大家做一些介绍。首先,让我们来看数据中心网络。数据中心网络最大的变化是从为简单的 Web 服务设计的简单网络,演变成为大规模异构并行计算所设计的网络,执行 AI、大数据、高性能计算等传统上超级计算机才能处理的任务。
从 Web 服务到大规模异构并行计算
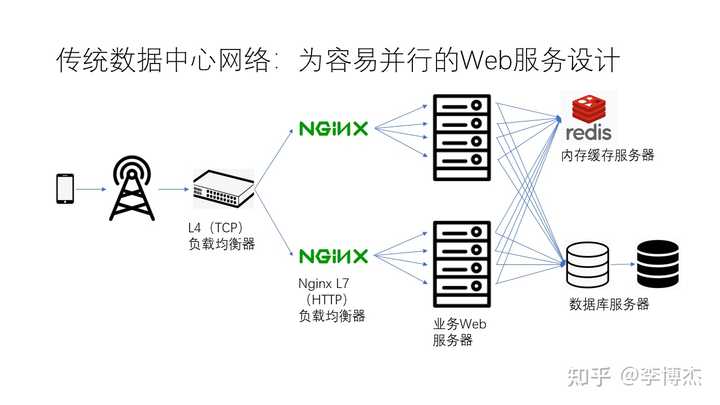
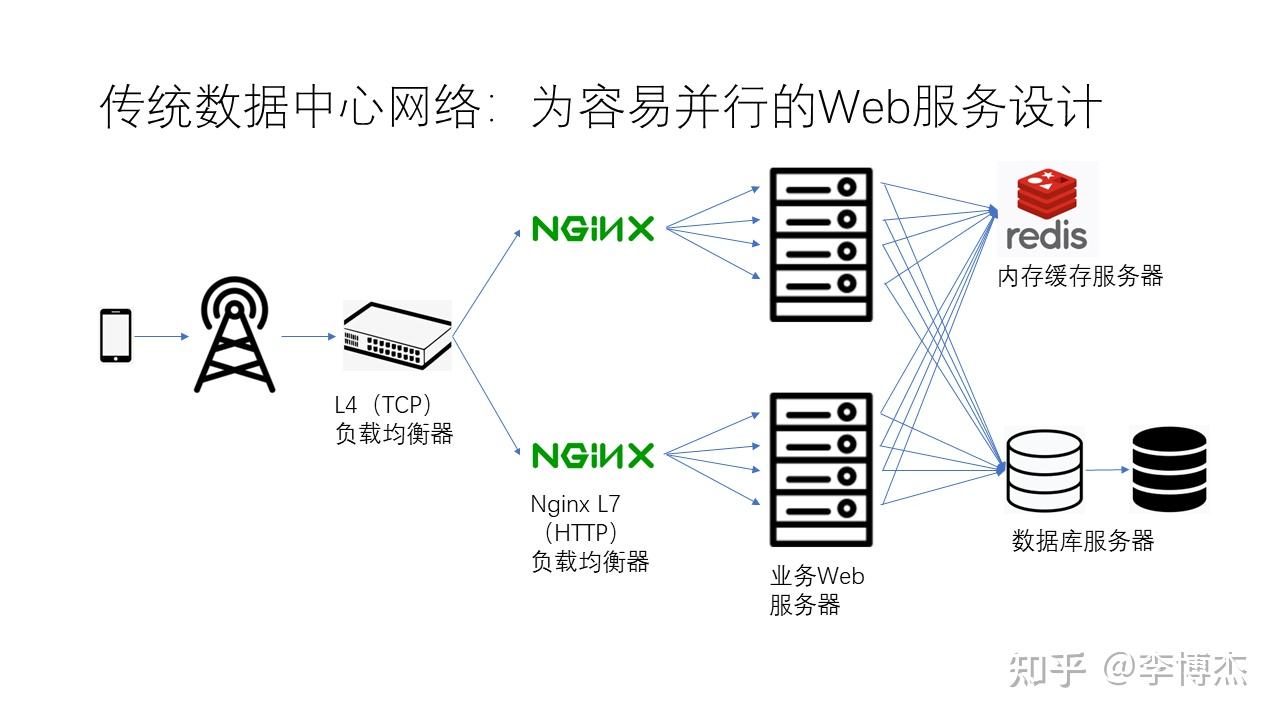
传统的数据中心网络是为了易于并行处理的 Web 服务而设计的。当我们的手机访问数据中心网络时,首先会进入一个四层负载均衡器,然后再进入一个七层负载均衡器。四层负载均衡器负责将不同的连接分配到不同的服务器上,而七层负载均衡器则可以进一步按照一定策略将这些连接分发到业务的 Web 服务器上。Nginx 就是一个典型的七层负载均衡器。
我们业务的 Web 服务器通常使用 Python、Java 或 Node.js 等语言编写。Web 服务器在处理 HTTP 请求的业务逻辑时,可能会访问内存缓存服务器,也可能会访问数据库。为了容灾,数据库服务器一般有多个副本,例如在上图中,白色表示主节点,黑色表示备份节点。
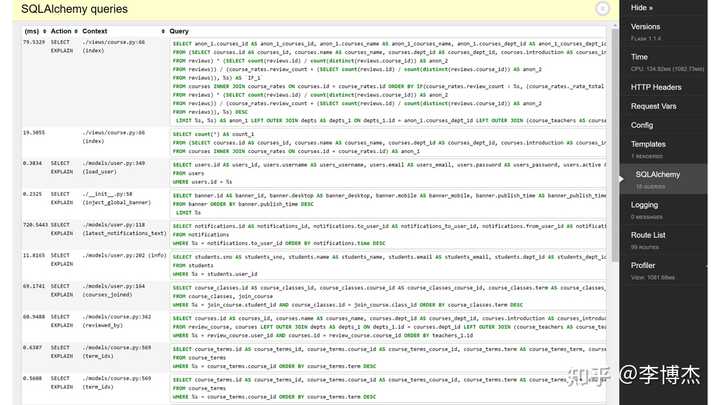
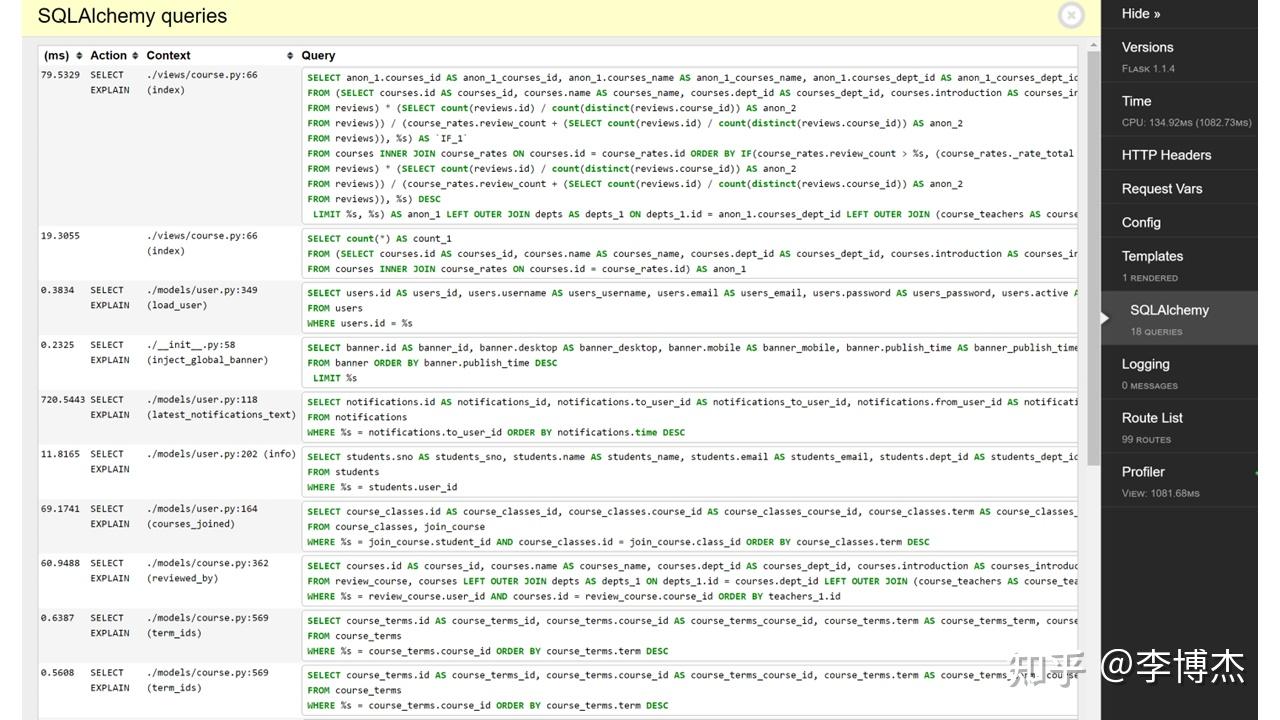
事实上,传统的 Web 服务对于数据中心网络的延迟并不敏感。例如,我在学校开发的一个使用 Flask 制作的网站,打开一个网页的延迟基本上是秒级的。而处理网页的延迟在百毫秒量级,用户很难感知到百毫秒以内的延迟。广域网的延迟通常在几十毫秒到几百毫秒量级,数据中心内网的延迟即使是毫秒级,但相较于百毫秒级的数据处理延迟(包括数据库延迟以及业务处理延迟),其实都是一个较小的数量级。因此,数据中心网络的延迟在这种场景下并不是一个关键因素。
从上图中我们可以看到,整个网页的后端渲染时间花了 1000 多毫秒,其中 Flask 的后端业务逻辑占用了 134 毫秒的 CPU 时间,剩下的大部分时间都花在数据库查询,也就是 SQL 语句的执行上。有些数据库查询可能优化得不太好,时间较长,需要 720 毫秒;而有些查询可能只需要几十毫秒甚至几个毫秒。
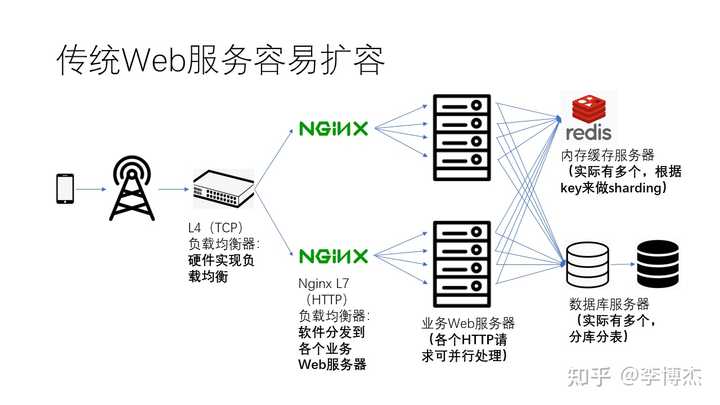
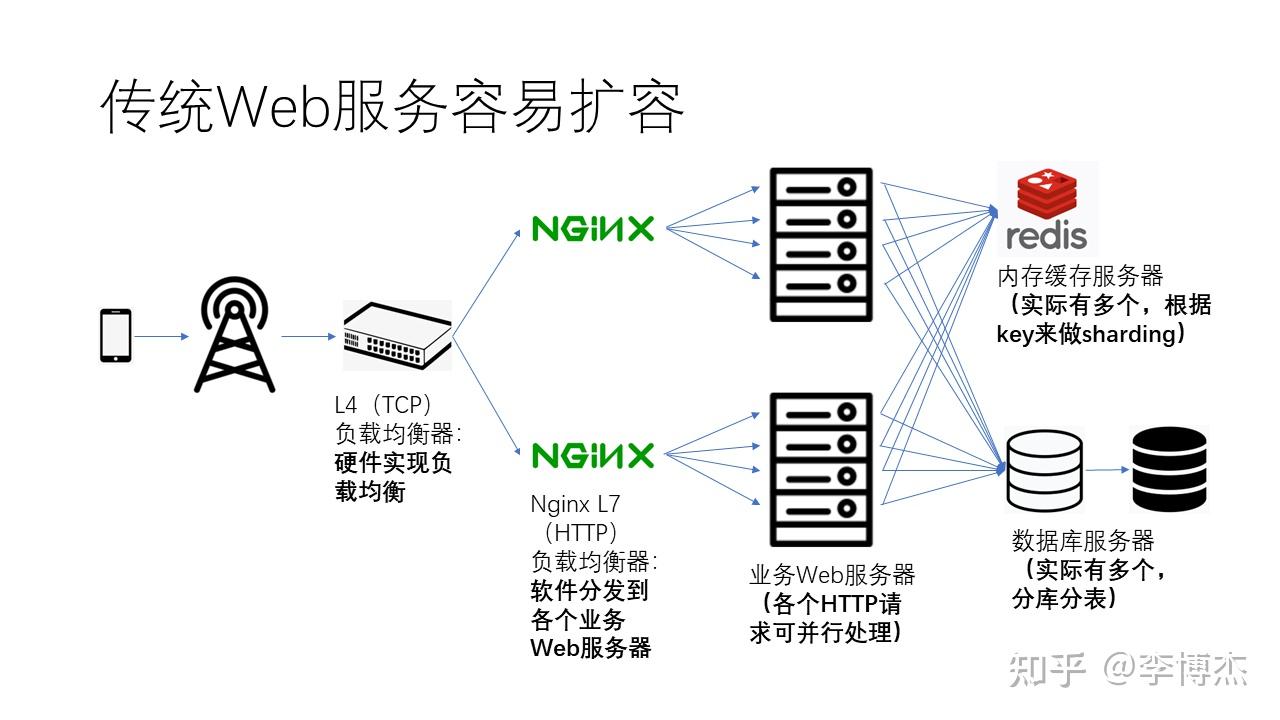
刚才我们讲到,Web 服务对于数据中心网络的延迟并不敏感。另一方面,Web 服务也相对容易扩展,也就是容易通过增加机器数量的方式来提升整体的性能。
具体来说,当一个应用服务器不够用时,我们可以增加负载均衡器的数量。正如之前提到的,四层负载均衡器可以通过硬件实现负载均衡,而七层负载均衡器可以通过软件将不同的网络连接分散到不同的业务服务器上。这样一来,可以实现非常高的并发程度。在业务的 Web 服务器上,每一个 HTTP 请求实际上都可以并行处理。
而在内存缓存服务器上,由于单个服务器的容量和处理能力都无法满足所有用户的需求,所以实际上会有多个内存缓存服务器。一般来说,内存缓存服务器中存储了大量的键-值(key-value)映射,其中的键(key)和值(value)可以简单理解成是一个字符串。这样,内存缓存服务器就可以根据键(key)的哈希值进行分片,也就是每个键值服务器负责一个范围的键值映射。
数据库服务器在实际应用中,通常会有多台,一方面是为了扩展数据库容量与处理能力,另一方面是为了容灾。当一个数据库在单台服务器上容纳不下时,数据库管理员(DBA)需要把数据分配至多个服务器,也就是所谓的分库分表。具体而言,数据的划分方式可以是横向划分,也可以是纵向划分。通过对多个表的划分,数据库不仅扩大了容量,还增强了处理能力。


如果仅仅考虑传统的 Web 服务,现有的数据中心网络和内核的 TCP 协议栈已经足够应对需求。那为什么说计算机网络进入了一个新黄金时代呢?不管网络、系统还是体系结构,最大的两个驱动力始终是应用需求和硬件能力。
数据中心网络能够发展得这么快,根本原因是人工智能(AI)、高性能计算(HPC)、大数据、存储等新兴业务对带宽和延迟提出了更高要求。而我们的网络硬件性能还没有触到天花板,可以匹配上应用的需求。新的网络硬件又对上层的软件和系统带来新的需求,这就带领整个行业不断有新的事情可做。
以 2022 年的 stable diffusion 生成模型为例,这个计算机视觉(CV)生成模型令人叹为观止,能根据用户输入的提示词(prompt)生成精美图片。该模型的训练使用了 256 个英伟达 A100 GPU,耗费 15 万 GPU 小时,共计花费 60 万美元。


两周前(注:相对 2022 年 12 月 12 日),OpenAI 发布了 ChatGPT,一个基于 GPT-3.5 和 InstructGPT 的 AI 问答系统。对于 ChatGPT,许多人可能尚不了解。事实上,ChatGPT 具备强大功能,首先是其强大的思维链能力。给定提示词,它可以根据用户的思路生成回答。其次,它具备出色的代码逻辑思维能力,能编写如 Protocol Buffers 地址簿等代码。此外,它还能帮助修复代码中的 bug。相比传统的 NLP 大模型,一个显著优势是其卓越的记忆能力,能够回顾前面的内容,解决指代的难题。在过去的自然语言处理(NLP)领域,各种任务需分开处理,而在 ChatGPT 中,所有这些问题都得到了统一解决。尽管 ChatGPT 目前尚未广泛普及(注:2022 年 12 月 12 日原演讲内容),但未来它必将成为颠覆性的创新。
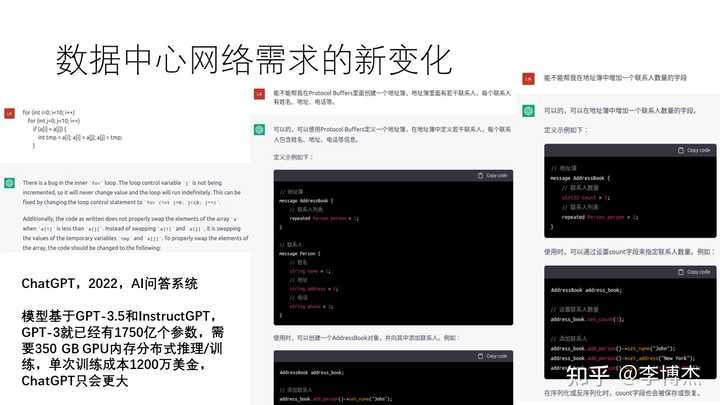
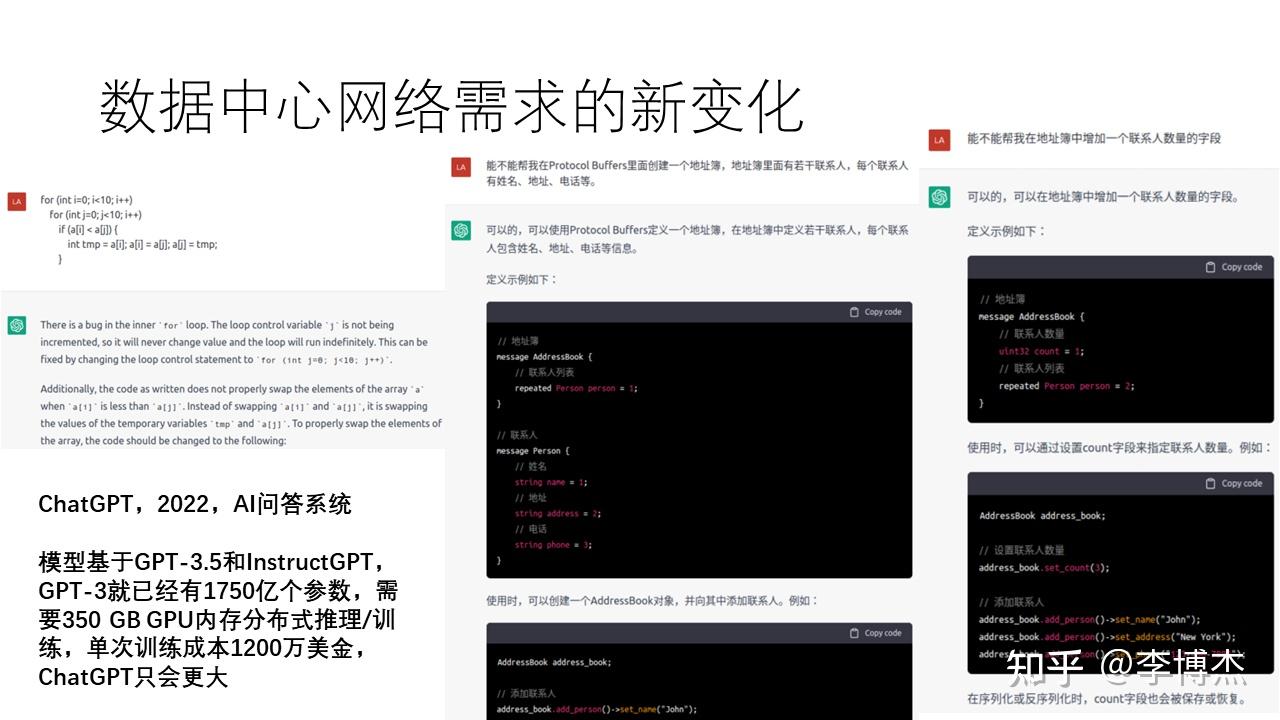
GPT-3.5 的上一代模型 GPT-3 已具备 1750 亿参数,单是推理就需要 350 GB 的 GPU 内存,单张 GPU 卡肯定是放不下的,需要多张 GPU 卡组成分布式推理集群。训练需要存储反向传播中的状态,需要的内存容量更大。这一模型的训练成本高达 1200 万美元,可能需要上万块 GPU 组成的集群来做训练。虽然 GPT-3.5 的规模尚不明确,但很可能也是一个庞大的模型。为什么模型需要这么大,其根本原因是存储的知识多,上知天文,下至地理,还懂多种语言。
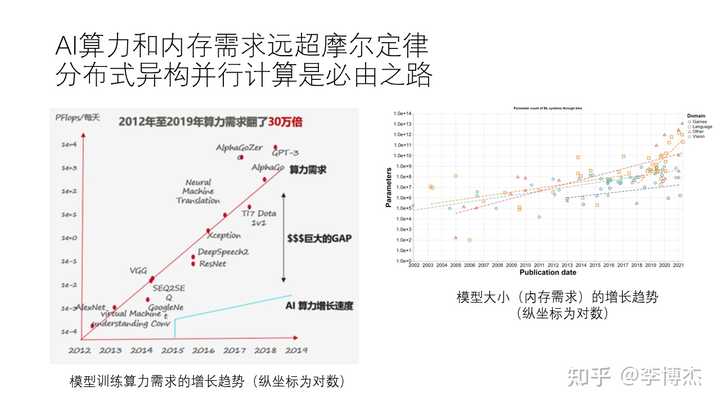
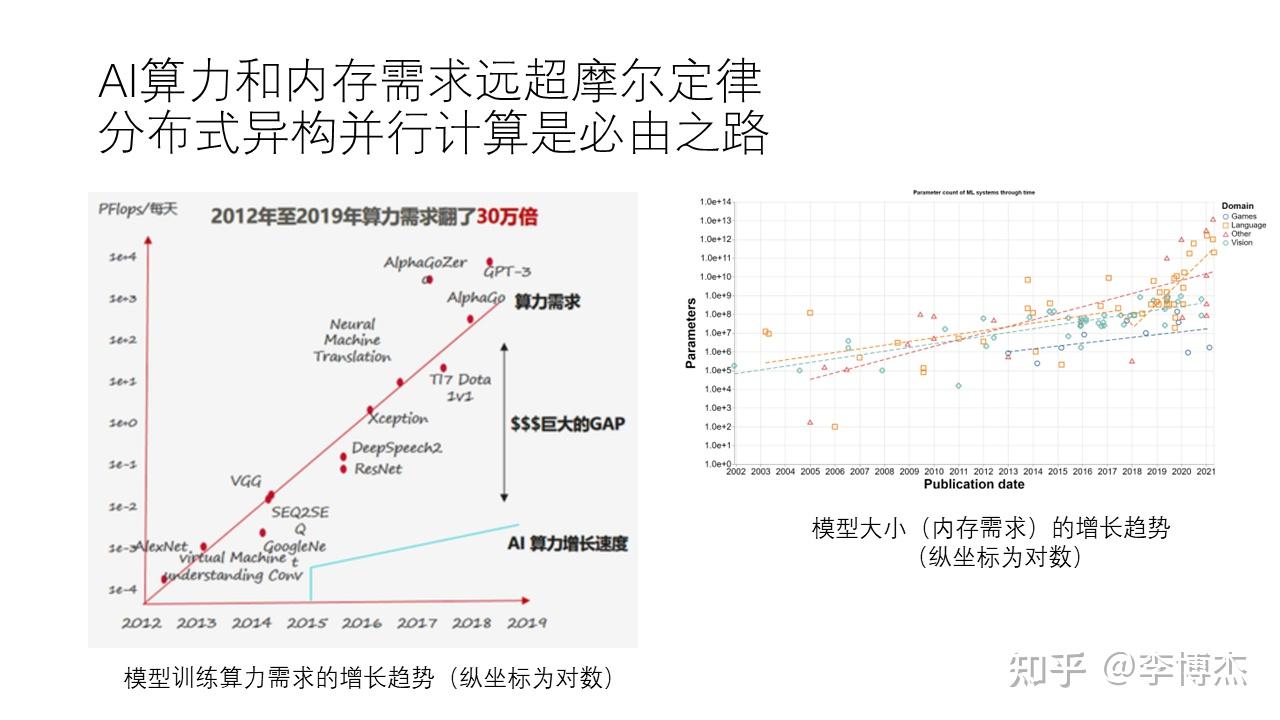
我们来看一下这些 AI 模型对于计算能力和内存需求的增长趋势。在 2012 年,最早的 AlexNet 问世;到了 2014 年,有了 GoogleNet;之后是 2015 年的 Seq2Seq,2016 年的 ResNet。到了 2018 年出现了 AlphaGo 和 AlphaZero,最后在 2020 年出现了 GPT-3 等。我们可以看到,从 2012 年到 2020 年,这些模型对算力的需求增长速度非常快,翻了 30 万倍。这个增长速度并不像摩尔定律那样每 18 个月翻一倍,而是在 18 个月内翻 40 倍,非常惊人。
然而,我们的 AI 算力,即单个 GPU 的算力增长速度,实际上还是相对遵循摩尔定律的,因为它毕竟是硬件。这么巨大的需求差距要求我们必须采用分布式并行计算来满足这些需求。
从另一个角度来看,大模型的内存需求也非常大。我们可以看到,不同的模型对内存的需求也在增长,越大的模型通常意味着越高的内存需求。例如,我们之前提到的 stable diffusion 和 ChatGPT 等模型,在单个 GPU 中很可能是放不下的,需要更多的 GPU 资源才能完成推理。
训练需要的集群规模就更大了,ChatGPT 很可能是用成千上万张卡并行计算的。这些 GPU 之间需要的通信带宽是极高的,需要达到 100 GB/s 以上,远远超过目前以太网或者 RDMA 网络所能提供的带宽。因此,新型模型对数据中心网络的需求极高。目前,小规模 GPU 集群内的通信是通过超高带宽的 NVLink 专用硬件进行的,带宽最高可达 900 GB/s。但是 NVLink 只能用于几百块卡的小规模互联,大规模互联仍然要通过比 NVLink 慢几十倍的 Infiniband 网络,带宽只能达到 20 GB/s。
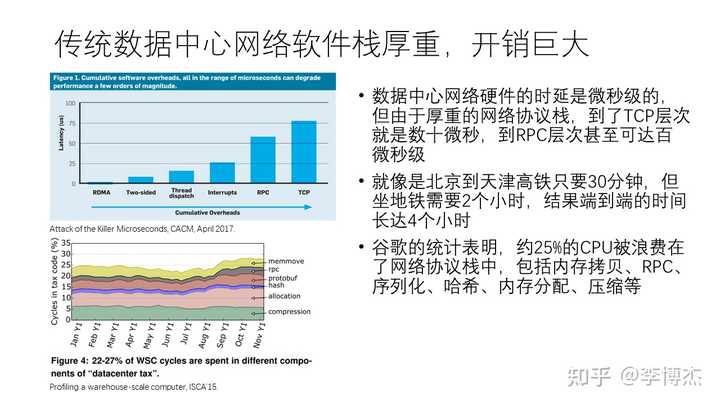
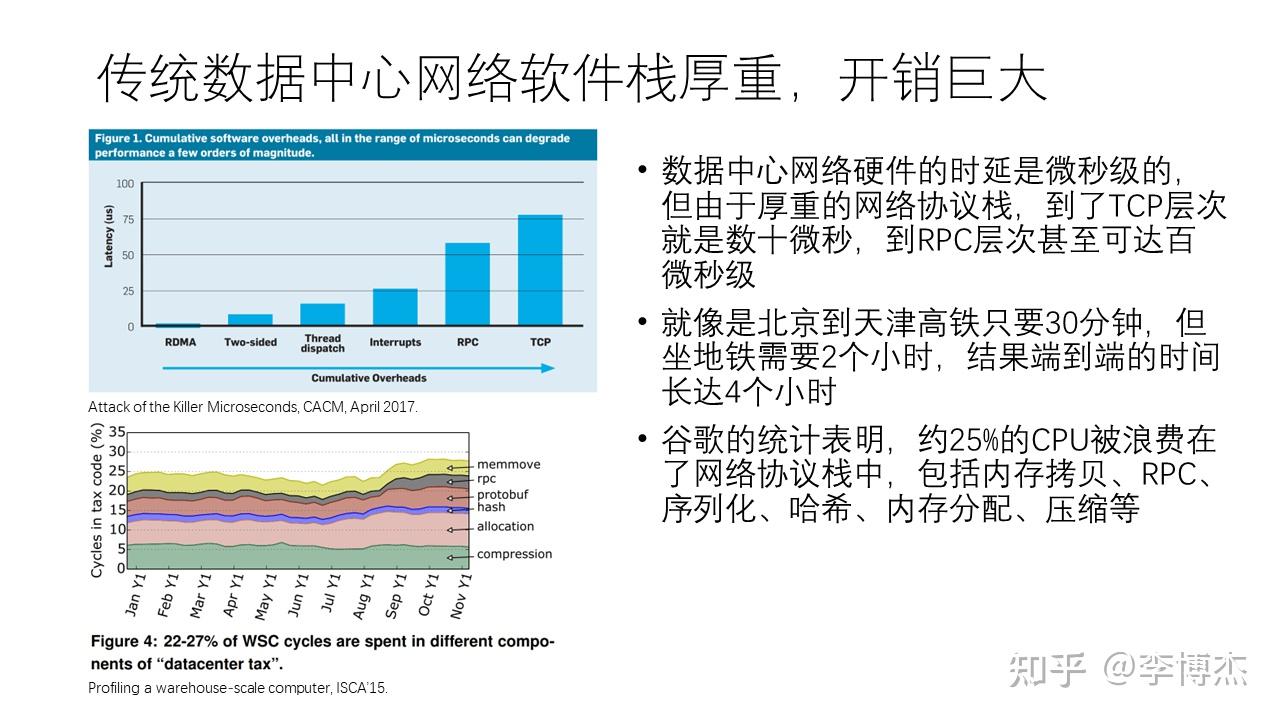
传统的网络协议设计于上世纪七八十年代,那时的处理器速度的发展速度超过网络的发展速度,而且应用对网络通信的时延和带宽并不敏感,因此网络协议都是 CPU 上的软件在处理。CPU 上的软件栈实际上相当复杂,开销非常大。
虽然数据中心网络硬件的延迟是微秒级,但是由于网络协议栈的复杂性,到了应用层,延迟可能会增加几十倍,甚至在 RPC 层次上达到百微秒级别。打个比方,从北京到天津,坐高铁只需要 30 分钟,但由于在市区内需要乘地铁花费两个小时,所以端到端的时间可能需要四个小时。谷歌曾经统计过,大约 25% 的 CPU 资源被浪费在了网络协议栈上,包括内存拷贝、RPC 调用、序列化、内存分配和压缩等。谷歌将其称为 “数据中心税”,意味着这个负担太重了。
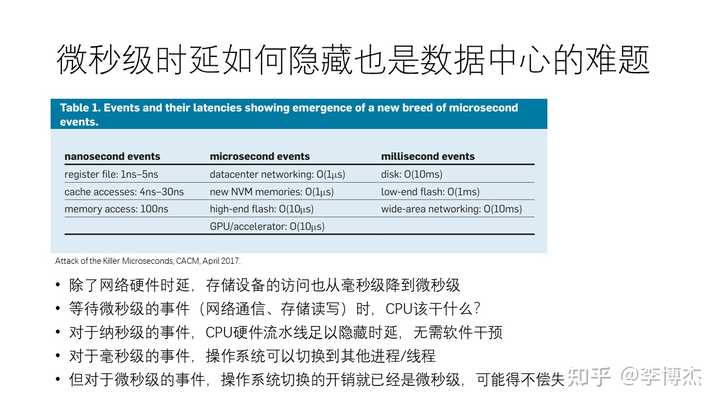
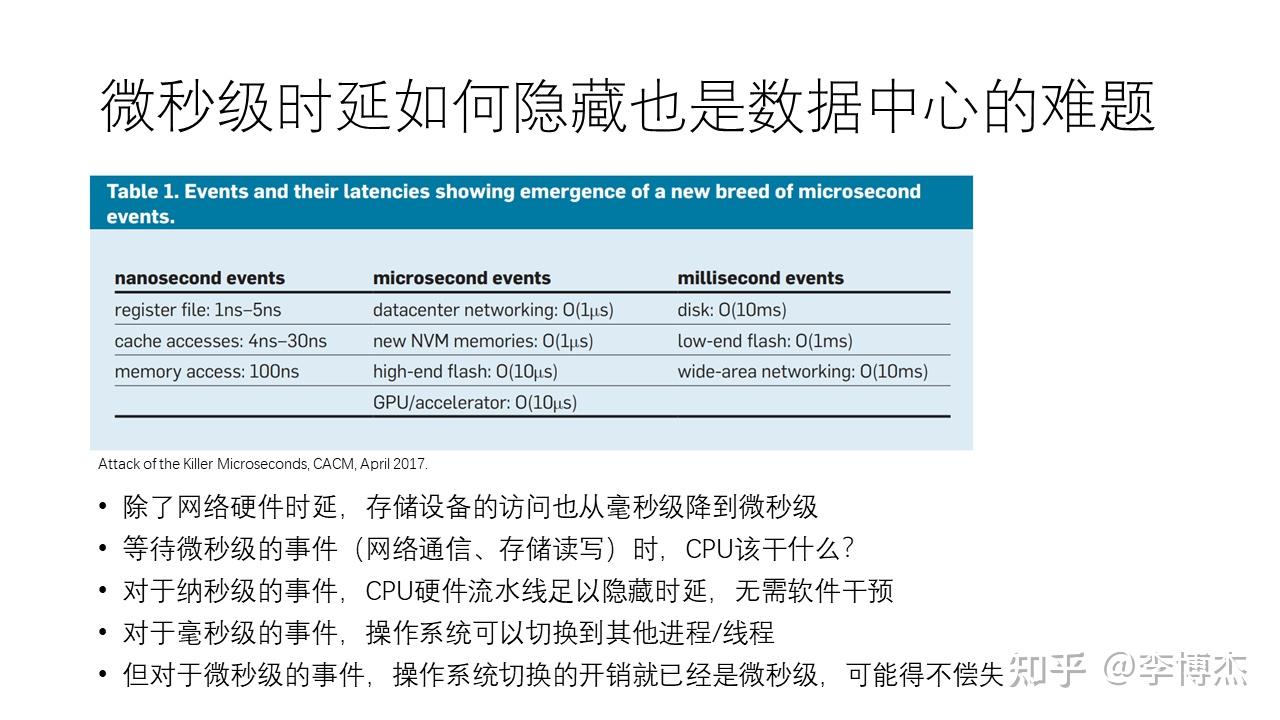
实际上,即使我们将延迟降到微秒级,许多应用也无法充分利用这个低延迟。其中一个原因是延迟隐藏问题。当我们等待这些微秒级事件时,比如进行网络通信或者存储设备的读写,CPU 应该去执行什么操作?在传统的计算机体系结构中,CPU 的流水线能很好地隐藏纳秒级事件。也就是说,在等待这些事件时,CPU 可以执行其他指令,而不需要软件干预。然而,对于微秒级时延的事件,CPU 的流水线深度不足以隐藏时延,因此 CPU 就会卡住等待这个慢速的指令,其效率是很低下的。
对于毫秒级事件,操作系统可以处理这些任务切换,这是软件的职责。操作系统在进行进程或线程切换时,只需几个微秒就能完成,因此不会浪费太多时间。但是,如果事件本身就是微秒级的,比如访问存储花费 10 微秒或访问高速网络花费 3 微秒,这时候如果将 CPU 核切换到其他进程或者线程上,操作系统本身就要花费几个微秒的时间。操作系统切换到其他进程或者线程,再切换回来,这个过程花费的时间可能比直接等待事件完成还要长。所以,对于微秒级的时延,操作系统的任务切换实际上是在浪费时间。
体系结构和操作系统的机制都不能隐藏微秒级的时延,而如今最先进的网络和存储硬件时延都降到了微秒级,这就是微秒级时间隐藏难题的原因。
编程抽象:从字节流到内存语义


接下来,我会介绍一些解决上述问题的方法。首先我们从编程抽象的角度来考虑。编程抽象是任何系统的关键部分,它涉及到设计功能以及相应接口。有一条著名的建筑学上的设计原则,“form follow function”(形式遵循功能),也适用于软件工程领域,也就是接口设计一定要遵循功能的描述。
我们很多人,包括我自己,都比较习惯在别人的生态基础上做改进,总是想要保证兼容性,提升一点性能,但不敢提出自己的生态,这就是一种生态迷信。历史上有巨大影响力的系统大多数不是把现有系统的性能提升了 10 倍,而是提出了自己的系统和编程抽象,满足了新的业务需求或者用好了新的硬件能力。
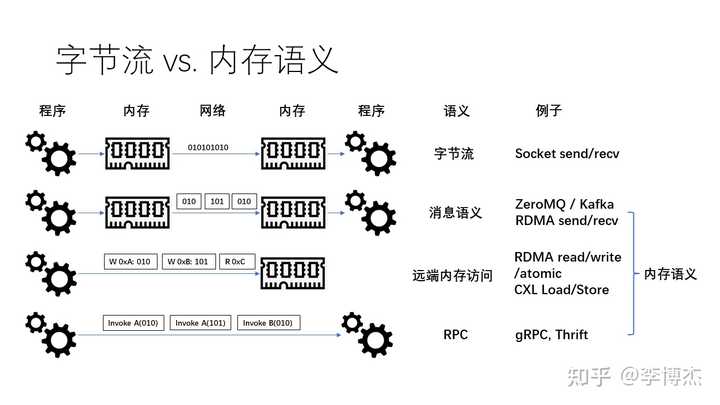
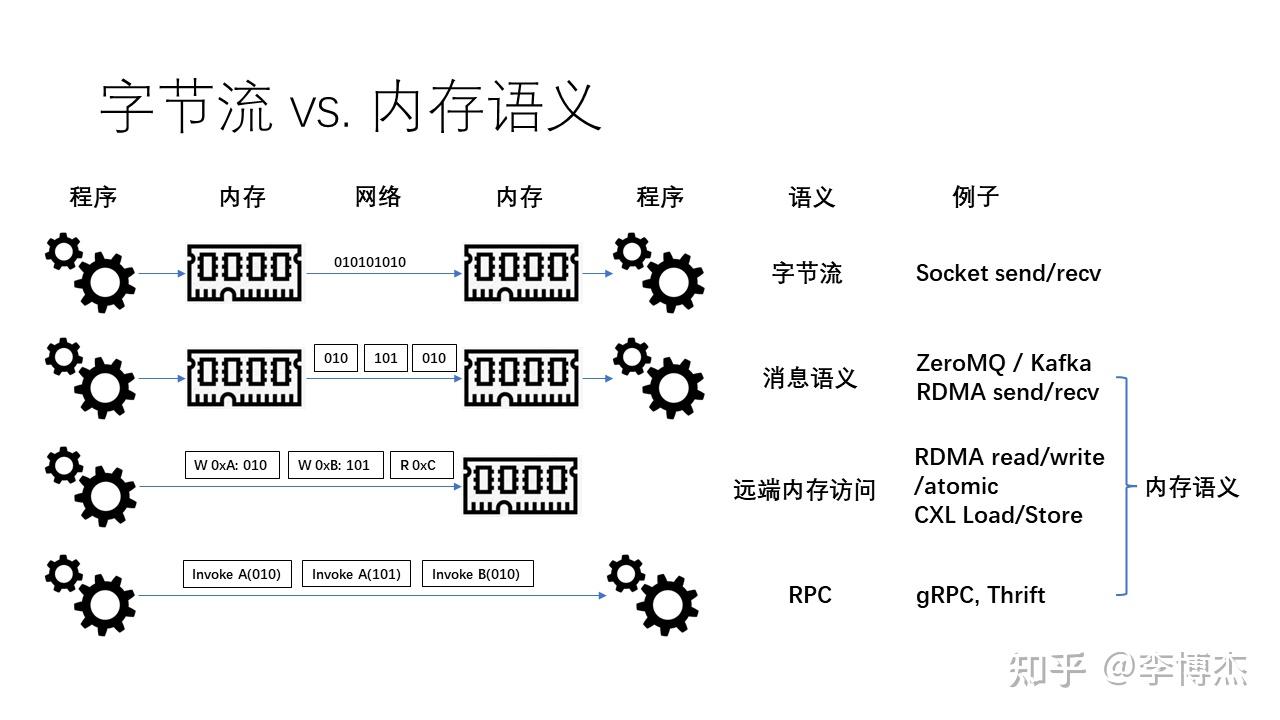
原来我们用的都是基于字节流语义的 socket,这是一个很漂亮的编程抽象,体现了 UNIX 操作系统 “一切皆文件” 的设计原则,把网络通信管道也当成是文件了。但是,字节流的抽象在很多场景下并不好用,它没有消息边界的概念,在发送端 send 1024 字节,在接收端接收到的可能不是 1024 字节的一个整体,而是分成了两块。这样就需要应用自己去做消息重组的事情。
为了解决这个问题,一些新的编程抽象逐渐引入了消息边界的概念。例如,ZeroMQ 和 RabbitMQ 等消息队列系统,它们提供了基于消息的抽象。在这种抽象中,数据被组织成一个个独立的消息,每个消息都有明确的边界。这使得应用程序不需要关心如何保证消息边界的问题。这种新的抽象使得分布式系统的开发变得更加简单和高效。
如果我们最终的目的就是为了提供基于消息的语义,为什么需要先提供一个字节流的语义,再在上面封装一个消息语义呢?因此,一些最新的网络协议栈直接在不可靠的数据报文基础上构建消息语义。其中典型的一个例子就是 RDMA(远程直接内存访问)。RDMA 支持一种称为 “发送-接收”(Send-Receive)的通信模型,其中发送方将消息放入一个发送缓冲区,然后让网卡发送,接收方首先将接收缓冲区注册到网卡,然后网卡将数据写入接收缓冲区,并通知接收方。这种提前注册缓冲区的方法避免了基于字节流的消息语义中数据必须拷贝的问题,进一步提升了性能。
在消息传递之外,我们还有一个更进阶的编程抽象,那就是远程内存访问。无论是字节流还是消息语义,一个程序通信的对象一定是另一个程序,但为什么我们不能让程序直接访问远程的内存呢?也就是说,在网络上发出直接读写远程内存的指令。我们可能会问,这种远程内存访问的语义有什么作用呢?
首先,我可以让多个程序共享一块远程的内存,也就是将一块内存当作多个节点共享去访问,这样的一种方式被称为内存池化。其次,如果对面的应用程序里面存储了一些数据,比如一个哈希表,那么访问这块数据的过程中可能不需要引入对方的 CPU,也就是在不打扰对方 CPU 的情况下完成了数据结构的增删改查。当然,不打扰对方的 CPU 需要硬件的支持,这也就是 RDMA(远程直接内存访问)中的 read、write 以及 atomic(原子操作)等技术。例如,原子操作是我们可以在本地发起,但在远程完成的内存操作。
RDMA 的这些远程内存访问操作都是异步完成的,而本地内存访问操作是同步的。有人提出,既然本地操作可以同步,为什么不能把同步的内存操作引入到远程呢?当然,在 RDMA 的情况下,因为延时较高,不太适合把操作变成同步的。因为同步操作意味着阻塞 CPU 的流水线,也就是说,CPU 在等待访问时无法执行其他任务,这会导致效率低下。
在诸如 CXL 这样的新型互联总线中,因为实现了极低的延时,比如只有两三百纳秒,比 RDMA 的延时低一个数量级,这个时候,我们就可以引入 load、store 这样的同步操作。也就是说,让 CPU 直接访问远程的内存,就像访问本地内存一样,应用程序无需进行修改。这样的做法极大地方便了应用程序的编程,但它带来的后果是访问远程内存的粒度较小,因此它的效率可能会比异步访问的方式更低一些。
在字节流消息和远程内存访问之外,我们还有一种称为 RPC 的通信方式,实际上是程序与程序之间的一种交互,也就是远程调用。程序语言里的函数调用我们都很熟悉,它就是一个本地调用。如果我们想要调用另一个程序里的函数,就需要通过 RPC 的方式去实现。现在有很多的 RPC 框架,如 gRPC 和 Thrift 等。
我们将消息语义、远程内存访问和 RPC 统称为内存语义。这个内存语义的定义可能比一般人认为的更加广泛,也就是说,大部分人认为只有程序直接访问远程内存才叫做内存语义,但实际上,我们认为消息语义和 RPC 也属于内存语义,因为它们都涉及到程序与内存之间的交互。


那么,为什么我们需要内存语义而不是字节流呢?首先,刚才我们讲过,字节流的抽象层次太低,没有消息边界的概念,所以应用程序需要进行封包和拆包,增加额外的内存拷贝。
其次,字节流是一个有序的流,所以不能充分利用通信中的并行性,例如利用多条物理链路,数据中心里面有不同的物理路径,无线网络有 Wi-Fi 和 5G。
同时,字节流无法区分消息的重要性和优先级需求,所以在同一个流(同一条连接)内不能按照优先级进行服务。如果要区分优先级,那就只能建立多条连接,这就意味着需要维护大量的连接状态,并为每个连接预留缓冲区,导致内存占用量较大。内存占用量大不仅仅是内存开销的问题,同时也会占用大量缓存,导致缓存命中率降低,从而降低整个网络协议栈处理报文的性能。
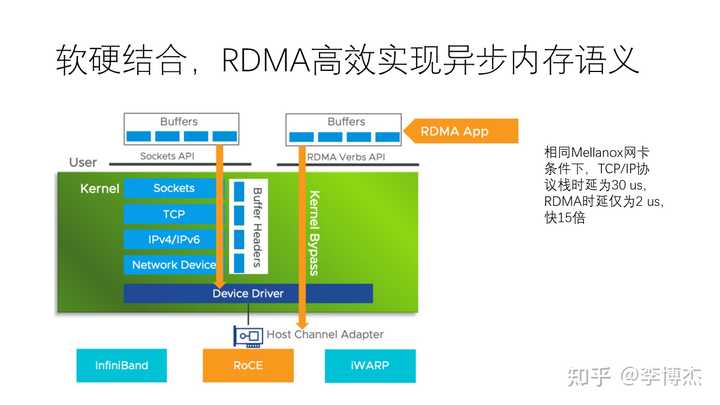
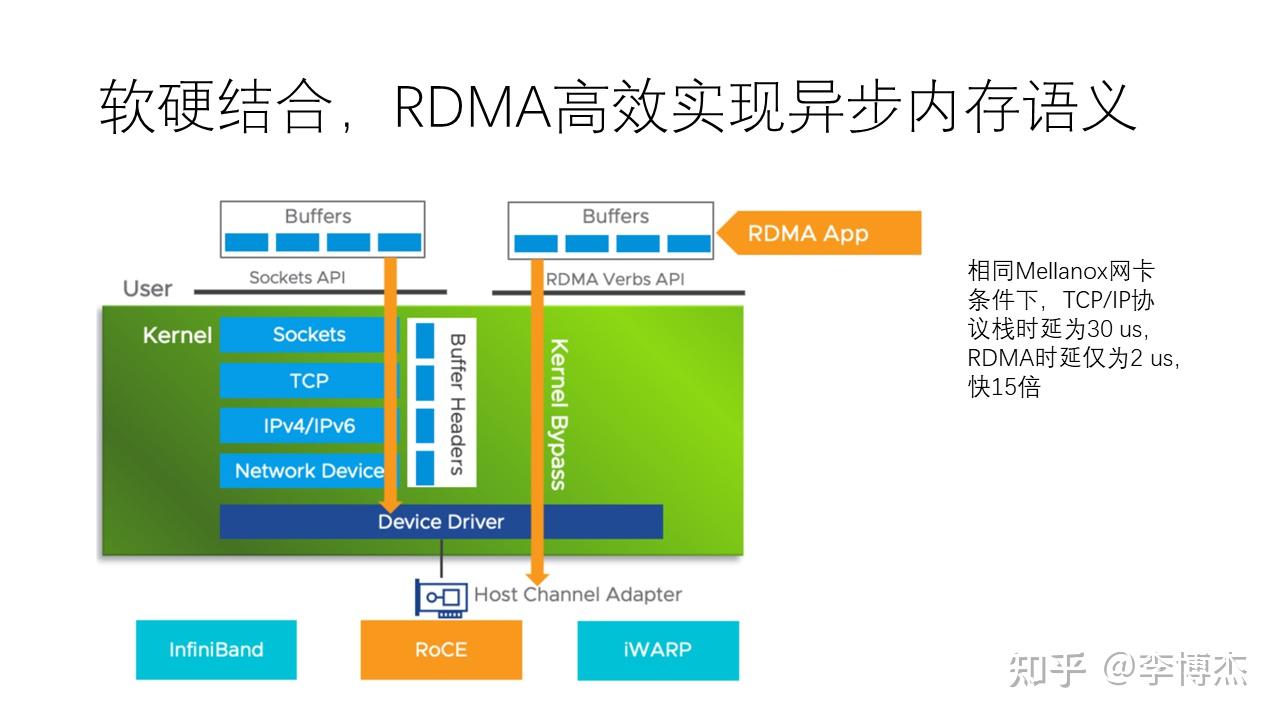
RDMA 技术实际上是一种软硬结合的高效实现内存语义的方法。在同样的硬件下,如果使用传统的 TCP socket 协议栈,需要大约 30 微秒的时间,但如果使用 RDMA 协议,它只需要 2 微秒的时间,快了 15 倍。这是因为它将内核中原本由软件完成的很多工作放到了硬件中去完成,通过硬件加速的方式提高了速度。
尽管 RDMA 性能很高,但它的使用相对 TCP socket 较为复杂。主要原因有:首先,RDMA 内存需要事先注册到网卡才能访问,这些内存需要被绑定,也就是不能进行换入换出,因为网卡使用物理地址而不是虚拟地址来访问内存。第二,为了实现零拷贝,发送和接收操作都是异步的。在发送端,可以异步等待发送完成,而接收端需要事先指定接收缓冲区,并异步等待网卡生成的接收完成事件。为了实现内核旁路传输协议栈,还需要创建注册到网卡硬件的发送和接收队列,以在用户态与网卡直接交互。
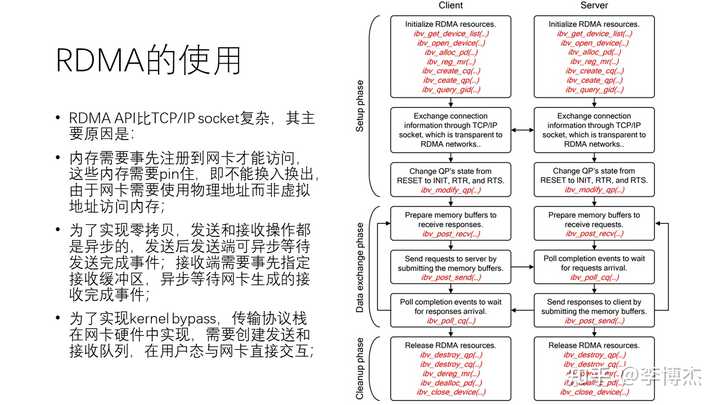
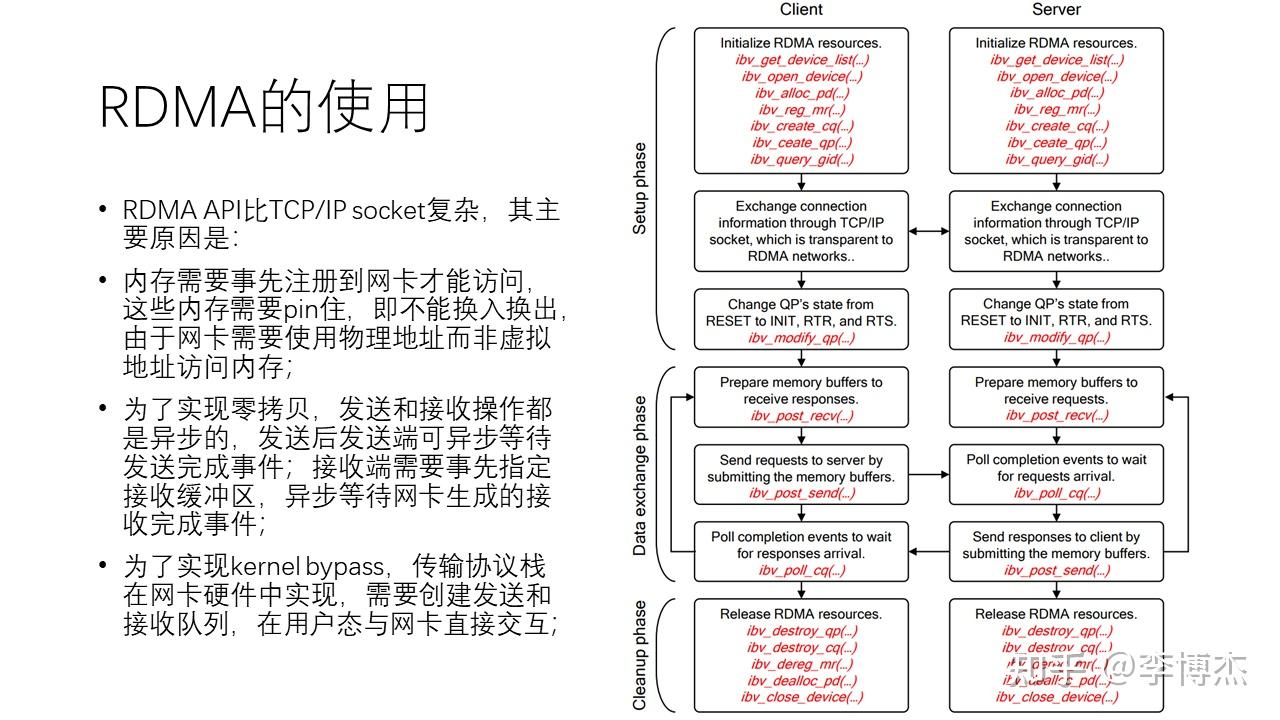
从上图中,我们可以看到在使用 RDMA 时,在控制面上,首先需要创建很多的发送和接收队列以及资源,然后还需要通过一个带外通道来交换对方的信息。最后,还需要把队列状态设置为 ready to send,也就是准备好发送的状态。在数据面,还需要准备好很多内存缓冲区,然后才能发起请求。在发起请求之后,还需要等待完成事件。整个过程是一个异步的相对复杂的过程。最后,在使用完 RDMA 后,还需要释放所有的 RDMA 资源。
总之,内存语义相对于字节流具有更高的抽象层次和更好的性能,可以更好地适应现代高速网络通信的需求。尽管 RDMA 等技术的使用相对复杂,但它们仍然在很多场景下提供了显著的性能提升。为了降低 RDMA 的使用门槛,现在也有很多工具可以简化它们的使用,例如把 socket 转成 RDMA 的 SMC-R 和 rsocket 等技术,以及 FaSST RPC、eRPC 等基于 RDMA 的 RPC 库。
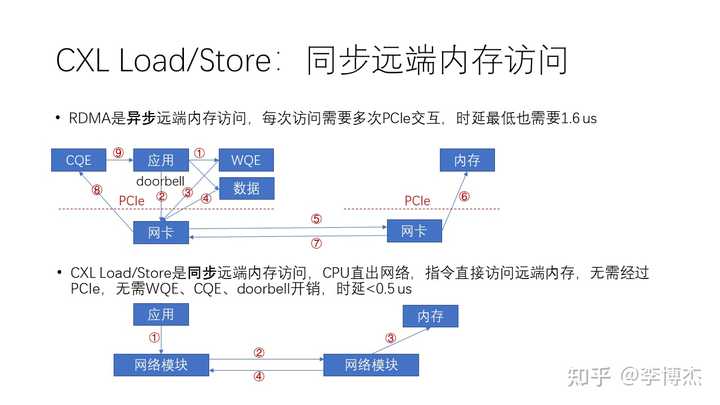
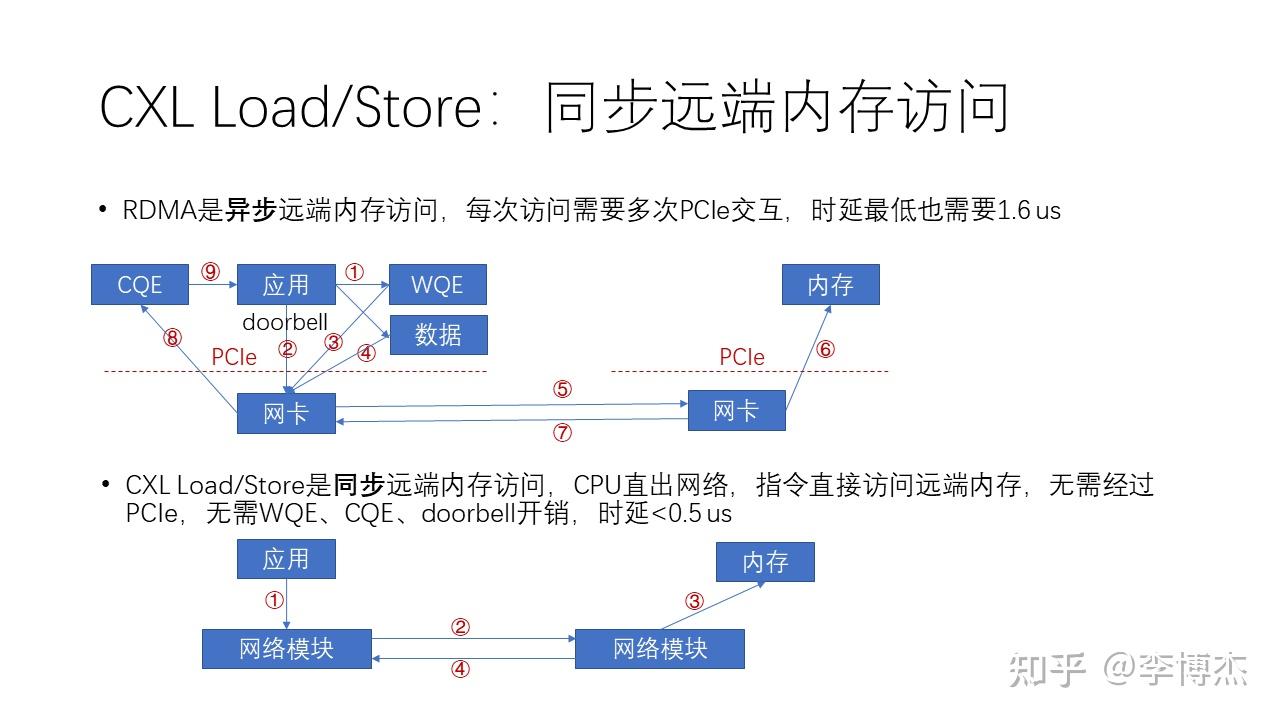
相比 RDMA 这种比较复杂的异步的远端内存访问,实际上 CXL 和 NVLink 这种 Load/Store 就是一种更简单的内存访问方式,也就是同步的访问方式。为什么它会更简单呢?我们从上面这张图可以看到,在 RDMA 中如果想发送一个数据,那么:
- 软件首先会生成一个 WQE(work queue element),就是工作队列里边的一个工作任务。
- 然后这个任务再下发一个 doorbell,就是按一个门铃到网卡告诉说我有事情要做了。
- 接着,网卡在收到这个门铃之后会从内存里面把这个工作任务取到网卡里面。
- 然后再根据工作任务当中的地址,访问内存中的数据,把它 DMA 到网卡。
- 再接下来,网卡会把这个数据封装成一个网络报文,从本地发送到远端。
- 然后,接收端的网卡在收到了这个数据之后,再把它写到远端的内存。
- 接着,接收端的网卡返回一个完成消息说我干完了。
- 发起端的网卡收到了这个完成消息之后,它就在本地内存中生成一个CQE。
- 最后,应用需要去 poll 这个CQE,也就是说它要获取这个完成队列里的完成事件才能够完成整个过程。
我们可以看到,整个过程非常复杂。
而 CXL 和 NVLink 就没有这么复杂了,因为它的 Load/Store 是一个同步的内存访问指令,也就是说 CPU(对 CXL 而言)或者 GPU(对 NVLink 而言)有一个硬件模块能够直接访问网络单元。那么这个指令就可以直接去访问远程的内存,而不需要经过 PCIe,这样就不需要 WQE、CQE 还有 doorbell 的这些开销,整个的时延可以降低到 0.5 us 以下。整个过程实际上只需要 4 步:
- 应用发一个 Load/Store 指令;
- CPU 中的网络模块发起一个 Load 或 Store 网络报文,在网络上面获取或者传送数据;
- 对方的网络模块会做一个 DMA,把对应的数据从内存里面拿出来;
- 通过网络回馈给发起的网络模块,然后CPU的这条指令就宣告完成,可以继续进行后续的指令了。
因为 CPU 有一条流水线,本来就能够去隐藏一些同步访问指令的延迟,所以它不需要把流水线卡死。但是,它会降低 CPU 流水线的并行度,因为 CPU 的流水线深度是有限的。
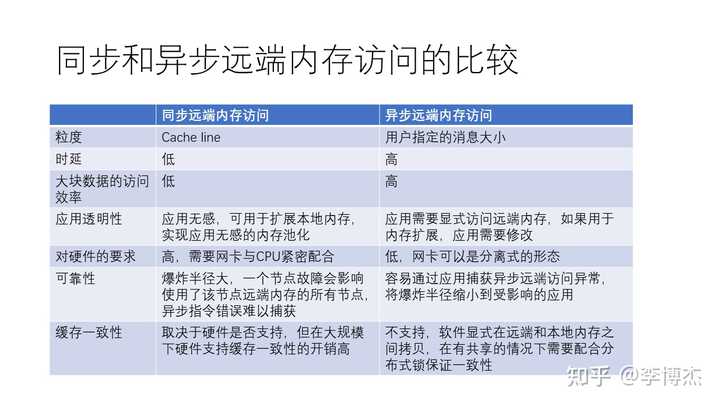
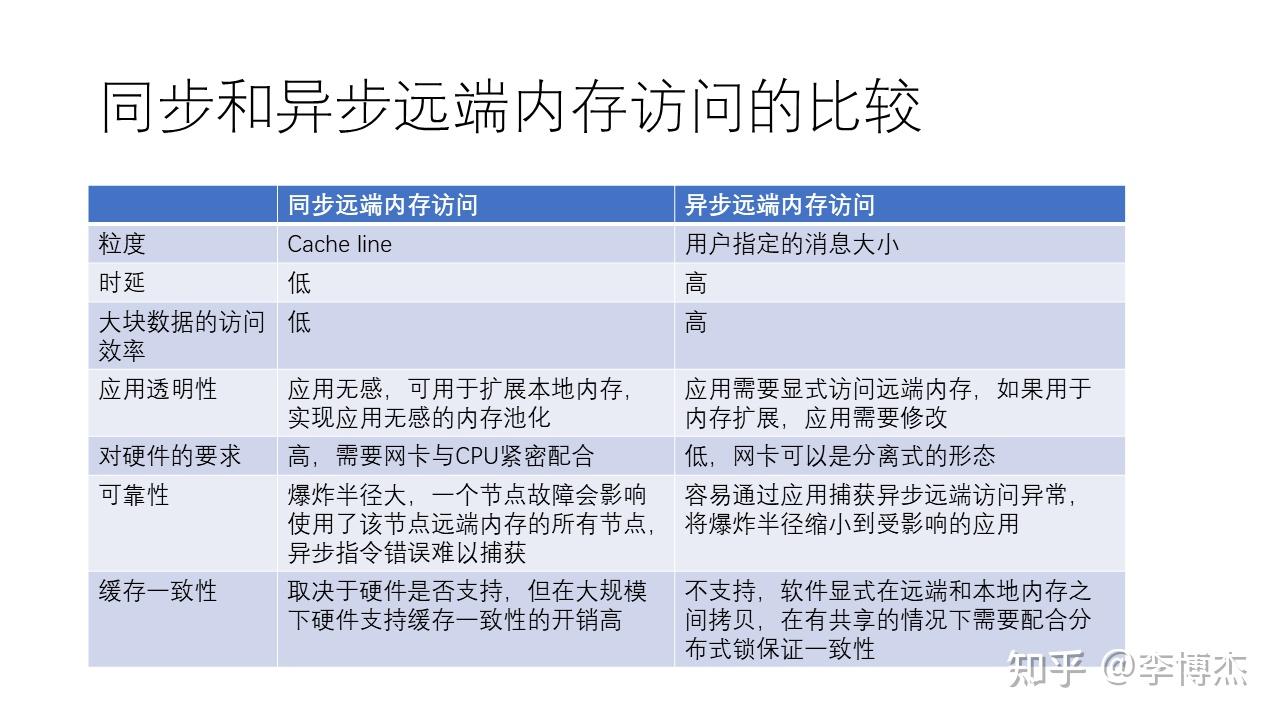
总的来说,同步和异步远程内存访问各有优缺点。同步远程内存访问,如 CXL 和 NVLink,使用简单的 Load 和 Store 操作,可以在不需太多复杂步骤的情况下实现远程内存访问。这种方式相较于异步远程内存访问,如 RDMA,更加简单,但也有一定的局限性。
同步远程内存访问的优势在于:
- 过程简单,交互流程简洁,使得访问延迟较低。
- 对应用程序来说是透明的,可以用来扩展本地内存,而不需要修改应用程序。
- 在访问较小数据量时,效率可能更高。
- 在硬件支持的情况下,可能支持缓存一致性。
同步远程内存访问的劣势包括:
- 对硬件要求较高,需要网卡与 CPU 紧密配合。
- 每次访问的数据量相对较小(通常是一个缓存行,如 64 字节),因此在访问大数据量时,效率可能不如异步远程内存访问。
- 同步远程内存访问的可靠性可能较差,因为一个节点故障可能会影响到使用了该节点所贡献的远端内存的所有节点。有一个所谓 “爆炸半径” 的概念,远端内存如果发生故障了,影响的不只是自己这个节点,这就会导致爆炸半径增大。
- 大规模下的缓存一致性开销很高。
异步远程内存访问的优势在于:
- 用户可以指定访问的数据量大小,从而在访问大数据量时,效率可能更高。
- 对硬件要求相对较低,网卡可以采用分离式形态,如 PCIe 接口的网卡。
- 可以通过应用捕获异常,从而将影响范围缩小到受影响的应用。
异步远程内存访问的劣势包括:
- 过程较复杂,涉及到与网卡的复杂交互,导致访问延迟相对较高。
- 对应用程序来说不是透明的,需要显式访问远程内存,因此如果用于扩展内存,需要修改应用程序。
- 不支持缓存一致性,需要靠软件在远端和本地内存之间进行拷贝,并在共享内存情况下配合分布式锁来保证一致性。
根据实际应用场景和需求,开发者可以选择适合的内存访问方式。对于需要访问较小数据量且对延迟要求较高的场景,同步远程内存访问可能更合适;而对于需要访问大数据量且对延迟要求不高的场景,异步远程内存访问可能更为有效。
值得注意的是,目前 NVLink 上的很多通信仍然是基于同步 Load/Store,这一方面是因为 GPU 的核数多,浪费一些核用于通信不太可惜,另一方面是因为 NVLink 规模小,时延低,只有几百纳秒。NVLink 虽然宣称支持一致性,但是它其实是以页面(page)为粒度、仅支持一个共享者的受限一致性,避开了分布式缓存一致性领域多个共享者如何存储共享者列表的经典难题。由于 GPU 主要用于 AI 和 HPC 场景,NVLink 上的通信主要是集合通信,而不是数据共享,因此受限一致性基本上是够用的。
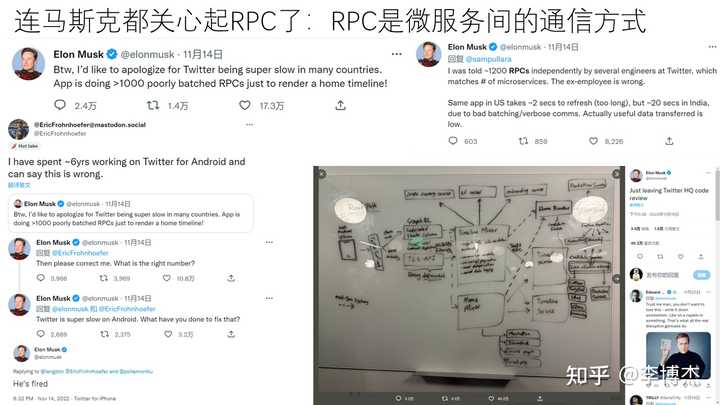
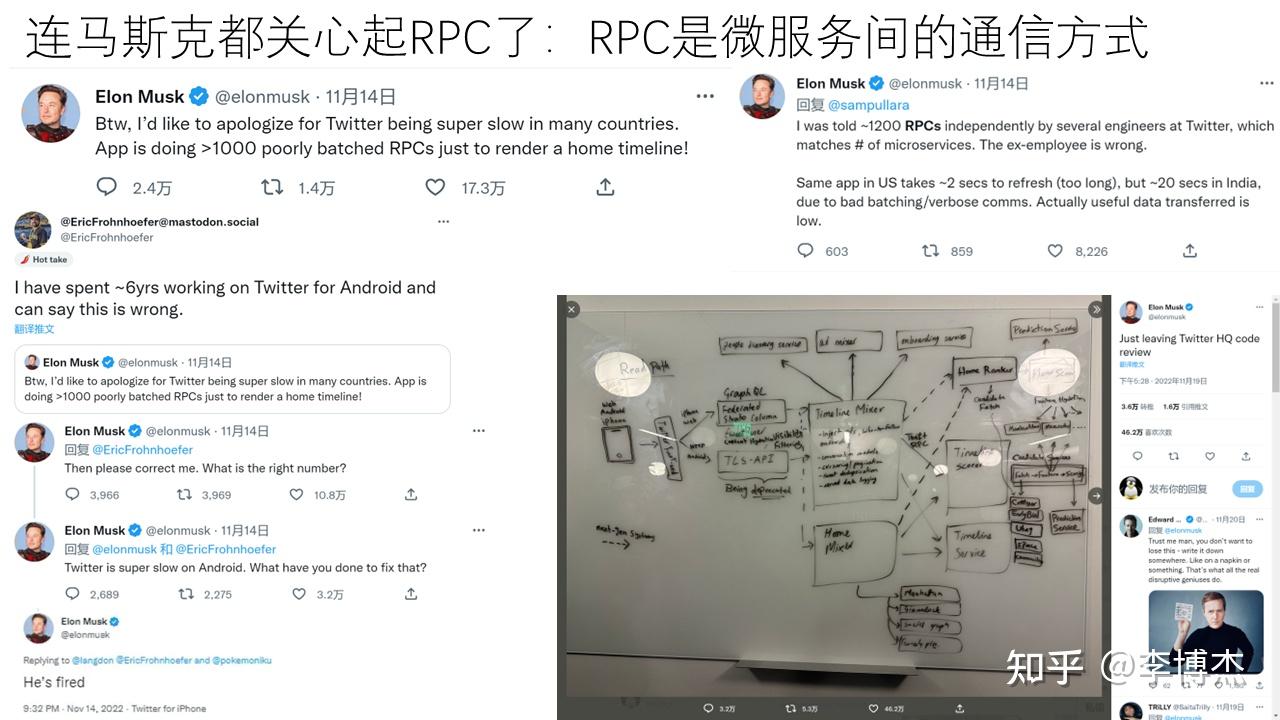
接下来我们再来看一下 RPC,RPC 的全称是远程过程调用,它实际上就是跨主机、跨进程以及跨语言的函数调用。RPC 在数据中心内部的通信中非常重要,它其实是一个非常通用的东西,各种微服务之间的通信都是通过 RPC 的。谷歌有个统计,95% 的数据中心流量都是 RPC。
前段时间,我们看到埃隆·马斯克在 Twitter 上说 RPC 特别重要,甚至有一个工程师质疑他说 RPC 实际上根本不重要。然后马斯克直接就把他给炒了。后来他又补充说,就是在一次网络访问中,比如访问一个 Twitter 的首页,可能需要 1200 个 RPC 左右。这也就说明,我们对于 RPC 去做一些加速,是非常有价值的。
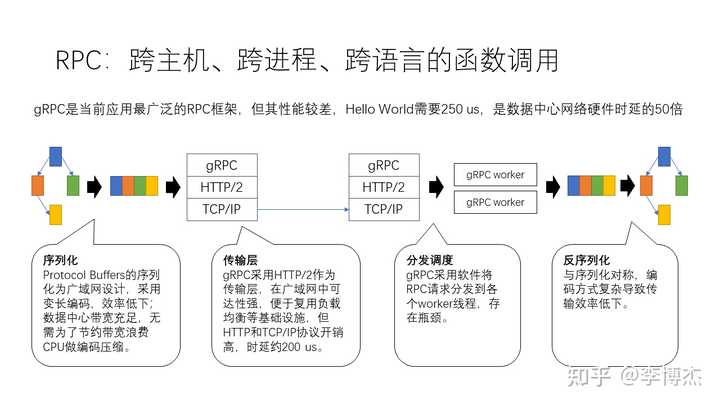
比如说我们现在的 gRPC,就是当前应用最广泛的一个 RPC 框架,它的性能比较差。比如说一个简单的 Hello World 程序需要 250 微秒,它实际上是达到了数据中心网络硬件时延的 50 倍。那么为什么它的开销这么高呢?传统上我们都认为可能是因为传输层的原因,但其实它有很多问题。
- 首先,最大的一块,实际上是在序列化和反序列化这个地方,它实际上用的是 Protocol Buffers 来做序列化。这个序列化方案是为广域网设计的,采用了变长编码,所以效率比较低。我们在数据中心里,带宽其实是比较充足的,因此不需要为了节约带宽浪费很多 CPU 去做这样的编码压缩。
- 接下来就是传输层里面,因为 gRPC 采用了 HTTP/2 作为传输层,在广域网中的可用性比较强,可以复用各种负载均衡等基础设施。但是 HTTP 协议的解析开销非常高,整个过程包括 HTTP 和 TCP 协议加起来可能达到了将近 200 微秒。
- 再接下来还有一块开销,就是分发调度,首先用软件把请求从 TCP 协议栈里面收上来,然后再把它分发到各个工作线程,这个过程中存在很多瓶颈。
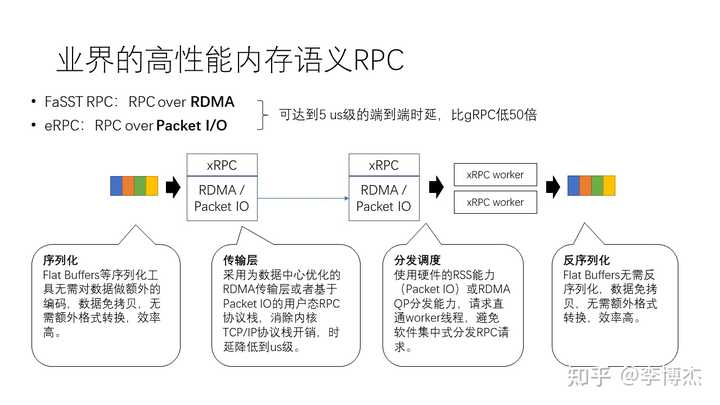
学术界在高性能的 RPC 方面已经做了很多探索。比如说一个较早的工作,叫做 FaSST RPC,它是基于 RDMA 的 RPC。我们知道 gRPC 实际上是仅仅支持 TCP/IP 协议的,而 FaSST RPC 使用了 RDMA 之后,把传输层卸载到了硬件,就可以达到 5 微秒级的端到端延迟,性能比 gRPC 高大约 50 倍。最近的一个工作是 eRPC,它可以基于 Packet I/O 运行,这是另外一种思路,相当于是把传输层放在软件里面,但是它不是在内核中实现,而是在用户态实现,这是一种用户态 I/O 的思路。这种方法其实也能达到很高的性能。
在序列化这一方面,我们有像 Flat Buffers、Cap’n Proto 这些序列化工具,它不需要对数据进行额外的编码压缩,而且在创建数据结构的时候就把数据连续地存储在内存中,从而数据不需要在不同的数据格式之间来回做转换,这样它的效率就比较高。Flat Buffers 和 Cap’n Proto 不仅免除了序列化的工作,也免除了反序列化的工作,在访问数据结构的时候直接从连续内存中读取,而无需创建大量零散的语言原生对象。
在传输层这一方面,刚才讲的像 FaSST RPC 和 eRPC,它们都是为数据中心优化的,或者基于 RDMA 网卡实现硬件卸载,或者基于 Packet I/O 的用户态协议栈,来消除内核 TCP/IP 协议栈的开销,从而使得延迟能够降低到微秒级。
而在分发调度这一方面,网卡硬件在 Packet I/O 模式下有 RSS(Receive-Side Scaling)的能力,使用 RDMA 的时候 QP 也天然自带分发的能力,这样我们可以使得请求从客户端直接到达 RPC 执行线程,避免软件集中式分发 RPC 请求。
把数据中心作为一台计算机


数据中心网络有了这样的一种内存语义的编程抽象,我们就可以把数据中心作为一台计算机。


在数据中心作为一台计算机里面,我们主要考虑的是两个方面,第一是让数据中心互联像一台计算机的内部总线一样高效,第二是数据中心内的分布式系统编程像单机编程一样便捷。
让数据中心互联像计算机内部总线一样高效
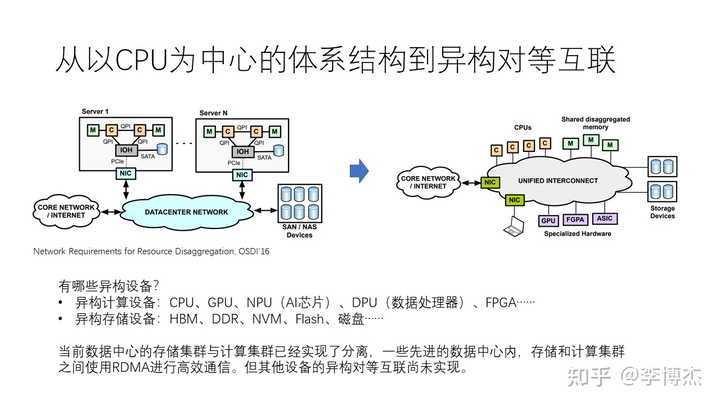
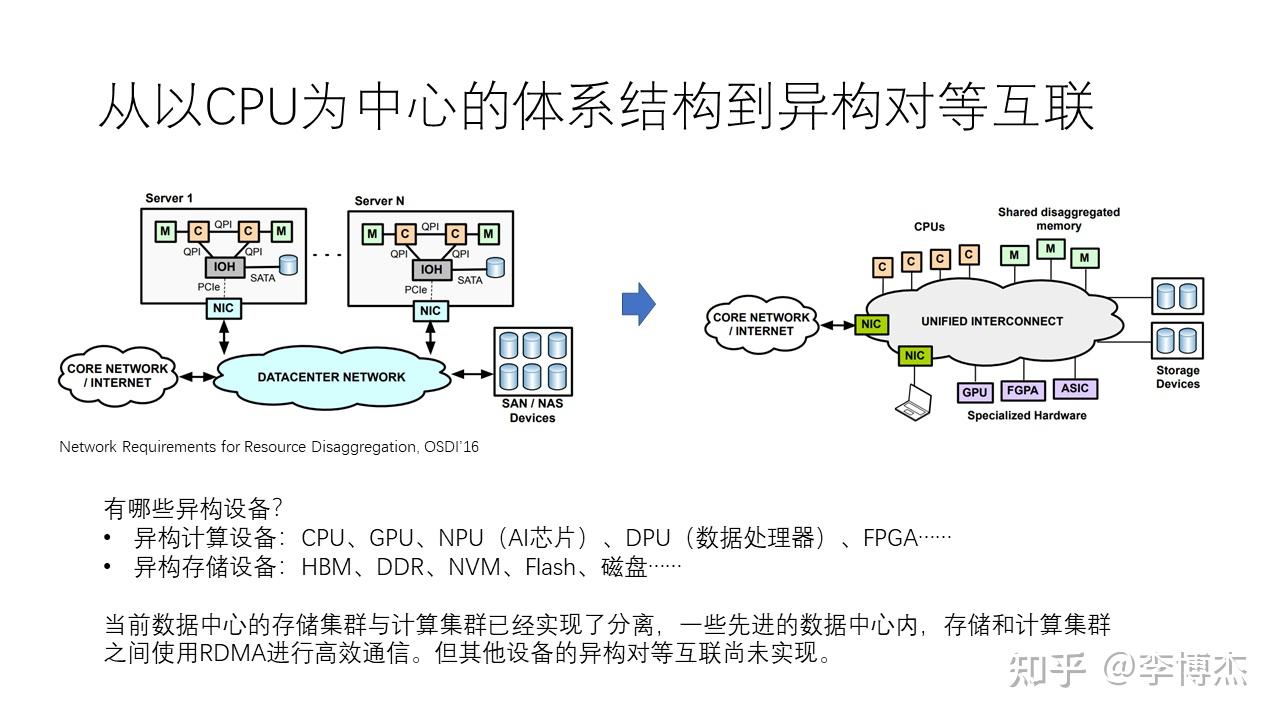
从以 CPU 为中心的体系结构开始,我们把它发展到以异构的对等互联的体系结构。目前,CPU 是计算机体系结构中绝对的老大哥,但在新的体系结构里面,我们会有各种各样的异构计算设备,比如说包括 CPU、GPU、NPU(神经网络处理器,即AI芯片),以及 DPU(数据处理器),FPGA 等等。同时,还有很多不同的异构存储设备,包括 HBM、DDR、非易失性内存(NVM)、Flash SSD 等等。
当前,数据中心的存储集群和计算集群已经实现了分离,在很多先进的数据中心当中,存储和计算集群之间使用 RDMA 进行高效通信,但是其他设备的异构对等互联尚未完全实现。
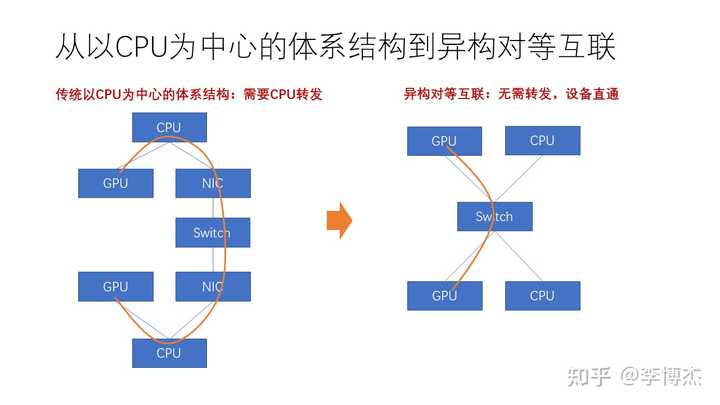
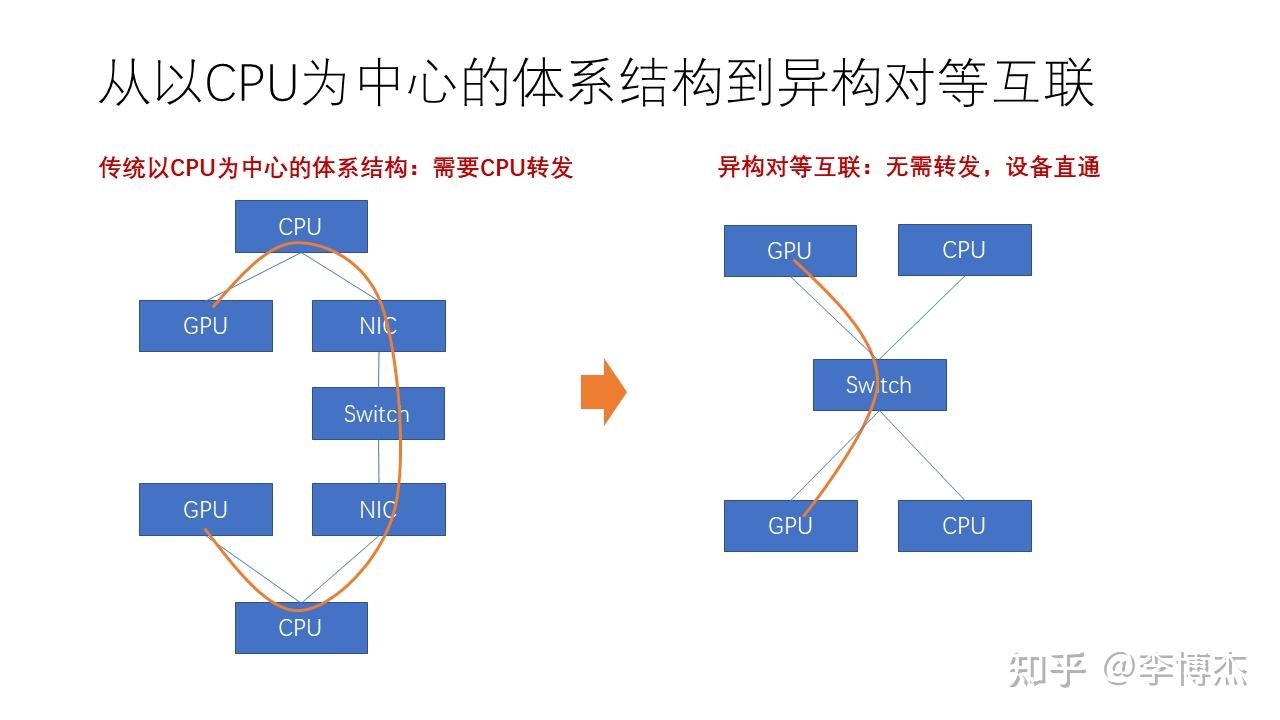
我们为什么要实现所谓的对等互联呢?这是因为以 CPU 为中心的体系结构在很多时候需要 CPU 进行中心化转发。例如,假设有两台机器,其中一个 GPU 需要与另一个 GPU 通信,如果这两个 GPU 之间没有直接的互联,那么它们可能需要通过 CPU 转发到网卡,然后再通过 InfiniBand 或者 RoCE 或者以太网等网络通信。如果两个 GPU 之间有 NVLink 互联,它们就可以直接互相通信。但是 NVLink 的互联范围是有限的,只能互联几百张 GPU 卡,超过了这个范围,又需要 CPU 和网卡去做转发。
而在对等互联的体系结构中,我们不再有 GPU 和 GPU 之间通过 NVLink 互联或者通过 Infiniband 互联这样的差异,它们会统一连接到一个高速的交换网络。实现设备直通后,可以大大扩展对等互联的规模。这样,计算集群在大规模任务下的性能将大大提高,对大模型训练有很大帮助。
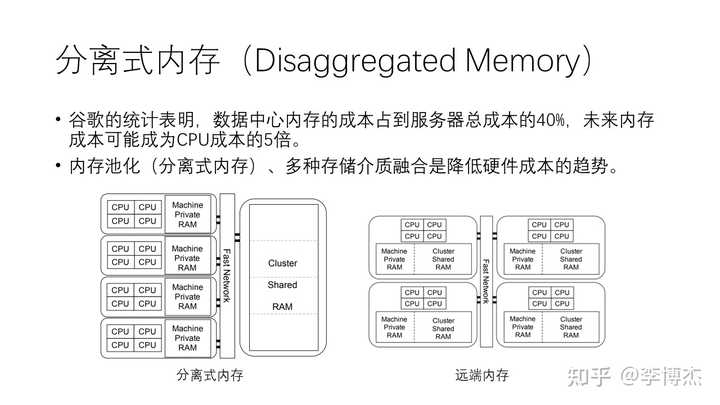
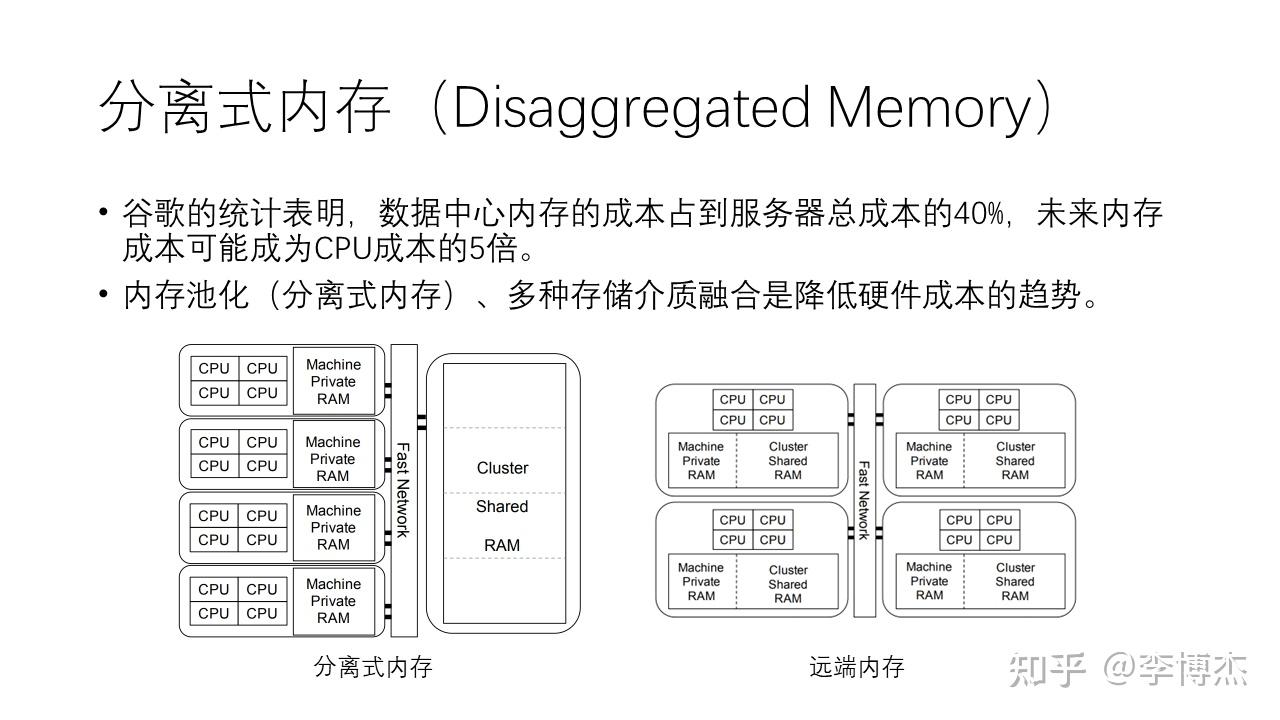
另外一个重要的趋势是分离式内存,即 disaggregated memory。谷歌的统计显示,数据中心内存的成本占到服务器总成本的 50%;Meta 的统计也显示,数据中心内存的成本占到机架总成本的 40%。因此,内存分离以及多种内存介质的融合将成为降低硬件成本的一个重要趋势。
所谓的分离式内存是指每个机器都有一小块空间作为私有内存,然后通过高速网络连接到共享内存池,大部分的内存都在共享内存池中。然而,这种方案的可行性可能并不高,因为内存所需的带宽很高,时延很低,目前网络的带宽和时延比内存相去甚远,可能会导致性能下降。这就像是盖一座高楼,把所有的厕所都修在一楼。
相对来说,远端内存的方式可能更为可行。每个节点都有自己的 CPU 和内存,但可以贡献一部分内存供其他人使用。当本地内存不足时,可以向其他节点借用内存。我们知道,在公有云中内存的使用率是比较低的,很多内存都是空闲的,这些空闲内存就可以组成内存池。本地内存中存储热数据,远端内存池中存储冷数据。
在任何计算机体系结构设计中,局部性(locality)都是关键。之所以可以实现完全的分离式存储,是因为两个原因:
- 存储所需的带宽比数据中心网络的可用带宽低,而且存储介质的访问时延本身就高于数据中心网络的时延,因此性能损失不会很大。即使这样,数据中心存储的流量也已经占据了整个数据中心总流量的一半以上。
- 存储需要高可靠性,不能仅仅依赖于本地存储。当服务器出现故障时,本地存储的数据可能会丢失,因此需要将数据复制到多个节点以实现高可靠性。
分离式内存需要的带宽可能高于数据中心网络的可用带宽,而且一般不需要多副本,因此实现它的代价是高于分离式存储的。
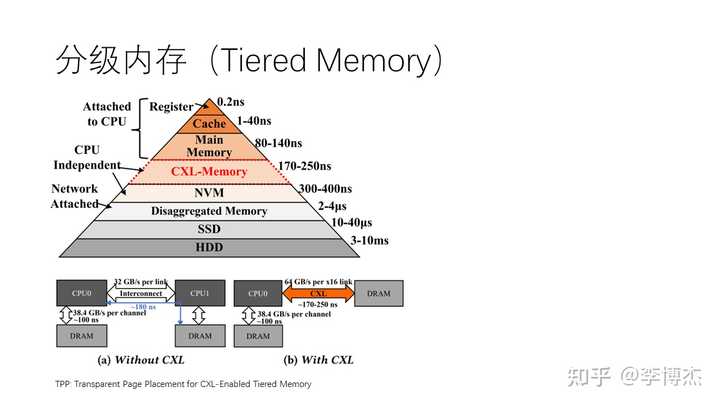
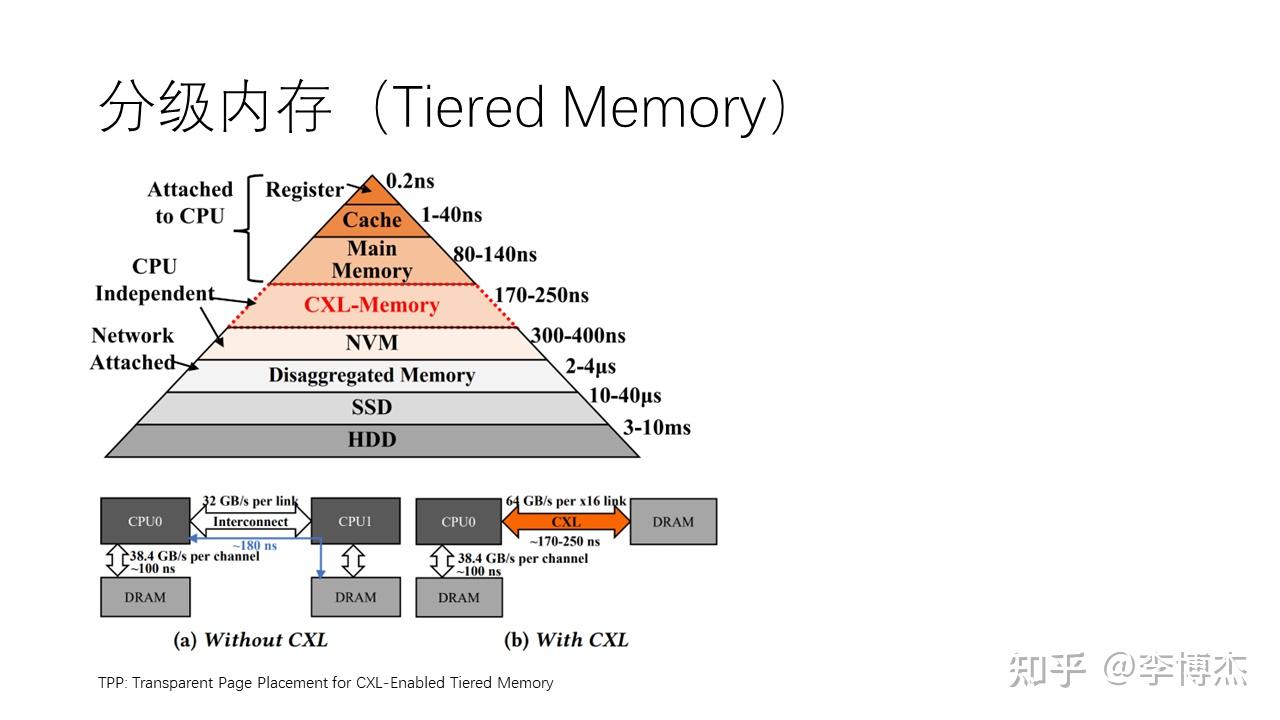
除了使用远端内存来扩展本地内存容量外,另一个思路是使用分级内存,即 tiered memory。内存层次结构(memory hierarchy)是从计算机诞生的第一天起就存在的经典问题,可以包括本地内存、远程内存、非易失性内存(如 Intel 的 Optane 内存)以及 SSD、HDD 等。这实际上形成了一个庞大的存储金字塔,我们在计算机体系结构课程中应该都有所了解。在这个金字塔中,上层的性能较高、价格也较高,下层的性能较低、价格也较低。
Jeff Dean 列出了一个很有名的表格 Numbers Everyone Should Know (在 Designs, Lessons and Advice from Building Large Distributed Systems 这个报告里面),讲的就是存储金字塔,其中的一些数字可能今天并不适用,但其中的思想是深刻而永恒的。我们做计算机的一定要对数量级保持敏感,知道一些关键操作和系统组件的时延、吞吐、功耗、价格的数量级,并且能够快速估算一个系统各项指标的数量级,这叫做 Back of the Envelope Calculations,这样才能对系统有更好的感觉。
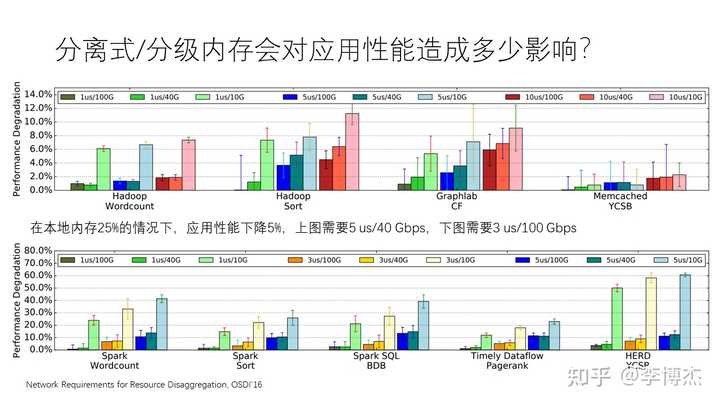
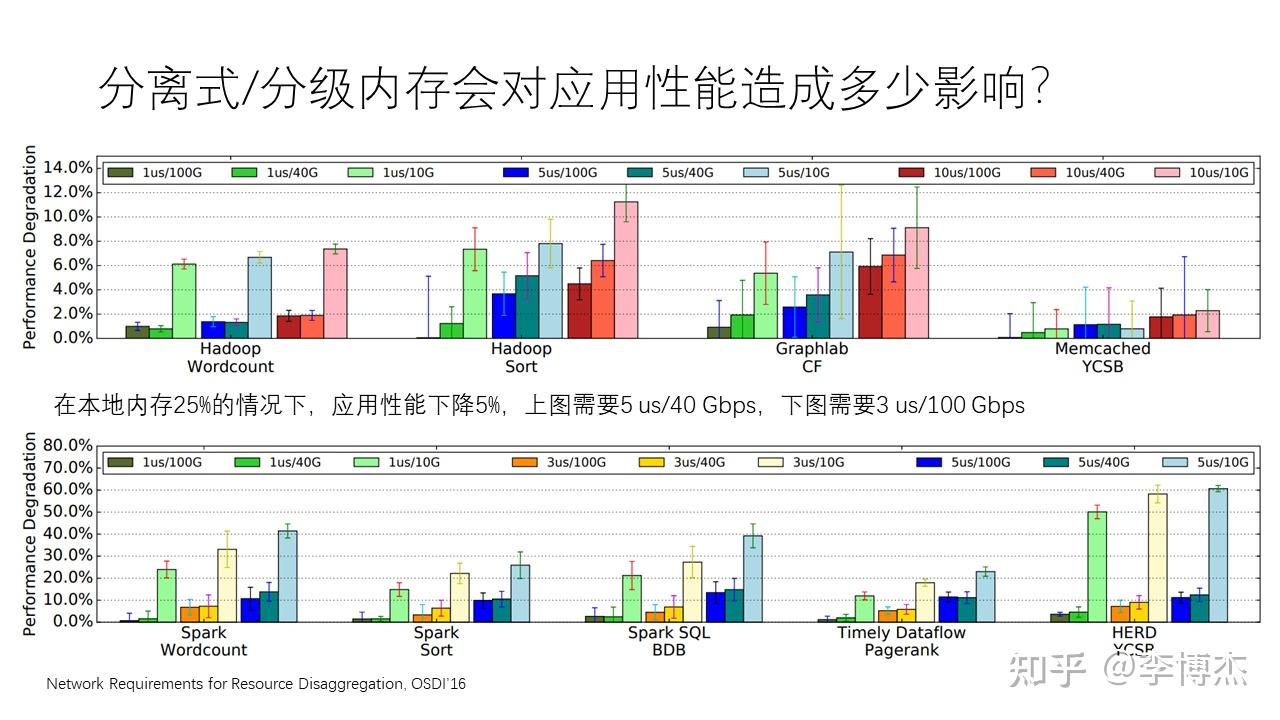
我们很关心的一个问题是,如果使用分离式内存或分级内存,而不是传统的本地内存,那么与单纯使用本地内存相比,它会对应用的性能造成多大的影响?实际上,造成的影响没有大家想象的那么严重。
有一篇经典的文章叫做 “Network Requirements for Resource Disaggregation”,它说明了在本地内存只有 25% 的情况下(也就是 75% 的数据都放在远端内存里),要达到性能下降不超过 5% 这样的指标,在访存不太密集的应用中,例如 Hadoop,GraphLab,Memcached 等,需要 5 微秒的网络往返时延和 40 Gbps 的带宽。而在对访问内存要求较高的应用中,例如 Spark,PageRank,HERD 等,需要 100 Gbps 的带宽和 3 微秒的往返时延。
我们可以看到,在热数据存储在本地内存、冷数据存储在远端内存的前提下,现有的硬件(如 Mellanox 的网卡)实际上已经满足了应用性能不显著下降的需求,所以在很多场景下应用性能并不是一个很大的问题。
如何将经常访问的数据存储在本地,而将不常访问的数据存储在远程成为了一个关键问题。这里又有两个子问题,首先是如何低开销地识别数据的冷热,其次是如何低开销地做冷热数据迁移,学术界和工业界都有很多人正在研究。
让分布式系统编程像单机编程一样便捷


前面我们讨论的是 “让数据中心的网络互联像单台计算机内部总线一样高效”,接下来我们讨论的是 “把数据中心作为一台计算机” 的另一个方面,也就是我们要让数据中心分布式系统的编程像单机一样便捷。
2009 年,伯克利针对这个云计算做了很多的预测,都成为现实了:
- (理论上)无限可用的计算资源
- 用户再也不需要承担服务器运维的工作和责任
- 服务的按需付费成为可能
- 超大型数据中心的使用成本显著降低
- 通过可视化资源管理,运维操作的难度大大降低
- 得益于分时复用,物理硬件的利用率大大提高
伯克利提出了一个很有影响力的观点:分布式系统的编程应该像单机编程一样便捷。为了实现这个目标,他们提出了很多新的编程模型和编程框架。其中一些比较知名的有 MapReduce、Hadoop、Spark 等。这些编程模型和框架的核心思想是:让程序员只需要关注数据处理的逻辑,而不需要关心分布式系统底层的细节,例如数据分片、并行计算、容错等。
这种编程模型在一定程度上确实简化了分布式系统的开发,但是也有一些问题。首先,这些模型通常只能很好地处理特定类型的任务,例如大规模数据处理任务。对于一些复杂的分布式系统,例如分布式数据库或者分布式事务,这些模型可能就不太适用了。其次,这些模型和框架往往有很高的学习成本,程序员需要学习一套全新的编程语言和概念,这对于很多人来说可能是一个挑战。
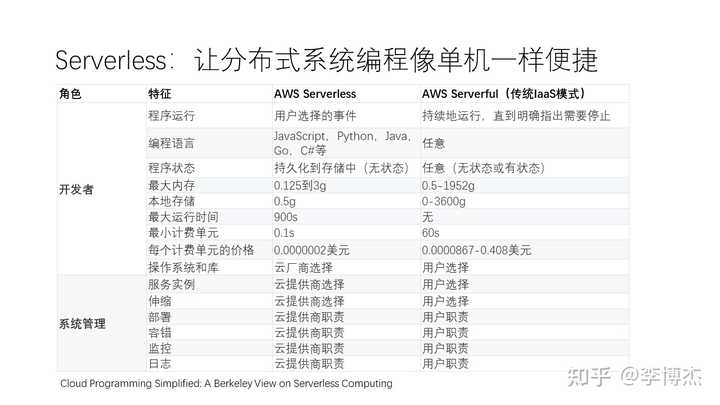
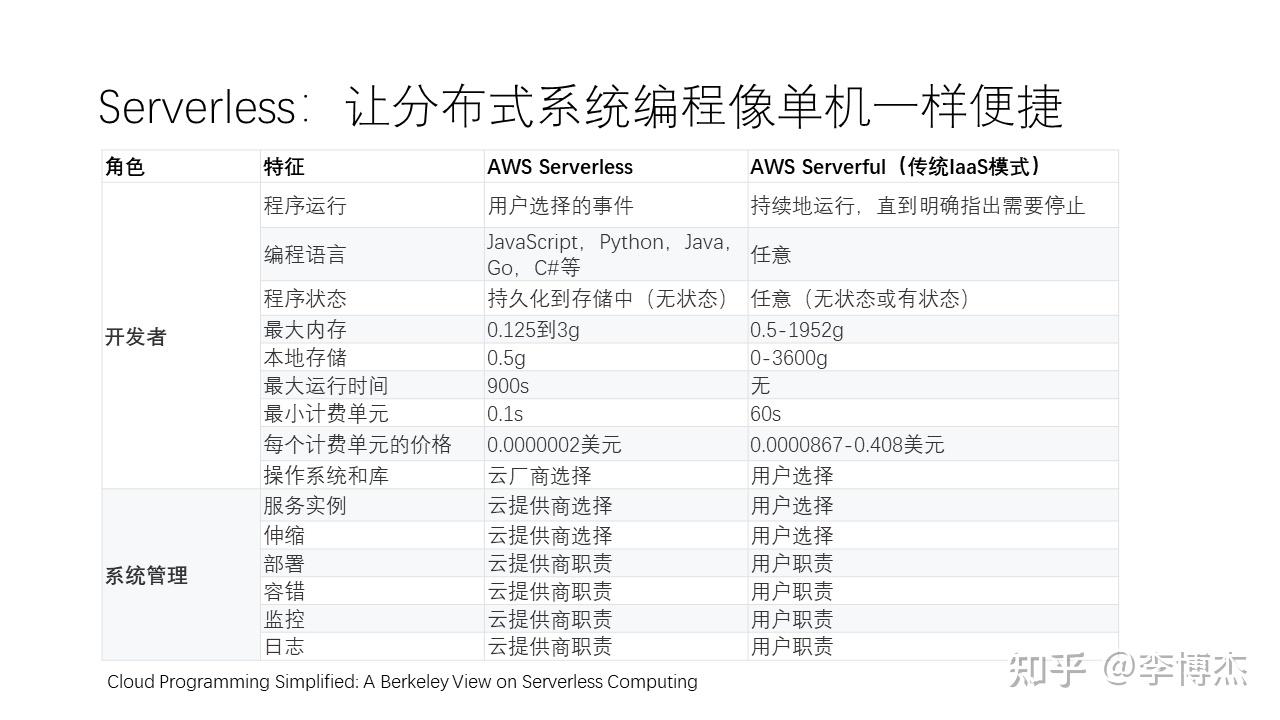
2019 年,伯克利又预言 Serverless 将成为下一个重要的应用范式。现在很多云服务商,包括华为云,都提供了 Serverless 函数服务。伯克利指出,Serverless 服务与传统的 IaaS 模式相比,有一些显著的差异。最大的区别在于系统管理方面,比如服务的实例扩缩、部署、容错、监控和日志等方面,Serverless 都由系统自动完成,而传统的 IaaS 模式全部需要程序员和运维工程师手工处理。
例如,在 IaaS 中,以下这些事情都是要程序员和运维工程师手工处理的,而如果使用 Serverless 服务,这些问题就完全是由 Serverless 服务解决的:
- 为可用性做到冗余,这样一台机器的故障不会导致服务中断
- 在发生灾难时保留服务的冗余拷贝的地理分布
- 通过负载均衡、请求路由来高效利用资源
- 根据负载变化自动伸缩系统
- 监控服务确保它们一直健康地运作
- 记录日志用于 debug 和性能调优
- 系统升级,包括安全补丁
- 在新实例可用时迁移到新实例
此外,在程序运行方面,Serverless 允许用户选择的事件触发执行,而传统模式必须持续运行,直到明确指出需要停止。
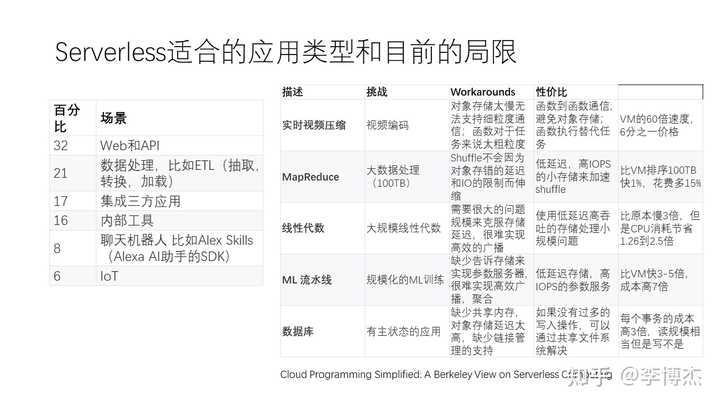
然而,目前的 Serverless 并不是一种万能解决方案,它的适用范围有一定的局限性。目前的 Serverless 更适合一些无状态、短时间运行的应用,同时这些应用可能具有很高的突发性,即访问量在某些时刻非常大,而在其他时候突然没有人访问。在这种情况下,使用 Serverless 可以很好地实现服务的自动扩缩。
在编程语言方面,传统模式可以使用任意的语言,而 Serverless 可能只能使用几种受限的编程语言。在程序状态方面,AWS 的 Serverless 是一个无状态的服务,而传统模式可以是有状态或无状态的。一些应用具有很复杂的中间状态,如机器学习、线性代数或数据库等,这时候 Serverless 的抽象会带来较大的挑战。正如伯克利的文章指出的,Serverless 的时代还刚刚开始,这些都是有待我们进一步探索和解决的问题。
本章小结
以上就是数据中心部分的内容。
数据中心网络传统上为容易并行的 Web 服务设计。但如今 AI、大数据、HPC 都是大规模异构并行计算系统,对通信性能都提出了很高的要求,厚重的软件栈造成巨大的开销,这就要求数据中心网络的通信语义从字节流演进到包括消息语义、同步和异步远端内存访问、RPC 在内的内存语义,软硬结合实现极致的时延和带宽。未来,我们期望把数据中心作为一台计算机,一方面实现异构计算、存储设备间的对等直通,让数据中心互联像主机内部总线一样高性能;另一方面通过 Serverless 让分布式系统编程像单机编程一样便捷。
广域网


广域网主要分为两大类通信模式,一类是端云通信,一类是云际通信。我们先从端云开始讲起。
端云网络
我们一般提到广域网,就认为它是不可控的,运营商的网络设备都不是自己能控制的,还有大量其他用户在并发访问,很难做到确定性。但今天的很多应用又需要一定程度的确定性,比如视频会议、网络游戏,时延高到一定程度用户就会感觉卡顿。如何调和这一对矛盾呢?这就是我们今天的课题。
就像我们在上一章数据中心网络中讲到的,应用实际感受到的带宽与物理带宽差距很大,因此才有优化的空间。我们知道现在 5G 和 Wi-Fi 的理论带宽都是数百 Mbps 乃至上 Gbps,家庭宽带的带宽很多也是几百 Mbps 甚至达到了千兆,理论上 100 MB 的数据一两秒钟就能传输完成。但我们在应用市场里面下载应用的时候,有几次是 100 MB 的应用一两秒钟就能下载完的?另外一个例子,压缩后的 4K 高清视频只需要 15~40 Mbps 的传输速度,听起来远远没有达到带宽的理论上限,但我们有多少网络环境能流畅看 4K 高清视频?这一方面是端侧无线网络的问题,一方面是广域网的问题。要把理论带宽用好,还有很长的路要走。
我当年在微软实习的时候,微软大厦二楼的中餐厅就叫做 “云 + 端”(Cloud + Client),12 楼 sky garden 那里的背景板也写着 cloud first, mobile first,数据中心和智能终端确实是 2010~2020 年最火的两个领域。但可惜的是微软的移动端一直没做起来。华为恰好是在端云两侧都有强大的实力,因此在端云协同优化方面有着独特的优势。


传统互联网应用对带宽和时延的诉求其实并没有那么高,例如网页浏览、文件下载、1080p 的视频点播,100 Mbps 的带宽足够了,时延达到秒级也足以满足用户的需求。
但是,如今的实时音视频(Real-Time Communications,RTC)等新型应用对带宽和时延提出了更高的诉求。例如:
- 4K 高清视频可能需要 1000 Mbps 的带宽。
- 视频会议需要 100 毫秒的时延,否则会感受到视频和声音有显著延迟。
- 直播的时延从之前的分钟级降低到了秒级,直播跟视频会议不同,直播经常有上万人同时观看一个频道,因此需要 CDN 网络层层转发。
- 远程桌面更是需要 10 ms 级别的稳定时延,我曾经用过一段时间远程桌面办公,40 ms 的时延就已经能感受到明显卡顿了。
- 云游戏,比如云原神,跟远程桌面类似,也是需要 10 ms 级别的稳定时延。
我们知道,在光纤里面,10 ms 光只能走 2000 公里,也就是说 10 ms 的往返时延,理论上服务器最远不能超过 1000 公里。而且还要考虑到无线接入网络的时延、网络路由器中的排队时延和数据中心中的处理时延,10 ms 真的是非常苛刻的要求,必须在数据中心选址、无线网络、广域网、数据中心网络、数据中心业务处理等每个环节都锱铢必较,才有可能达成稳定的低时延。
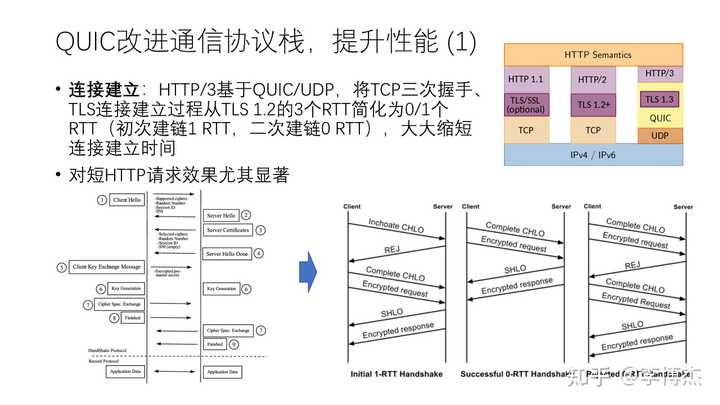
实时音视频需要一系列的关键技术,今天由于时间限制,只讲其中一个有代表性的新型传输协议,QUIC。QUIC 是谷歌等互联网巨头提出的,旨在取代传统的 HTTP,目前最新的 HTTP/3 就是基于 QUIC 的,很多大型网站,比如 Google 和 Facebook,已经支持 QUIC 了。
传统基于 TCP 的 HTTP 协议在广域网传输上有一系列的问题,包括建链时延、拥塞控制、队头阻塞、丢包恢复等等。我们一个一个分别来讨论。
首先是连接建立的时延问题。我们都知道 TCP 需要三次握手,也就是一次往返时延后才能够发送数据。
现在网络上的流量大多数是通过 TLS 加密传输,TLS 在 1.3 之前,加密连接的建立也需要两次往返,主要目的是让客户端验证服务端的身份,并且生成一个用于加密数据的随机密钥。
- 在 TCP 连接建立之后,首先是客户端把自己所要访问的域名、支持的加密算法列表、用于生成随机密钥的随机数发给服务端。这里注意域名是明文传输的,也就是说虽然使用了 TLS,运营商还是能知道你访问的是什么网站的。
- 然后服务端把服务端的 TLS 证书、所选用的加密算法和用于生成随机密钥的随机数发给客户端。
- 客户端验证服务端的证书,然后根据前面的随机数生成用于加密数据的密钥,并且把使用服务端证书中的公钥加密的密钥发送给服务端。
- 服务端使用私钥解开用于加密数据的密钥,这样客户端和服务端都拥有了同一份密钥,而网络上的监听者不可能拿到密钥。
接下来,应用才可以基于这个加密的连接发送数据,也就是客户端发送的 HTTP 请求和服务端返回的 HTTP 响应。
QUIC 把上述 3 次网络往返才能完成的连接建立过程压缩到 0 到 1 次,第一次建立连接的时候只需要一次往返,而后续的连接建立甚至一次往返都不需要。这是怎么实现的呢?
首先,通过无连接的 UDP 来传输数据报文,可以节约 TCP 的连接建立开销。QUIC 内部通过 Session ID 来区分不同的连接,也就是在会话层实现了连接区分,而不是基于 TCP/IP 的五元组来区分连接。
其次,TLS 1.3 对 TLS 1.2 做了改进,在首次建链的时候,把原来需要两次往返的加密通道建立过程缩减为一次。其基本原理是将上述 TLS 1.2 握手流程第 3~4 步的过程和发送数据并行化。我们注意到在上述第 3 步客户端验证完证书、生成对称密钥之后,其实就已经可以开始使用对称密钥加密应用的消息了,因此发送密钥之后就可以流水线化地发送加密的数据。当然,为了前向安全(forward secrecy),这个对称密钥只是在第一个往返中使用,第二个往返及以后的数据将使用支持前向安全的另一个密钥。
最后,在之前建立过连接的情况下,QUIC 协议栈内部的 TLS 1.3 模块会缓存该连接的对称密钥(Pre-Shared Key,PSK)。这样,只要缓存没有过期,客户端仍然可以使用原来的对称密钥来加密数据并直接发送,这样就不需要任何握手,做到 0-RTT 建链。也就是说,QUIC 协议栈内部事实上是维护了长连接的,这叫做会话重用。当然,会话重用也带来了重放攻击的风险,并且削弱了前向安全的特性。
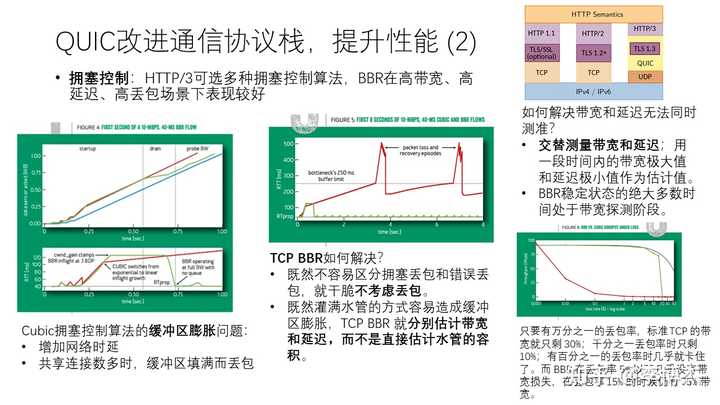
接下来是拥塞控制的问题。广域网上的拥塞控制问题已经研究了几十年,有的是基于丢包的,有的是基于时延的,还有综合以上两者的。
HTTP/3 里面有多种拥塞控制算法可选,今天我们重点介绍一个比较特别的拥塞控制算法,就是谷歌的 BBR,它是为高带宽、高时延、高丢包场景设计的。
传统的拥塞控制算法,比如我们教科书上面学过的 TCP Cubic,很容易导致缓冲区膨胀(buffer bloat)。因为每个连接都是在丢包或者延迟较高时才降低速度,反馈是需要一个网络往返的时延的,这样每个连接在瓶颈链路上都会占用一定的缓冲区,形成一定的队列。当通过一个瓶颈链路的连接数较多时,队列就会比较长,导致端到端时延升高。如果通过瓶颈链路的连接数多到一定程度,队列超过了路由器的缓冲区容量,就会导致丢包。
传统的 TCP Cubic 只有遇到了丢包才会降速,因此队列深度就会一直维持在高位,时延也一直比较高。有没有方法解决这个问题呢?基于时延的拥塞控制算法可以在时延上升的时候就开始降速,而不用等到丢包。BBR 也是一样的,不考虑丢包,而是尝试直接估计 BDP(Bandwidth-Delay Product,带宽和时延的乘积)。BBR 不考虑丢包还有另外一层考量,在广域网上的丢包有时并不是由于拥塞导致的,有些是由于错误导致的,例如无线弱网的情况;有些是由于网络上的中间设备(middlebox)导致的。
如何估计 BDP 呢?做过网络的都知道,带宽和时延是很难同时测准的:测带宽的时候把网络打满了,时延就会很高;测时延的时候需要网络空载,带宽又上不去。BBR 采用了一个交替测量带宽和时延的巧妙办法:绝大多数时间处于带宽探测阶段,也就是全速传输,偶尔尝试多发一些数据,如果时延上来了就说明带宽已经打满,如果时延没有升高说明还可以发得更快。少部分时间切换到延迟探测阶段,降低传输速度,取测得的时延极小值作为基础时延。这样就可以比较准确地估计 BDP,又能及时响应网络变化了。
对于随机丢包的场景,BBR 的表现很好。在 BDP 比较大的情况下,只要有万分之一的丢包率,TCP Cubic 的带宽就只剩下 30% 了;有千分之一的丢包率时,TCP Cubic 的带宽只剩 10%;丢包率达到 1% 时,TCP Cubic 就几乎卡住了。而 BBR 在丢包率 5% 以下时几乎没有带宽损失。
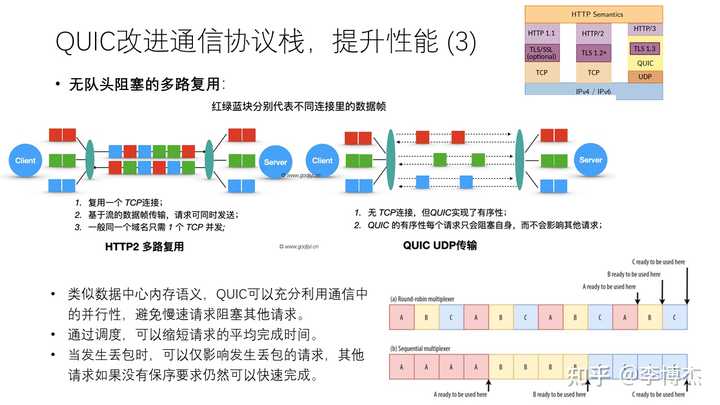
第三个问题是队头阻塞(head of line blocking)。前面在数据中心部分已经讲过,TCP 是字节流的抽象,也就是说所有数据都是有序传输的,同一个域名下面的多个 HTTP 请求或者 HTTP 响应之间就算没有前后依赖关系,也必须按序传输。这样其实是不高效的。
网络通信中的并行性是广泛存在,而又经常容易被忽略的。被忽略的原因是很多系统坚持保序的编程抽象,从而丧失了乱序传输的优化机会。
举个例子,微信的消息就是乱序传输的,有时候我们会发现发送和接收的消息顺序不一致。比如文字、照片和视频就是并行发送的,对方可能先收到文字,再收到照片,再收到视频。如果微信要求消息严格保序传输,那么一旦发送一个几百 MB 的大视频,可能几分钟都没法发送其他消息,这是无法忍受的。
另外一个例子,在视频会议中,音频的优先级是高于视频的,声音断了比视频卡顿一般来说更难以忍受,而且音频比视频的数据量小很多;在视频中,也存在关键帧(I 帧)和非关键帧(P 帧),每个 I 帧之间互相独立,每隔一段时间有一个,而 P 帧则是相对 I 帧的增量。I 帧如果丢了,后续的 P 帧也就无法解码了,因此 I 帧是更重要的。
QUIC 正是利用了网络通信中的并行性,使得每个 HTTP 请求或者 HTTP 流可以乱序独立发送,避免大的请求阻塞小的请求,避免一个请求丢包导致后续所有请求都要等它重传。在 QUIC 中,高优先级的请求可以插队发送,小请求也可以超越大请求,一个请求丢包了不影响不相关的其他请求。
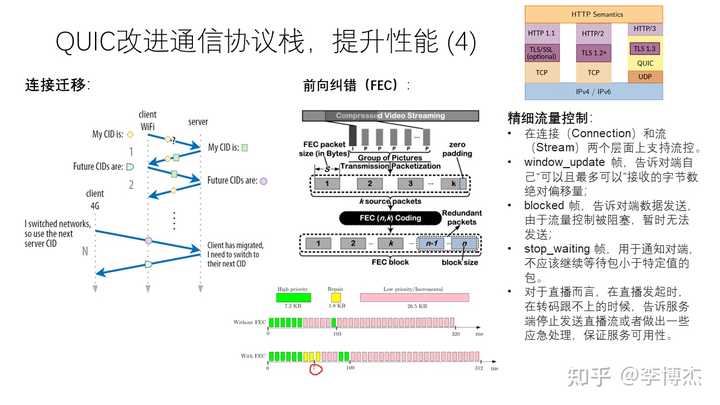
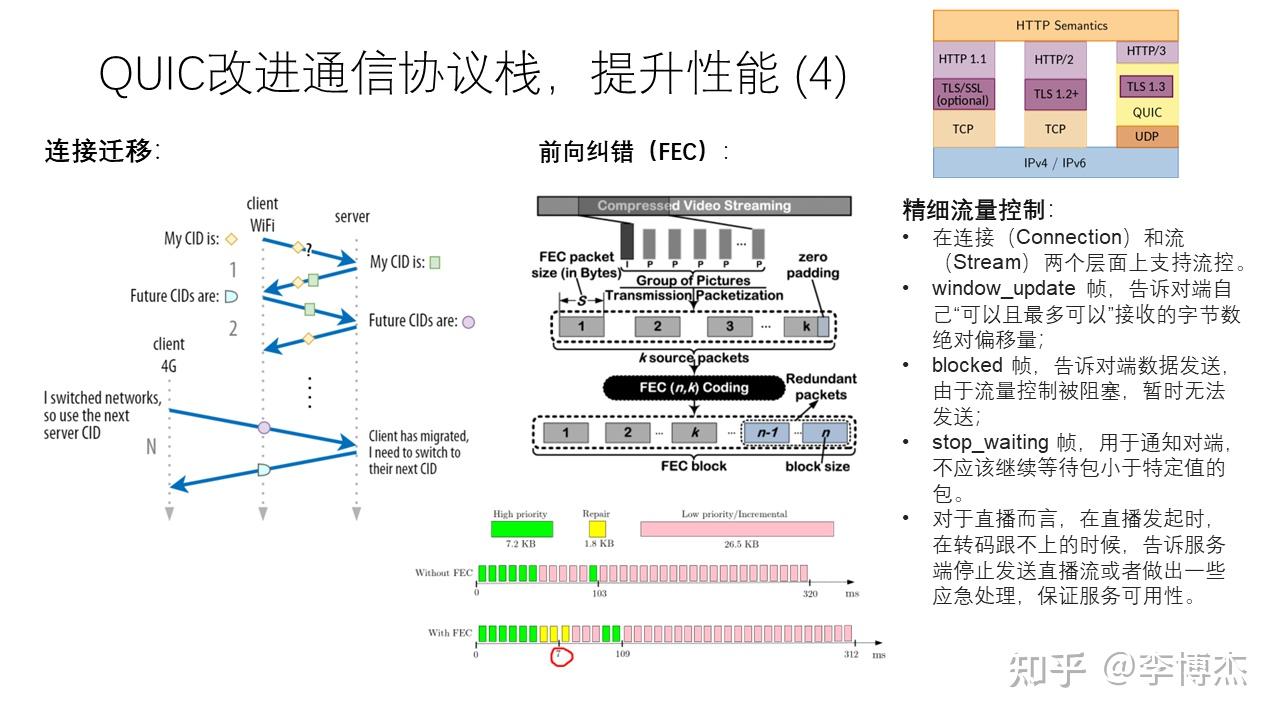
QUIC 把连接建立在会话层上的特性还充分体现在 “连接迁移” 上。传统的 TCP 连接是绑定客户端和服务端 IP 地址的。而在移动环境中,用户可能在 Wi-Fi 和 5G 之间迁移,客户端的 IP 地址可能改变。QUIC 既然已经不依赖 TCP/IP 五元组的概念区分会话,干脆就做得更彻底点,允许客户端 IP 地址变化,根据客户端的 Session ID 来判断是哪个会话。这样,用户就可以在不同的网络间 “漫游” 而无需担心连接中断了。这其实是类似 HTTP 等应用层协议中使用 Cookie 标识用户身份的方法。
QUIC 为了解决无线弱网场景下的高丢包率问题,引入了前向纠错(FEC)机制。前向纠错机制本质上是一种冗余编码,即使丢了一部分报文,也有比较大的概率能够把丢掉的报文恢复出来。前向纠错机制的代价是浪费了额外的带宽,因此 QUIC 会自动根据当前的丢包率选择合适的冗余编码方式。当然,前向纠错机制比较适用于随机丢包,但如果连续丢很多个包,前向纠错机制也回天乏术了。
最后,流量控制(flow control)一直是网络中的关键问题。流量控制的目的是在接收端的应用来不及处理或者接收内存缓冲区不足的时候,能够反压(backpressure)发送端,让它暂缓发送数据。很多人一直分不清流量控制和拥塞控制,拥塞控制的目的是降低多个并发连接经过同一瓶颈链路时带来的排队长度。具体到 TCP 协议中,发送端的 cwnd 就是为了做拥塞控制,rwnd 则是为了做流量控制,实际的发送窗口是两者的较小值。
针对直播等场景,有可能会发生转码跟不上直播的问题,导致卡顿。为了提升用户体验,QUIC 提供了精细流量控制的能力。在转码跟不上的时候,告诉服务端暂停发送直播流,或者采取降低码率等方式。


QUIC 相比传统的 HTTP over TCP 有很多改进,但它也仍然有很多可改进的空间。
在拥塞控制方面,BBR 的慢启动过程仍然需要多次网络往返,但很多请求仅需传输少量数据,慢启动阶段占了大部分甚至全部传输时间,需要更快速地探测到可用带宽。BBR 等通用拥塞控制算法的基本假设是长稳流量模型,也就是连接上有无穷多的数据源源不断地发送。但很多应用的流量是突发式的,如果为它预留带宽则会影响带宽利用率,如果不预留带宽又可能出现丢包或延迟骤增。此外,BBR 依赖对时延和带宽的测量,但一些场景下由于拥塞等原因,时延是经常抖动的,会导致 BBR 的 BDP 计算不准确。
在丢包重传方面,QUIC 采用了前向纠错技术,在随机丢包下表现较好,但在突发丢包下表现较差。此外还有伪丢包的现象,即时延抖动导致时延突然上升,被当作是丢包,导致不必要的重传。
最后,QUIC 只提供加密的可靠传输,要求所有数据都必须到达,但一些实时视音频数据事实上超时后没有必要重传,即使重传过去,对应的帧也已经被跳过了。
通过对 QUIC 等协议的系统优化,我们希望将端云广域网从 “尽力而为” 变为 “准确定性”,之所以我们在确定性前面加了一个 “准” 字,是因为在不可控的广域网上完全的确定性理论上就不可能实现,因此我们希望在大多数场景下对大多数典型业务实现一定的确定性时延、带宽,满足应用的服务质量需求。
云际网络


前面我们以 QUIC 为例,介绍了端云广域网通信协议的一些最新进展。事实上,广域网上除了从用户终端到数据中心的流量,还有很大一部分流量是数据中心之间的,叫做云际网络。
云际网络和端云网络最大的区别是云际网络的可控性一般比端云网络高很多。数据中心间的通信很多是走的专线,专线的带宽和时延都是比较稳定的,丢包率一般也比较低。即使是数据中心之间通过 Internet 通信,其带宽一般也是比较有保证的。此外,云际网络在数据中心出口处的网络交换设备一般是数据中心所有者控制的,因此在流量调度、拥塞控制等方面具有独特的优势。
云际网络的几个典型的应用场景包括:
- 同一 region(区域)内多个数据中心之间的数据同步,距离为数十公里,主要用于提升数据库等应用的可靠性,达到容灾的目的。
- 多个 region(区域)之间的数据同步,包括将各地的数据集中起来进行大数据处理等。
- 从大型数据中心到边缘数据中心和 CDN 服务器传递数据,用于缓存、直播等。
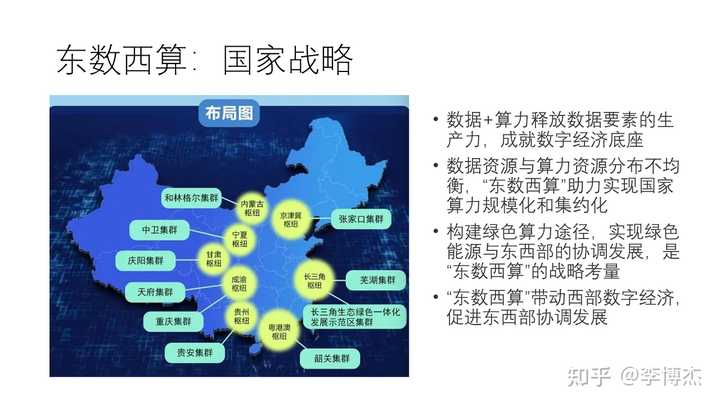
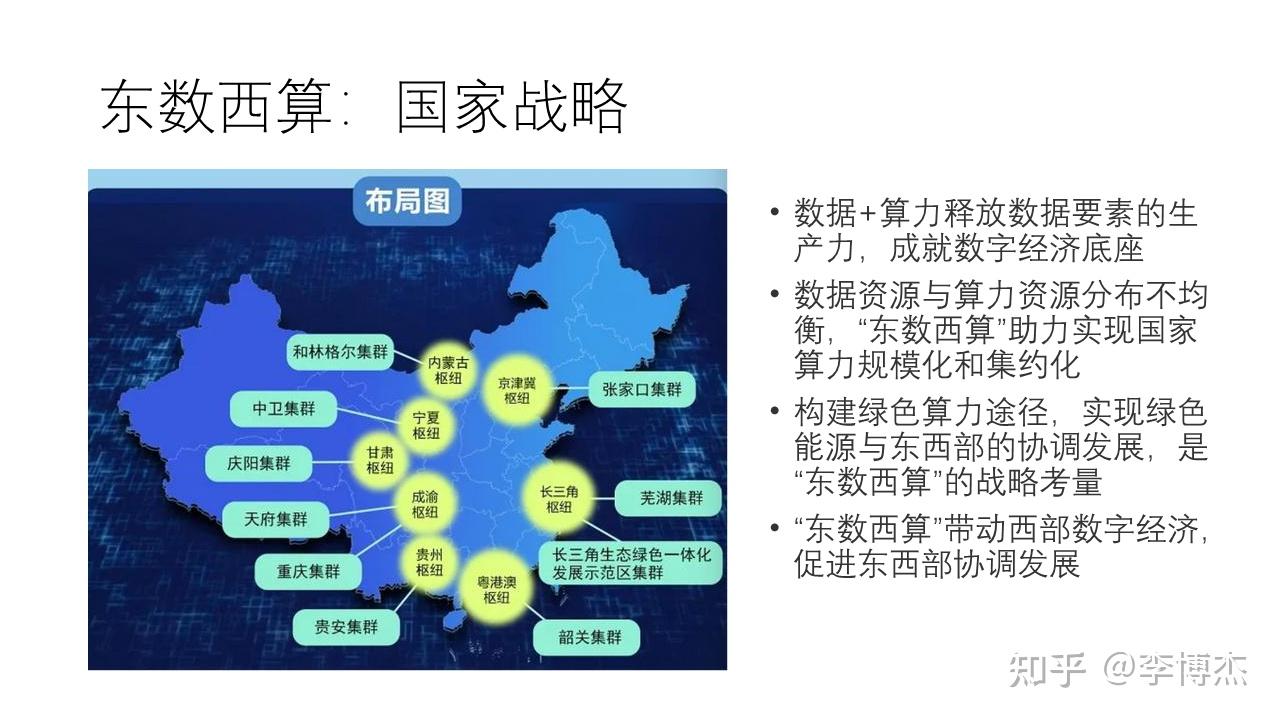
- 将成本较高的计算和存储任务迁移到成本较低的数据中心,在我国,这就是 “东数西算” 国家战略。
我国提出了 “全国一体化大数据中心” 的顶层设计,根据能源结构、产业布局、市场发展、气候环境等,在京津冀、长三角、粤港澳大湾区、成渝,以及贵州、内蒙古、甘肃、宁夏等地布局建设全国一体化算力网络国家枢纽节点,发展数据中心集群,引导数据中心集约化、规模化、绿色化发展。其中,国家枢纽节点之间的高速网络传输通道就是 “东数西算” 工程。
东数西算就像南水北调、西电东输一样,其他国家不一定有相同的战略诉求,也不一定能集中起足够的力量办成这件大事。显然,对时延要求高的任务适合留在东部,而对算力要求高的批处理任务适合放在西部。如何在东西部之间高效的划分任务和高效地传输数据,是一个重要的问题。


通常情况下,用户购买云服务的资源前,不管是 IaaS、PaaS 还是 SaaS,都是先选 Region(区域),而用户对云服务的全球部署、网络拓扑的连接并没有整体概念,所以云厂商需要将资源的分布、价格、使用现状一一呈现给用户,再让用户自行选择服务的部署区域,并自行在区域间进行互联组网。
华为云提出了 Regionless 的概念,期望为云上的租户提供 “全国一体化大数据中心” 甚至 “全球一体化大数据中心” 的编程抽象。
Regionless 就是在云的架构设计上打破 Region 级服务的约束,引入全域调度能力,基于对算力成本最优化、特定云服务及业务负载接入时延,以及应用/应用群之间的通信耦合关系,为用户提供最佳选择。至于具体云服务的资源实例发放到哪一个地理区域,完全由云的智能调度系统动态确定。
这个 Regionless 化的过程中,由华为云来完成调度策略,屏蔽底层资源调度的复杂性。用户无需自己选择地理 Region,就能享受全局服务的全球部署能力。通过这种方式,可以解决东西地区的平滑引流,使得用户在几乎无感知的情况下,将业务负载从东部城市平滑地迁移到西部,比如华为云的乌兰察布数据中心、贵安数据中心。其中涉及到地区层面的架构分层以及全域调度,乃至东部和西部资源的定价差别等等。
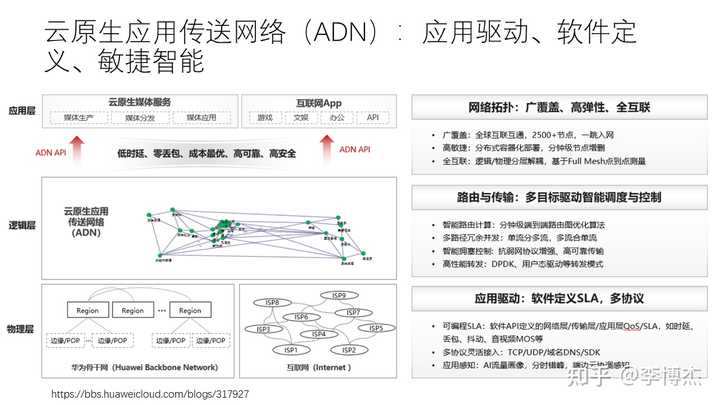
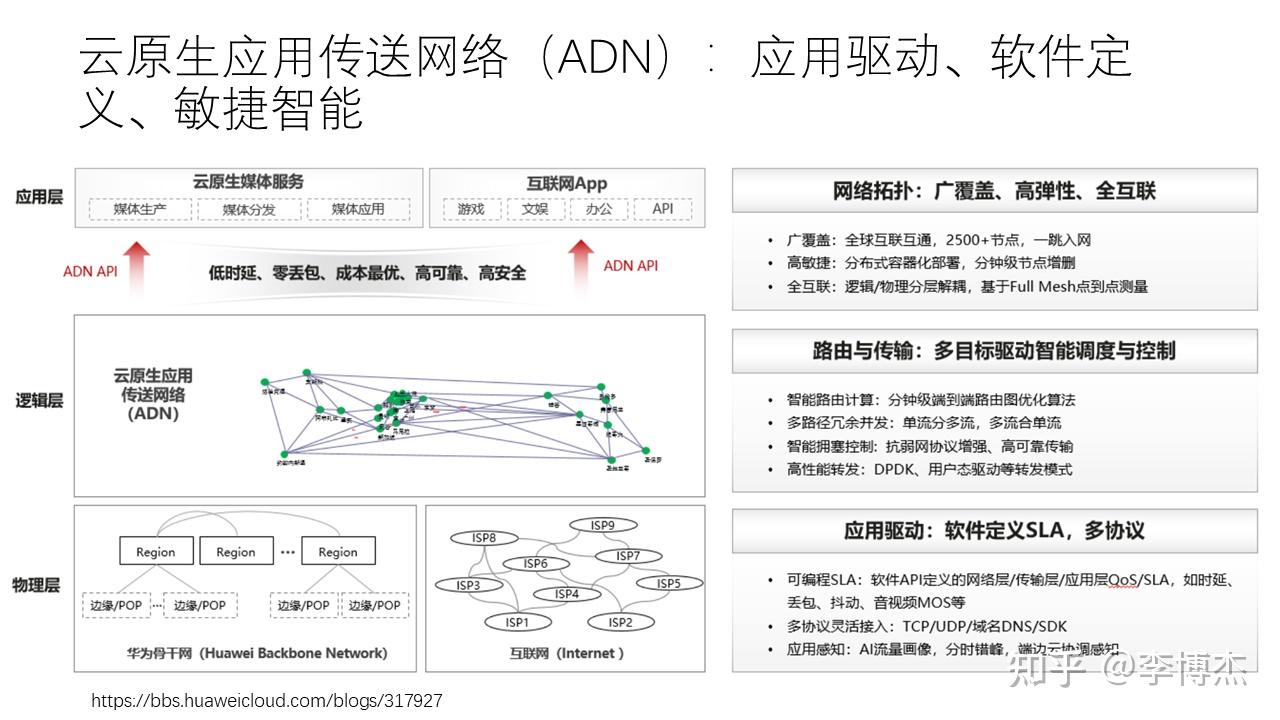
为了构建高性能的云际网络,华为云构建了云原生应用接入网络(ADN)。ADN 的底层是专线和 Internet,专线的稳定性高,但在总的租用带宽低的时候成本较高,单位带宽的专线租用成本是随总的租用带宽量降低的。Internet 的稳定性较差,但成本可能较低。这样,高优先级的、时延敏感的流量就更适合走专线,其他流量更适合走 Internet。
为了提高可靠性,专线和 Internet 互为冗余关系,不同的路由路径也是互为冗余关系。由于专线网络拓扑的原因,直连的专线带宽可能不如通过中间节点绕行更大,因此最短路未必是最优路径。流量工程(Traffic Engineering)就是根据用户对流量的带宽需求和优先级,将流量路由到不同的网络路径上。
跟前面讲过的端云网络的 QUIC 一样,云际网络的流量工程也需要用户指定优先级等 QoS(服务质量)需求。在系统设计中,让应用给系统提供提示(hint)是一个常见的优化方式,如果系统缺少应用的信息,那么很多时候根本没办法做好优化。
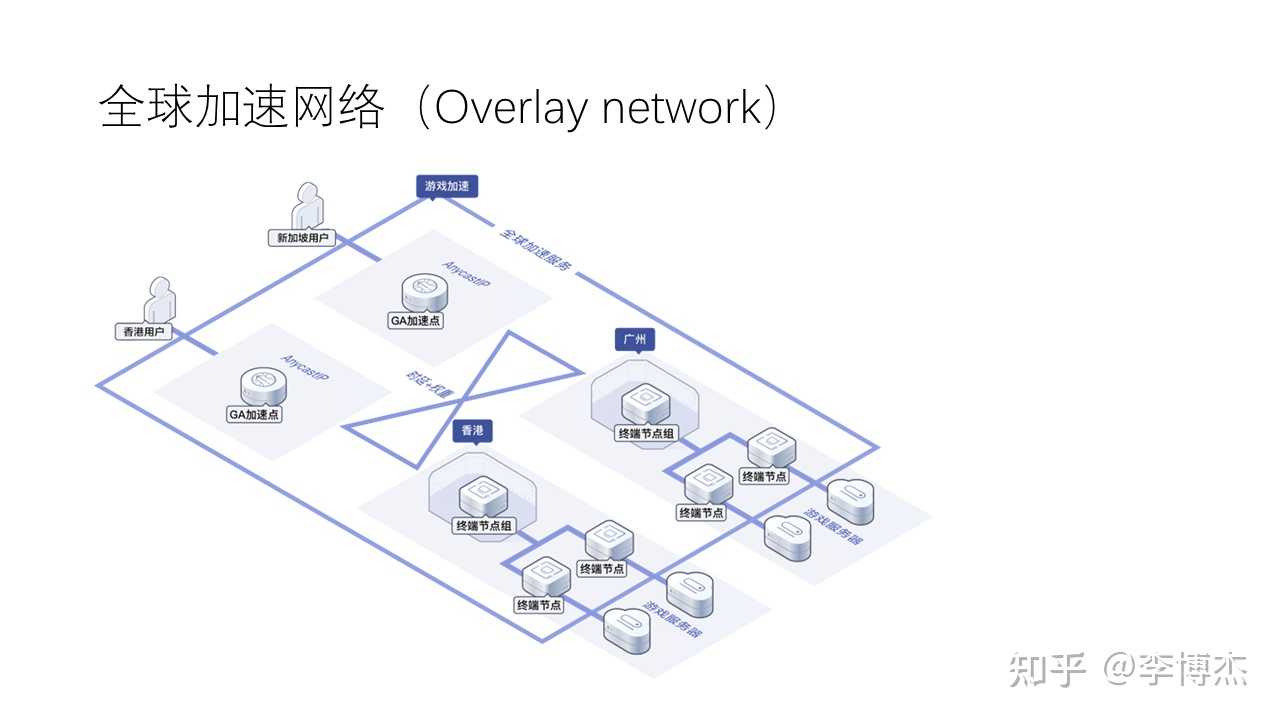
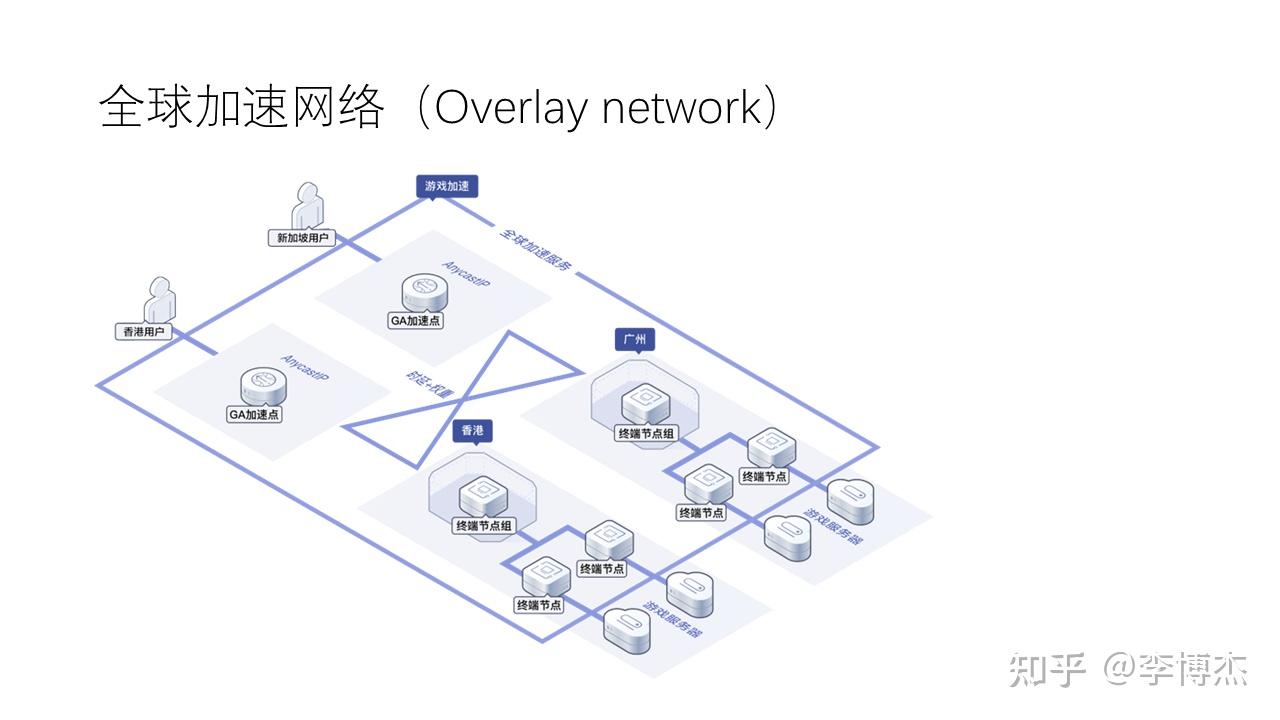
基于上述的高性能云际网络,我们不仅可以加速跨数据中心服务器之间的通信,还可以加速端侧用户接入云上的业务。包括华为云在内的很多云服务商提供了全球加速覆盖网络(overlay network)。所谓覆盖网络,就是在物理网络拓扑的基础上覆盖一层逻辑拓扑,组成一个虚拟网络。
如上图所示,业务首先通过 Internet 连接到最近的全球加速覆盖网络入口节点,然后覆盖网络将报文路由到对应的数据中心。全球加速覆盖网络属于云际网络,其中经过的是专线或者服务商优化过的 Internet 链路。相比跨区域、长距离的 Internet 网络,很多情况下先接入覆盖网络再在覆盖网络内路由到目标数据中心的服务器,比直接通过 Internet 连接到同一个服务器的时延更低,带宽更高,丢包率更低。这里,端云网络通信被云际网络加速了。
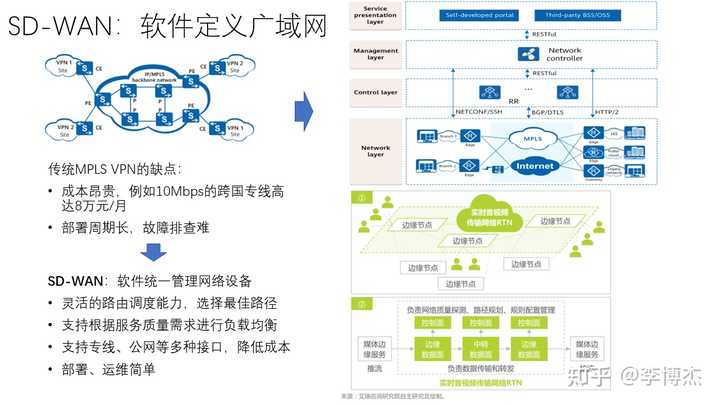
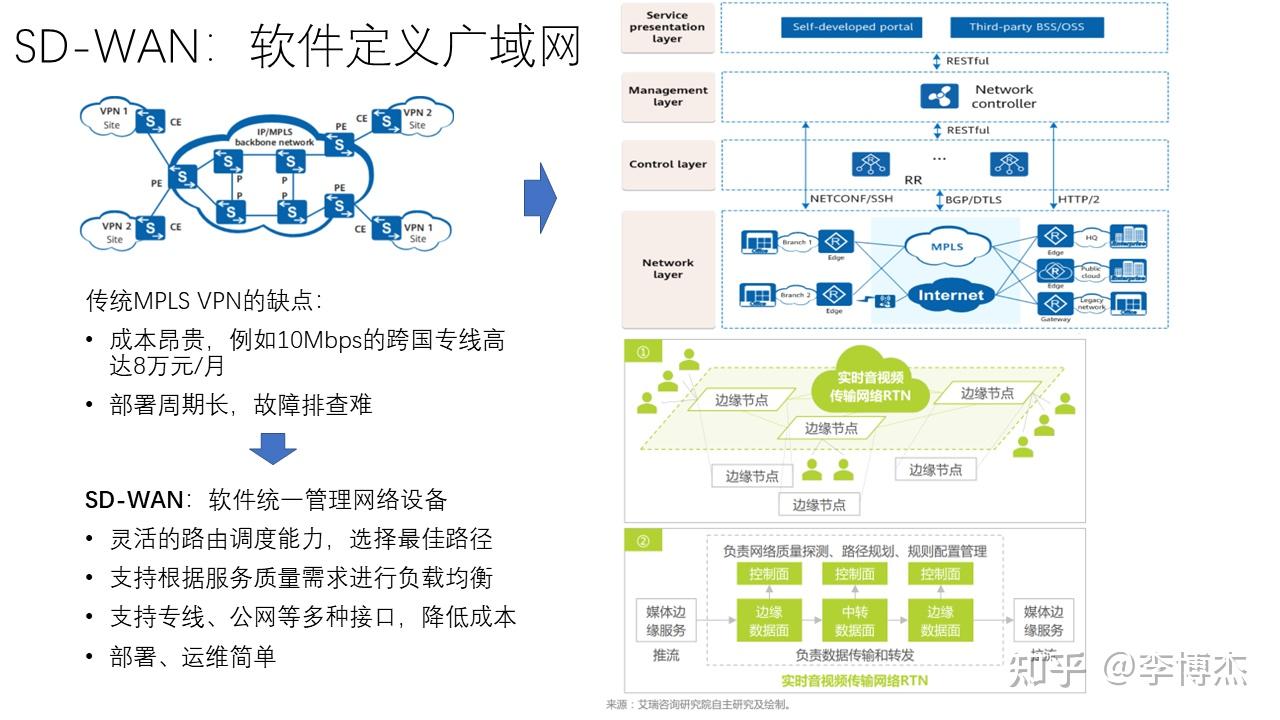
在广域网的管理方面,目前业界已经广泛采用 SD-WAN(Software-Defined WAN)的方法,继承自 SDN(Software-Defined Network)的概念。在 SD-WAN 中,软件统一管理网络设备,网络控制器软件可以通过 RESTful 等标准接口统一管理和配置各种不同厂家的网络设备,从而具有灵活的路由调度能力,支持根据 QoS(服务质量)需求进行负载均衡,支持专线、Internet 等多种接入方式,简化部署、运维。
SD-WAN 也可以管理 CDN 等边缘节点。基于 SD-WAN 的实时视音频传输网络(RTN)的软件控制面统一管理边缘节点和数据中心节点,负责网络质量探测、路径规划、规则配置管理等;而数据面负责数据传输和转发。
本章小结
以上就是广域网部分的内容。
大规模直播和短视频点播、实时音视频通信等应用对广域网传输的稳定性提出了新挑战。互联网巨头纷纷自建全球加速网络,并设计 QUIC 等新型传输协议,实现优质用户体验。此外,由于我国西部能源成本低,东数西算成为国家战略,通过 Regionless 调度,实现 “全国一体化大数据中心”。
无线网络


无线网络是一个非常广阔的领域,对应华为的两大产品线,一是无线,二是消费者 BG。无线主要就是我们熟悉的 5G 和 Wi-Fi,而消费者 BG 做的是包括手机在内的各种智能终端。
在上一章广域网开头我们就提到,当前的传输协议对无线网络和广域网的带宽并没有充分利用,导致很多应用实际上无法体验到 5G 和 Wi-Fi 标称的数百 Mbps 高带宽,这就是我们常说的 “最后一公里” 问题。随着无线网络的性能越来越接近有线网络,一些原本适用于数据中心的优化将适用于无线网络。之前我们提到分布式系统,想到的都是数据中心,而现在家中这么多终端设备和智能家居设备,也组成了一个分布式系统,未来有可能一个家庭就是一个迷你数据中心。
无线性能接近有线
无线网络的性能优化
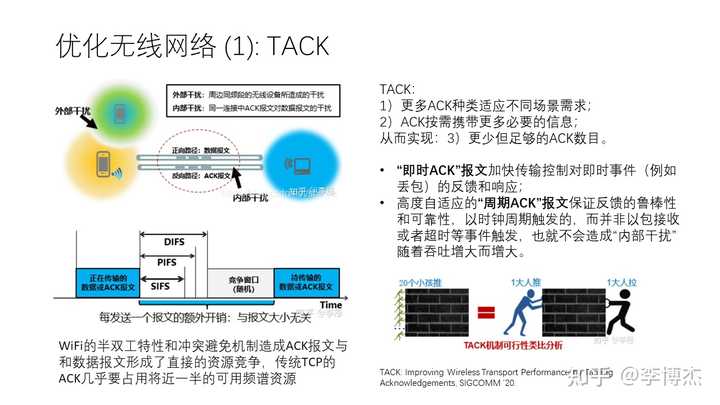
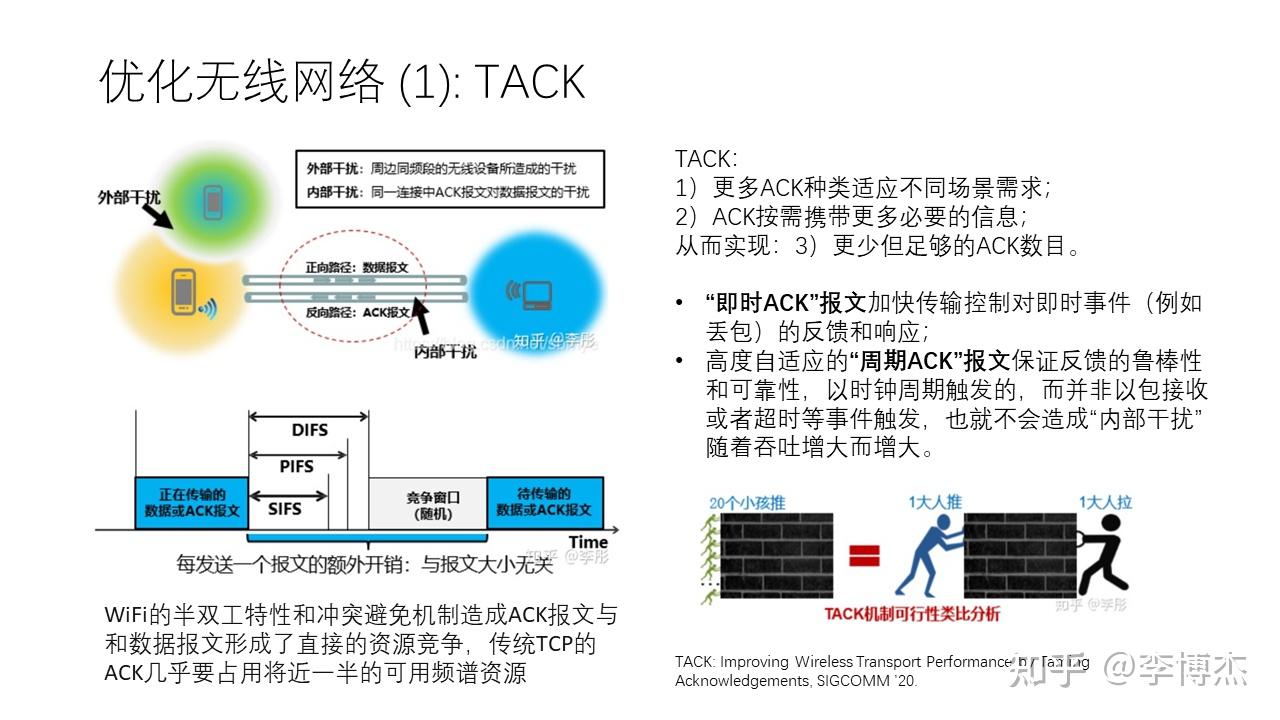
为什么 5G 比 Wi-Fi 的频谱利用率高呢?就是因为 5G 是中心化的分配时隙,Wi-Fi 是载波监听(CSMA)模式的抢占,看到没人发包自己就去发,如果跟其他人冲突了就过一段时间重发。抢占模式理论上的频谱利用率就不会很高,大家可能记得计算机网络课本上学过的 ALOHA 协议,它的最大信道利用率只有 18%;即使把时间分成固定长度的时隙,最大信道利用率也只有 37%。但是我们短期内又没办法修改 Wi-Fi 的协议,因此只能尽量减少不必要的冲突。
我们发现,TCP 协议默认情况下每 2~3 个数据报文都会返回一个 ACK 报文,一方面为了确认数据报文已经收到,另一方面为了做拥塞控制和流控。在数据中心内通信的一些场景,我们希望把每 2~3 个报文返回一个 ACK 改成每个报文都返回一个 ACK,以便做更精细粒度的拥塞控制。但在无线网络的场景中,由于我们的主要问题是频谱利用率低,我们希望减少 ACK 的数量。在 TACK 这个研究工作中,我们通过减少 ACK 的数量,让每个 ACK 携带更多的信息,达到提高频谱利用率的效果。
TACK 提供了两类 ACK,一类是 “即时 ACK”,加快对丢包等事件的响应;另一类是 “周期 ACK”,是每过一段时间触发一次,而不是每收到两三个报文就触发一次。这样,既不会减慢拥塞控制信息的反馈速度,又减少了 ACK 的数量,减少了不必要的信道冲突。
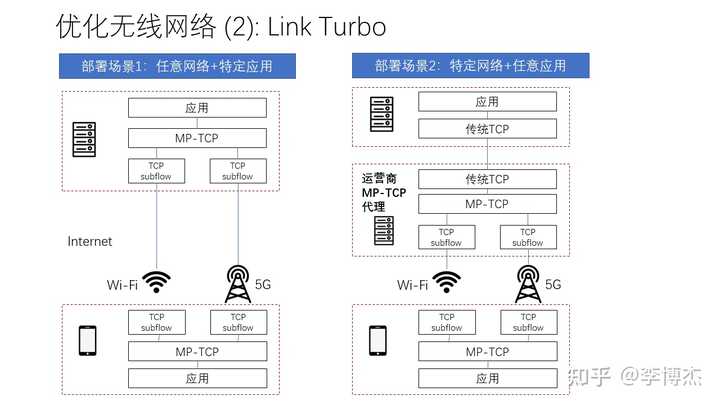
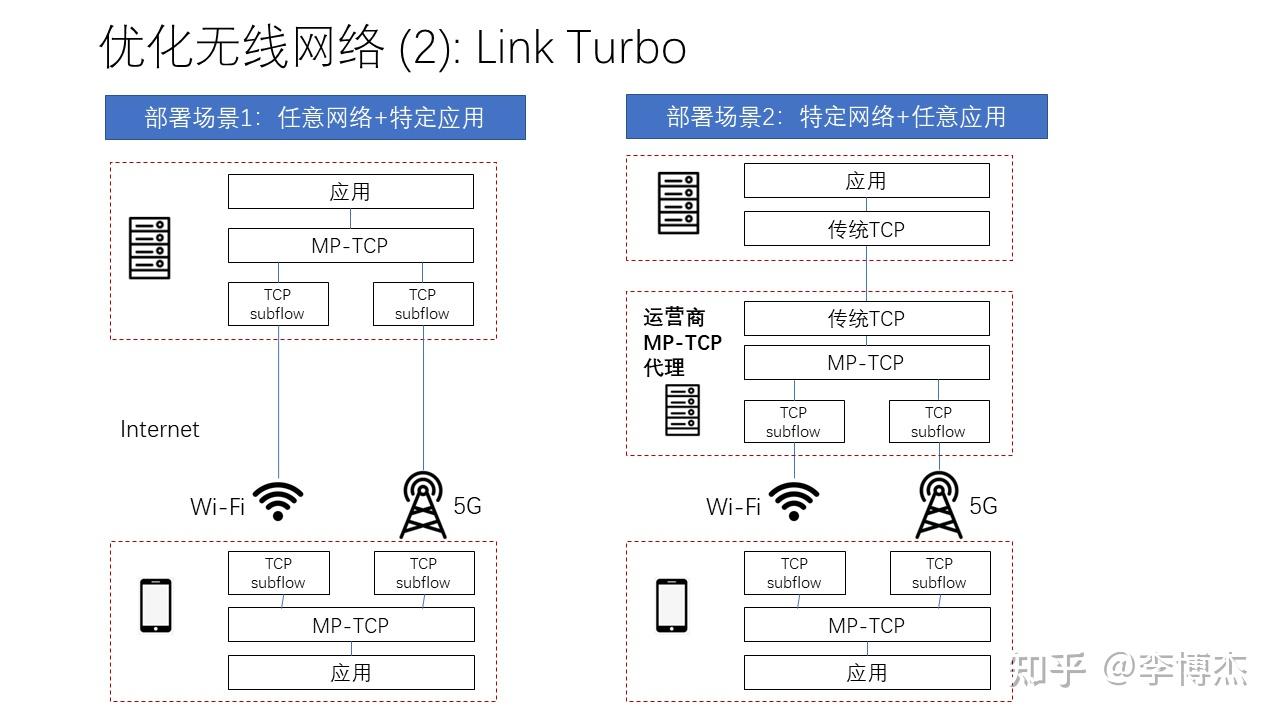
另一项关键技术是 Link Turbo,就是把 5G 和 Wi-Fi 两种物理信道一起使用。提升带宽倒是其次的,更重要的是提高可靠性。比如我们微信消息半天发不出去,或者视频会议中间卡顿,都是用户很难忍受的。单独使用 5G 或者 Wi-Fi,有时 5G 信号好,Wi-Fi 信号差,有时则反过来。此外,经常出现信号看起来很强,但实际丢包率很高的场景,例如连上了不能上网的公共 Wi-Fi。
解决此类问题的方法就是同时利用 5G 和 Wi-Fi 来发送数据。这里 5G 是泛指运营商的蜂窝网络,也包括 4G。一种最简单的方式是把每个数据报文都通过 5G 和 Wi-Fi 发送两遍,但这样显然会浪费一倍的带宽,而且在 Wi-Fi 信号较好时也会浪费较多 5G 流量。因此,Link Turbo 持续测量每种无线信道的性能,并决定如何把数据在各种无线信道之间分配,以及决定是否使用 FEC 编码的方法冗余发送数据。
让流量同时走 Wi-Fi 和 5G 有一个重要问题,就是服务器怎么知道这两条路上来的报文是同一个连接的呢?在服务器看来,同一个手机 Wi-Fi 和 5G 的公网 IP 几乎肯定是不同的。上一章 QUIC 中有个 Session ID,可以支持连接迁移,但是它做得还不够彻底,并不能支持数据包同时从两个源 IP 到达。为了解决把一个连接拆分成多个子连接的问题,一个关键技术就是 MP-TCP(Multi-Path TCP,多路径 TCP)。
最理想的情况就是左图所示,服务器或者数据中心的网关支持 MP-TCP 协议,这样手机终端拆分出的多个子连接在服务器或者网关就可以被聚合起来。但事实是,MP-TCP 虽然已经标准化了很久,也进入了 Linux 内核,很多服务器和云厂商的网关并没有启用它。因此,这种部署形态仅对服务器端支持 MP-TCP 的特定应用有效。
如何在服务器或者云网关不支持 MP-TCP 的情况下,让应用能够用上 MP-TCP,解决无线网络 “最后一公里” 的问题呢?右图中的代理就是一种可能的部署形态。应用或者终端操作系统设置运营商部署在边缘或城市数据中心的代理服务器,在代理上聚合并终结 MP-TCP,再通过标准的 TCP 协议连接到真正的服务器。这种方案适用于任意应用,但代理服务器的带宽等成本较高。
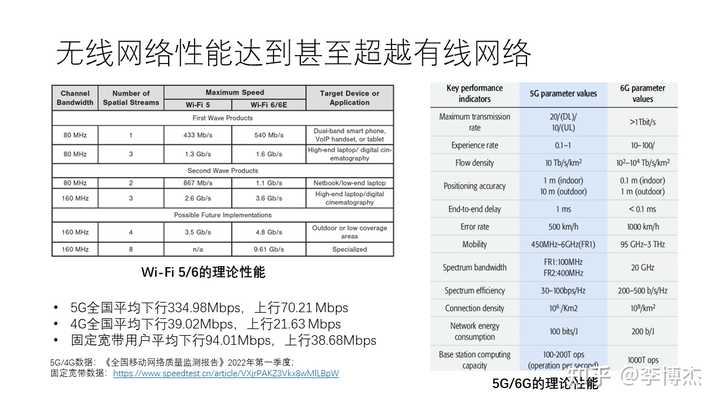
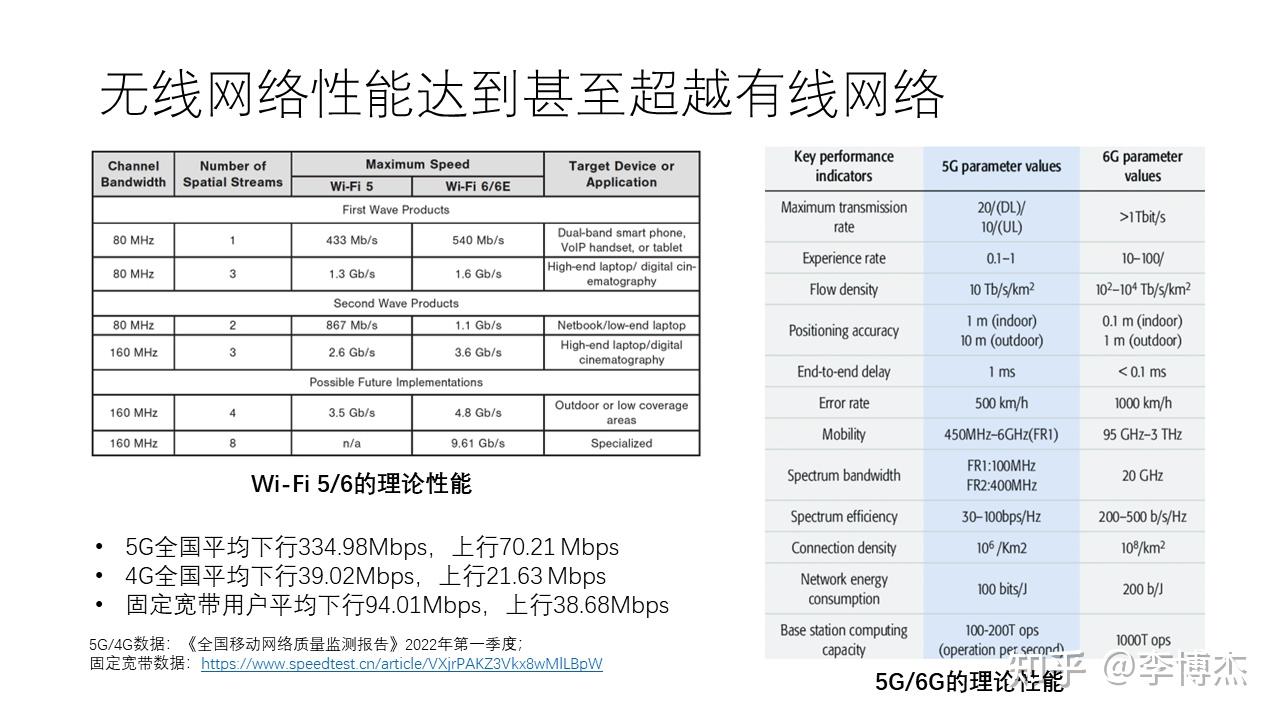
大家也许已经知道,无线网络的带宽目前已经很高,达到甚至超过很多有线网络了。例如 Wi-Fi 6 的理论速率可以达到 1 Gbps 以上。使用测速工具测出来的 5G 全国平均下行速率达到 335 Mbps,是 4G 平均下行速率的 10 倍;5G 平均上行带宽没有下行那么高,但也达到了 70 Mbps,这个上下行的不对称是 5G eMBB 天生的。相比之下,虽然大城市里家庭宽带动辄几百 Mbps 甚至上 Gbps,但全国来看平均下行带宽只有 94 Mbps。也就是说,5G 的平均速率已经超过了家庭宽带。使用 5G 传输大量数据的最大障碍在于流量成本,目前还没有降到跟有线网络同样一个量级。
随着我们的管道越做越大,管道充分利用可能不一定是最关键的,更重要的是达到 “准确定性” 的时延和带宽,提升服务质量。这跟数据中心流量调度的思路是一样的,不管是优先发送小流,还是用 coflow 的概念协同优化一组流的完成时间,在无线网络中,也需要来自应用的更多信息才能更好地对流量进行调度。
在端云网络一节中我们提到一个问题,目前的拥塞控制协议很难感知到实际可用的带宽,因此慢启动和突发流量的表现不好。我们如果做一个大胆的假设,在大多数端云传输中,广域网和数据中心网络都不是瓶颈,那么主要瓶颈就是无线接入网络,这时只要硬件根据信号强度、干扰、共享的终端数量等信息估计出可用的带宽,就可以估计出端云传输的最大可用带宽。如果有多个应用同时访问网络,也可以在终端上做一个智能调度的服务,根据服务质量(QoS)等信息来做调度,而不是让各个连接分别独立争抢共享的无线带宽。
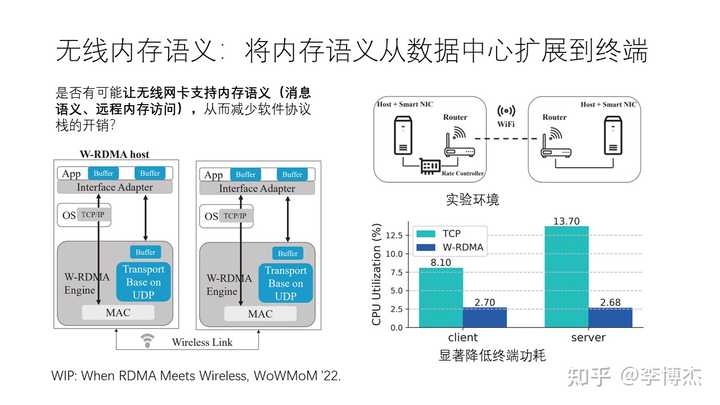
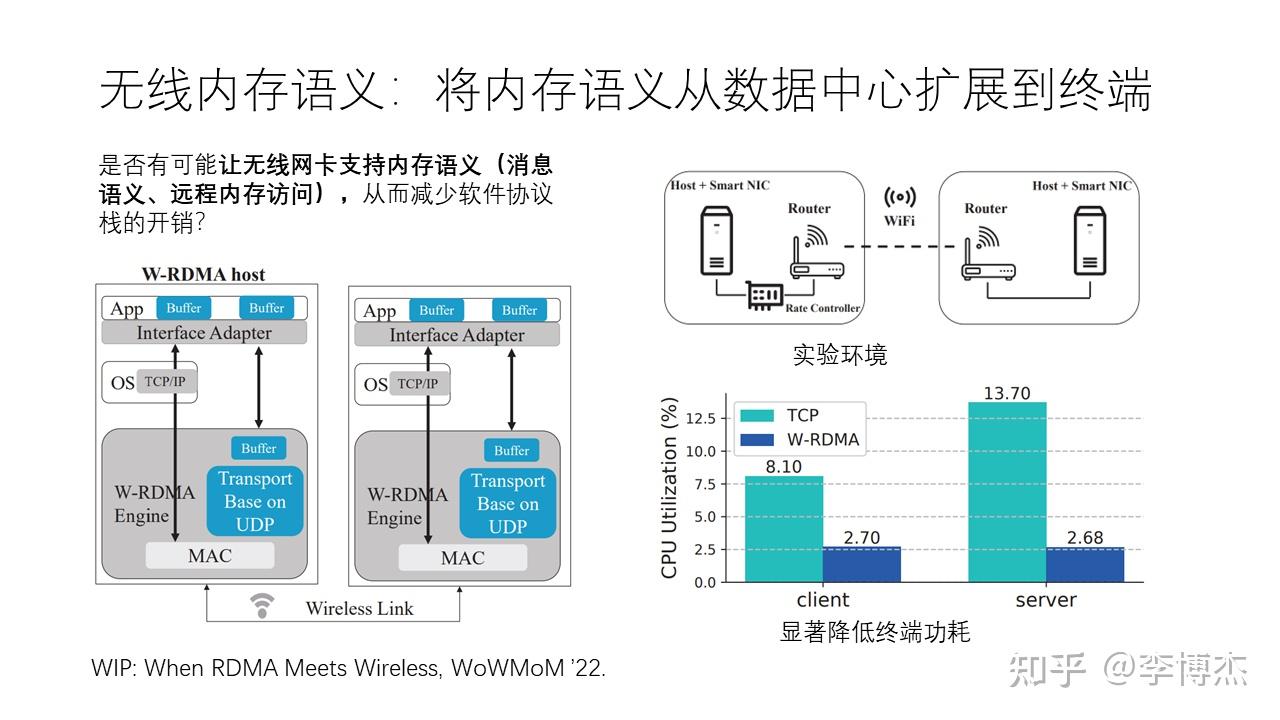
至少在家庭局域网的范围内,无线网络的带宽已经达到 Gbps 级别,可以组成高带宽、低时延的家庭分布式系统。数据中心的带宽是 100 Gbps 级别,时延是微秒级别,而终端无线网络的带宽是 Gbps 级别,时延是毫秒级别。但考虑到终端 CPU 的算力远远低于服务器 CPU,Gbps 级别的带宽使用传统的 TCP/IP 协议栈已经占用了手机等终端不少的 CPU 资源。因此才会出现我们买了相对便宜的一些家用路由器之后,达不到标称的千兆转发带宽。由于终端 CPU 的睡眠模式功耗限制了唤醒时延,TCP/IP 协议栈的延迟也达到了毫秒级,超过了基带芯片和无线空口的时延,因此也是值得优化的。
因此,我们也在尝试把内存语义从数据中心扩展到终端,让手机等终端的无线网卡支持类似 RDMA 的内存语义,从而减少软件协议栈的开销。我们发表的 WIP 论文表明,假设无线网卡支持内存语义,TCP/IP 协议栈所占的终端功耗显著降低,客户端降低到 1/3,服务端降低到 1/5。期望未来的无线网卡芯片能够将无线内存语义真正实现。
讲到这里,想起我博士期间思考过的一个探索性问题,用一些手机的 SoC 芯片组成的阵列是否有可能达到相当于服务器 CPU 或者 GPU 的算力呢?我们评估之后发现,如果所计算的任务是容易并行的,那么用手机 SoC 芯片甚至还有一定的性价比优势。这就像系统领域的一篇著名论文 “ FAWN: A Fast Array of Wimpy Nodes ”,用一些很弱的节点组成高性价比的存储阵列。但如果所计算的任务是不容易并行的,比如比较大的深度学习模型训练或推理,那么关键瓶颈点就在 SoC 之间的通信上了。
手机 SoC 并不像服务器上的 PCIe 板卡一样可以通过有线连接随意组合,只能通过性能有限的无线接口组成松耦合的系统。但我们并不需要真的用一大堆手机 SoC 芯片去替代 NVIDIA A100,对于很多智能家居中的分布式应用来说,Wi-Fi 6 的无线性能已经足够了,只要我们把 AP 布局合理,把无线理论性能充分利用起来,“家庭数据中心” 一定会逐渐成为现实。
5G to B
说到 5G,很多人认为它只是用于消费者领域。其实 5G 在 B 端的应用场景更为广阔,在此我简单举几个场景作为例子。


港口中的集装箱堆垛是靠龙门吊来搬运货物的,传统上需要操作工人爬到龙门吊顶上高高的操作室,俯视下面的集装箱堆垛来进行操作,操作工人长时间俯身工作,很容易出现腰肌劳损。使用 5G 技术后,操作室的实时图像传送到中控室,操作工人坐在办公室里就能控制龙门吊精准移动。
这样的实时操控需要 10 毫秒级别的时延,传统的 4G 技术是不能满足需求的。Wi-Fi 的覆盖距离又太短,不能满足数百米的远程控制需求。同时,港口场景对 5G 上行带宽要求比较高,因为实时高清图像需要从龙门吊通过 5G 上传到中控室。这跟消费者领域的下行带宽超越上行带宽是不同的需求。
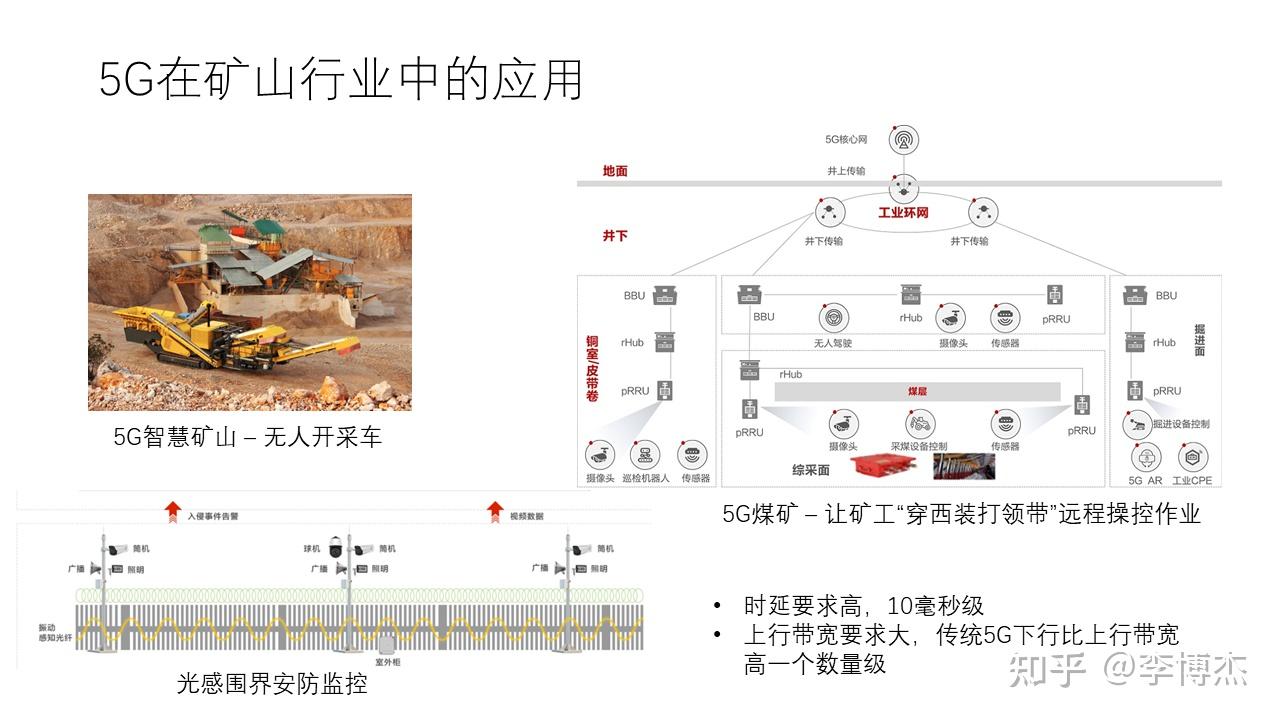
在矿山场景中,煤矿工人都是非常辛苦的,而且经常面临危险。我们的理想是让矿工 “穿西装打领带” 地远程操控作业。首先,需要矿工远程控制无人开采车,有的是图里这样在地面上开采,有的是在地下的煤层中开采。其次,需要各种矿井内的传感器,包括图像、有害气体、风速、压力、温湿度等。最后,还需要矿区周界的安防监控。
与港口场景类似,矿山场景的实时操控也需要 10 毫秒级别的时延,同时也是对上行带宽的需求高于下行带宽。
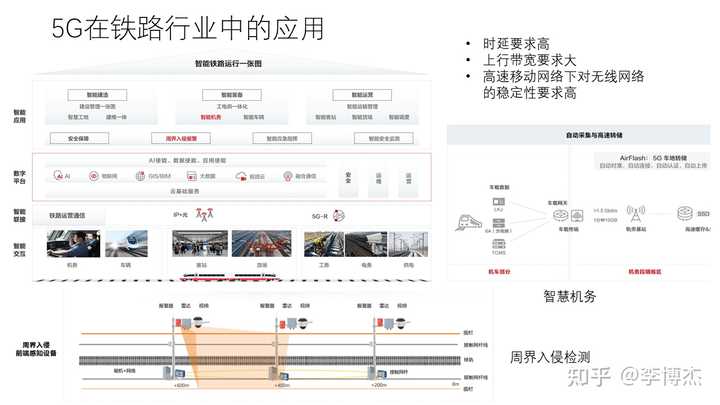
在铁路场景中,首先需要智慧机务,也就是高铁上的列车运行监控系统(LKJ)、机车车载安全防护系统(6A)、列车网络控制系统(TCMS)采集包括音视频、各种传感器数据在内的信息,通过车载网关上传到铁轨旁边的基站,然后再走有线线路汇总到路局控制中心,持久存储下来。一列列车需要的带宽高达 1.5 Gbps 以上,而且需要在 350 km/h 高速运行的高铁上不间断发送,对 5G 上行的考验是非常大的。为此,列车车载网关的天线开发了自动对准基站的机制,实现高速运动场景下的高速传输。
有了高效的车地通信机制,除了智慧机务,还有望解决高铁上运营商信号差的问题,通过车载 Wi-Fi 等方式为乘客提供更好的互联网体验。
此外,铁路线路被非法入侵一直是一个安全隐患,周界入侵检测系统可以通过雷达、视频等方式检测入侵,并通过轨旁基站上传。
以上这几个 5G to B 的应用其实也是在物联网的范围内。目前物联网在学术界也非常火,但很多学生对物联网的了解仅限于智能家居里面摄像头、门锁、开关、温湿度传感器这类简单的控制系统和传感器,因此很难想到有挑战的问题。要做好物联网研究,一定要深入到产业里面,制造业、港口、矿山、铁路、机场、森林等工业里面的传感器可谓琳琅满目,对性能指标的要求很多是非常苛刻的,有很多值得研究的问题。
卫星通信
最近(2022 年 9 月)华为和苹果最新发布的手机都支持卫星通信,加上马斯克的星链,卫星通信又火起来了。卫星轨道按照轨道高度,划分为 vLEO、LEO、MEO、GEO 等。在卫星通信领域,“占频保轨” 是很关键的,因为通信频率和卫星轨道是稀缺资源,先到先得。因此各国都在加紧构建卫星星座,上世纪的铱星虽然商业上失败了,但它的频率和轨道资源仍然是非常宝贵的。
- 100 公里是卡门线,再往下就是各国的领空了。
- 100~500 公里是 超低轨(VLEO,Very Low Earth Orbit) ,这个区间主要用于做高清图像卫星,蜂窝通信的补充,以及 6G 通信的探索性验证。
- 500~2000 公里是 低轨(LEO,Low Earth Orbit) ,主要是用于军事和通信,例如最早的铱星,现在马斯克的星链(Starlink),苹果卫星通信用的 Globalstar,以及 Amazon 的 Kuiper,都在这个区间里面。这个区间是相对拥挤的,低轨目前已经有 4000 多颗星,绕地一周的时间是 1.5~4 小时。低轨卫星的优势是发射相对容易,通信时延短(5~10 ms),可以使用较为空闲的数十 GHz 的 Ka 和 Ku 频段来通信,而且手持设备用 1W 的功率就可以实现通信。缺点是经过服务的国家和地区上空时间短,只有 5~8 分钟,并且多普勒频移比较严重。
- 2000~10000 公里是 中轨(MEO,Medium Earth Orbit) ,主要用于陆基通信的补充和海事通信,目前全球有 200 多颗星,绕地球一周的时间是 12 小时。
- 10000 公里以上是 高轨(HEO,High Earth Orbit) ,其中包括约 36000 公里的 地球静止轨道(GEO,Geostationary Earth Orbit) ,GEO 轨道上的卫星是相对地面上的观察者静止的,这样与之通信的卫星天线就不需要移动。HEO/GEO 主要用于定位、导航类。例如中国的北斗就是由 2.1 万公里和 3.6 万公里的星座构成的,美国的 GPS 是由 1.9 万公里的 24 颗卫星构成的,欧洲的伽利略是 2.4 万公里的星座。目前全球一共有 500 多颗星。华为手机的卫星通信就是基于北斗的短报文服务。HEO/GEO 的优点是服务时间长,缺点是发射需要的火箭技术高,通信时延高(HEO 在 200 ms 以上,GEO 在 250 ms 以上),一般需要手持设备 5W 的发射功率才能实现通信,并且由于大气对高频吸收的影响,只能跟地面基站无线网络一起挤 1~4 GHz 的 L/S 频段。
以上超低轨、低轨、中轨和高轨的划分是比较主观的,物理上并没有很明显的分界线,例如有的人认为北斗 2.1 万公里的轨道属于中轨(MEO)。
目前手机直连卫星通信只能用于紧急救援场景,不能用来日常打电话或者浏览网页。主要原因是与卫星通信所需的发射功率太大,比如传统的卫星手机是 2W,有一个很大的外置天线,蝶形天线(大锅)是 4W,而消费电子终端允许的发射功率只有 0.2~0.4W,因为发射功率太大对健康是有影响的。因此,要在普通手机上用较低的发射功率提供跟传统卫星手机相同的通信能力,是需要很高的技术的。
支持卫星通信的手机首先把数据发送到卫星,卫星转发到信关站。信关站就是固定在地面上的一口大锅,它的功率比一般的蝶形天线大很多,因此带宽可以达到 Gbps 的级别。然后信关站再转发到核心网。Starlink 也提出了使用卫星之间的激光通信来将数据转发到信关站没有覆盖的区域。但不管怎么转发,信关站的建设成本是远远超过运营商基站的,因此大城市中海量的移动网络带宽需求还是需要以地面蜂窝网络为主。
鸿蒙分布式超级终端


随着无线性能接近有线,家庭数据中心的概念成为可能。我们希望把家庭中的各种设备组成一个 “分布式超级终端”,从用户的角度看可以实现数据和服务在各个终端间无缝流转,从开发者的角度看可以用统一的 API 来进行开发,无需关心通信的细节。

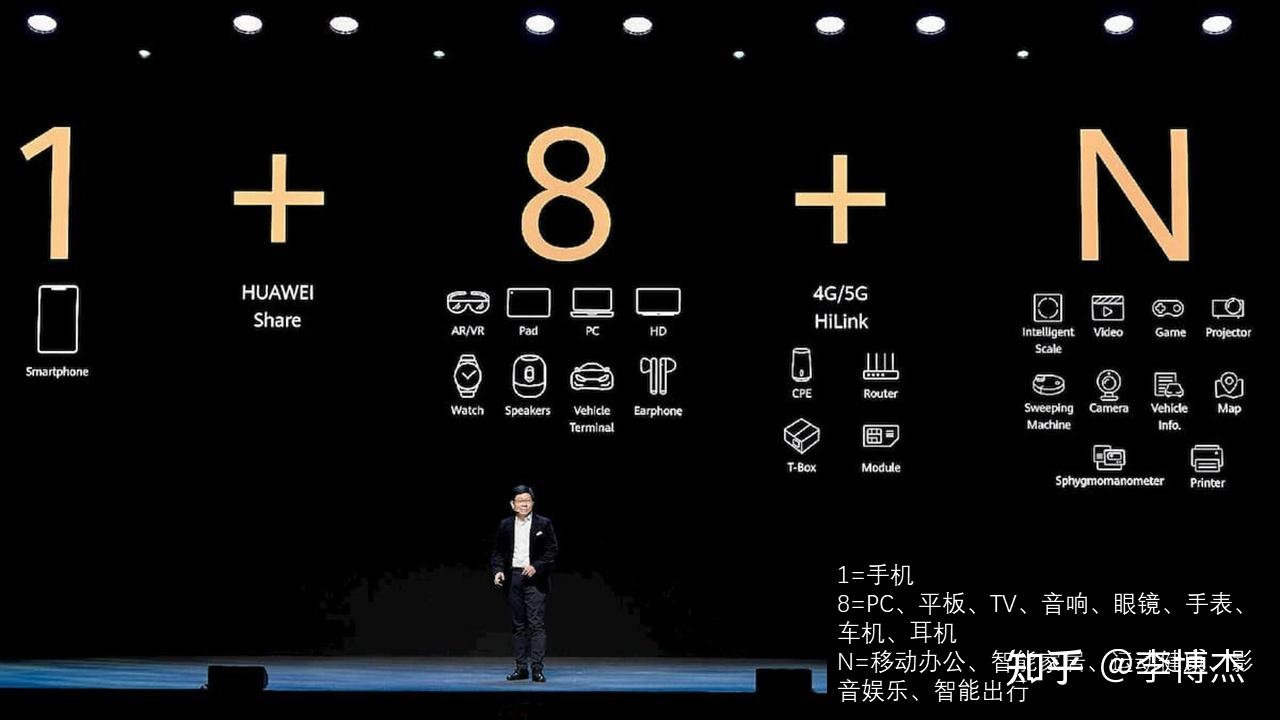
鸿蒙分布式超级终端的概念包括 1+8+N,其中 1 是手机;8 是各种智能设备,目前包括 PC、平板、电视、音响、眼镜、手表、智能驾驶中的车机、耳机;N 是多个场景,包括移动办公、智能家居、运动健康、影音娱乐、智能出行等。
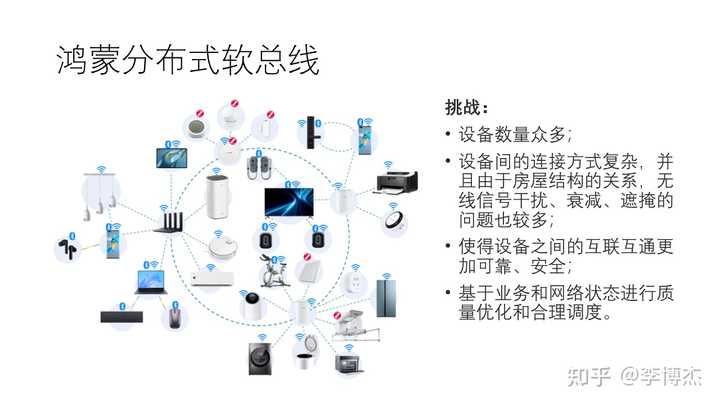
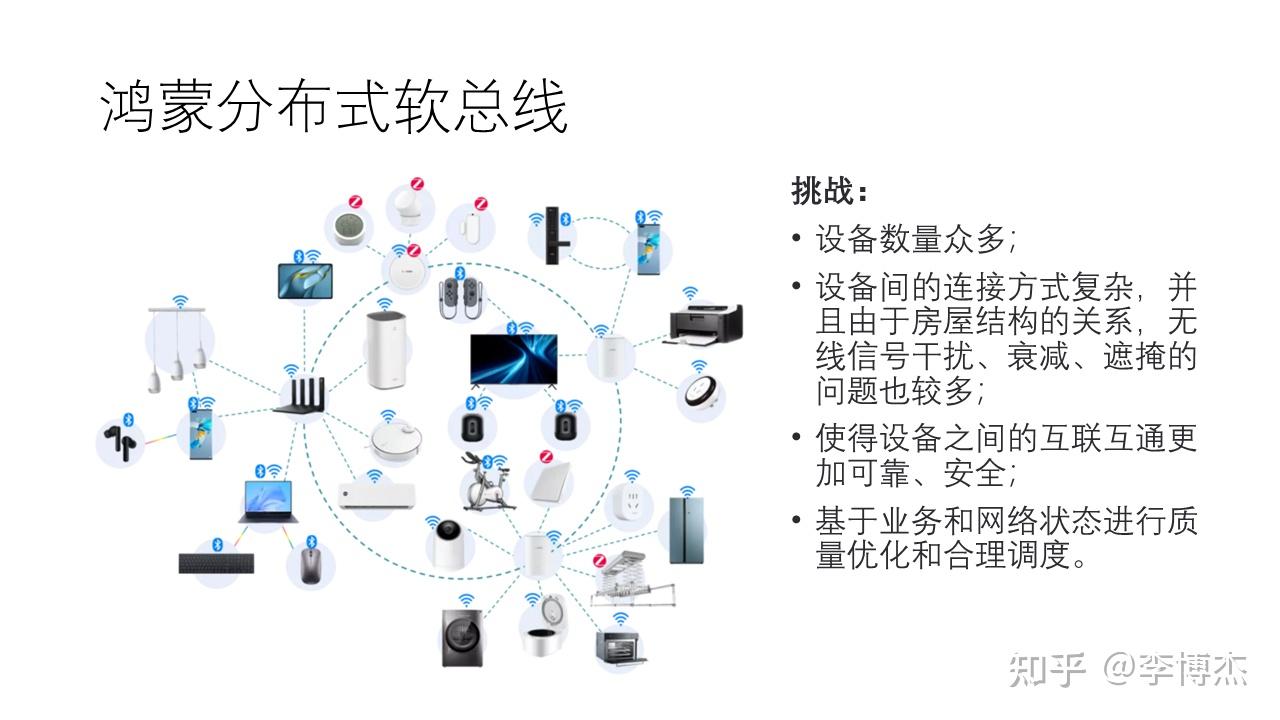
分布式超级终端中的通信主要是通过分布式软总线,“软” 的意思就是用软件实现的。软总线的概念由来已久,例如 Linux 的 D-Bus 就是一种软总线,用于进程间通信。鸿蒙的分布式软总线是把总线的概念延伸到了整个家庭的分布式系统。它的主要挑战是:
- 设备数量众多;
- 设备间的连接方式复杂,并且由于房屋结构的关系,无线信号干扰、衰减、遮掩的问题也较多;
- 使得设备之间的互联互通更加可靠、安全;
- 基于业务和网络状态进行服务质量优化和合理调度。
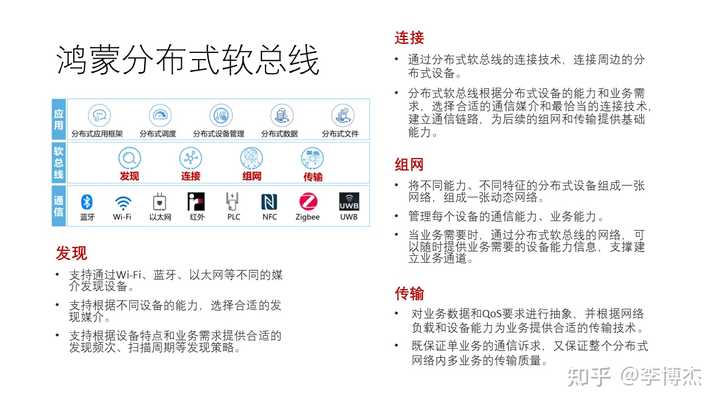
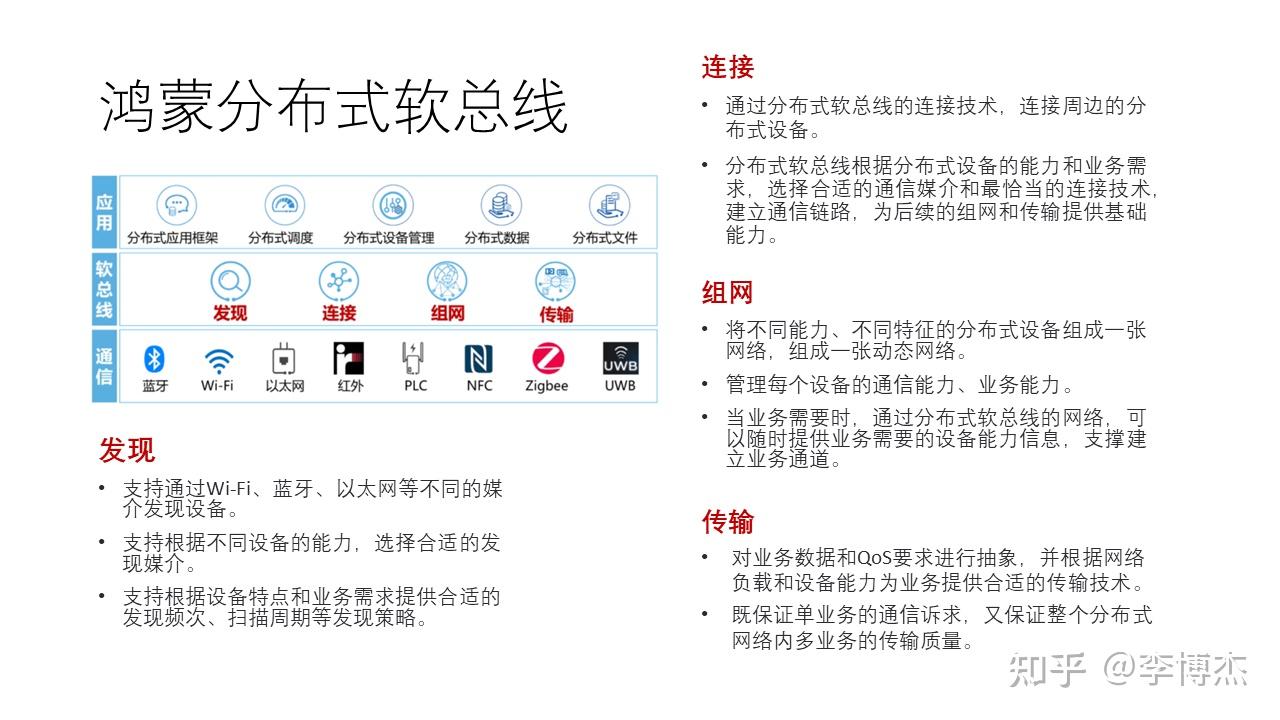
鸿蒙分布式软总线支持发现、连接、组网、传输四种基本能力。
- 发现 指的就是设备发现,如何找到整个网络中所有的终端设备。发现并不是看起来那么简单,比如有源的 RFID 标签,为了节约电池功耗,它不可能持续发送信号,只能周期性地发送;而手机为了节约功耗,也不可能不停地扫描 RFID 标签,是每间隔一段时间扫描一段时间。那么 RFID 标签和手机应该分别使用怎样的周期来发送和扫描信号呢?这就是很有讲究的。
- 连接 指的是通过分布式软总线来连接周边的通信设备。一种设备可能同时具备 Wi-Fi、蓝牙等不同通信能力,Wi-Fi 也有不同频段,那么如何选择合适的通信媒介,以及在信号较差时如何动态切换?
- 组网 指的是把不同能力和不同特征的分布式设备组成一张动态网络。一种智能家居设备可能可以通过 Wi-Fi 连接无线 AP,也可以通过蓝牙连接手机,这两个连接需要识别出同一个智能家居设备,而且其他的手机需要有能力控制该智能家居设备,这就要求网络中的每个设备都具备统一注册认证、统一寻址路由的能力。当业务需要时,需要建立任意两个设备之间的通信通道。
- 传输 就是指的传输层,包括拥塞控制、丢包重传、服务质量保证等,根据链路上的通信媒介、业务负载提供合适的传输层协议。

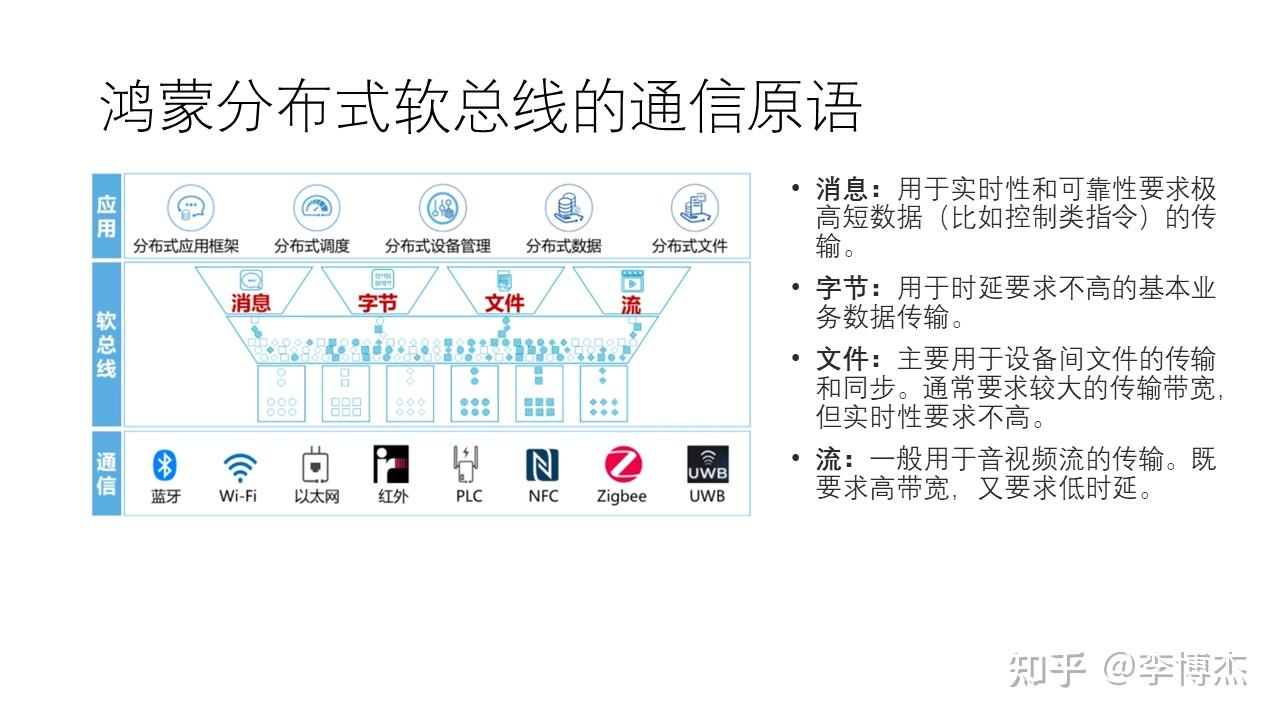
刚才我们讲了鸿蒙分布式软总线的四种基本能力,接下来我们讲它面向应用开发者的接口,也就是通信原语。我在这里不会讲具体的 API,只讲通信原语的四个基本类型。
- 消息 :用于实时性和可靠性要求极高的短数据,例如控制类的指令。
- 字节 :用于时延要求不高的基本业务数据传输,与 TCP socket 类似。
- 文件 :主要用于设备间文件的传输和同步。通常需要较大的传输带宽,但实时性要求不高。鸿蒙提供了分布式文件系统的抽象,可以打开一个远程的文件并对它进行读写。在传统的智能家居中,只有提供 NFS 之类协议的 NAS 设备才能实现文件共享。在鸿蒙中,任何文件都可以做到共享访问,并且提供了统一的权限管理机制。在不需要实时同步的场景中,也可以先写入本地副本,再在合适的时候同步到源端设备。
- 流 :一般用于音视频流的传输,既要求高带宽,又要求低时延。这跟类似 TCP socket 的字节流是不同的,音视频流是分为很多帧的,上一章我们也讲过不同帧和音视频流之间的差异,因此它比顺序传输的字节流结构更复杂。
分布式软总线的四种通信原语跟我们前面讲的数据中心内存语义(消息、远程内存访问、RPC)有些类似,但也不是完全相同的。数据中心内存语义并没有区分不同语义的优先级,每种语义的不同事务可以有优先级的区分;而鸿蒙分布式软总线的不同通信原语天生就有不同的优先级。
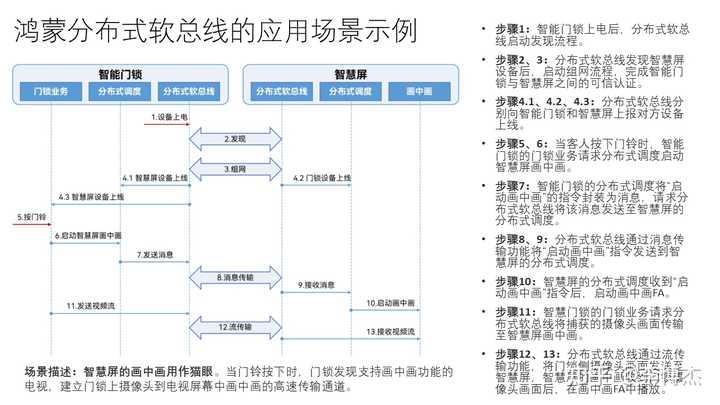
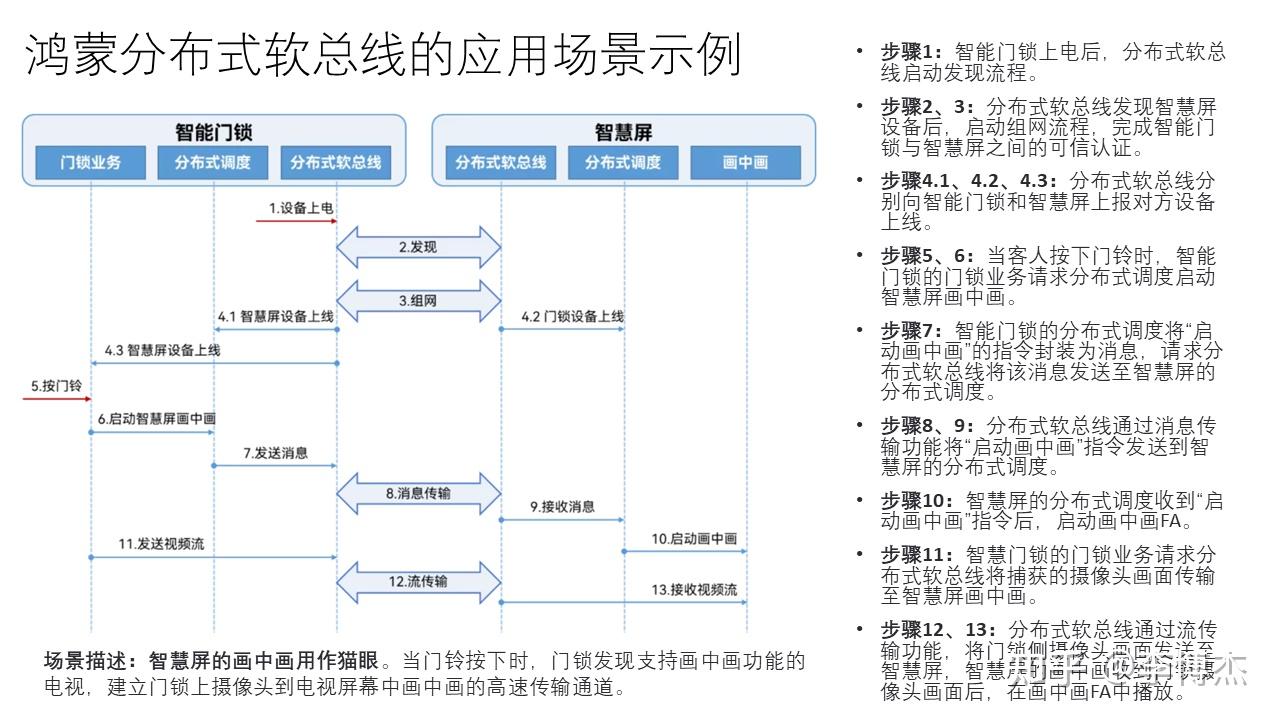
下面我们通过一个例子,说明鸿蒙分布式软总线的应用场景。这个场景是把电视屏幕的画中画功能当作智能门锁的猫眼用。当门铃按下的时候,门锁需要发现支持画中画功能的电视,然后建立门锁上摄像头到电视屏幕中画中画的高速传输通道。详细步骤如下:
- 步骤 1:智能门锁上电后,分布式软总线启动发现流程。
- 步骤 2、3:分布式软总线发现智慧屏设备后,启动组网流程,完成智能门锁与智慧屏之间的可信认证。
- 步骤 4.1、4.2、4.3:分布式软总线分别向智能门锁和智慧屏上报对方设备上线。
- 步骤 5、6:当客人按下门铃时,智能门锁的门锁业务请求分布式调度启动智慧屏画中画。
- 步骤 7:智能门锁的分布式调度将 “启动画中画” 的指令封装为消息,请求分布式软总线将该消息发送至智慧屏的分布式调度。
- 步骤 8、9:分布式软总线通过消息传输功能将 “启动画中画” 指令发送到智慧屏的分布式调度。
- 步骤 10:智慧屏的分布式调度收到 “启动画中画” 指令后,启动画中画 FA(Feature Ability,元服务)。
- 步骤 11:智慧门锁的门锁业务请求分布式软总线将捕获的摄像头画面传输至智慧屏画中画。
- 步骤 12、13:分布式软总线通过流传输功能,将门锁侧摄像头画面发送至智慧屏,智慧屏的画中画收到门锁摄像头画面后,在画中画 FA(元服务)中播放。
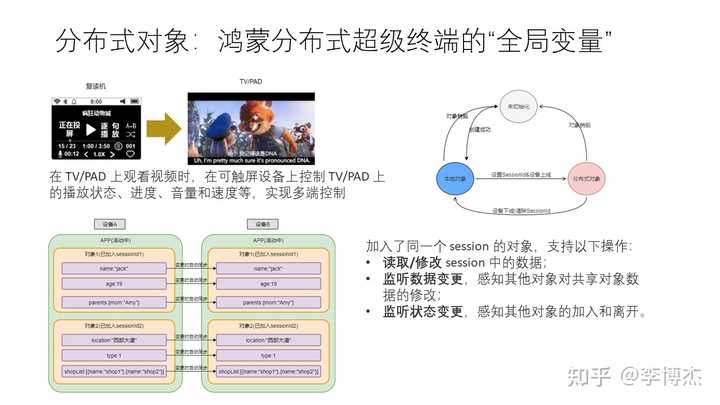
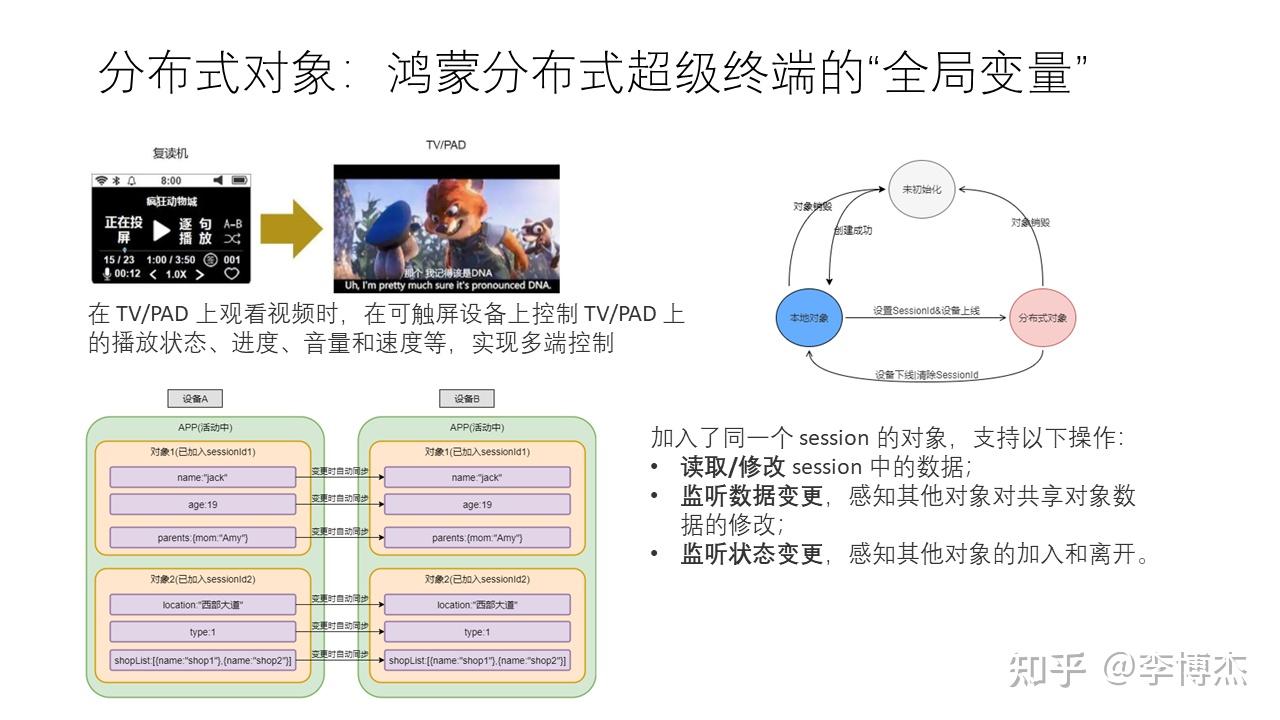
分布式软总线中提供了 “分布式变量” 的抽象,方便开发者进行分布式编程。分布式变量可以看作是在鸿蒙分布式超级终端中的 “全局变量”。
举一个例子,在电视或者平板上看视频的时候,有播放状态、进度、音量、速度等控制属性,在手机等其他智能设备上可以控制这些属性,这就是所谓的多端控制。它的实现原理就是分布式变量。
与传统的共享内存不同,分布式变量不是基于内存地址的,而是基于对象的,每个对象使用 session ID 和 object ID 来索引。基于对象相比分布式共享内存有很多优点,首先是避免了分布式共享内存中内存分配、并发访问的原子性问题,所有对象访问都是由对象管理节点处理的;其次是以对象为粒度访问比以字节为粒度访问的效率更高;最后是以对象粒度做缓存的分布式缓存一致性代价更低。
分布式变量除了提供读写的基本能力,还提供了通知机制,这在分布式系统中也是非常关键的。分布式对象提供了监听数据变更的能力,可以感知其他对象对共享对象数据的变更;还提供了监听状态变更,可以感知 session 内新增和删除对象的事件。例如,音量被其他终端设备修改的时候,播放视频的设备需要感知到该分布式变量的修改,并通知扬声器修改音量。
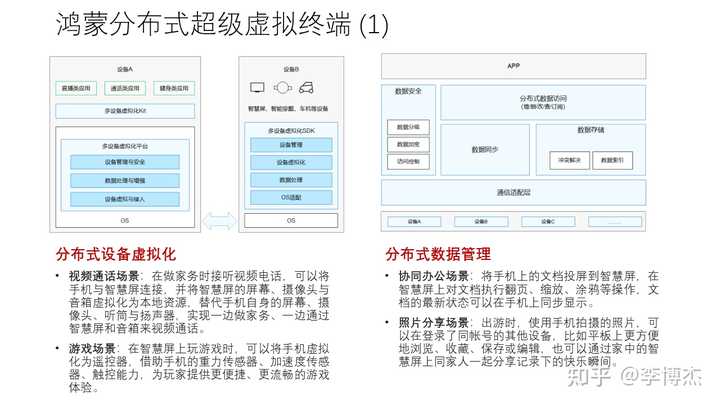
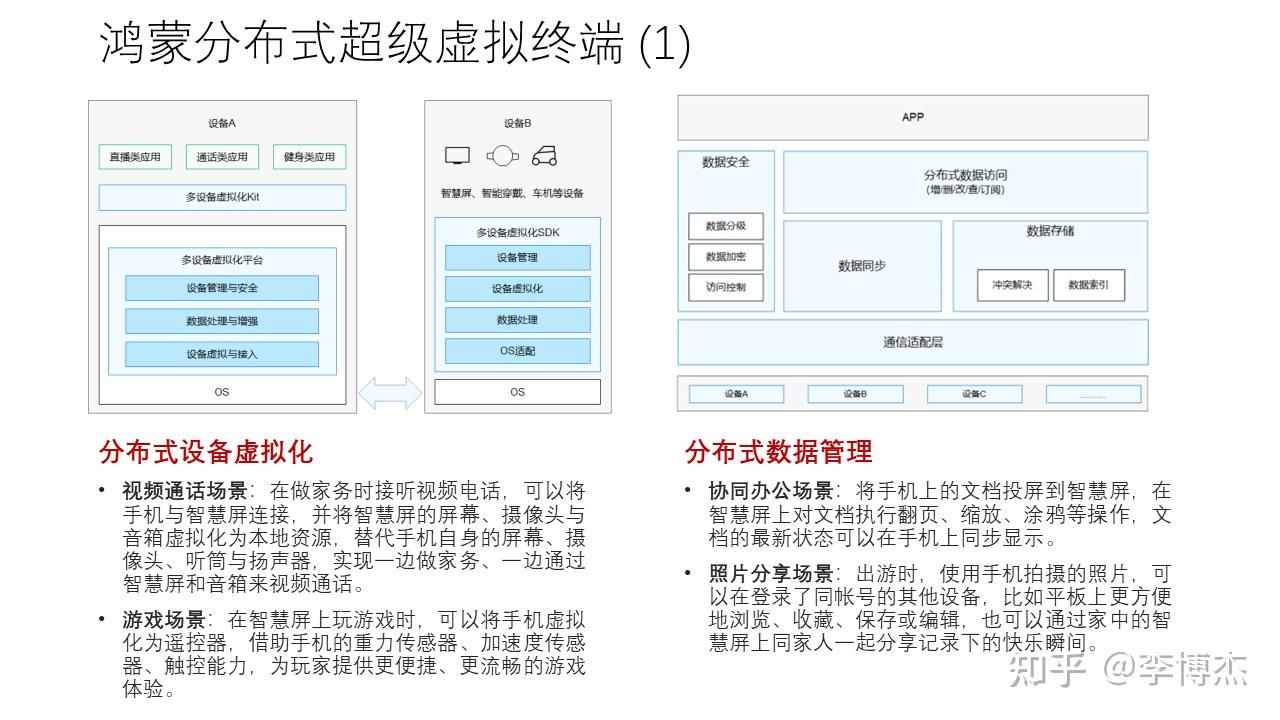
以分布式软总线作为基础,可以把家庭中的智能设备组成鸿蒙分布式超级虚拟终端,支持分布式设备虚拟化、分布式数据管理、分布式任务调度、一次开发多端部署。
分布式设备虚拟化 就是把一个设备虚拟化成另一个设备,比如把智慧屏虚拟化成手机,或者把手机虚拟化成游戏手柄。在视频通话场景,为了在做家务的时候接听视频电话,可以把手机和智慧屏连接,并将智慧屏的屏幕、摄像头、麦克风和音箱虚拟化成本地资源,替代手机自己的屏幕、摄像头、麦克风和扬声器,实现一边做家务,一边通过智慧屏来视频通话。在游戏场景,可以把手机虚拟化成智慧屏的遥控器,借助手机的重力传感器、加速度传感器、触摸屏,把手机当作游戏手柄来用。
手机投屏其实不是新技术,现在有三大主流投屏协议:DLNA、Airplay 和 Miracast,我们一方面支持现有协议以便兼容非鸿蒙生态的设备,另一方面研发自己的分布式设备虚拟化协议,实现除了视频流、语音流、控制流之外的通用设备虚拟化能力,并能更加充分地利用无线带宽,适应多变的无线网络环境。
分布式数据管理 就是把数据在多个屏幕之间共享,与分布式变量不同,它可以提供更高级的冲突解决、数据索引能力,实现增删改查和订阅能力,也支持数据加密和访问控制。例如在协同办公场景,可以把手机上的文档投屏到智慧屏上,但这不是一个简单的视频投屏,而是把这个文档用分布式数据管理的方式在智慧屏的文档协同编辑应用上打开。在智慧屏上进行各种文档编辑操作时,文档的最新状态也可以被同步到手机上。手机和电脑也可以同时操作文档,文档协同编辑应用通过分布式数据管理框架进行冲突解决。在照片分享场景,多个手机、智慧屏、平板等可以通过家庭局域网共享照片,而无需将照片上传到云端,可以大大加速照片分享的速度,同时又能通过登录同一账号保证安全性。
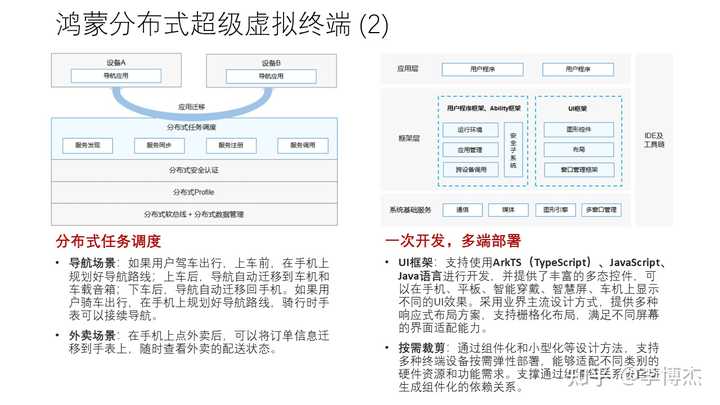
分布式任务调度 就是把一个应用在不同鸿蒙设备之间迁移,例如上车后把手机上的导航 App 迁移到智能汽车的车机上,用车载大屏和车载音箱方便操控,下车后从车机迁移回手机上。注意这里不是用手机投屏实现的。在外卖场景中,可以把手机上下单的订单信息迁移到手表上,从而随时可以查看外卖的配送状态,注意此时手表上是运行着外卖 App 的一个子任务,而不是外卖 App 把状态信息推送到手表。
我们可以看到,鸿蒙设备分布式协同的一些需求用分布式设备虚拟化(也就是手机投屏的加强版)、分布式数据管理、分布式任务调度三种方案都可以解决。具体使用哪种方案,取决于应用的需求。例如手机上的导航 App 如果用手机投屏的方式投影到车机上,那么将导航 App 将持续消耗手机的电能,而且投屏本身也会耗电;如果用分布式任务调度的方式把应用迁移到车机上,虽然迁移过程会消耗几秒时间传输应用状态数据(通过类似虚拟机迁移的增量迁移技术,可以使应用的暂停时间达到亚秒级),但在导航过程中将不再消耗手机的电能。文档协同编辑也可以用手机投屏或者分布式数据管理来实现,但手机投屏方案中手机上的文档编辑 App 在电脑上的使用体验不一定好。
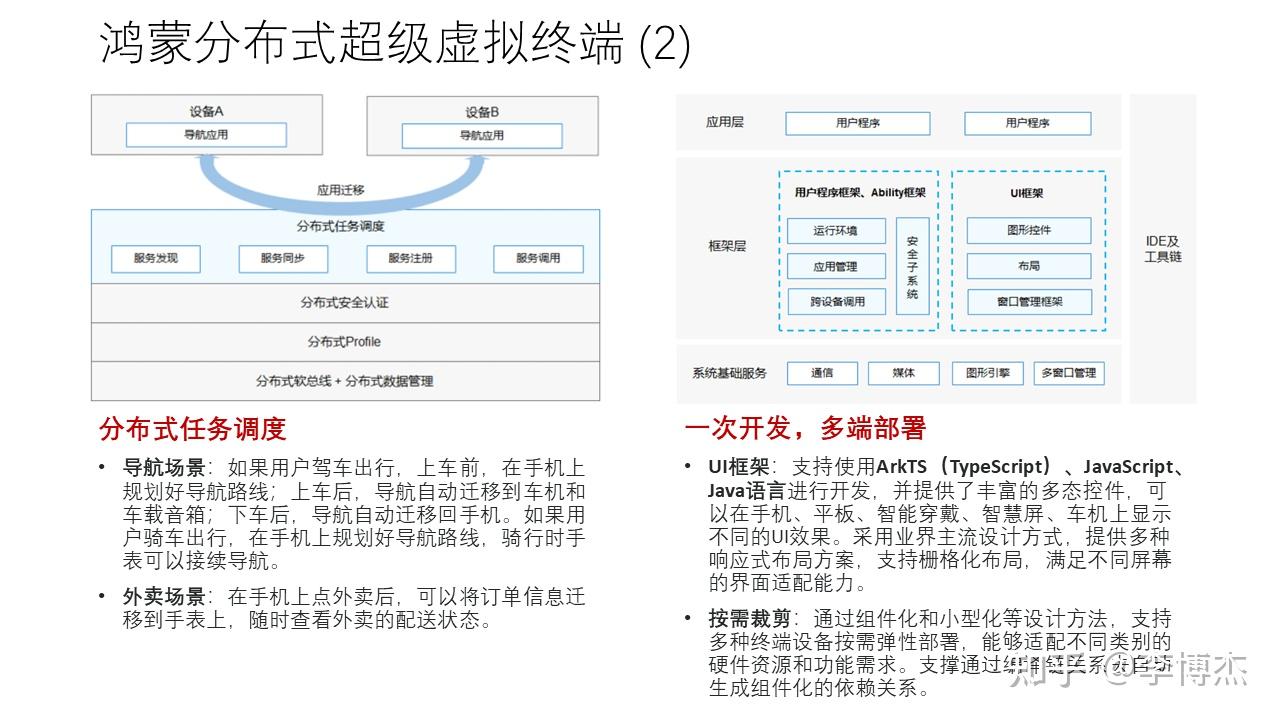
一次开发,多端部署 也是鸿蒙生态的一个典型特征,它支持使用 ArkTS(TypeScript)、JavaScript 和 Java 语言来进行开发,提供了丰富的多态组件,以便在手机、平板、智能穿戴、智慧屏、车机上显示不同的 UI 效果,提供栅格化布局和响应式布局,就像我们现在 Web 前端的很多框架一样,可以在 PC 和移动端分别用合适的布局来显示。除了响应式 UI 布局,将 App 运行在多种设备上的另一个挑战是不同设备的硬件资源和功耗要求不同,例如手表比手机的要求就严苛得多。鸿蒙通过组件化和小型化的设计方法,支持多种终端设备按需弹性部署,适配不同的硬件资源和功能需求。
以上关于鸿蒙分布式超级终端的知识都可以在鸿蒙开发者社区查到,如果大家感兴趣,可以进一步学习鸿蒙的 API,在支持鸿蒙的智能设备上开发属于自己的应用。
本章小结
以上就是无线网络部分的内容。
手机、PC、穿戴设备、智能家居、智能车等智能终端的无缝协同、5G to B 等工业互联网应用都需要稳定的低时延和高带宽,这需要无线协议栈优化,甚至无线内存语义以支持 Gbps 级别的带宽。此外,通过鸿蒙的 “分布式超级终端” 编程框架,可以使能更紧密的分布式协同,实现数据和服务无缝流转。
全文总结


今天,我们讲到了数据中心、广域网、无线网络领域的一些最新进展。从 “把数据中心作为一台超级计算机”、“全国一体化大数据中心” 到 “鸿蒙分布式超级终端”,网络都是其中非常关键的组成部分。以往我们认为总线仅仅是单台服务器、单台设备内部的高速互联硬件,而如今高性能的数据中心网络和鸿蒙分布式软总线模糊了服务器和终端设备的边界,“总线网络化” 和 “网络总线化” 成为历史的潮流。未来的硬件总线需要吸收网络领域的设计以便扩展到更大的规模,而网络和通信原语的设计需要吸收高速总线的思想以提高性能。
我认为,网络和系统领域创新的两大驱动力是应用需求和硬件能力。
- 如今,在数据中心领域,AI、大数据、高性能存储、科学计算等对算力和存储容量的需求增长速度超过摩尔定律,使得我们需要越来越大的集群来做分布式并行计算,而网络是其中的关键瓶颈。在终端领域,工业互联网、AR、VR、高清实时音视频、分布式协同等应用也对广域网和无线网络的带宽和时延,特别是稳定的带宽和时延,提出了新的需求。
- 而在硬件能力方面,网络的性能尚未见顶:数据中心网络即使用了 RDMA,与 NVLink 等高速总线的性能之间仍有一条巨大的鸿沟;广域网的路由器交换性能远未达到光纤容量的上限;终端领域的 Wi-Fi 6、毫米波、卫星通信等也有巨大的挖潜空间。
- 再看软件,事实上厚重的软件协议栈和落后的传输协议远远不能充分利用现有硬件的能力,不管是数据中心还是广域网,内核的 TCP/IP 协议栈都浪费了数倍到数十倍的硬件能力。这是由于传统网络协议栈运行在通用处理器上,假定通用处理器的算力增长符合摩尔定律,但这已经不再是事实。随着异构算力和存储性能的快速增长,网络协议栈愈发成为瓶颈,因此需要软硬件协同设计,重新定义通信原语,也就是重新划分软件和硬件各自负责的事务。
因此,我认为计算机网络也进入了一个黄金时代,其中有无数的问题等待我们一起探索,特别是其中的软件部分,软硬件协同设计和软件协议栈优化都将是未来 10 年的重要课题。
计算机系统的三驾马车是计算、存储、网络。作为系统基础架构的一部分,网络往往是坏了的时候才会被人想起。只要哪个应用挂了,大家往往第一时间想到的就是网络问题。这说明我们的网络目前还不够鲁棒,而且故障定位、故障自愈的能力还不够强。但我认为网络的可靠性问题一定是可以解决的。就在短短 20 年前,我们还经常需要到处找地方上网。今天,网络已经几乎无处不在,但信号不好还是常事。未来,断网也许将成为罕见的事故。即使百年之后,我相信网络仍然会作为计算机系统的基石,成为万物互联的智能世界背后默默奉献的力量。


数据中心、广域网、终端无线网络通信中的问题我们基本上都在研究,也有一些初步成果,但还没有正式发布,因此今天讲的主要是学术界和工业界现有的一些技术。感兴趣的同学欢迎来我们计算机网络与协议实验室实习或者工作,我们拥有非常强的一支团队,承担公司战略项目的研发工作,我相信其中的技术是世界领先的。