协方差的意义和计算公式
学过概率统计的孩子都知道,统计里最基本的概念就是样本的均值,方差,或者再加个标准差。首先我们给你一个含有n个样本的集合,依次给出这些概念的公式描述,这些高中学过数学的孩子都应该知道吧,一带而过。
很显然,均值描述的是样本集合的中间点,它告诉我们的信息是很有限的,
而标准差给我们描述的则是样本集合的各个样本点到均值的距离之平均。以这两个集合为例,[0,8,12,20]和[8,9,11,12],两个集合的均值都是10,但显然两个集合差别是很大的,计算两者的标准差,前者是8.3,后者是1.8,显然后者较为集中,故其标准差小一些,标准差描述的就是这种“散布度”
。之所以除以n-1而不是除以n,是因为这样能使我们以较小的样本集更好的逼近总体的标准差,即统计上所谓的“无偏估计
”。
而方差则仅仅是标准差的平方。
为什么需要协方差?
上面几个统计量看似已经描述的差不多了,但我们应该注意到,标准差和方差一般是用来描述一维数据的,但现实生活我们常常遇到含有多维数据的数据集,最简单的大家上学时免不了要统计多个学科的考试成绩。面对这样的数据集,我们当然可以按照每一维独立的计算其方差,但是通常我们还想了解更多,比如,一个男孩子的猥琐程度跟他受女孩子欢迎程度是否存在一些联系啊,嘿嘿~
协方差就是这样一种用来
度量
两个随机变量关系
的统计量
,我们可以仿照方差的定义:
来度量各个维度偏离其均值的程度,标准差可以这么来定义:
协方差的结果有什么意义呢?如果结果为正值,则说明两者是正相关的(从协方差可以引出“相关系数”的定义),也就是说一个人越猥琐就越受女孩子欢迎,嘿嘿,那必须的~结果为负值就说明负相关的,越猥琐女孩子越讨厌,可能吗?如果为0,也是就是统计上说的“相互独立”。
从协方差的定义上我们也可以看出一些显而易见的性质,如:
协方差多了就是协方差矩阵
上一节提到的猥琐和受欢迎的问题是典型二维问题,而
协方差也只能处理二维问题
,那
维数多了
自然就需要计算多个协方差,比如n维的数据集就需要计算
个协方差,那自然而然的我们
会想到使用矩阵来组织这些数据
。给出协方差矩阵的定义:
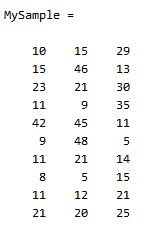
这个定义还是很容易理解的,我们可以举一个简单的三维的例子,假设数据集有
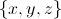 三个维度,则协方差矩阵为
三个维度,则协方差矩阵为
可见,
协方差矩阵是一个对称的矩阵,而且对角线是各个维度上的方差
。
计算dim1与dim2,dim1与dim3,dim2与dim3的协方差:
|
123
|
sum( (dim1-mean(dim1)) .* (dim2-mean(dim2)) ) / ( size(MySample,1)-1 ) % 得到 74.5333sum( (dim1-mean(dim1)) .* (dim3-mean(dim3)) ) / ( size(MySample,1)-1 ) % 得到 -10.0889sum( (dim2-mean(dim2)) .* (dim3-mean(dim3)) ) / ( size(MySample,1)-1 ) % 得到 -106.4000
|
搞清楚了这个后面就容易多了,协方差矩阵的对角线就是各个维度上的方差,下面我们依次计算:
|
123
|
std(dim1)^2 % 得到 108.3222std(dim2)^2 % 得到 260.6222std(dim3)^2 % 得到 94.1778
|
这样,我们就得到了计算协方差矩阵所需要的所有数据,调用Matlab自带的cov函数进行验证:
把我们计算的数据对号入座,是不是一摸一样?
Update:今天突然发现,原来协方差矩阵还可以这样计算,先让样本矩阵中心化,即每一维度减去该维度的均值,使每一维度上的均值为0,然后直接用新的到的样本矩阵乘上它的转置,然后除以(N-1)即可。其实这种方法也是由前面的公式通道而来,只不过理解起来不是很直观,但在抽象的公式推导时还是很常用的!同样给出Matlab代码实现:
|
12
|
X = MySample - repmat(mean(MySample),10,1); % 中心化样本矩阵,使各维度均值为0C = (X'*X)./(size(X,1)-1);
|
理解协方差矩阵的关键
就在于
牢记它计算的是
不同维度之间的协方差
,而不是
不同样本之
间
,
拿到一个样本矩阵,我们最先要明确的就是
一行是一个样本还是一个维度
,心中明确这个整个计算过程就会顺流而下,这么一来就不会迷茫了~
http://download.csdn.net/detail/goodshot/5087550
协方差的意义和计算公式学过概率统计的孩子都知道,统计里最基本的概念就是样本的均值,方差,或者再加个标准差。首先我们给你一个含有n个样本的集合,依次给出这些概念的公式描述,这些高中学过数学的孩子都应该知道吧,一带而过。均值:标准差:方差:很显然,均值描述的是样本集合的中间点,它告诉我们的信息是很有限的,
对于一般的分布,直接代入E(X)之类的就可以
计算
出来了,但真给你一个具体数值的分布,要
计算
协方差
矩阵,根据这个公式来
计算
,还真不容易反应过来。网上值得参考的资料也不多,这里用一个例子说明
协方差
矩阵是怎么
计算
出来的吧。
记住,X、Y是一个列向量,它表示了
方差:方差是变量与其平均值的平方和的算术平均值,例如:
有一组数据{4,5,6,7}, 平均值为:(4+5+6+7)/4=22/4=5.5
其方差为:[(4-5.5)2+(5-5.5)2+(6-5.5)2+(7-5.5)2]/4
标准差:方差的开2次方
例如上面那组数据的标准差为:{[(4-5.5)2+(5-5.5)2...
先从方差开始,我们有一组样本x1、x2、x3····xn,这组样本的均值为EX,每一个样本都与EX之间存在误差,那么这组样本的方差被定义为:所有误差的和的均值,也即[Σ(xi-EX)^2]/(n-1),
方差的作用就是用来“衡量样本偏离均值的程度”。
下面开始看
协方差
:
MATLAB
图像
基本运算1.均值函数代码函数调用2.中值函数代码函数调用3.众数函数代码函数调用4.方差函数代码函数调用5.
协方差
函数代码函数调用6.相关系数函数代码函数调用
求出
图像
矩阵所有数值的均值。
①
图像
矩阵的每个值都是uint8类型的,uint8的范围是0-255,在进行求和之前需要把
图像
矩阵转换成double类型,如果不转换,继续对uint8类型进行运算会产生溢出;
②将矩阵变为1×n或者n×1形式,求和时可以采用单层循环,加快
计算
速度。
function [r
SSIM(Structural Similarity),结构相似性,是一种衡量两幅
图像
相似度的指标。该指标首先由德州大学奥斯丁分校的
图像
和视频工程实验室(Laboratory for Image and Video Engineering)提出。SSIM使用的两张
图像
中,一张为未经压缩的无失真
图像
,另一张为失真后的
图像
。
给定两个
图像
和,两张
图像
的结构相似性可按照以下方式求出:
其中是的平均值,是的平均值,是的方差,是的方差,是和的
协方差
。,是用来维持稳定的常数。是像素值...